基于人工智能的智能交通系统设计①
2019-01-22辛淏炎
辛淏炎

摘 要:本文详细介绍了基于人工智能的智能交通系统的系统设计,以及该系统所运用的核心算法。该智能交通系统分为鸣笛声检测定位系统、车牌号识别系统、用户系统三大模块,可实现准确定位鸣笛车辆,识别鸣笛车辆车牌信息,以及能够及时将用户违章信息上传至数据库,同时告知用户违章信息。该系统可帮助交通部门提高执法精确度,节省人力物力和财力,同时也使环境噪声污染得到有效的控制。
关键词:鸣笛声识别 声源定位 图像识别 智能交通 人工智能
中图分类号:TP18 文献标识码:A 文章编号:1674-098X(2019)09(a)-0099-04
1 引言
人们日常出行首选的交通工具便是汽车了,在这个家家户户都有车的时代,汽车带来的环境噪声污染问题也不可忽视。环境噪声对人类的危害不仅体现在对听力系统的损害,还可能使人类烦恼、易怒、激动,严重者则产生精神错乱。噪声控制被我国列为环境保护的重点,国家方面也出台了相关法律法规,禁止机动车辆在禁止鸣笛的区域或者路段鸣笛。由于噪声的特点,噪声源一旦停止发声,噪声就会消失,这给工作人员监测车辆鸣笛增加了很大的难度。因此,一系列先进的科学技术研究被应用于提高噪声污染防治的工作中。本文基于人工智能设计出了一套功能完善的智能交通系统并应用到鸣笛车辆治理的场景中,其功能表现为可以准确定位鸣笛的车辆随后识别出车牌号。该智能交通系统提高了执法准确度,使交通部门的管理得到加强,同时也减少了人力物力与财力。
本文所阐述的智能交通系统主要涉及基于麦克风阵列的鸣笛声源定位以及车牌号识别两大主要技术。常用的基于麦克风阵列的鸣笛声源定位方法有以下四种[1-2]:基于最大输出功率的可控波束形成法、高分辨率谱估计法、基于到达时间差(TDOA)的声源定位法和基于卷积神经网络的声源定位法。基于最大输出功率的可控波束形成法的基本思想是,设置一个麦克风阵列,用来接收所有声源假定位置处的声源信号,将接收到的信号进行加权求和,所得值最大的位置即为声源的预测位置。高分辨率谱估计法利用麦克风阵列接收信号之间的相关矩阵来确定方向角,从而达到定位目标声源的目的。但以上提到的两个算法计算量均较大,较难满足本文构建的智能交通系统对于实时性的要求。基于到达时间差(TDOA)的声源定位法主要思想是将同声源信号到达不同麦克风的时间差求出即时间延迟估计,已知声音传播的速度,可将时间差轻易转化为声程差,进而结合麦克风阵列中麦克风的位置通过几何法或者搜索法定位目标声源。基于深度神经网络的声源定位法将声源可能存在的空间按一定的角度平均分为若干个区域,输入声音的相位谱和幅度谱计算出每个区域内声源存在的概率,输出概率最大的区域即可定位目标声源。车牌号识别则主要涉及对鸣笛车辆图像进行预处理、对车牌区域进行定位与分割,最后对分割的字符进行识别。传统的车牌定位方法将数学形态学进行的粗定位与投影法进行的细定位结果相结合,并运用Hough变换解决水平区域存在夹角的问题[10],以便后续进一步分割。基于模板的车牌分割法和基于投影的车牌分割法是目前较为传统的两种车牌分割方法。但由于实际捕捉到的车牌图像状态十分复杂,极易存在车牌扭曲的情况,以上两种方法在该情况下分割效果不是特别理想。由于在使用以上两种方法进行车牌分割之前首先要对车牌首字符进行定位,若该定位存在偏差,將会对分割效果产生很大的影响[3]。分割效果相对较好的是基于投影和先验知识的车牌分割法,同时也解决了首字符的准确定位问题[3]。基于神经网络的字符识别算法依据我国车牌特点,分别建立汉字神经网络、字母神经网络和字母数字神经网络对系统进行训练,通过增加动量提高系统的学习速率,从而减少系统的学习时间,实现对分割后的车牌进行精准的字符识别[13]。
