一种HEVC帧内编码快速决策组合算法
2019-01-24易清明谢志煌
易清明,谢志煌,石 敏
(暨南大学 信息科学技术学院,广州 510632)
1 引 言
由视频编码联合组(JCT-VC)制定的最新视频编码标准——高效视频编码H.265/HEVC(HEVC,high efficiency video coding)[1]致力于提高视频压缩性能,与当前普及的高级视频编码标准H.264/AVC(AVC,Advanced Video Coding)相比,节省了大约50%的码率.HEVC引用四叉树结构概念对图像进行划分成编码树单元(CTU,coding tree unit),如图1所示,最大编码单元(LCU,largest coding unit)大小为64×64,最小编码单元(SCU,smallest coding unit)大小为8×8.同时,HEVC将帧内预测模式从H.264/AVC的9种扩大到了35种,包括33种角度预测模式、DC模式和Planar模式[2].四叉树结构的灵活划分编码单元和众多的预测模式不仅显著提升了压缩效率,同时大幅增加了计算复杂度,不利于实时应用.因此,降低HEVC的编码复杂度是近几年的研究热点.
在帧内编码过程中,一个LCU最终划分结构的确定,需要依次从深度0到深度3的全部遍历计算,即1+4+4×4+4×4×4=85 个CU的预测过程.而预测过程中,每一个PU包括向下继续划分的4×4大小PU均需要遍历35种预测模式的粗模式决策(RMD)过程,即1×35+4×35+16×35+64×35+256×35=11935次粗模式决策.接着,仍需要进行包括最可能模式(MPMs,most probable modes)在内的候选模式列表的率失真(RD)代价计算,得出最后的最优模式.
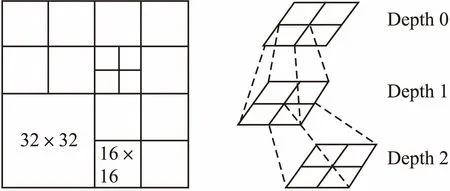
图1 CU划分结构Fig.1 CU partition structure
为了降低编码的计算复杂度,许多学者对HEVC帧内编码的快速算法进行研究.在预测模式决策方面,文献[3]提出一种基于边缘检测和根据绝对误差和(SATD,sum of absolute transformed difference)计算代价分类的算法,该算法提前减少RDO候选模式个数以达到减少编码时间.文献[4]提出一种类似于三步搜索法的方法,在RMD阶段根据原始模型计算得到的哈达玛变换代价(HAD cost,Hadamard transform based cost)逐步缩小预测模式候选列表,同样减少了遍历所有的预测模式所带来的计算复杂度.文献[5]根据相邻PU的像素值和当前PU像素值的相似度对预测模式进行筛选,虽然该算法取得不错的编码时间缩减,但对预测模式的过度排除导致率失真性能损失不小.
在编码单元大小决策方面,文献[6]通过对当前CU和向下划分的四个子CU率失真代价进行比较,决定是否终止CU继续划分.文献[7]根据纹理特征提出一种CU深度快速决策算法,纹理复杂的CU则从最大深度向最小深度反向预测,纹理平滑的CU则从最小深度从最大深度进行编码,并根据方差提前终止划分.文献[8]设计了多个纹理探测器对水平方向、垂直方向、45°方向和135°方向进行检测再与下一层的4个子编码单元进行比较决定是否终止划分或提前划分.文献[9]利用机器学习的线性支持向量机(linear-SVM)对编码单元的划分与否进行分类.文献[10]运用方差阈值法来对CU深度做决策,在进行帧内预测之前对整个CU的方差计算与阈值进行比较,直接决定CU的划分深度后再进行帧内预测.
在已有算法的基础上,本文提出一种应用于预测模式决策和编码单元大小决策的快速组合算法.在编码单元划分上,我们在每一个CU深度层都利用方差阈值法将决策划分成三种:首先对于复杂CU我们提前进行划分;接着对于平滑CU我们终止其再向下划分;而第三种即为不确定类,此类当前CU大小不能用阈值法准确判定是否终止划分或提前划分,故不做处理.完成快速划分决策的编码单元在帧内预测过程中,对角度模式和填充渐变模式进行分别处理,排除低可能性的预测模式,减少不必要的计算.
2 预测模式快速决策
HEVC编码器的帧内预测过程主要由以下三个步骤完成:第一步,粗模式决策(RMD)对所有的35种预测模式进行代价递增排序,然后根据表1选取对应个数的预测模式组成候选模式列表;第二步候选模式列表与最佳可能模式列表匹配,若最佳可能模式列表中有候选模式列表不包含的预测模式,则更新到候选模式列表中;最后一步即将更新后的候选模式列表通过RDO选出最优模式.整个过程中,最后一步的RDO计算复杂度最高.
表1 RDO候选模式数量
Table 1 Number of candidate modes in RDO

PU size64×6432×3216×168×84×4number33388
我们对帧内预测过程做了直观的时间损耗分析如表2所示,RDO的计算复杂度极高使得它占据整个预测过程超过一半的时间损耗,而RMD也占据了近乎四分之一的时间损耗,因此准确地找出PU的最佳预测模式或准确地排除低可能性的预测模式就能够有效地降低帧内预测过程的计算复杂度.本文在预测模式快速决策上设计了两个子算法,分别为角度模式快速筛选(AMFE,angular modes fast exclusion)算法和基于统计分析的概率决策(SAPD,statistical analysis based probabilistic decision)算法.
