基于加权模糊C-均值聚类的锅炉运行参数基准值建模
2019-01-25王培红梁俊宇杜景琦
赵 明,王培红,梁俊宇,杜景琦,殷 捷,赵 阳
基于加权模糊C-均值聚类的锅炉运行参数基准值建模
赵 明1,王培红2,梁俊宇1,杜景琦3,殷 捷4,赵 阳2
(1.云南电网有限责任公司电力科学研究院,云南 昆明 650217; 2.东南大学能源与环境学院,江苏 南京 210096; 3.云南电力试验研究院(集团)有限公司,云南 昆明 650217; 4.南京瑞松信息科技有限公司,江苏 南京 210000)
锅炉运行参数基准值是锅炉耗差分析的基础和前提。本文提出了基于加权模糊C-均值聚类的锅炉运行参数基准值确定方法,该方法基于不同锅炉运行参数对锅炉效率影响程度不同,利用锅炉效率简化计算模型对锅炉运行参数进行求导,进而确定不同锅炉运行参数各自的权重;然后利用加权模糊C-均值聚类算法在典型负荷区间进行多参量同步挖掘,从而确定锅炉运行参数基准值。实例分析结果表明,相对于基于模糊C-均值聚类的传统方法,本文方法确定的锅炉运行参数基准值更加合理有效。
锅炉;运行参数;耗差分析;权重;模糊C-均值聚类;基准值
锅炉耗差分析是指分析锅炉当前运行参数偏离基准值时所造成的煤耗变化量。利用锅炉耗差分析,能够了解导致锅炉效率变化的影响因素[1]。为了能够对锅炉主要运行参数进行耗差分析,需要确定在不同工况下锅炉运行参数的基准值。确定锅炉运行参数基准值的方法分为以下几种。1)以设计数据或锅炉热力性能试验为数据基础确立基准值。该方法只适用于特定环境条件,随着机组运行性能退化及外部条件的改变,往往无法获得当前运行参数的基准值。2)运用设备的变工况等特性知识[2],建立基准值模型。该方法考虑了机组运行方式与设备效率对设备特性的影响,变化趋势相对合理,然而由于机组特性的复杂性导致计算精度仍然不高。3)利用数据挖掘技术和历史运行数据确定参数基准值模型。该方法由于其时效性和可行性,目前已取得广泛地应用。