本文将主要阐述该智能交通系统的设计,系统各个模块之间的联系,以及系统功能实现的核心算法。
2 智能交通系统设计
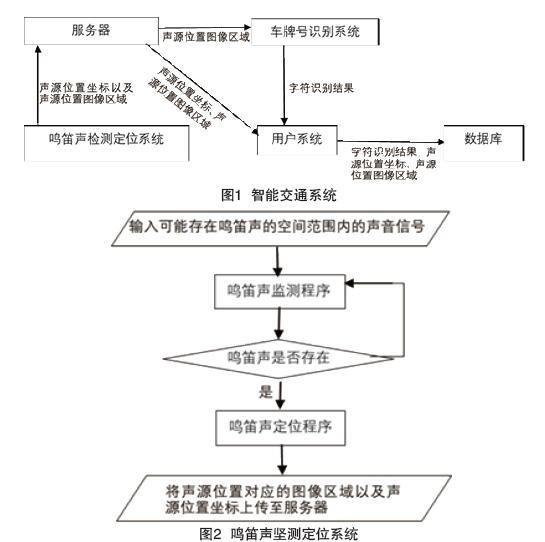
该智能交通系统包括鸣笛声监测定位系统、车牌号识别系统和用户系统三个子系统。其子系统之间的联系示意图如图1所示。
2.1 鸣笛声监测定位系统
鸣笛声监测定位系统主要实现对道路上鸣笛声音的监测和定位,并截取鸣笛车辆的图像上传至服务器,以进行后续的车牌号识别。该系统构成如图2所示。
(1)鸣笛声监测程序:该程序用于监测麦克风阵列所在道路上是否存在违法鸣笛的行为,该程序功耗较小,故放于本地一直循环运行,若鸣笛声存在则继续执行鸣笛声定位程序。
(2)鸣笛声定位程序:该程序用于确定鸣笛声源的位置。在一定区域内判断麦克风阵列的位置,将位置坐标转换成图像坐标输入摄像装置中,摄像装置截取相应区域内的图像信息,并将该图像信息上传至服务器。
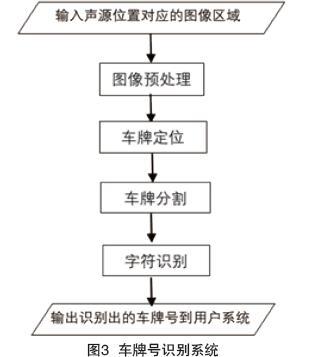
2.2 车牌号识别系统
车牌号识别系统下载服务器上的车辆信息图像,经过一系列处理后输出精准识别后的车牌号[3]。该系统的构成如图3所示。
(1)图像预处理:车牌号识别系统从服务器上获取车辆图像信息作为输入。将服务器中存储的截获的鸣笛车辆图像信息作为系统的图像输入到车牌号识别系统中。截取的图像质量受光照条件、车牌与摄像头角度、车牌与摄像头距离等不可控因素的影响,通常含有很多噪点,在该处主要对图像有效信息进行增强和保留处理,对不必要的图片信息进行删减,为后续流程提供便利,同时也节约了存储空间。主要处理方法为灰度化,灰度拉伸,边缘检测,二值化等。
(2)车牌定位:该模块的目的是将车牌区域准确地从经过预处理后的汽车图像中分离出来,同时解决车牌区域与水平方向存在夹角的问题,便于后续进行分割以及字符识别。
(3)车牌分割:定位后的车牌图像被分割,组成车牌号的一系列单个字符被分割出来用于后续识别。
(4)字符识别:将上一步骤中分离出的单个车牌字符导入训练好的神经网络模型中,识别出相应的汉字字母数字,最后将识别结果即车牌号发送至用户系统页面[6]。
2.3 用户系统
用户系统作为智能交通子系統,其主要功能为实现智能交通系统与用户的交互。该系统可将违章时间,地点等信息通过短信方式发送至识别后的车牌号对应车主的手机,同时将违章信息记录进车主信息数据库,更加便于管理。用户系统的构成如图4所示。
(1)车主提醒:从数据库中获取车主信息,将违章信息通过短信或其他方式发送给车主。可以让车主及时了解自己车辆的违章信息,同时防止此类违法行为再次发生。
(2)数据库:用于实时记录并存储车主的违章信息,包括时间、地点、图像、违章次数等。实现对车主违章数据的管理,并作为后续对车主违法行为进行处罚的主要证据。
3 系统关键技术
3.1 鸣笛声识别
本系统通过深度神经网络模型来实现鸣笛声识别的核心算法[1]。不同于传统的算法的是,本系统采用的算法没有明确的对声源信息特征进行提取的步骤,而是直接将傅里叶变换系数中的相位谱和幅度谱输入到训练好的卷积神经网络模型中,在卷积运算层中,通过若干个不同的卷积核得到对应的特征图,在全连接层中融合特征图,实现维度的转换,最后输出声源发生在每个区域的概率,概率最大的区域即为目标声源的定位区域。使用过滤器保证了在麦克风阵列的位置有微小变动时,仍然可以计算出较准确的概率。在训练过程中,加入了存在与麦克风阵列不同方向和距离的噪声的干扰,保证了该系统在有噪声干扰的情况下仍有较好的定位效果。