表2 帧内预测过程时间损耗占比
Table 2 Proportion of time consumption in intra prediction
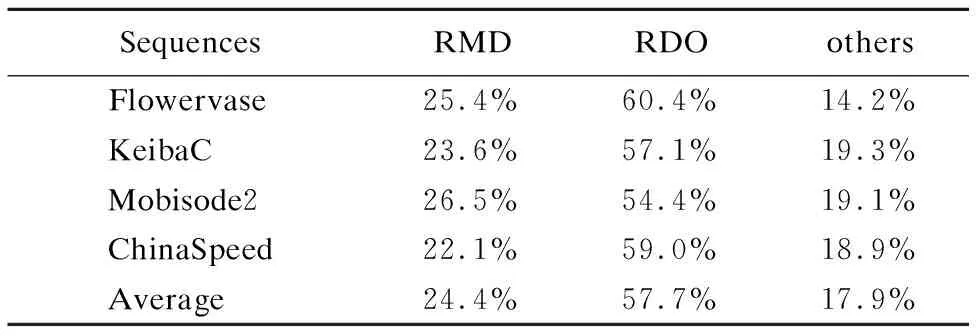
SequencesRMDRDOothersFlowervase25.4%60.4%14.2%KeibaC23.6%57.1%19.3%Mobisode226.5%54.4%19.1%ChinaSpeed22.1%59.0%18.9%Average24.4%57.7%17.9%
2.1 角度模式快速筛选
本文对角度预测模式设计了四个方向探测器,如图2所示.对于当前PU中的每个像素都进行这四个方向的检测,检测允许存在一定的像素偏移,即方向像素差小于3的均视为
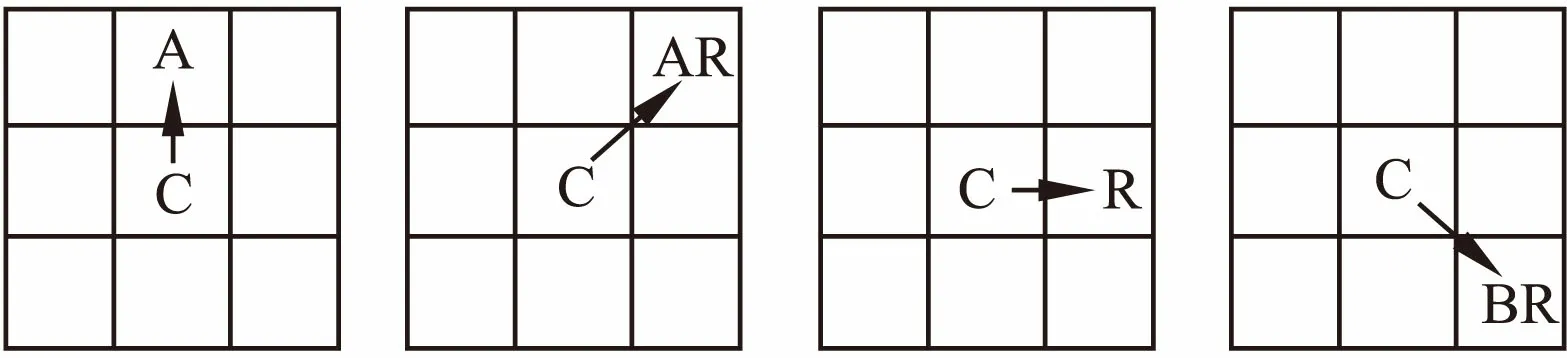
图2 四个方向探测器Fig.2 Four directional detectors
偏移像素不做处理,像素差大于等于3则视为变化像素,累加对应方向的惩罚权值(DPWs,directional penalty weights),计算如式(1)所示:

(1)
其中,pixelc为中心像素,pixeli为各方向上的像素.PU中所有像素遍历完四个方向后得到的四个惩罚权值总和即为最终的方向惩罚权值.越小的DPWs证明PU在该方向的方向特征越强,越大的DPWs表示PU在该方向的像素值变化越大,该方向的方向特征越弱.因此,我们可以根据DPWs对33种角度预测模式进行筛选,通过小于惩罚阈值的最小DPWs所检测出的方向,在RMD之前根据表3选择对应方向的角度预测模式组,降低RMD的计算复杂度.
表3 AMFE中RMD预测模式组
Table 3 Prediction modes groups for RMD in AMFE algorithm
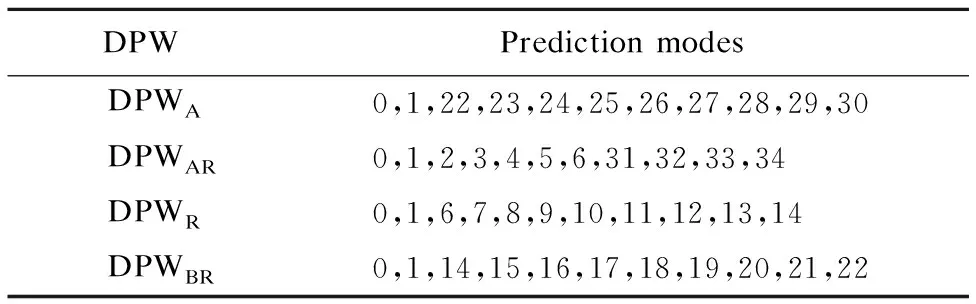
DPWPrediction modesDPWA0,1,22,23,24,25,26,27,28,29,30DPWAR0,1,2,3,4,5,6,31,32,33,34DPWR 0,1,6,7,8,9,10,11,12,13,14DPWBR0,1,14,15,16,17,18,19,20,21,22
AMFE算法用错误率来决定惩罚阈值,错误率即满足DPWs惩罚阈值编码后的PU预测模式与原始HM模型编码后的PU预测模式不匹配率.如图3所示,训练序列为Flowervase、Slideshow和BasketballDrive,分辨率分别为832×480、1280×720及1920×1080,量化参数为标准测试的22、27、32和37,测试PU大小为8×8.

