基于联合模型的藏文实体关系抽取方法研究
2019-01-22夏天赐
夏天赐,孙 媛
(1. 中央民族大学 信息工程学院,北京 100081;2. 中央民族大学 国家语言资源监测与研究中心 少数民族语言分中心,北京 100081)
0 引言
实体关系抽取任务作为信息抽取领域的重要研究课题,其主要目的是抽取句子中已标记实体对之间的语义关系,即在实体识别的基础上确定无结构文本中实体对间的关系类别,并形成结构化的数据以便存取。例如,是的妻子。实体关系抽取能自动识别实体“叶莉”和“姚明”是夫妻关系。
传统的实体关系抽取任务通常采用“流水线”方式。首先需要提取句子中相关实体,然后再识别实体之间的关系。这种方式的好处是,处理起来非常方便,且组合很灵活,但它忽略了两个子任务之间的关联,且会产生错误的叠加,比如,实体识别任务产生的错误会传递给关系识别的任务,导致整个模型错误率上升。
不同于上述的“流水线”方式,联合模型进行实体关系抽取时,能够从非结构或者半结构化的文本中提取出实体以及能够识别语句中的语义关系。通过这种方式,我们能根据语义信息,从预定义的关系表中匹配语句中出现的实体之间的关系。提取实体和判别实体之间关系同时进行,大大降低了错误率的叠加,并且产生结果更加快速和高效。
联合模型的框架是将实体识别和关系识别任务用简单模型联合起来。有效地聚集了实体和关系的信息,并且在这个任务中得出一个比较好的结果。然而,目前存在的联合模型是基于特征的结构化系统,这个系统需要极其复杂的特征以及依靠很多的自然语言处理工具,在这种情况下,难免产生很多错误。为了降低人工处理的错误,目前业界普遍采用端到端的神经网络模型,这种模型已经被运用到各种序列标注任务中,比如命名实体识别(NER)或者组合范畴语法(CCG)。而常用的神经网络模型是利用BiLSTM结构来获取句子表达或者句子信息来完成序列任务。
在本文中,我们将集中介绍联合模型抽取的任务,从一个生文本中抽取出包含两个(或以上)实体以及它们之间的关系,进而构成一个三元组(E1,E2,RE)。因此,我们可以直接构建一个联合模型提取实体以及实体关系,基于这种想法,我们将实体关系转化为一种序列标注问题,将句子切分成词或者字,并且给每一个词或字添加标签组(BIESO)。同时,为了提高提取信息的准确率,我们也给每个词或者字进行词性标注。通过这种方法,我们仅通过神经网络就能构建相应的模型,而不需要进行复杂的特征工程。
1 相关工作
实体关系抽取任务是构建知识库的一个重要环节,目前处理这个任务有两种方式,“流水线”方式和联合学习方式。
“流水线”方式处理这个任务分为两个步骤: 命名实体识别和关系分类。