文献[3]利用神经网络模型预测锅炉运行中需要优化的性能参数;文献[4]利用粒子群优化Apriori算法,挖掘精简后的数据库中符合机组NO减排要求的各个参数的最优参考工况;文献[3-4]的建模和寻优确定锅炉运行参数基准值的方法受建模精度影响较大。文献[5-8]利用关联规则、模糊关联规则以及增量挖掘确定机组的监控参数基准值,这类算法计算复杂度较高。文献[9]首次将模糊C-均值聚类(FCM)应用到锅炉再热器压损和锅炉排烟温度的基准值建模,利用各聚类数据集中心与负荷的对应关系建立了基准值模型。文献[10]提出一种基于FCM和实际运行数据确定不同负荷下基准值的方法,该方法针对各典型负荷邻域内锅炉各监控参数的数据样本可进行多参量同步挖掘。然而FCM进行多参量同步挖掘时将各个参量视作等权重,未考虑不同锅炉运行参数对锅炉效率的影响程度不同。
本文在文献[10]的基础上,提出一种基于加权模糊C-均值聚类算法的锅炉运行参数基准值确定方法。该方法针对不同锅炉运行参数对锅炉效率影响程度不同,利用锅炉效率简化计算模型[11]对锅炉运行参数进行求导获得了各个参数的权重,并利用加权模糊C-均值聚类算法进行多参数同步挖掘,进而确定更合理有效的锅炉运行参数基准值,并通过实例证明了本文方法的有效性。
1 加权模糊C-均值聚类算法
FCM[12-13]是由Dunn和Bezdek提出的一种聚类算法。FCM把个样本x(=1, 2, …,)分为个模糊组,并求使非相似性价值指标达到最小的组聚类中心。FCM采用模糊划分,使其每个数据样本用区间[0,1]内的隶属度来确定其属于各个类的程度。FCM的目标函数为

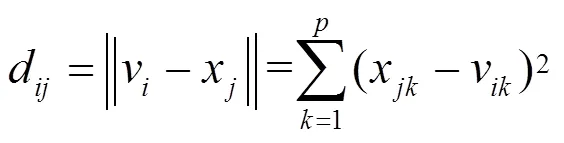
(2)
由拉格朗日变换,对所有输入参数求导,使式(1)达到最小的必要条件为:
