基于知识图谱的云端个性化测试推荐
2019-01-24段玉聪邵礼旭崔立真高洪皓
段玉聪,邵礼旭,崔立真,高洪皓
1(海南大学 信息科学技术学院, 南海资源利用海洋国家重点实验室, 海口 570228)2(山东大学 计算机科学与技术学院, 济南 250100)3(上海大学 计算中心, 上海 200444)
1 引 言
知识图谱是用于存储计算机系统或人与计算机之间交流使用的复杂结构化和非结构化信息的知识库.知识图谱目前用于解释搜索结果,探索知识空间,使文本文档语义更加丰富或支持知识密集型应用程序,如推荐系统.推荐系统是信息过滤系统的一个子类,旨在预测用户对一个物品的"评级"或"偏好"[1].推荐方法通常包含五种方法,分别是协同过滤方法、基于内容的方法、基于个性化的方法、基于知识的方法和混合方法.
本文分析了基于知识图谱的测试推荐系统.引入知识图谱的目的是提高效益,这包括了推荐结果的正确性和准确性以及推荐活动的效率.知识图谱可以补充在基于内容的搜索中被语义隔离的项目之间的语义信息,补充的语义关系将通过调节更多的相关信息与被语意隔离的项目相比较来有效提高推荐结果的正确性.新增加的相关信息将有助于排除由孤立项目组成的不可能的语义,否则,排除这些还需要进行探索.类似的,本文也可以在这个基于知识图谱的对比架构下来检查协同过滤的合理性.本文还利用协同过滤以统计数据的形式说明上下文信息和时间轨迹信息,从而提高利用知识图谱增强内容搜索功能的有效性.本文采用这种方法,根据用户的搜索信息,测试历史,用户信息等来推荐试卷和考题.本文还提出了一个用于在云计算环境下的测试推荐系统MapReduce模型.
2 语义知识图谱的功能
大量的数据、信息和知识等类型化的资源以及用户复杂的检索需求,导致了许多并行的、复杂的工作,用户对推荐的满意度和准确性的要求也大大提高.用户希望获得更多的个性化推荐服务.知识图谱已经成为将知识以具有标记的有向图形式表示并给出文本信息的语义的强大工具.知识图谱通过将每个项目,实体和用户作为结点,并且通过将边缘相互联系的那些结点进行连接来建立图形.与UML类图相比,知识图谱具有丰富的自然语义,其表达机制更接近于自然语言,可以包含各种更完整的信息.过去已经提出了许多使用内容的方法,他们中并没有很多利用内容本身和外部知识源之间的联系,也就是知识图谱.在基于内容的方法中,知识图谱可以解决搜索词之间的语义隔离,然后补充搜索词之间的语义信息.信息表达的完整性会大大提高.知识图谱可以检查协同过滤对比较结构的合理性.基于内容的方法不考虑用户的行为轨迹和偏好.基于内容的搜索和协同过滤方法给出的推荐的准确性和效率的发展趋势是不同的,本文不能随意地将这两种方法组合起来使用.本文建议通过引入知识图谱作为媒体层来组合基于内容的搜索和协同过滤方法.本文利用协同过滤方法以统计数据的形式引入上下文信息和时间轨迹信息,从而提高利用知识图谱增强内容搜索功能的有效性.
3 语义知识图谱的应用
3.1 知识图谱增强的基于内容推荐方法
大多数现有的基于内容的推荐系统,通常用关键字描述项目,旨在根据文本内容推荐项目.然而,由于自然语言的模糊性,基于关键字的相似性评估可能会被误导.此外,这种方法也可能导致结果偏离,单个和不准确的信息源是导致结果偏离的根本原因.一个搜索请求可以表示多种含义.知识图将显示完整的信息,使用户能够找到他们最想要的那一种意义.通过单词,句子和段落表达信息的语义相关性完整性是不同的.知识图谱构建了一个与搜索信息相关的完整的知识结构.对于每个搜索关键字,本文可以通过知识图谱得到更丰富,更全面的信息.现有的建模方法对于语义信息来说并不完美.通过知识图谱的图形结构,本文可以简单地表达单词,句子,段落等.本文在图1给出了在考试推荐系统应用的部分知识图谱.用户输入的关键字被映射到图谱上的某个结点.然后历遍整个图谱,来搜索相关结点,以补充关键词与其他信息之间的语义关系,为用户提供更准确和正确的建议.