图3 惩罚阈值与错误率的关系Fig.3 Relation between thresholds and wrong hit rate
从图中我们可以看出错误曲线对量化参数并不敏感,四条量化曲线几乎稳定重合,即在量化参数范围内视频纹理特征基本不改变,惩罚阈值不因量化参数改变而改变.可以看到,错误曲线在错误率5%附近处有个拐点,当阈值逐步递增时,错误率迅速增加,因此当PU大小为8×8时,平衡编码时间和编码质量后,惩罚阈值选取为14,表4给出了其余的惩罚阈值.
表4 各大小PU的惩罚阈值
Table 4 Thresholds in each size of PU

PU size64×6432×3216×168×84×4Thresholds38813643141
我们还对满足DPWs阈值条件的8×8及4×4大小的PU候选模式列表的选取率进行分析,如表5所示,因为大于8×8大小的PU候选模式均为3个,待RDO计算数量已经很少故不做处理.表5中,CandN表示候选模式列表中的第N个候选预测模式,可以看出,两种大小PU的前3个候选模式成为最优模式的概率总和均超过95%,更新MPM后的概率总和分别达到了96.7%和98%.故将候选模式列表中的候选模式从8个缩减到3个后并更新MPM,不仅保证了预测准确率,也大大降低了RDO过程的计算时间.
表5 候选模式成为最优模式的概率
Table 5 Proportions of each candidate mode being selected as the best mode

SizeCand0Cand1Cand2Cand3Cand4MPM8×880.3%11.0%4.0%1.2%0.8%1.4%4×489.2%6.2%1.8%0.6%0.4%0.8%
2.2 基于统计的概率决策
本文对不满足AMFE算法的PU,进行原始HM编码器的RMD过程后得到原始的候选模式列表.根据候选模式列表与最优模式统计发现,若候选模式列表中的前三模式包含DC、Planar和垂直模式(模式26)中任意两个,则这三个模式成为该PU最优模式的概率远高于其他模式.表6统计了所有PU各种大小中满足该特定条件且这三个预测模式最终被选取为最优模式的概率.
表6 特定条件下三个预测模式成为最优模式的概率
Table 6 Three candidates under specified condition being selected as the best mode
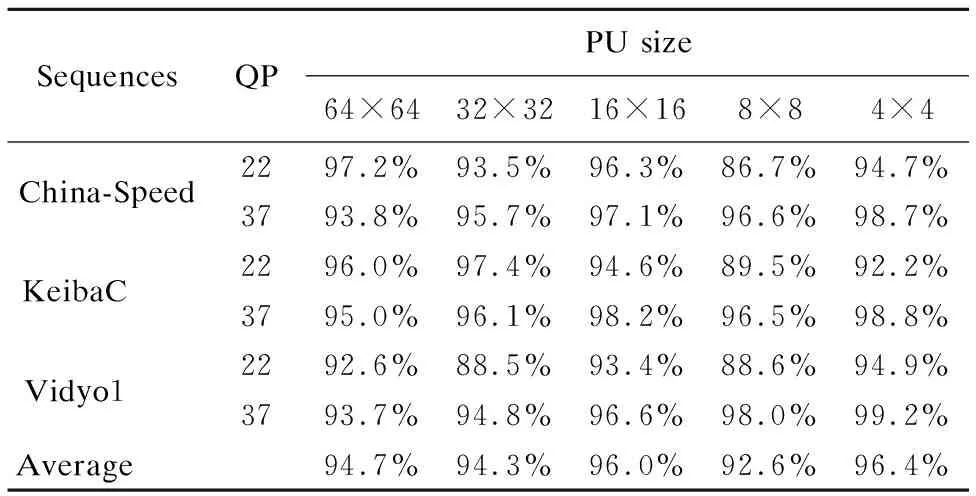
SequencesQPPU size64×6432×3216×168×84×4China-Speed2297.2%93.5%96.3%86.7%94.7%3793.8%95.7%97.1%96.6%98.7%KeibaC 2296.0%97.4%94.6%89.5%92.2%3795.0%96.1%98.2%96.5%98.8%Vidyo1 2292.6%88.5%93.4%88.6%94.9%3793.7%94.8%96.6%98.0%99.2%Average 94.7%94.3%96.0%92.6%96.4%
测试视频序列为ChinaSpeed、KeibaC及Vidyo1,视频内容包含均等的纹理复杂和纹理简单区域,量化参数为22和37.从表6我们可知,最低准确率为8×8大小PU的92.6%,最高准确率为4×4大小PU的96.4%,总平均准确率约为95%.以上数据表明,该特定条件在纹理复杂与简单视频序列、不同量化参数下都拥有较高的准确率.故满足此特定条件的PU可以只选取这三种预测模式组成候选列表,有效减少候选模式数量,为后续的率失真代价计算节省时间.
同时,为了验证此类条件并非极少情况,本文还测试了各视频序列及各大小PU满足此条件的占比如表7所示,该百分比为满足SAPD的PU在视频序列中所有相同大小PU的比例.如表所示,总平均比例为26.1%,表示超过四分之一的所有大小PU均能用SAPD进行快速筛选.最低比例为32×32大小的PU,平均所占比例为18.2%,接近五分之一.最高比例为4×4大小PU的37.4%,即所有4×4大小的PU中超过三分之一的PU包含该三种模式种的任意两种,且由表6可知这三种预测模式拥有高达96.4%的概率成为最优模式.