(4)
FCM算法确定类中心时,采用距离为2范数欧氏距离,此距离度量空间内各个维度的权重相等,对类中心确定的影响也相同。然而,锅炉的各个运行参数对锅炉效率的影响是不同的,在度量空间内各个维度的权重应当与运行参数对锅炉效率的影响程度一致。基于此,本文提出加权模糊C-均值聚类(加权FCM)算法,将欧氏距离变换为加权欧氏距离:
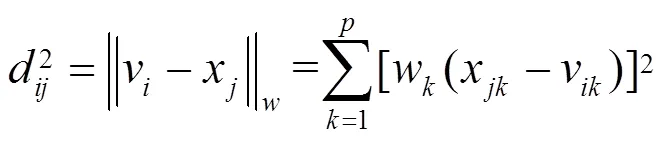
式中,w为第维锅炉运行参数的权重。
加权FCM是将加权欧氏距离式(5)代入式(3)及式(4),得到聚类的类中心及隶属度,即根据不同锅炉运行参数对锅炉效率的影响程度来确定。
2 锅炉运行参数基准值确定
2.1 锅炉运行参数权重确定
锅炉运行参数包括排烟氧量、排烟温度以及飞灰含碳量等[14-15]。不同锅炉运行参数的权重可根据专家经验确定,但这种方法具有一定的主观性。由于飞灰含碳量通常变化幅度较小,对锅炉效率影响也较小,故只确定排烟氧量2py、排烟温度py2个运行参数的权重。
锅炉效率可以通过式(6)—式(15)的简化计算模型来计算:
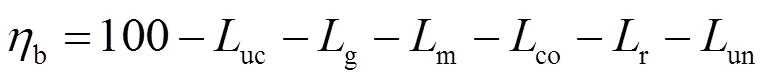

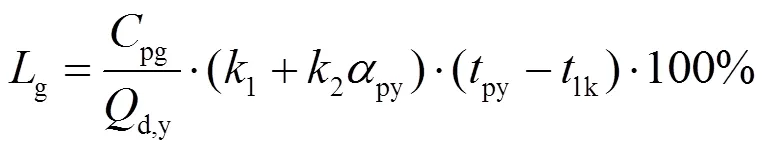
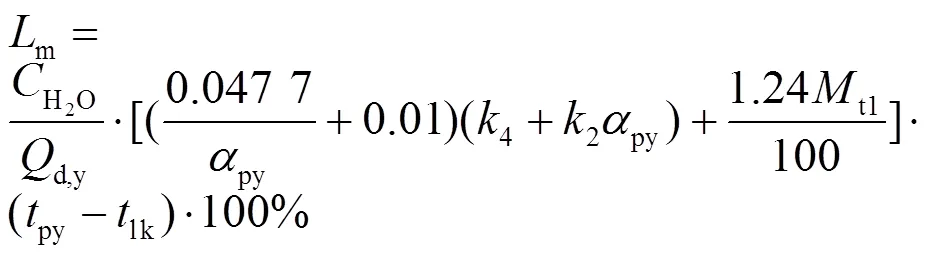
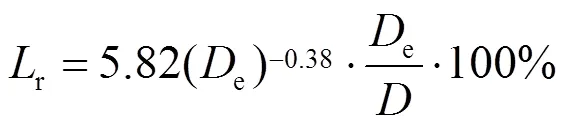
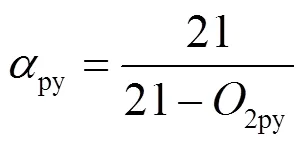
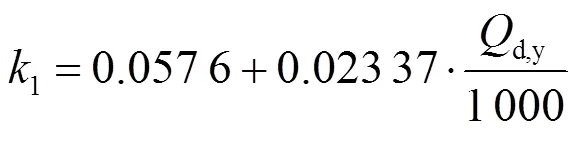
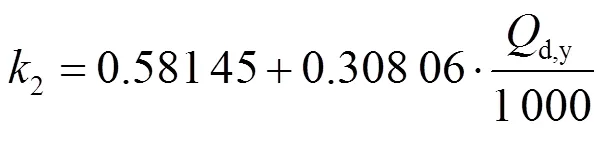
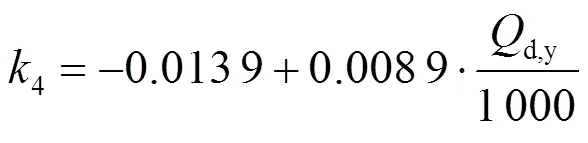