3.2 车牌号识别核心算法
车牌号识别算法主要包括图像预处理算法、车牌定位算法、车牌分割算法和字符识别算法。
3.2.1 预处理算法
车牌号识别系统从服务器下载图像信息,然后对图像信息进行灰度化、二值化等一系列预处理[3]。灰度化处理的主要思想为将图像的RGB值设为相同的三个数值。该具体数值可以通过最大值法,平均值法,加权平均值法三种方法中任意一种来确定。图片灰度处理后,由于车牌区域与非车牌背景区域对比度不高,难以准确地从边缘提取车牌界限,因此需要将车牌区间进行灰度拉伸,将原图像的点(x , y)的灰度f(x , y) 通过特定映射关系转化为灰度g(x , y), 以增强车牌区域与背景区域的对比度。进而将所得图像进行二值化,呈现出明显的黑白效果[7]。
3.2.2 定位算法
本系统采用传统车牌定位算法,将数学形态学与投影法相结合,并通过Hough变换消除车牌与水平方向存在夹角的影响,为后续分割做准备[3]。利用膨胀,腐蚀,开启和闭合四个结构元素,度量形态特征,提取蕴含在图像里的信息,分析其拓扑和结构特点,从而对车牌进行数学形态法的粗定位。进行投影法的细定位之前首先要判断车牌是否倾斜,若车牌倾斜,则采用Hough变换将其进行矫正处理,若车牌没有倾斜,则可省去Hough变换这一步骤。利用Hough变换将倾斜车牌矫正的基本思想是统计出车牌图像在参数空间中与对应曲线的交点数最多的点[11-12],该点映射到原图像中最长的直线与X轴的夹角即为车牌的倾斜角度。通过极坐标运算得到新的矫正过后的像素点。同时由于二值化的车牌图像在垂直方向的投影呈现出显著的波峰-波谷特性,因此可利用改波峰-波谷特性特点对于车牌进行左右边界的精确的定位[8-9]。
3.2.3 分割算法
对汽车车牌进行扫描,将汽车车牌的左右边框基于字符处黑白跳变次数多于边框上黑白跳变次数这一特性进行去除,然后对车牌进行分割[4]。采用从中间字符右边界向左向右进行扫描的方法实现对字符的分割,可以降低边框去除不准确对字符分割产生的影响。对放入矩阵m[i] (1*n)(其中n为车牌区域的整体宽度)中的像素点进行扫描,当连续发现三个像素点均小于垂直投影灰度阈值Q1后,即可判断该处达到了字符边界位置。由于首字符为车牌所属地区,存在左右结构,易产生汉字分割不连续问题,故对汉字采用起始终点做差法比较与阈值Q2的差,若差值大于Q2,则为完整字符,若差值小于Q2,则继续扫描寻找首字符边界。
3.2.4 识别算法
将分割后的字符通过网格特征提取法(即建立网格系统,选择网格中白色像素的点作为特征值)与笔划密度特征提取法(即从水平方向和垂直方向扫描字符,统计扫描线与笔划线的相交情况)提取的特征相结合,根据字符位置输入到训练好的三层神经网络中(向汉字网络输入分割产生的第一位字符,字母网络输入分割产生的第二位字符,字母数字网络输入第三到七位字符),经一系列运算后得到车牌号识别的结果[5]。网格特征提取法减小了车牌上污点造成的干扰,笔划密度特征提取法则解决了字符微微变形的问题,二者互补,以实现对车牌字符的精确识别。
4 结语