典型的命名实体识别模型是基于统计模型,比如Passos[1]等提出从与实体相关的词典中学习一种新的词向量表达形式,并且利用新的神经词向量作为单词语义表达。该方法在CoNLL03数据集上F1值达到90.09%。Luo[2]等提出一种新的实体关系抽取模型——JERL(Joint Entity Recognition and Linking),该模型主要将实体识别和知识库中的实体进行联合来捕获实体和知识库中的依存关系,利用CRF(Conditional Random Field)模型进行实体识别,然后利用知识库中已有的实体进行类别判断。该模型在CoNLL03数据集上F1值达到91.2%。目前,很多神经网络模型也运用到命名实体识别任务中,比如Chiu[3]等利用BiLSTM+CNN联合模型进行字级和词级的特征提取。该模型首先从CNN模型预处理的字级特征向量中提取出新的特征向量,然后将提取出的新的特征向量输入到BiLSTM中,进行词级的特征提取,最后输出该实体的类别概率值。该模型在CoNLL03数据集上F1值达到90.77%。Huang[4]等利用BiLSTM+CRF混合模型将命名实体识别任务转变为序列标注问题。该模型将分词后的词向量直接输入到BiLSTM中,提取出词级特征,在最后判断实体的类别时,利用CRF层将类别概率转变成序列概率值输出。该模型在CoNLL2000数据集上F1值为94.40%。Lample[5]等提出利用LSTM+CRF模型提取词级特征同时基于过渡的方式构造标签片段。该方法的实验数据主要来源于有监督的字级语料库以及无监督的非标记的语料库。首先,对输出的句子利用依存句法的过渡方式进行处理,构造出有标记的单词,然后将预处理的单词输入到LSTM中,最后通过CRF输出序列概率值。该方法在CoNLL2003(英文)上F1值达到91.20%,在CoNLL2003(德语)上F1值达到78.76%,在CoNLL2002(西班牙语)上F1值达到85.75%。
对于关系分类任务,主要有两种方式,一是基于特征提取的人工处理方式,Rink[6]等采用SVM分类器进行语义关系类别识别,然后利用语义关系类别进行关系分类。该文采用上下文、语义角色索引以及可能存在名词性关系等一系列特征进行分类。该模型在SemEval-2010 Task 8数据集上F1值达到82.19%,Precision达到77.92%。Kambhatla[7]等利用最大熵模型组合不同词汇、句法和语义等特征进行关系分类。该方法在添加了多种特征,包括实体类型、依存关系以及句法树等,F1值达到了52.50%,Precision达到了63.50%。