图1 在考试推荐系统应用的知识图谱的一部分Fig.1 Part of the knowledge map applied in the
知识图谱可用于更好地查询信息复杂的相关性,从语义层面了解用户的意图,从而提高搜索质量.对于一个试卷推荐系统,用户可能想要获得试卷的电子版或者不同阶段的考试卷的综合试卷,那么数据量将变得很大,数据分析也将变得更加复杂.知识图谱可以补充在基于内容的搜索中被语义隔离的项目之间的语义信息,补充的语义关系将通过调节更多的相关信息与被语意隔离的项目相比较来有效提高推荐结果的正确性.新增加的相关信息将有助于排除由孤立项目组成的不可能的语义,否则,排除这些还需要进行探索.例如,如图2所示,用户输入的关键词是公式:z+|z|=2+i.根据关键字确定相应的问题,用户输入的方程考查复变函数的知识点,相关问题可能属于大二年级的复变函数与积分变换,可以向用户提供相关的试卷.
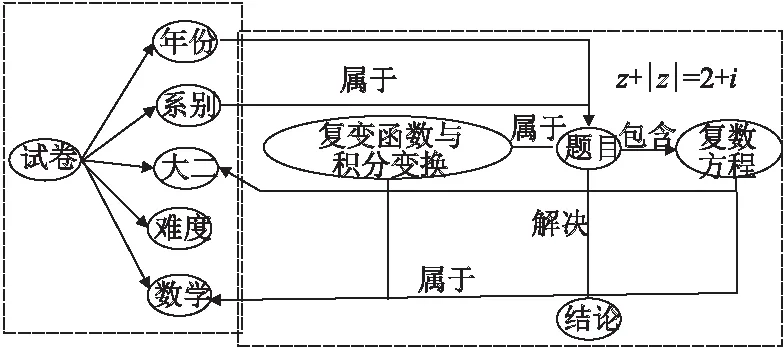
图2 知识图谱补充语义的例子Fig.2 Example of the complementary
3.2 知识图谱增强的协同过滤方法
协同过滤分析用户的兴趣,并找到与特定用户类似的其他用户,主要吸引力在于不需要任何关于用户或项目的知识,仅基于评级矩阵进行预测,其面临的核心问题是如何识别和发现特定用户群,该系统的效率取决于用户评价的质量和数量通过整合这些类似用户给出的信息评估,本文可以预测具体用户的偏好并提出建议.在协同过滤方法中,用户偏好信息和用户行为信息的统计因素很复杂,一些具有相同语义影响的因素可以重新考虑,有的因素可能具有相反的语义效应,甚至有的因素是无效的.例如,一个好学生在图书馆学习很长时间,很少去网咖玩游戏.这两个统计在语义上是互补的.当本文使用知识图谱来模拟这个学生时,本文可以用互补语义过滤这些冗余数据.在[2]中,作者提出了一个建议框架,从知识库中将协作过滤与项目的不同语义表征整合到一起.本文将常识和时间行为的统计信息并入以知识处理中心.通过检查图中结点的相关度等信息,可以发现重要的结点,删除冗余信息,从而提高遍历整个图谱的处理效率.如图3所示,本文将具有较高相关度的结点作为重要结点.如果一个结点与关键结点直接相邻,本文也将该结点当作关键结点.对于试卷推荐系统,本文考虑与考卷相关的信息,如用户的测试记录,特定用户的兴趣是不相关的因素,所以不需要考虑.