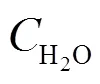
为了确定锅炉排烟氧量与排烟温度对锅炉效率的影响,利用锅炉效率简化计算模型对锅炉各运行参数求导[16],以衡量不同运行参数对锅炉效率的影响程度,结果如下:
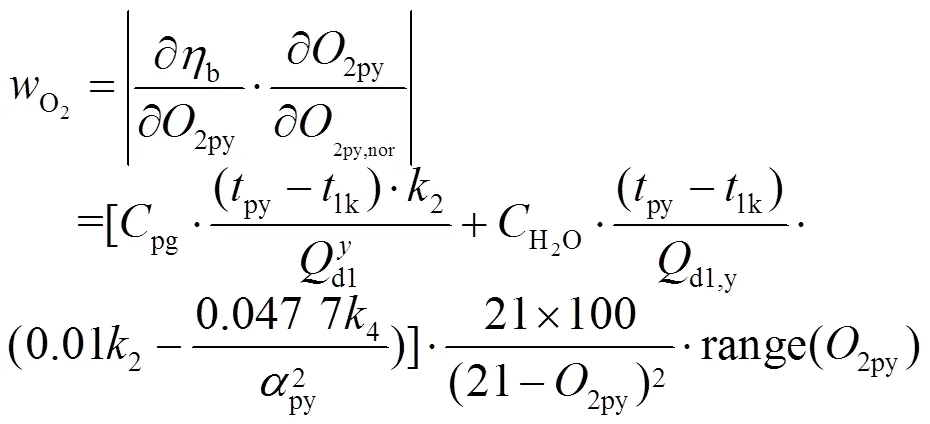
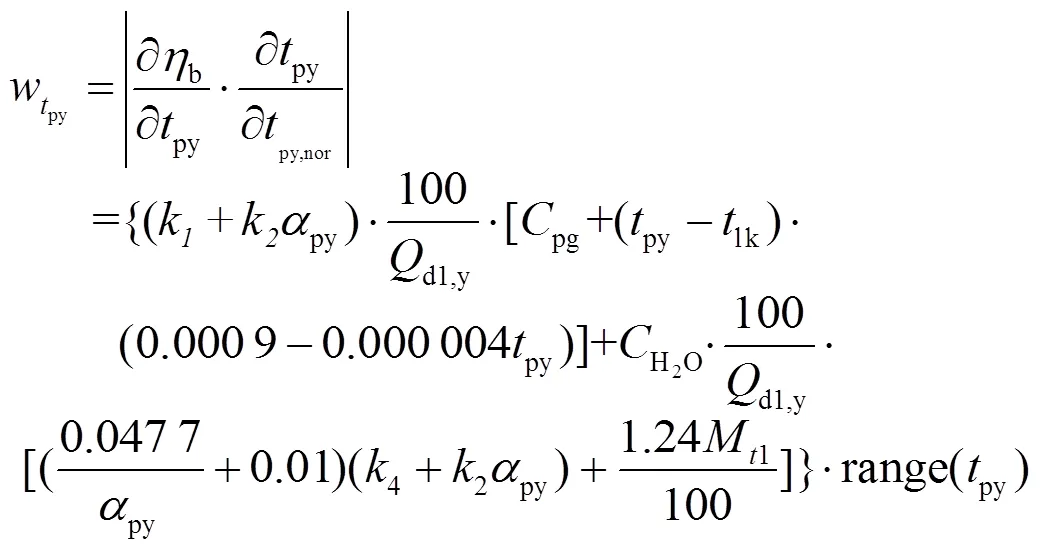
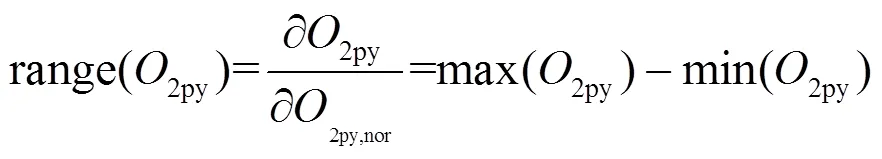
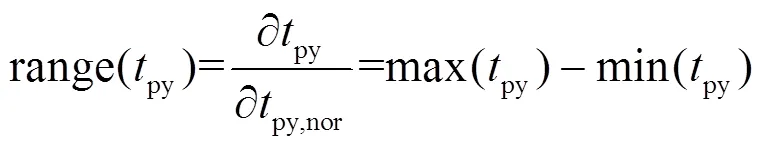
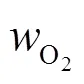
2.2 基准值确定过程
首先从电厂分布式控制系统(DCS)中提取历史运行数据,分别划分个典型负荷区间,如50%负荷、70%负荷等;采用2.1节方法确定各负荷区间内的排烟氧量2py、排烟温度py的权重;之后利用加权FCM算法对各负荷区间内的2个锅炉运行参数进行聚类,将第个负荷区间的运行数据样本分为类1、2、...、C;然后对比各个类中心点处的锅炉效率,假设C为该区间内锅炉效率最高的类中心,则返回距离C最近的数据样本点,该样本点即为第个典型负荷所对应的运行参数基准值样本点x=(2pyi,pyi),=1, 2, …,;接着利用个挖掘出的基准值样本点进行回归分析,分别确定各运行参数的基准值模型。
在基准值样本点挖掘的过程中,为了保证结果的可靠性及有效性,数据样本需要达到相应的运行模式支持度以及确定合适的聚类数,对应的确定方法可以参考文献[9]。
3 计算实例