另一种是基于神经网络的处理方式,Xu[8]等通过卷积神经网络(CNN)结合最短依存路径进行语义关系分类。首先将语句输入到CNN网络中,提取语句中的关系特征,最后通过依存特征进行类别判断。该方法在SemEval-2010 Task 8数据集上F1值达到了85.60%。Zheng[9]等提出基于CNN的模型和基于LSTM的模型,为了学习关系模式信息和给定实体的语法特征。首先,利用CNN进行关系模式的提取,然后利用LSTM进行实体语义的特征提取,最后将两者结合进行语义关系分类。该方法在ACE05数据集上F1值达到了53.60%,Precision到了60.00%。
联合学习方式处理实体关系任务通常只需要一个模型。大部分联合模型是基于特征的结构,比如Ren[10]等提出一种基于Distant Supervision和Weakly Supervision对文本中的实体和关系联合抽取的框架。该框架主要分为三个部分: ①候选集的生成;②联合训练实体和向量空间;③实体类型和关系类型的推理预测。该方法在三个公开集上做测试: 在NYT数据集上F1值为46.30%,Precision为42.30%;在Wiki-KBP数据集上F1值为36.90%,Precision为34.80%;在BioInfer数据集上F1值为47.40%,Precision为53.60%。Yang[11]等利用联合推理模型进行观点类实体和观点类关系的抽取。在观点类识别任务中,采用CRF模型将识别任务转变成序列标注任务。在观点类关系抽取任务中,利用观点—参数模型识别观点类关系。该模型在MPQA数据集上F1值为57.04%。Singh[12]等利用联合推理进行三个任务: 实体标注、关系抽取以及共指。该模型利用联合图模式将三者结合在一起,相互作用,通过学习和推理的方式优化联合推理模型参数。该模型在ACE2004数据集上针对实体抽取任务的F1值为55.39%,针对实体标注任务达到了82.9%的Precision。Miwa和Bansal[13]提出一种联合实体检测参数共享的关系抽取模型,模型中有两个双向的LSTM-RNN,一个是基于Word Sequence(bidirectional sequential LSTM-RNNs),主要用于实体检测;另一个是基于Tree Structures(bidirectional tree-structures LSTM-RNNs),主要用于关系抽取。后者堆在前者上,前者的输出和隐含层作为后者的输入的一部分。Zheng[14]等利用联合模型将实体关系抽取任务转变成序列标注任务,主要是采用End-to-End的模型直接抽取实体和关系。