表7 SAPD在所有PU中的比例
Table 7 Ratios of PUs meeting SAPD at all size
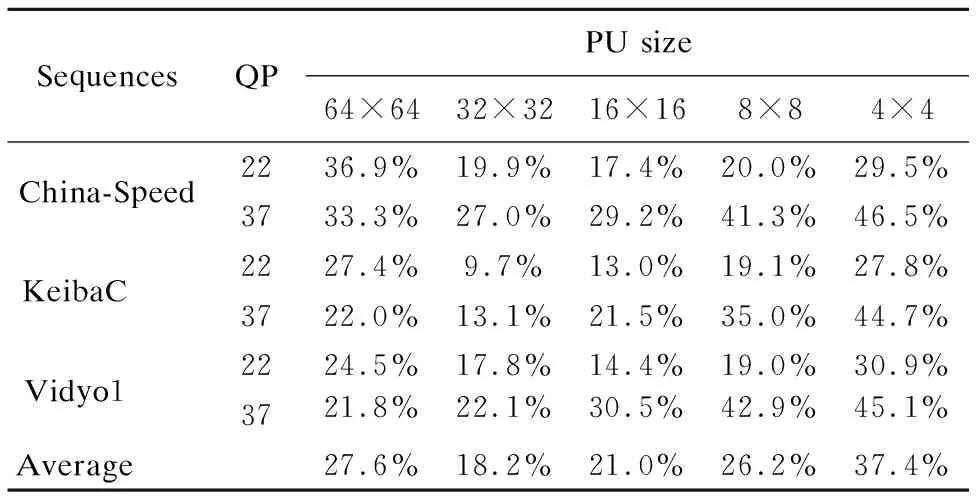
SequencesQPPU size64×6432×3216×168×84×4China-Speed2236.9%19.9%17.4%20.0%29.5%3733.3%27.0%29.2%41.3%46.5%KeibaC 2227.4%9.7%13.0%19.1%27.8%3722.0%13.1%21.5%35.0%44.7%Vidyo1 2224.5%17.8%14.4%19.0%30.9%3721.8%22.1%30.5%42.9%45.1%Average 27.6%18.2%21.0%26.2%37.4%
2.3 预测模式快速决策算法流程
以上对帧内预测模式快速决策的AMFE算法和SAPD算法做了详细的分析,整合后的预测模式快速决策算法具体步骤如下:
1)获取PU内所有的亮度像素信息;
2)运用四个方向探测器对PU进行方向检测得到四个DPWs与惩罚阈值进行比较,判断纹理特征的强弱;
3)若方向纹理特征较强,执行AMFE算法,根据表3选取对应的预测模式组,通过RMD过程得到候选模式列表,并根据PU尺寸大小对候选模式数量自适应缩减,跳过步骤4、5.若纹理特征较弱则执行步骤4;
4)PU进入原始RMD过程得到候选模式列表,对原始候选模式列表进行检测.若满足SAPD特定条件,则执行SAPD算法后跳过步骤5.若不满足条件则进入步骤5;
5)执行原始HM编码器对PU进行帧内预测.
3 编码单元大小快速决策
HEVC帧内编码中,CTU的划分和编码单元内的纹理复杂度有着紧密的联系,编码单元CU从最大尺寸64×64到最小尺寸8×8共有四层深度的划分.大尺寸的CU适用于纹理较为简单和平坦的区域,纹理复杂的区域由小尺寸的CU编码则更为精确.图4给出了原始HM模型帧内编码后的CTU划分结构,编码视频序列为Johnny,量化参数为37,如图,纯色简单背景区域均由大尺寸编码单元直接编码,而有方向信息且多变的区域则划分为小尺寸编码单元再编码.