以某电厂300 MW凝汽式机组为例,该机组锅炉型号为HG-1025/17.5-L.HM37,由于其运行时间较长,用设计数据作为其排烟温度和排烟氧量的基准值不准确,故利用加权FCM算法对锅炉运行数据挖掘基准值,寻找各负荷工况下锅炉的高效运行工况。本文选取该锅炉近期1个月的历史运行数据,对应的运行负荷区间为143.6~269.4 MW,经过数据预处理后的数据样本数为13 334条,锅炉热效率为修正到环境温度20 ℃、设计煤种(低位发热量 21 000 kJ/kg,收到基灰分20%,全水分10%),采用锅炉效率简化计算模型计算锅炉效率。
首先将总负荷区间划分为8个负荷区间;然后计算每个区间数据样本的平均排烟温度py和平均排烟氧量2py,代入式(16)—式(17),得到每个负荷区间内排烟氧量和排烟温度的权重(表1)。
表1 不同典型负荷区间排烟温度与排烟氧量权重对比

Tab.1 The weight of exhaust temperature and exhaust oxygen content in different typical load regions
利用加权FCM算法寻找各个区间内的类中心,找到对应锅炉效率最高的类中心,距离其最近的样本点所对应的2py和py即为该典型负荷区间内排烟温度和排烟氧量的基准值。然后对每个负荷区间进行相同的操作,直到找到所有典型负荷区间的基准值样本点并对样本点进行回归,最终得到图1、图2所示的排烟氧量和排烟温度基准值模型。
根据图1和图2可得,排烟氧量和排烟温度基准值回归模型为:

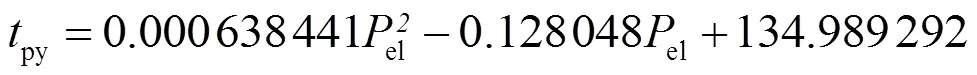
从表1可以看出,所有负荷区间内排烟温度的权重要大于排烟氧量的权重,即对于标准化后的参数数据,排烟温度对锅炉效率的影响要略大于排烟氧量,寻找基准值时须更重视排烟温度。此外,本文与文献[9]基于FCM的基准值确定方法进行对比,结果见图3和图4。

图1 排烟氧量基准值典型样本点及其回归模型
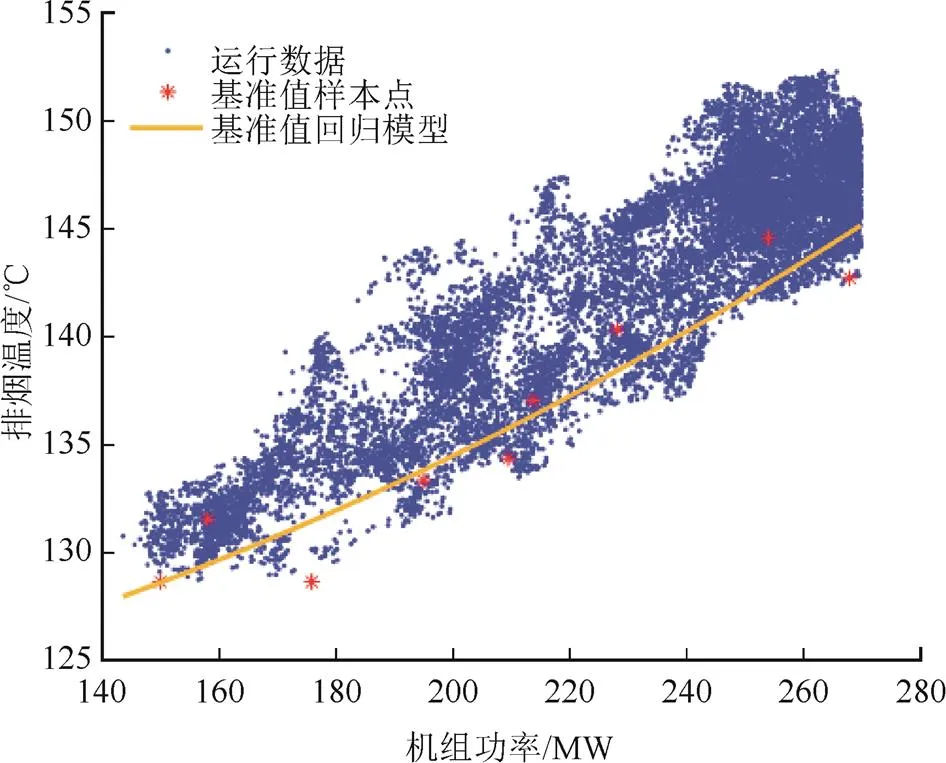