藏文信息抽取处理技术起步较晚,通常也是采用“流水线”方式进行实体关系抽取,即藏文命名实体识别和藏文关系分类。
针对藏文命名实体识别,金明[15]等首次提出基于规则和HMM模型藏文命名实体的研究方案。罗智勇[16]等通过研究藏族人名汉译的方法,提出了利用藏族人名的字级特征以及命名规则,结合词典采用字频统计和频率对比策略,以及人名前后一个词为单位共现概率作为可信度度的藏文人名识别模型,需要先给出预先定义的域值。在新华网藏族频道文本和《人民日报》(2000~2001)上实验的召回率分别为85.54%和81.73%。华却才让[17]等提出基于音节的藏文命名实体识别方案,采用基于音节训练模型,准确识别藏文人名、地名和机构名,识别的F1值达到86.03%。刘飞飞[18]等提出基于层次特征的藏文人名识别方法,将人名的内部和上下文特征作为CRF特征,然后将人名并列关系特征设计为规则,进一步提高识别效果,识别的F1值达到了95.02%。
针对藏文关系分类,龙从军[19]等通过研究藏语名次语义关系,提出组织名次的基本单位是义类,联系名词和名词、名词与其他词之间的关系是语义关系。马宁[20]等以模板的方式从互联网中抓取纯藏文文本,然后对文本进行分词、词性标注和命名实体识别,并对关键字和实体进行过滤,抽取出候选模板,最后对抽取出的候选模板计算语义相似度,超过一定阈值就成为关系模板。
本文基于以上设计思路,同时考虑到藏文信息抽取任务的研究相对滞后、藏文的语料稀少、结构复杂、处理领域单一等问题,考虑将联合模型运用于藏文实体关系抽取任务中,按照字级或者词级处理语料,然后利用词性标注特征进行补充,同时也将藏文关系抽取任务转变成藏文序列标注任务。
2 方法介绍
2.1 总体框架介绍
首先,我们对藏文语料分别按照词级或者字级进行序列标注处理(见2.2节),然后利用自然语言工具,给每个词或者字进行词性标注(见2.3节),再输入到神经网络编码层(见2.4.2节),经过编码层解析,然后通过解码层(见2.4.3节),最后通过输出层输出结果(见2.4.4节),总体框架如图1所示。
其中,模型最终输出yi代表输入藏文分词或者分字的序列标签。如图2所示(中文释义: 扎西顿珠出生于迭部村庄),以分词为例,其中“/”表示词与词之间的分隔符,“BP”表示关系分类中“BirthPlace”类别。最后的输出与分词结果一一对应。
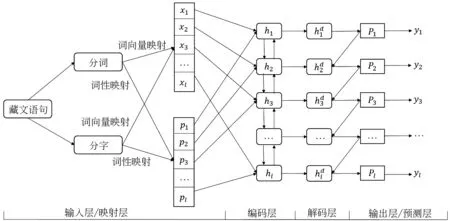
图1 总体框架

图2 示例图
2.2 词级、字级处理
2.2.1 藏文词级处理