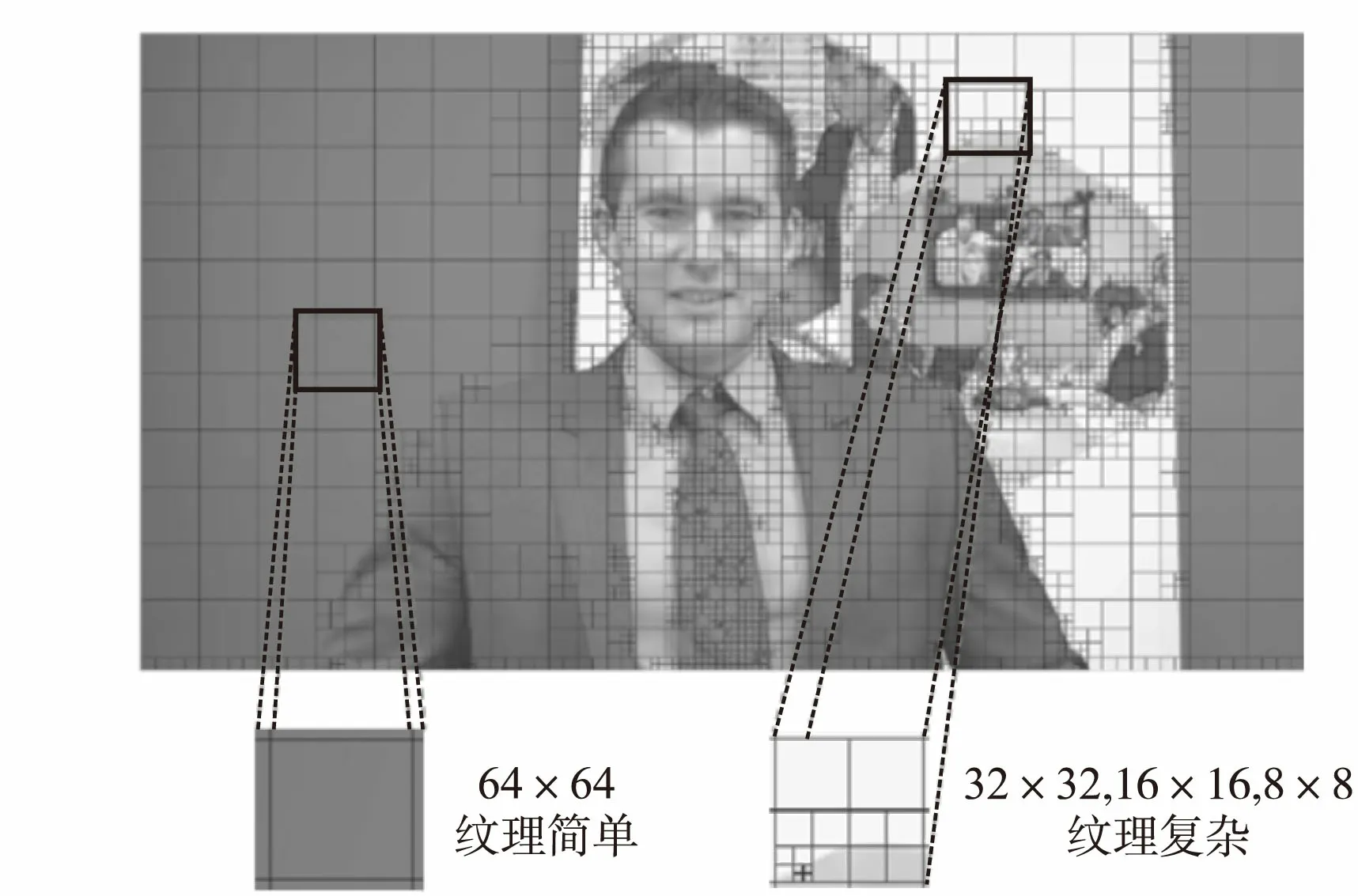
图4 Johnny的CTU划分结构Fig.4 CTU partition structures of Johnny
文献[7]、文献[10]和文献[11]均用方差或标准差来衡量编码单元的纹理复杂度,文献[10]用整个CU的方差与单一阈值比较,从而直接决定CU的划分深度,但单一的阈值缺乏对各层CU纹理复杂度的考虑和整体方差不能准确表征局部信息,导致该算法虽然减少了编码时间,但也带来了大量的比特率增长,其他算法均有类似问题.为此本文提出根据水平和垂直方向的方差求解对CU的纹理复杂度进行更准确的判定,如图5所示.
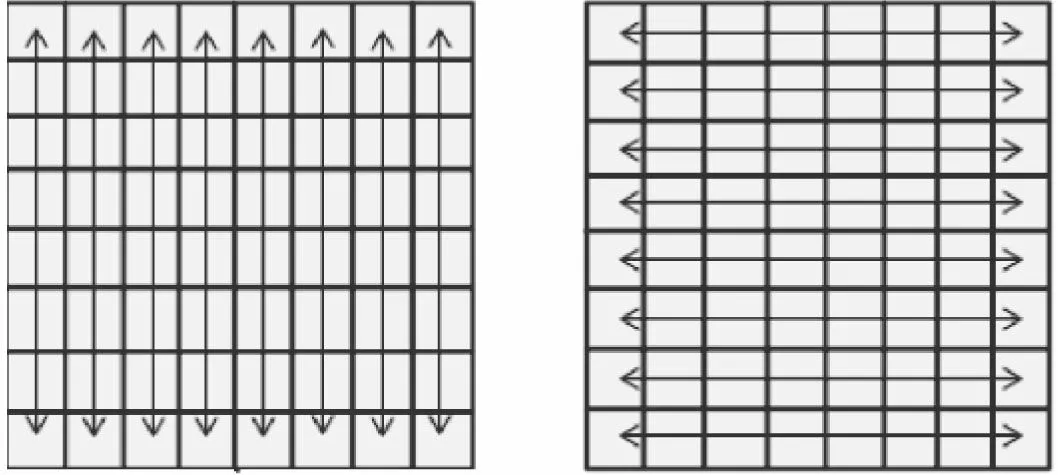
图5 CU纹理计算方式Fig.5 Method of textural calculation in CU
如图5对当前深度的CU计算对应的方差,若该深度的CU纹理简单,则其无论是水平方向还是垂直方向的纹理都十分平坦,即水平和垂直方向的方差都应较小.若该深度的CU纹理较为复杂,则水平或垂直方向至少存在一个方差较大的情况.水平与垂直方差均值具体计算如式(2):
(2)
式(2)中,VARHor为水平方向的方差均值,VARVer为垂直方向的方差均值,mean(pixeli,:)为某行或某列的像素均值.当VARHor和VARVer都小于终止方差均值阈值时,表示当前CU的纹理比较简单,直接用当前尺寸大小的编码单元进行预测编码,终止其向下划分的过程;当VARHor和VARVer都大于划分方差均值阈值时,表示当前CU的纹理比较复杂,该大小的编码单元不能够精确地预测编码,则可以跳过预测过程直接向下划分得到四个子CU,子CU再判定是否进行预测过程或继续划分;而VARHor和VARVer不满足上述两个阈值的情况均为不确定类,采用原始HM编码器流程进行编码.