图2 排烟温度基准值典型样本点及其回归模型
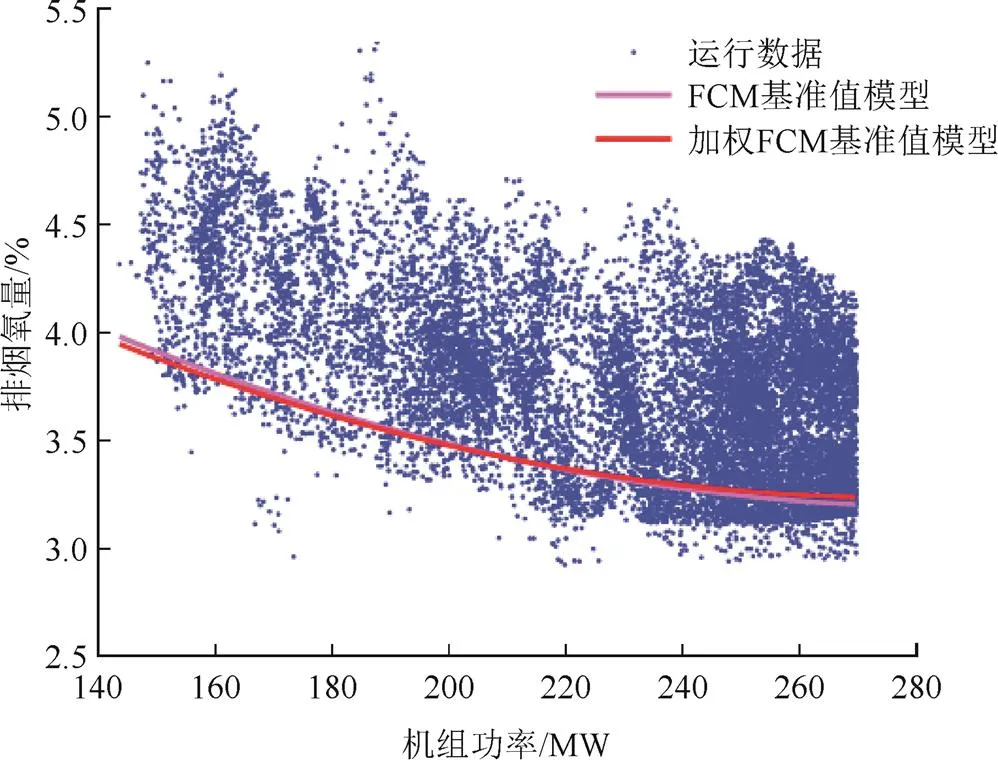
图3 排烟氧量基准值模型对比
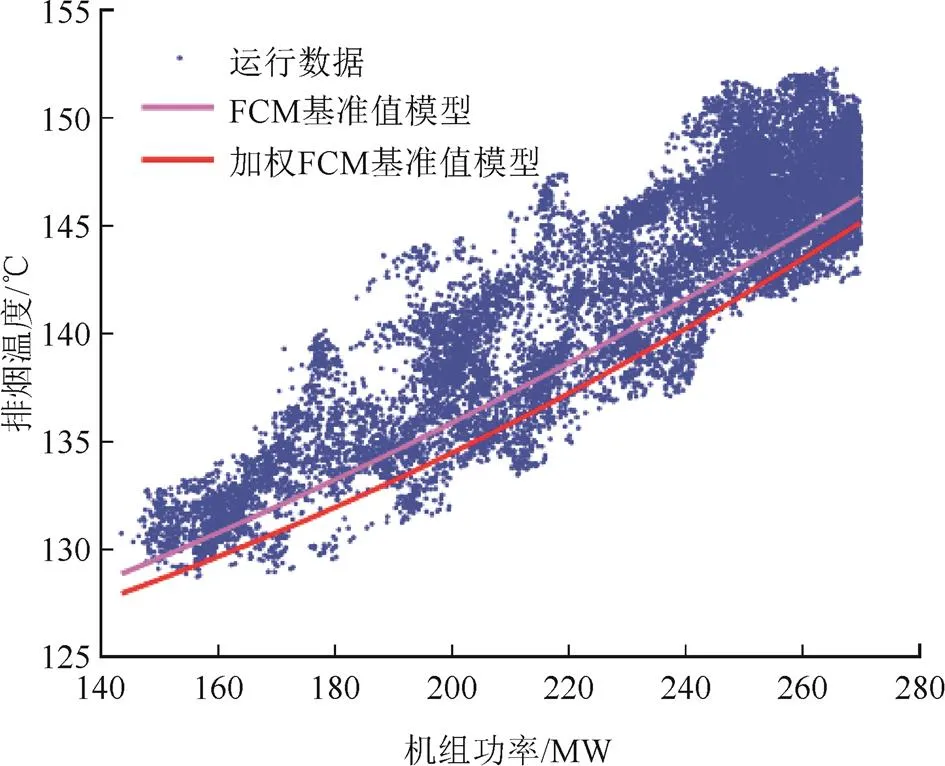
图4 排烟温度基准值模型对比
由图3和图4可见,基于加权FCM得到的排烟氧量基准值回归模型比基于FCM得到的回归模型整体上接近或略高,而排烟温度回归模型则整体上略低。这是由于加权FCM根据对锅炉效率影响程度的不同调整了2个参数的权重,在典型负荷区间内增加了对排烟温度参数的重视程度,因此相对于基于FCM的基准值确定方法,尽管排烟氧量基准值略有上升,但对锅炉效率影响更大的排烟温度基准值却相对降低。图5为2种方法得到的锅炉效率响应曲线对比。

图5 锅炉效率响应曲线对比
由图5可见,加权FCM得到的基准值模型对应的锅炉效率响应曲线比FCM基准值模型更高,这是由于权重更高(意味着对锅炉效率影响更大)的排烟温度基准值降低的缘故。排烟温度降低则排烟热损失降低,因此对应的锅炉运行参数基准值的锅炉效率更高(平均提高0.65%)。说明基于加权FCM的锅炉运行参数基准值确定方法能够得到更加合理和有效的基准值模型,证明了本文算法的有效性。
4 结 论
本文提出了以加权FCM为基础的锅炉运行参数基准值确定方法。针对不同的运行参数对锅炉效率影响程度的不同,利用锅炉效率简化计算模型的求导确定锅炉运行参数的不同权重,利用加权FCM进行多参数同步挖掘,从而获得典型负荷区间运行参数基准值。通过对某电厂300 MW机组的实际运行数据进行锅炉运行参数基准值样本点的挖掘,表明利用加权FCM的锅炉运行参数基准值确定方法可得到各工况下更合理有效的基准值样本点。
[1]付鹏, 王宁玲, 杨勇平, 等. 多变边界火电机组能耗基准状态表征方法[J]. 工程热物理学报, 2015, 36(3): 468-473.