首先,本文利用CRF++工具对藏文进行分词。然后,对分词后的每个单词分配一个标签。标签“O”代表该单词与提及实体无关。除了标签“O”,其他单词标签分为三个部分: 实体位置、关系类型以及关系角色。实体位置,本文使用“BIES”来表示,“B”代表实体起始位置,“I”代表实体中间位置,“E”代表实体结束位置,“S”代表单个实体。关系类型,从已知的关系集中查找。关系角色则根据上下文信息确定,并同时设置为“1”和“2”。示例如图3所示。(中文释义: 扎西顿珠出生于迭部村庄)

图3 藏文词级处理示例
2.2.2 藏文字级处理
首先,本文按照藏文拼写特征,利用藏文音节点进行字级处理,然后对分字后的音节分配标签。与词级对应,标签“O”代表该音节与提及实体无关。其他的音节标签同样也分为三个部分: 实体位置、关系类型以及关系角色,各部分的定义与词级一致。示例如图4所示。(中文释义: 扎西顿珠出生于迭部村庄)
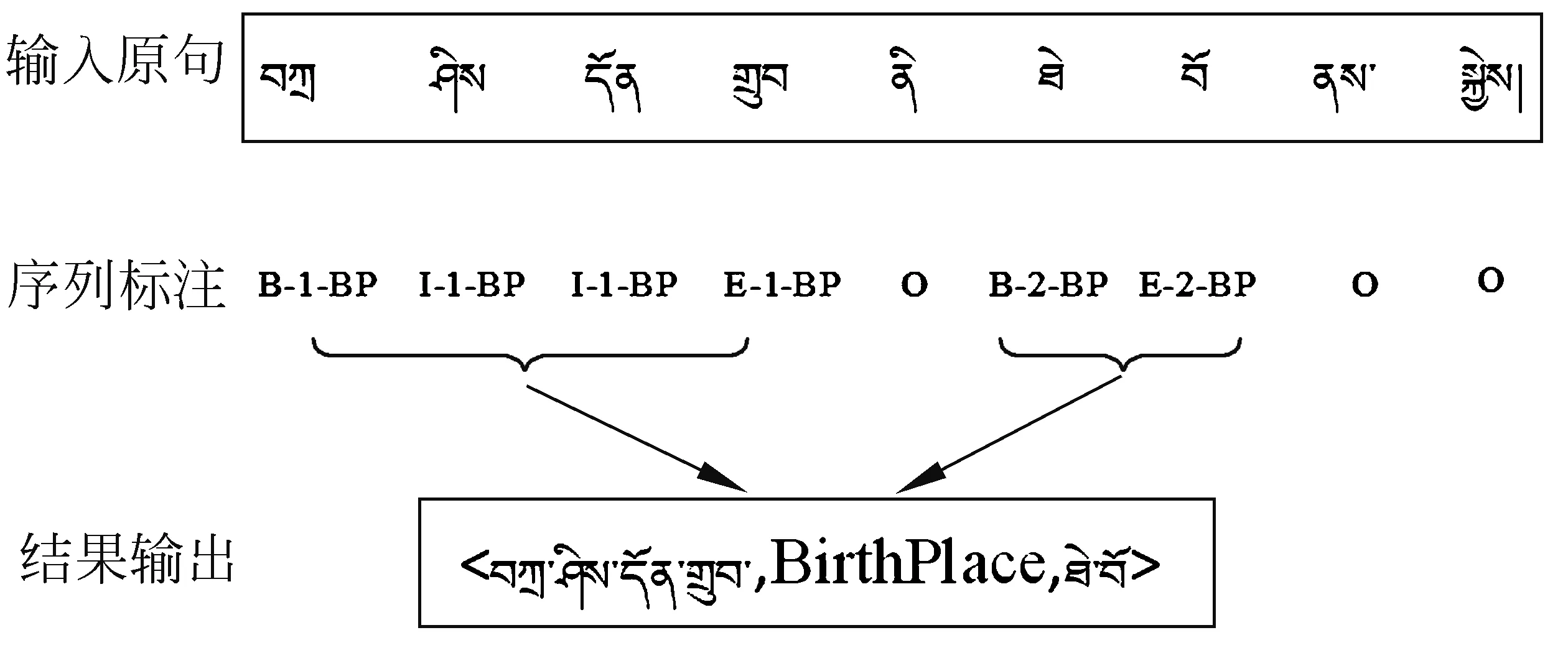
图4 藏文字级处理示例
2.3 词性标注
由于藏文进行序列标注过后的信息较少,在与实体无关的单词或者音节上都默认标签为“O”,对结果的提取存在较大偏差。本文针对这种情况,在序列标注过后的藏文词或者字进行词性标注,对所有的词或者字分配词性标签,降低最后提取的错误率。示例如图5所示。(中文释义: 扎西出生于迭部村庄)

图5 词性标注
这里需要注意,我们进行字标注时,根据词的词性来定义,示例如图6所示。(中文释义: 泽旺拉姆)

图6 字性的定义
不难发现,很多藏文特有的词性,例如,格助词、属格助词等对帮助判断两个实体的关系有辅助的作用。同时本文也借鉴了这种藏文特有的词性规则,比如利用属格助词来表达“包含”、“属于”之类的关系,以此来强化和提高藏文实体抽取的准确率。
2.4 端到端模型
目前,基于神经网络的端到端模型在序列标注任务中起到良好的效果。本文也采用端到端的模型进行实体关系抽取任务。模型主要包括预处理阶段、BiLSTM编码层、LSTM解码层以及一个Softmax输出层。
2.4.1 预处理阶段
给定一句长度为l的藏文语句W= {x1,x2,x3,...,xl},先通过word2vec生成词向量T={t1,t2,t3,...,tl},然后经过CRF工具获取每个词的词性P={p1,p2,p3,...,pl},并且通过Word-POS[21]的方法将词向量和该词词性向量进行拼接,组成新的向量表达TP={(t1,p1),(t2,p2),(t3,p3),...,(tl,pl)}。 流程如图7所示。(中文释义: 扎西出生于迭部村庄)