我们利用李天一等学者所建立的CPIH数据库[12](CPIH database,CTU Partition of Intra-mode HEVC database)对方差均值阈值进行测试选定.CPIH数据库从原始图像数据集(RAISE,Raw Images Dataset)中挑选2000幅分辨率为4928×3264的图片后下采样均等分成3个子集合,分辨率分别为2880×1920、1536×1024和768×512,且每一帧均由原始HM编码器用标准帧内编码参数进行编码.因为数据库中的每一幅图片的前后帧都是独立的原始图片,所以在数据集上没有时域上的相关性,能够最大化数据在帧内编码中的测试与训练作用.
JCT-VC给出原始HM模型测试的视频序列里,分辨率最小为D类的416×240,最大为A类的2560×1600,故本文选定测试样本集为更符合分辨率范围的3个子数据集,测试样本的量化参数为22、27、32及37.我们对每一层深度的CU对应4个量化参数分别从3个测试样本集中随机选取40000个CU测试样本.例如,当CU深度为0时,量化参数为37,则分别从2880×1920、1536×1024和768×512选取由原始HM编码器编码后带有是否向下继续划分标签的40000个量化参数为37、64×64大小的CU测试样本,共120000个CU测试样本.终止和划分的方差均值阈值测试结果最终的选取主要权衡准确率与总数比例,各大小编码单元的阈值在不同量化参数下的选取如图6所示.从图中可以看出32×32与16×16的参数曲线更为接近,在大部分64×64编码单元的划分决策中,更多决策为提前划分,主要是因为64×64包含的视频内容更丰富,而单一的预测模式不能很好地对当前区域的视频内容进行预测.
4 实验结果与分析
本文的算法实验以原始参考模型HM16.0为平台,配置文件为all-intra-main,量化参数为22、27、32和37,测试视频为官方推荐视频序列,测试范围为A类到E类全部.实验平台的硬件配置为Intel(R)-Core(TM)i5-4590 CPU,主频为3.30GHz,内存为8.00GB.
实验编码性能用比特率变化百分比ΔBR、推荐的比特率变化率BDBR[13]、峰值信噪比变化BDPSNR[13]及编码时间减少百分比TS来衡量.其中,ΔBR按式(3)计算得到,TS按式(4)计算得到,式中BRprop、Tprop为本文提出的快速算法编码后的比特率和编码时间;BRHM、THM为原始HM16.0编码后的比特率和编码时间.
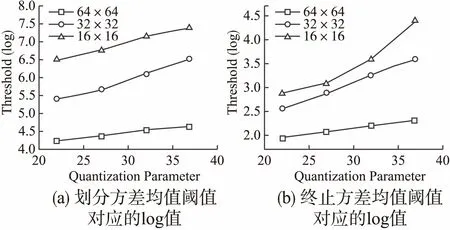
图6 各量化参数下的方差均值阈值Fig.6 Thresholds of Var-Mean in different QPs
(3)
(4)
表8给出了本文总体算法、预测模式决策算法和编码单元大小决策算法在四个量化参数下的编码性能结果,从表中可以看出,本文总体算法与原始HM标准算法相比在编码时间上平均节省38.0%,且BDBR仅有0.33%的增加.E类视频序列中存在较多的纹理简单区域,例如Johnny和KristenAndSara的视频内容里拥有大量单一纯色的背景,这些区域可以直接终止大尺寸编码单元的向下继续划分跳过不必要的预测计算,所以在编码单元大小决策优化上,E类的优化时间平均为44.3%远高于其他类.单一的纹理特征使得预测模式优化算法能够快速找到最优模式,除E类的纯色背景外,超高分辨率的A类视频序列里中清晰的斑马线、交通信号牌与地面标识都为算法的优化对象.而BlowingBubbles和PartyScene等视频内容的细节信息丰富、纹理较为复杂,需要向下划分得到更多的子编码单元用更多的模式来精确预测,所以节省的编码时间也最少.表9给出了本文总体算法与其他文献在帧内编码快速算法上的比较,编码条件均标准测试参数,编码性能用BDBR和TS进行衡量.