本文设计了一个基于人工智能的智能交通系统,该系统分为鸣笛声检测定位系统,车牌号识别系统以及用户系统三个子系统,分别实现对鸣笛声音的识别与定位,对车牌号的识别,以及与用户的交互三大功能。描述了系统中各模块的具体作用以及模块之间的联系,鸣笛声检测定位系统识别出鸣笛车辆并且将声源位置坐标以及车辆对应图像信息上传至服务器。服务器内的车辆图像信息被车牌识别系统获取,在识别系统内完成识别工作后,将识别结果上传至用户系统。同时用户系统从服务器上下载鸣笛位置坐标以及截取的汽车图像,将违章信息发送给对应的车主,并且将违章信息上传至数据库。简要阐述了该系统主要模块采用的核心算法。鸣笛声检测系统通过构建深度神经网络模型并加入噪声训练来实现鸣笛声的准确识别与定位,车牌识别系统灰度处理和二值化处理得到的图像信息,数学形态学、投影法以及Hough变换相结合对车牌进行定位,继而通过扫描和与垂直投影灰度阈值进行比较实现对车牌的分割,提取分割后的车牌特征,输入汉字神经网络、字母神经网络以及字母数字神经网络进行字符的识别。由于鸣笛声噪声环境复杂和车辆图像信息较复杂,未来仍需要对该算法继续进行优化,同时根据需求进一步对系统进行设计。
参考文献
[1] Brandstein M S, Sliverman H F. A practical methodology for speech source localization with microphone arrays[J]. Computer, Speech and language, 1997, 11(2): 91-126.
[2] Chakrabarty S , Habets, Emanu?l. A. P. Broadband DOA estimation using Convolutional neural networks trained with noise signals[J]. 2017.
[3] 白明雷. 基于神經网络的车牌号识别方法研究[D].
[4] 迟晓君, 孟庆春. 基于投影特征值的车牌字符分割算法[J]. 计算机应用研究, 2006(7):256-257.
[5] 韩力群. 人工神经网络理论、设计及应用(第二版)[M].化学工业出版社,2007.
[6] 肖坤平. 车牌字符自动识别方法的研究[D]. 重庆大学, 2011.
[7] 潘梅森, 张奋, 雷超阳. 一种车牌号码图像二值化的新方法[J]. 计算机工程, 2008, 34(4):209-211.
[8] 吴炜, 杨晓敏, 何小海,等. 一种边缘检测与扫描线相结合的车牌定位算法[J]. 电子技术应用, 2005, 31(2):43-46.
[9] 刘丽新, 刘京刚, LiuLixin,等. 行扫描进行车牌上下边界定位的研究[J]. 仪器仪表学报, 2005, 26(z2):177-179.
[10]包明, 路小波. 基于Hough变换的车牌倾斜检测算法[J]. 交通信息与安全, 2004, 22(2):57-60.
[11]王良红, 王锦玲, 梁延华. 改进的Hough变换在校正汽车牌照倾斜中的应用[J]. 太赫兹科学与电子信息学报, 2004, 2(1):45-48.
[12]Kesidis A L , Papamarkos N . On the inverse Hough transform[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1999, 21(12):0-1343.
[13]陆锋. 基于改进的BP神经网络进行车牌定位的研究[J]. 苏州大学学报(工科版), 2004, 24(6):5-8.