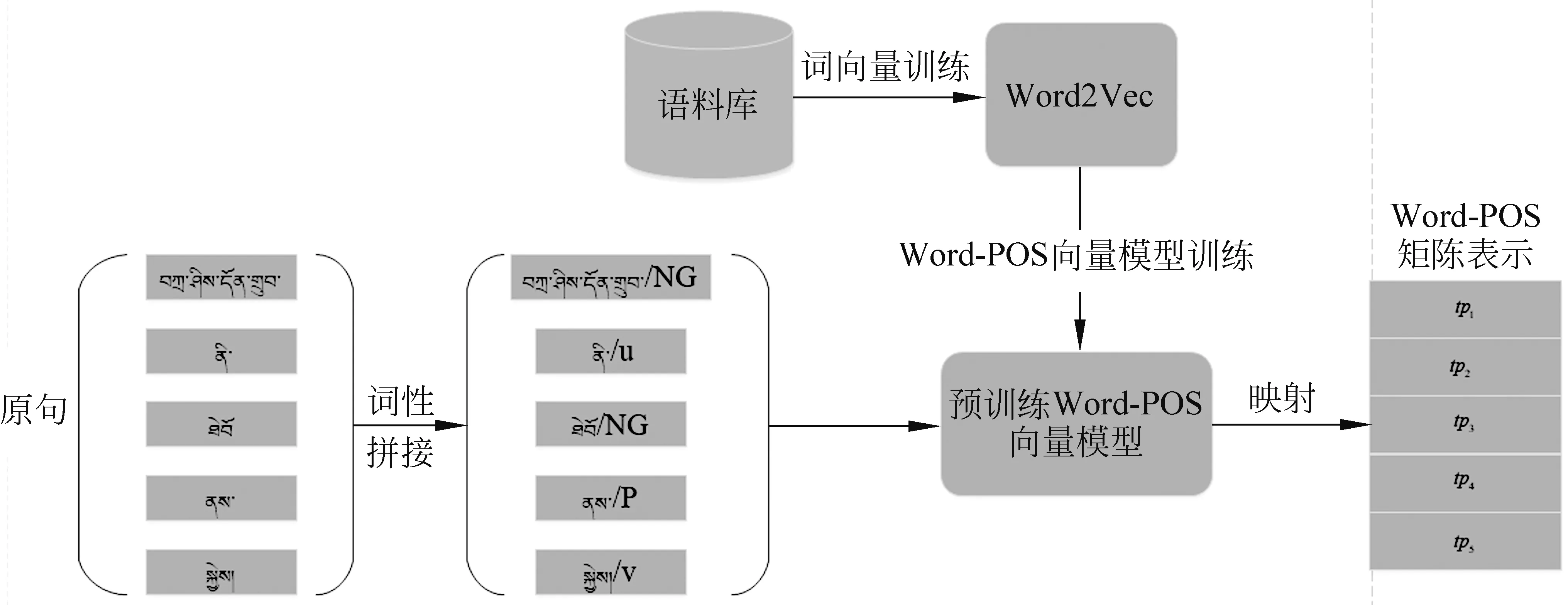
图7 预处理流程
2.4.2 BiLSTM编码层
将预处理阶段生成的向量表达TP输入到BiLSTM中。BiLSTM能够捕获到句子中的语义信息。它主要包括前向LSTM层、后向LSTM层以及一个连接层。通过预处理得到的藏文语句向量表达,输入到BiLSTM中,这个结构包含一系列的循环连接单元,称为记忆区块。每个当前的记忆区块能够根据前一层的隐向量ht-1、前一层的单元向量ct-1以及当前的输入向量tpt-1,捕获当前的隐向量ht。 具体定义如式(1)~式(5)所示。
输入门:
这一步主要决定是否对当前输入的文本信息中重要的词或者字进行更新。
遗忘门:
这一步决定以前的文本信息中是否丢弃无表达、无关的词或者字。
输出门:
最终输出当前时刻的文本信息状态以及最后的特征输出向量如式(6)所示。

2.4.3 LSTM解码层

输入门:
(7)
遗忘门:
(8)
输出门:
2.4.4 Softmax层
针对最后的Softmax层,基于输出的向量Pt,来预测实体的概率标签:
其中,Wy是输入Softmax矩阵,Nt是整个标签的数量,by是偏置项。
3 实验
3.1 数据集
数据集采用中央民族大学自然语言处理实验室处理的藏文数据集,数据格式同NYT数据集。该藏文数据集共包括了2 400个三元组及其原句,并有11种常见的关系,在实验中,我们采用的训练集有2 000句,测试集有400句。
3.2 评估
主要采用准确率P和召回率R以及F1值作为评估指标,不同于传统的机器学习方法,我们没有使用标签类型来训练模型,因此在评估过程中不需要考虑实体类型。同时我们会在训练集中随机选出10%的数据作为验证集来优化模型的参数。
3.3 参数设置
我们使用Word2Vec工具来生成词向量,对于词向量维度可选[20,30,50,80]。本文基于实验效果最好的维度50维,即d=50。神经网络隐层的数量依据启发式规则,将LSTM编码层单元数量设置成300层,LSTM解码层单元数量设置成600层,学习率初始值设为0.002。具体参数如表1 所示。
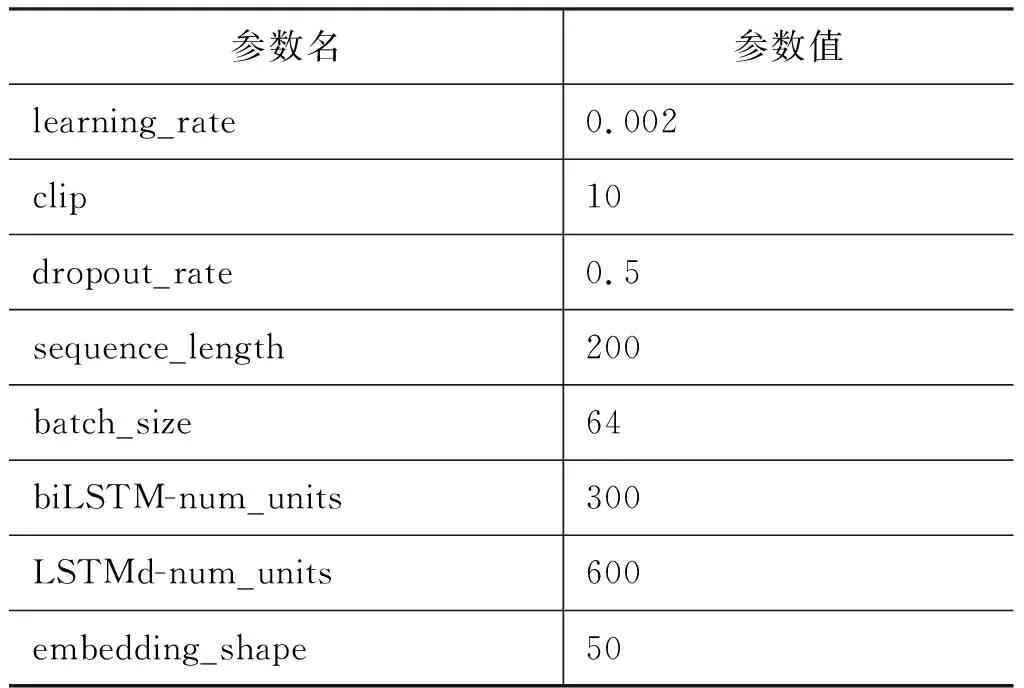
表1 参数表
3.4 基线方法
我们比较了各种算法在藏文实体关系抽取上的结果,包括传统的SVM和LR方法,同时也比较了单一的GRU方法在任务上的结果,我们的方法取得了最好的结果。
同时本文比较每个词性对于实体关系的抽取的影响,经过分析,选择词性NG(名词)、词性P(格助词)、词性V(动词)、词性A(动词)作为特征控制变量输入。即本文只选取其中一种词性作为词性特征输入,并且将其他的词性设置为空,进行二次实验。