图3 关键结点的部分分类Fig.3 Partial classification of key nodes
即使结点具有高的相关度,结点也可能不具有重要的语义影响.本文通过知识图谱重组这些信息,并使用PageRank算法构建一个关键字识别机制来识别具有重要语义影响的结点[3].想象一个随机行走的人,从图4(忽略边的方向)中的任意结点开始行走,每一步,他要么以概率1-α移动到当前结点的相邻点,要么以概率α(复位参数)跳回到起始结点.如果重复足够多次,这个过程将最终给出他在每个结点中的稳态概率的近似值.步行的最终结果仅由连接结构和起始结点决定.本文根据状态概率识别关键结点.搜索引擎公司应用PageRank算法来计算实体的重要性.与传统的Web图形相比,知识图谱中的结点从单个网页转换为各种类型的实体,图的边缘从超链接变为丰富的语义关系.因为不同实体和语义关系的流行程度和提取的信息的可信度是不同的,这些因素将影响最终计算结果的重要性.

图4 通过知识图谱对协同过滤因素重组的例子Fig.4 Examples of collaborative filtering factors
3.3 通过知识图谱结合基于内容与协同过滤推荐
基于内容的方法不考虑用户的行为轨迹和偏好.基于内容的搜索和协同过滤方法给出的的推荐的准确性和效率的发展趋势是不同的,不能随意地将这两种方法组合起来使用.本文建议通过引入知识图作为媒体层来组合基于内容的搜索和协同过滤方法.知识图谱数据的基于图形的性质使得与其他图谱的链接成为可能,从而可以轻松集成多种信息,并提高信息的完整性.通过遍历图谱,在计算推荐列表时发现和利用项目和用户之间的新的联系和共同点.本文在基于知识图谱的对比架构下来检查协同过滤的合理性,利用协同过滤以统计数据的形式说明上下文信息和时间轨迹信息,提高利用知识图谱增强内容搜索功能的有效性.协作信息被视为内容特征空间的附加特征,并且在该增强空间上使用基于内容的技术.通过在知识图谱以结点的形式来构建特征项,并且利用协作特征来丰富特征向量,使用这些数据来支持基于内容的推荐引擎.在试卷推荐系统中,本文通过知识图谱分别对试卷和用户进行了建模,确定二者之间的联系,并根据他们的关系结合起来.

图5 结合基于内容和协同过滤推荐方法Fig.5 Combining content based and collaborative
在图5中,如果用户输入的检索词是"海南"和"大学英语1",无法确定向该用户推荐海南某所大学的试卷.通过用户偏好信息和行为轨迹信息,可以知道该用户参加了海南大学高等数学期末考试,是海南大学的学生.那么推荐他海南大学的大学英语1试卷是合理的.此外,通过寻找类似的用户,本文可以根据类似用户的浏览记录,例如试卷答案,推荐用户更多可能感兴趣的项目.本文用逻辑谓语E表示实体,用逻辑谓语Lbl(E, L)表示标签,其中实体E包含了标签L.他们的关系由逻辑谓语Rel(E1, E2, R)表示,其中R表示实体E1和E2的关系,例如R(E1, E2),按公式(1)计算不同实体之间的相似度(Sim(E1,E2)):
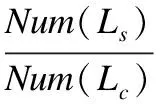
(1)
其中Lc表示E1和E2的公共标签,Ls表示具有相同信息的标签.
综上所述,Netrin-1联合Kim-1对新生儿窒息后AKI风险预测效果比较理想,敏感度、特异度高,有利于及时发现AKI,有针对性地调整治疗方案,改善预后,降低死亡率。
4 推荐系统
本文通过基于内容的方法向用户推荐与他/她测试过的试卷或搜索的信息相关的试卷,通过协同过滤方法向用户推荐和他做过相似测试的用户的试卷.图6展示了基于知识图谱的测试推荐系统,并根据MapReduce模型应用于云端.测试推荐系统的步骤如下:

图6 推荐系统框架Fig.6 Recommendation system framework
1)用户通过向测试推荐系统发送请求获得建议.当用户登录时,该请求将被激活.