表8 实验结果
Table 8 Experimental results
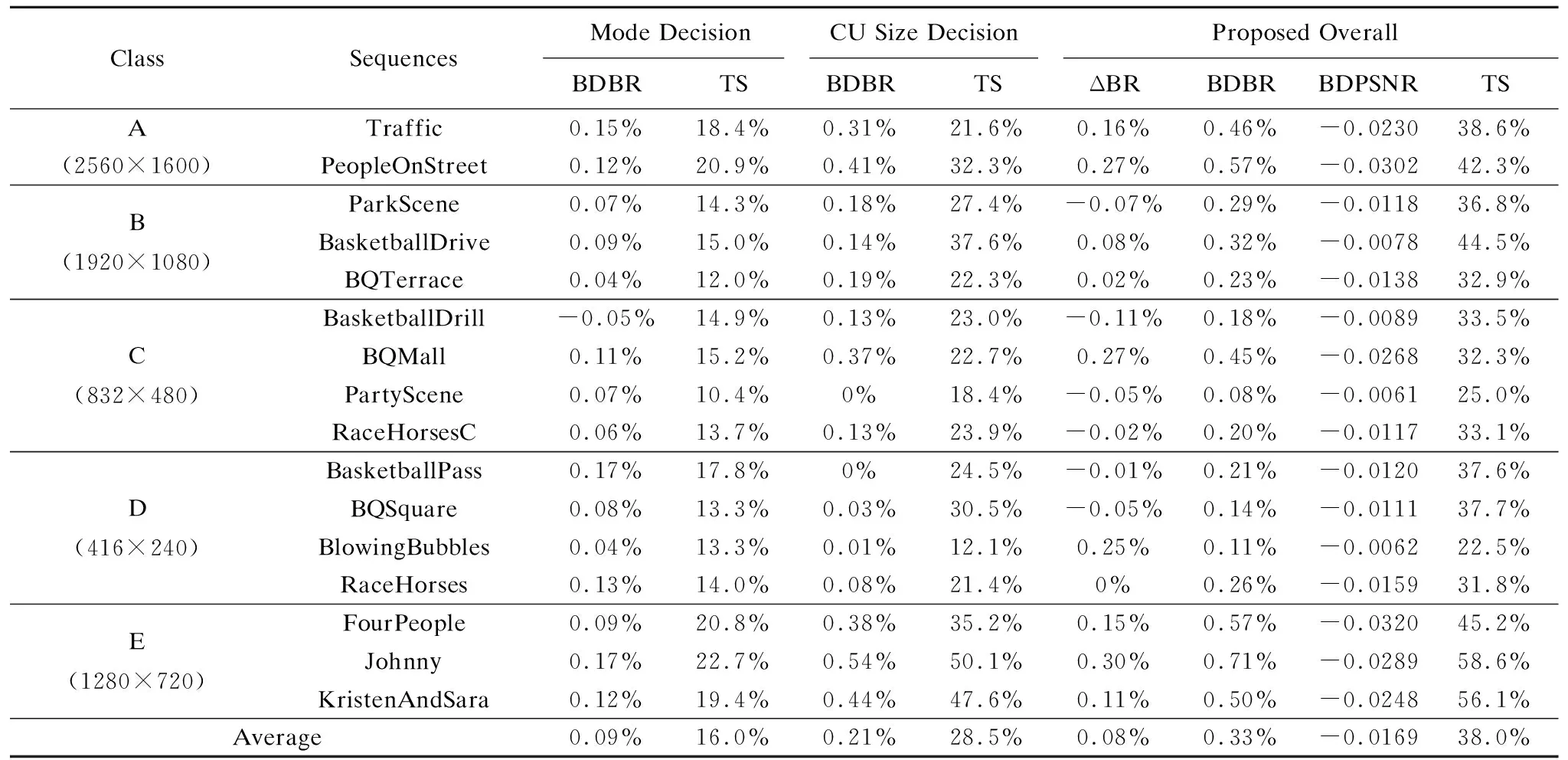
ClassSequencesMode DecisionCU Size DecisionProposed OverallBDBRTSBDBRTSΔBRBDBRBDPSNRTSATraffic0.15%18.4%0.31%21.6%0.16%0.46%-0.023038.6%(2560×1600)PeopleOnStreet0.12%20.9%0.41%32.3%0.27%0.57%-0.030242.3%B(1920×1080)ParkScene0.07%14.3%0.18%27.4%-0.07%0.29%-0.011836.8%BasketballDrive0.09%15.0%0.14%37.6%0.08%0.32%-0.007844.5%BQTerrace0.04%12.0%0.19%22.3%0.02%0.23%-0.013832.9%C(832×480)BasketballDrill-0.05%14.9%0.13%23.0%-0.11%0.18%-0.008933.5%BQMall0.11%15.2%0.37%22.7%0.27%0.45%-0.026832.3%PartyScene0.07%10.4%0%18.4%-0.05%0.08%-0.006125.0%RaceHorsesC0.06%13.7%0.13%23.9%-0.02%0.20%-0.011733.1%D(416×240)BasketballPass0.17%17.8%0%24.5%-0.01%0.21%-0.012037.6%BQSquare0.08%13.3%0.03%30.5%-0.05%0.14%-0.011137.7%BlowingBubbles0.04%13.3%0.01%12.1%0.25%0.11%-0.006222.5%RaceHorses0.13%14.0%0.08%21.4%0%0.26%-0.015931.8%E(1280×720)FourPeople0.09%20.8%0.38%35.2%0.15%0.57%-0.032045.2%Johnny0.17%22.7%0.54%50.1%0.30%0.71%-0.028958.6%KristenAndSara0.12%19.4%0.44%47.6%0.11%0.50%-0.024856.1%Average0.09%16.0%0.21%28.5%0.08%0.33%-0.016938.0%
表9 本文算法与其他算法的比较
Table 9 Comparisons between our method and others
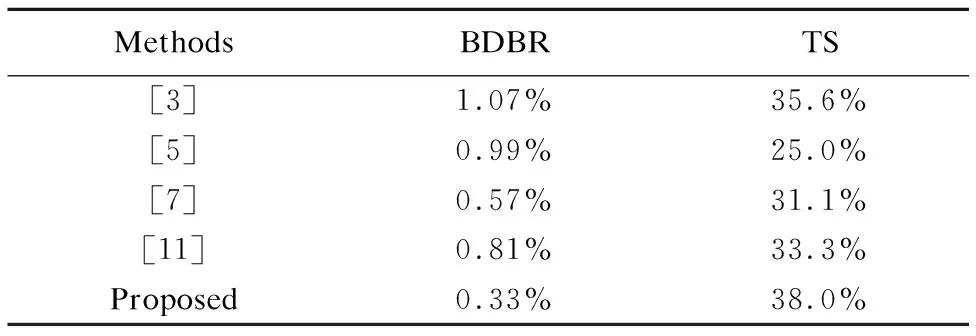
MethodsBDBRTS[3]1.07%35.6%[5]0.99%25.0%[7]0.57%31.1%[11]0.81%33.3%Proposed0.33%38.0%
从表中我们可以看出,本文算法在BDBR和TS都优于其他算法,编码节省时间与我们最接近的是文献[3]和文献[11]的算法,但两种算法在BDBR上都由较大的丢失.通过表9对比表明,本文算法在所有视频类的平均优化性能指标都比其他算法要好,即具有广泛适用性.表10给出了本文算法与其他优秀算法在高清及超清视频序列中性能表现的详细对比,除用BDBR及TS进行对比外,为了公平地评价优化算法的编码性能,我们引入评价参数(BDBR/TS×100)[14].该评价参数反映了编码复杂度和BDBR直接的关系,算法性能越优秀,参数值越小.