4 结果与分析
4.1 方法比较
在不同方法上的实验结果,如表2所示。
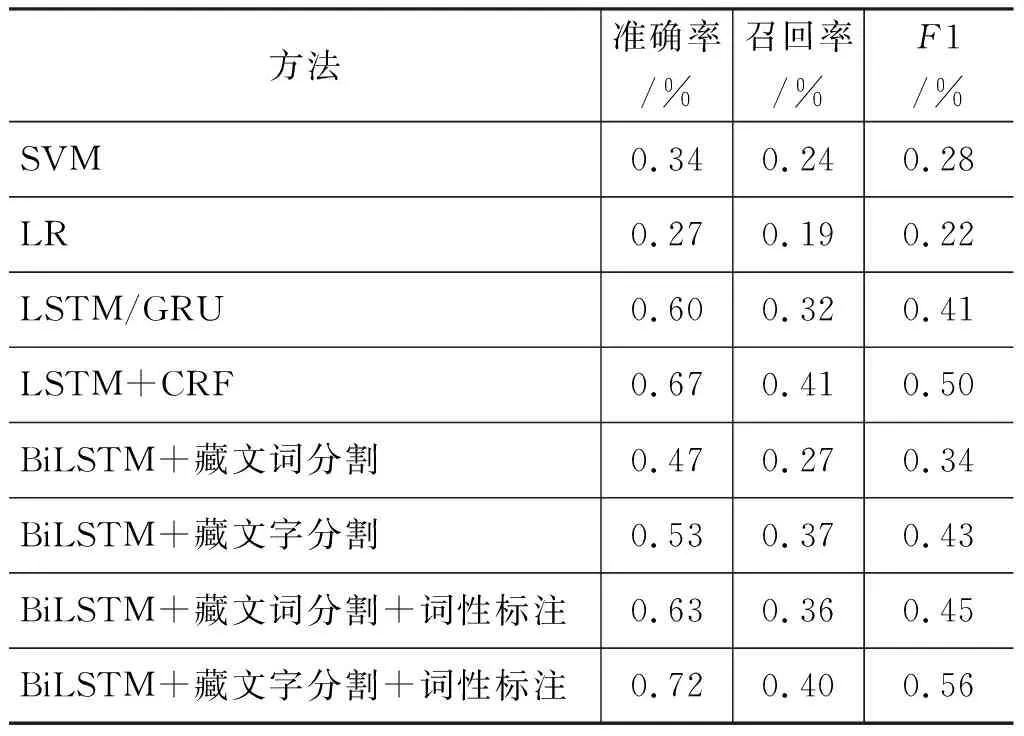
表2 方法结果比较
从表2可以看出,针对藏文的分割粒度以及词性标注的影响,我们的方法较传统的机器学习方法提升了很高的准确率。同时,在神经网络的方法中,综合比较了LSTM在藏文实体关系抽取任务上的不同处理,尤其是藏文语料的处理,我们采用了不同粒度对藏文进行处理,对藏文进行词分割和字分割,并在神经网络学习过程中添加词性标注进行优化,我们的方法较纯粹的神经网络模型也有一定的提升。
4.2 词性比较
这里,本文仅在藏文字级处理上进行进一步的词性标注的比较,结果如表3所示。

表3 词性结果比较
不难发现,词性NG的影响比较大,经过分析我们发现,藏文中词性NG在所有词性中占比最大,约为85%。在缺少词性NG的情况下,提取的准确率下降了至少10%,可见词性NG对于藏文实体抽取的重要性很高。而词性V在所有词性中占比最小,约为2%。同时,我们也发现,词性P以及词性A对于结果的影响偏差很接近,藏文中的格助词以及形容词在一定程度上能帮助提高藏文实体抽取的准确度。
由于藏文语料稀少、处理过程中需要有专业人士进行校正,上述的切分过程都是先使用机器进行程序化处理,然后经过人工校正,处理周期较长,并且结果也需要有专业的人士来进行修正,帮助优化神经网络参数。
经过专业人士修正,我们发现实验中也存在以下不足: ①在处理藏文词或者藏文字过程中,藏文语句的长度过长,往往几百行后才能找到相应的实体和关系;②藏文语句中表达存在意思冲突现象,藏文中一个实体往往会表达多个意思,也就是说,藏文一句话中,除了标注实体以外,其他词或者字中也表达相同的意思,给神经网络模型造成误判的现象;③本文方法中,在同一个句子中的两个实体,往往也会出现在其他句子中,但关系表达不一致,也造成了错误率提高。
5 总结
本文主要针对藏文语料匮乏的情况,提出一种将实体关系抽取任务转变成一种序列标注任务的方法。同时,对藏文语料的处理也是本文的一大亮点,我们的实验相对于传统的机器学习以及普通的神经网路模型,取得了较好的准确率。但是我们的方法在藏文的处理上也存在一些问题,针对神经网络的优化也没有做对比试验。在针对藏文特有的语法规则以及性质上面,本文没有进行深入的研究。
在未来的工作中,我们会逐步优化藏文的处理,尽量减少人工的参与,同时不断优化模型,添加藏文的特有规则,继续添加藏文特有的词性规则,使模型更适应于藏文的实体关系抽取,为后续的藏文自然语言处理的深入研究提供基础。