2)测试推荐系统创建MapReduce进程,并从知识图谱上获取知识.
3)知识图谱将知识返回测试推荐系统.
4)MapReduce进程的资源在获取知识图谱数据后准备,并且测试推荐系统客户端将MapReduce作业提交给MapReduce模型中的主结点.
5)工作结点在主结点的控制下运行并执行Reduce操作.MapReduce将结果返回到推荐系统.
6)测试推荐系统为用户提供推荐的试卷.
5 基于知识图谱的云端测试推荐
为了减少延时,本文提出云端推荐系统MapReduce模型,如图7所示,有一个主结点是作业跟踪器,五个工作结点是任务跟踪器.主结点初始化作业并将作业分配给工作结点.同时,主结点与工作结点保持通信,管理工作结点中作业的运行,工作结点执行映射和Reduce操作.基于内容的测试推荐系统和协同过滤测试推荐系统在客户机中运行,创建MapReduce作业,并在作业客户端中运行.作业客户端从主结点获取作业ID,并从知识图谱系统获取作业资源.然后作业客户端将作业提交到主结点.知识图谱数据拆分为4个部分.在工作结点0中运行的映射操作涉及第0部分和第2部分.在工作结点1中运行的映射操作涉及第1部分,在工作结点2中运行的映射操作涉及第3部分.工作结点0,1和2将写入日期在地图操作后的本地磁盘上.减少在工作结点3和4中运行的操作将读取工作结点0,1和2上的中间日期.Reduce操作将输出缩减的数据.在Reduce操作后,测试推荐系统将使用输出数据作为推荐.例如,基于内容的推荐系统创建MapReduce作业,以找到与试卷1最相似的试卷.由内容考试推荐系统和协同过滤检查推荐系统创建的MapReduce作业可以在MapReduce模型中并行执行.执行作业的步骤如下:
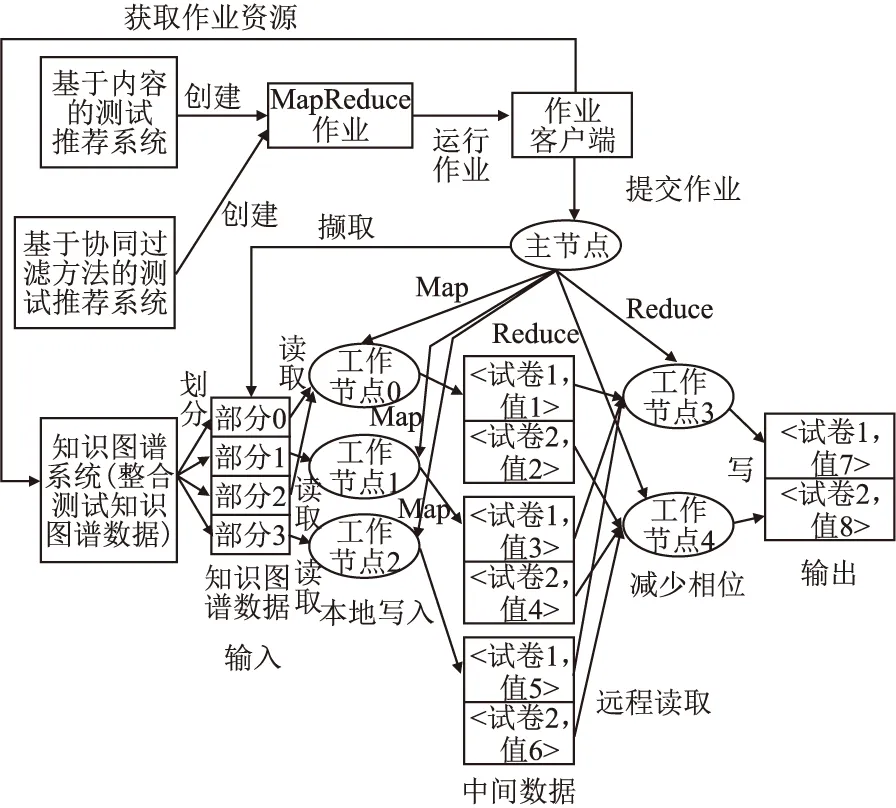
图7 云端推荐系统的MapReduce模型Fig.7 MapReduce model of cloud recommendation system
1)基于内容的测试推荐系统创建MapReduce作业并在作业客户端执行作业.