FU Peng, WANG Ningling, YANG Yongping, et al. The mechanism of energy-consumption benchmark in coal-fired units with varying boundary[J]. Journal of Engineering Thermophysics, 2015, 36(3): 468-473.
[2] 薛朝囡, 王万海, 韩小渠, 等. 基于GSE的600 MW锅炉热力系统变工况特性仿真研究[J]. 工程热物理学报, 2014, 35(10): 2001-2004.
XU Zhaonan, WANG Wanhai, HAN Xiaoqu, et al. Simulation on variable condition characteristics of 600 MW supercritical boiler thermal system based on GSE[J]. Journal of Engineering Thermophysics, 2014, 35(10): 2001-2004.
[3] 崔育奎, 陶丽, 崇培安. 神经网络Skeletonization算法在优化锅炉运行参数中的应用[J]. 锅炉技术, 2016(2): 21-26.
CUI Yukui, TAO Li, CHONG Peian. Application of neural network algorithm Skeletonization for boiler performance optimization[J]. Boiler Technology, 2016(2): 21-26.
[4] 李建强, 汪安明, 潘文凯, 等. 燃煤电站锅炉低NO燃烧运行参数优化[J]. 动力工程学报, 2016, 36(5): 337-342.
LI Jianqiang, WANG Anming, PAN Wenkai, et al. Operating parameters optimization for low NOcom- bustion of coal-fired boilers[J]. Journal of Chinese Society of Power Engineerin, 2016, 36(5): 337-342.
[5] 王春林, 张乐. 电站锅炉低NO燃烧建模优化研究与应用[J]. 热能动力工程, 2013, 28(4): 390-394.
WANG Chunlin, ZHANG Le. Optimization study and application of the modeling of the low NOcombustion of a utility boiler[J]. Journal of Engineering for Thermal Energy &Power, 2013, 28(4): 390-394.
[6] 刘宝玲, 何钧, 曾暄. 嵌套式数据挖掘技术在电站工况分析中的应用[J]. 电站系统工程, 2014(5): 13-15.
LIU Baoling, HE Jun, ZENG Xuan. The application of nested data mining in power plant operating condition analysis[J]. Power System Engineering, 2014(5): 13-15.
[7] 刘吉臻, 牛成林, 李建强, 等. 锅炉经济性分析及最优氧量的确定[J]. 动力工程, 2009, 29(3): 245-249.
LIU Jizhen, NIU Chenglin, LI Jianqiang, et al. Boiler economic analysis and the determination of optimal oxygen content[J]. Journal of Power Engineering, 2009, 29(3): 245-249.
[8] 谷俊杰, 孔德奇, 高大明, 等. 电站锅炉燃烧优化中最佳烟气含氧量设定值的计算[J]. 华北电力大学学报(自然科学版), 2007(6): 61-65.
GU Junjie, KONG Deqi, GAO Daming, et al. Cal- culation of the optimal set value of flue gas oxygen content for the optimization of combustion in power plant boiler[J]. Journal of North China Electric Power University, 2007(6): 61-65.
[9] 钱瑾, 王培红, 李琳. 聚类算法在锅炉运行参数基准值分析中的应用[J]. 中国电机工程学报, 2007, 27(23): 71-74.
QIAN Jin, WANG Peihong, LI Lin. Application of clustering algorithm in target-value analysis for boiler operation parameter[J]. Proceedings of the CSEE, 2007, 27(23): 71-74.
[10] 赵欢, 王培红, 钱瑾, 等. 基于模糊C-均值聚类的锅炉监控参数基准值建模[J]. 中国电机工程学报, 2011, 31(32): 16-22.