文献[15]与文献[16]均在预测模式决策和编码单元大小决策上做优化,三种算法在超清及高清视频的编码时间上均有较大的优化.文献[16]与本文在编码时间节省上的性能表现与本文相差无几,而BDBR却高出了0.31%之多.而文献[15]虽然在平均TS上比本文算法高出11.6%,但平均BDBR近乎是本文算法的三倍,编码质量损失较大.由前文可知,E类视频序列中存在大量纹理简单背景,优化算法可以大大缩短编码时间,但不准确的判断会导致BDBR的急剧上升与编码质量的下降.通过E类序列的编码性能比较可知,本文算法的TS略高于文献[16],低于文献[15],但文献[15]的E类序列的平均BDBR为1.84%,大于本文算法0.59%的三倍之多,证明本文算法比文献[15]与文献[16]能更准确地找到最适合的编码单元划分与最佳预测模式.因为本文算法在编码单元的决策上严格的筛选和预测模式上高准确率的选择,让编码过程减少对模糊部分做出错误判断.
表10 本文算法与其他算法在高清及超清视频序列 上的编码性能比较
Table 10 Performance comparisons between ourmethod and others in HD and UHD videos
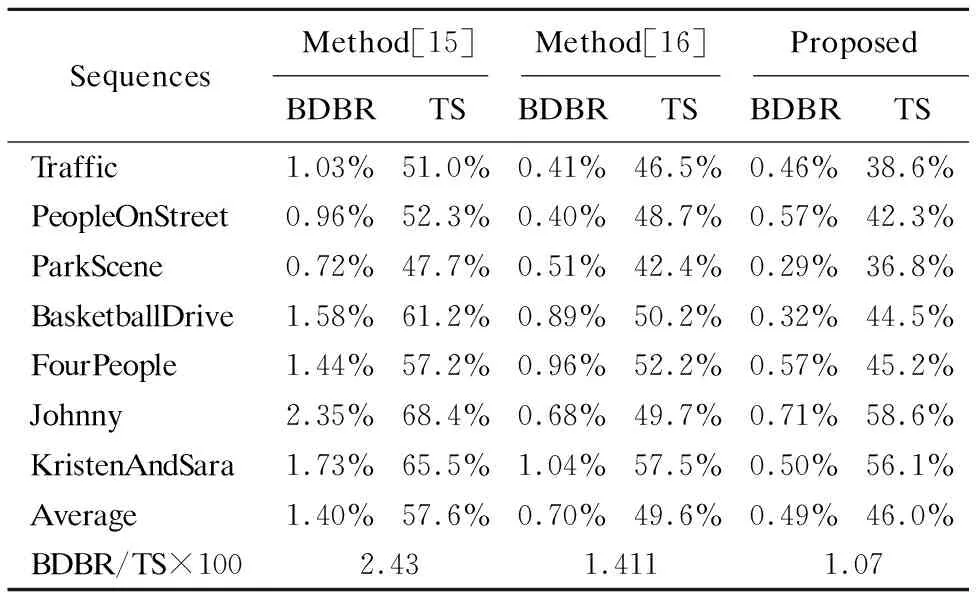
SequencesMethod[15]Method[16]ProposedBDBRTSBDBRTSBDBRTSTraffic1.03%51.0%0.41%46.5%0.46%38.6%PeopleOnStreet0.96%52.3%0.40%48.7%0.57%42.3%ParkScene0.72%47.7%0.51%42.4%0.29%36.8%BasketballDrive1.58%61.2%0.89%50.2%0.32%44.5%FourPeople1.44%57.2%0.96%52.2%0.57%45.2%Johnny2.35%68.4%0.68%49.7%0.71%58.6%KristenAndSara1.73%65.5%1.04%57.5%0.50%56.1%Average1.40%57.6%0.70%49.6%0.49%46.0%BDBR/TS×1002.431.4111.07
在BDBR/TS×100这项评价参数的对比上,本文算法平均仅有1.07,为三种算法最低,表明编码性能更优秀,即本文算法在拥有同等的编码时间优化能力情况下,具有更优秀的编码质量.
5 总 结
为了降低HEVC帧内编码的计算复杂度,本文提出了一种帧内编码快速决策组合算法,包括对预测模式的快速选择算法和编码单元大小的快速决策算法.在预测模式选择上,本文设计了四个方向探测器和应用数据统计分析,分别减少RMD和RDO的候选模式数量,减少两个过程的计算复杂度.在编码单元大小决策方面,本文对纹理复杂度进行分析,根据方差均值对编码单元划分决策进行分类,方差均值阈值则由编码单元数据库权衡准确率和占比测试得出.实验结果表明,本文算法与HM 16.0相比,在保证编码性能几乎无损失的情况下,帧内编码时间平均减少38.0%.