2)作业客户端从主结点获取作业ID,并从知识图谱系统获取所需的资源.然后作业客户端将作业提交到主结点.
3)主结点分配映射操作和Reduce操作到工作结点,中间数据如图7所示.
4)工作结点运行映射操作,结果将写入本地磁盘. 试卷1是关键.值1表示纸张1和纸张之间的相似度.例如,值1 = {"试卷3","0.8"}.这意味着试卷1和试卷3之间的相似性为0.8.
5)工作结点执行Reduce操作并输出结果.例如,在Reduce操作后,本文得到与试卷1相似度最高的试卷7,然后值7 = {"试卷7","1"}.
6)输出结果可用于测试推荐系统中的推荐文件.

图8 推荐准确性和时间延迟的比较Fig.8 Comparison of recommended accuracy and time delay
本文根据Web爬虫收集的数据集来验证本文的方法,分别存储在知识图数据库(Neo4J)和通用数据库(MySQL)中,对于每个实验,本文从5000篇试卷中随机抽取了一些试卷,使用不同的推荐方法来确定推荐10篇试卷的准确性和时间延迟,比较前k条推荐信息的质量,其中k是推荐列表的长度.与传统的基于内容的方法相比,本文通过知识图谱增强的方法可以在短时间内提供更准确的建议.在精确度差异较小的情况下,通过知识图谱增强的协同过滤时间延迟小于传统方法.在数据较少的情况下,基于内容的方法具有较高的准确性,但随着数据量的增加,协同过滤方法显示出更好的准确性和效率.本文的方法也符合这一趋势,实验结果如图8所示.
6 相关工作
推荐系统是提供用户感兴趣的东西的软件工具或其他技术[4-7].例如,图书推荐系统,化妆品推荐系统[8],购物推荐系统[9],英语学习推荐系统[10],基于对现有知识图谱概念的拓展,可将知识图谱划分为数据图谱、信息图谱、知识图谱和智慧图谱[11],并可应用于回答与5W相关的问题[12].20世纪90年代开始,推荐系统成为了一个独立的研究领域[13].Netflix的一个团队首次提高了其推荐系统的性能[14].推荐方法包含基于内容的方法[15],协同过滤方法[16-18],混合方法[19],基于知识的方法[20],协同过滤方法可解决冷启动问题[21].知识图谱旨在提取不同实体之间的关系.它可以找到新的关系事实,这是对从知识来源提取的关系的重要补充[22-24].分布式计算系统是一种编程模型,也是用于处理和生成大型数据集的相关手段[25].分布式计算系统编程模型简化了许多数据并行的应用的实现手段[26].
7 结 论
本文提出将知识图谱引入到非结构化语义信息中来改进搜索效率和目标有效性,语义知识丰富了基于内容的搜索,增强了所推荐内容的正确性,降低了计算复杂度.本文将统计常识和时间行为序列中的数据、信息和知识,纳入以知识图谱为资源处理框架的处理中,融合基于内容的推荐方法和协同过滤方法的优势,知识图谱的引入突破了顺序组合限制,并且允许重复地执行属于基于内容或协同过滤方法的中间活动,同时容纳多方共享信息.本文还提出MapReduce云端测试推荐模型,以应对知识图谱数据的快速增长.下一阶段本文将继续探索这种并行性在特定云环境中的潜在可能和自动生成处理语义丰富的知识图谱的技术.