ZHAO Huan, WANG Peihong, QIAN Jin, et al. Modeling for target-value of boiler monitoring parameters based on fuzzy C-Means clustering algorithm[J]. Proceedings of the CSEE, 2011, 31(32): 16-22.
[11] 张小桃, 王培红. 一种新的锅炉效率计算模型[J]. 电站系统工程, 1999, 15(4): 16-17.
ZHANG Xiaotao, WANG Peihong. New computing model for boiler efficiency[J]. Power System Engineering, 1999, 15(4): 16-17.
[12] DUNN J. A fuzzy relative of the ISODATA process and its use in detecting compact well-separated clusters[J]. Journal of Cybernetics, 1973, 8(3): 32-57.
[13] BEZDEK J C. Pattern recognition with fuzzy objective function algorithms[M]. New York: Plenum Press, 1981: 62-78.
[14] 上海发电设备成套设计研究所.电站锅炉性能试验规程: GB 10184—88 [S]. 北京: 国家技术监督局, 1989: 10-11.
Shanghai Power Equipment Research Institute. Performance test code for boiler: GB 10184—88[S]. Beijing: State Bureau of Technical Supervision, 1989: 10-11.
[15] 郑体宽. 热力发电厂[M]. 北京: 中国电力出版社, 2008: 18-20.
ZHENG Tikuan. Thermal power station[M]. Beijing: China Electric Power Press, 2008: 18-20.
[16] 殷捷. 大型电站锅炉性能在线监测模型研究[D]. 南京: 东南大学, 2011: 61-63.
YIN Jie. Research on performance monitoring model of large-scale utility boiler[D]. Nanjing: Southeast University, 2011: 61-63.
Modeling of reference value of boiler operating parameters based on weighted fuzzy C-means clustering algorithm
ZHAO Ming1, WANG Peihong2, LIANG Junyu1, DU Jingqi3, YIN Jie4, ZHAO Yang2
(1. Yunnan Electric Power Science Research Institute, Kunming 650217, China; 2. School of Energy and Environment, Southeast University, Nanjing 210096, China; 3. Yunnan Electric Power Research Institute (Group) Co., Ltd., Kunming 650217, China; 4. Nanjing Reason Information Technology Co., Ltd., Nanjing 210000, China)
The reference value of boiler operating parameters is the basis and prerequisite of boiler consumption deviation analysis. This paper proposed a method for determining reference value of the boiler operating parameters based on weighted fuzzy C-means clustering algorithm. Because the influence degree of different boiler operating parameters on the boiler efficiency is different, this method uses the simplified boiler efficiency calculation model to differentiate the operating parameters, thus to obtain the weight of each boiler operating parameter. Then, the weighted fuzzy C-means clustering algorithm is applied to mine multiple parameters synchronously in the typical load range, so as to determine the reference value of the boiler operating parameters. The case study results show that, compared with the conventional method based on fuzzy C-means clustering, the proposed method can determine more reasonable and effective reference values of the boiler operating parameters.
boiler, operation parameter, consumption deviation analysis, weight, fuzzy C-means clustering, reference value
National Science and Technology Infrastructure Program (2015BAA03B02); Key Project of Yunnan Power Grid Co., Ltd. (YNYJ2016043)
赵明(1964—),男,硕士,教授级高级工程师,主要研究方向为电站锅炉燃烧试验及节能发电技术,zming64@163.com。
TK264.1
A
10.19666/j.rlfd.201803060
赵明, 王培红, 梁俊宇, 等. 基于加权模糊C-均值聚类的锅炉运行参数基准值建模[J]. 热力发电, 2019, 48(1): 12-17. ZHAO Ming, WANG Peihong, LIANG Junyu, et al. Modeling of reference value of boiler operating parameters based on weighted fuzzy C-means clustering algorithm[J]. Thermal Power Generation, 2019, 48(1): 12-17.
2018-03-05
国家科技支撑计划项目(2015BAA03B02);云南电网有限责任公司重点科技项目(YNYJ2016043)
殷捷(1986—),男,硕士,主要研究方向为火电机组性能分析与优化、状态检测与诊断等,13813083850@163.com。
(责任编辑 杜亚勤)
