基于序列到序列的中文短文本省略补全
2019-01-22周国栋
郑 杰,孔 芳,周国栋
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
省略是一种很常见的语言现象,需要通过上下文来理解被省略的内容。省略现象在中文、英文等多种语言中都存在。据Kim[1]统计在中文和英文的语料中,英文大约有96%是显式主语,而在中文中却只有64%。由此可见,中文是一种省略现象十分频繁的语言。特别是在问答、对话等短文本中,因参与问答、对话双方的语言习惯、表达方式各有差异,故会导致表达的内容呈现出随意和不规范的特点。因此,省略现象在这类短文本中尤为突出。由于缺少谈话双方的背景知识,当机器在面对这类会出现大规模省略现象的短文本时,若不经过省略恢复处理,机器将很难理解短文本的含义。进而导致在问答、对话等系统中给出“错误”的回复,用户体验欠佳。因此,对中文文本,特别是对话、问答这种中文短文本进行省略恢复工作有着非常重要的意义。
本文的主要工作是针对中文短文本中的省略进行补齐,结合深度学习的网络模型提出了一种基于序列到序列[2]的省略检测和补全模型。
本文后续内容安排如下: 第1节简要介绍了中英文省略恢复的研究现状;第2节详细介绍了引入注意力机制的序列到序列的神经网络模型;第3节是实验过程及实验结果分析;第4节给出了总结。
1 相关工作
目前英文的省略恢复研究主要针对动词短语进行,并取得了一定的成果。代表性工作有: Dalrymple等[3]和Shieber等[4]对英文进行语言学分析,在英文动词短语省略恢复方面建立了一套语言学理论体系;Nielsen等[5]首次提出一种端到端的可计算的系统来对原始输入文本进行英文动词短语省略恢复;Liu等[6]继续Nielsen的工作,提出一种目标检测、先行词词首消解以及先行词边界识别的动词短语省略识别步骤。
中文方面,相关研究主要集中在主语位置的省略和空语类的恢复方面。代表性工作包括: Kong等[7-8],Chen等[9-11]在标准公开中文数据集上进行中文零指代的研究;Cai等[12],Kong等[13],Xue等[14]在中文标准公开数据集上进行关于中文空语类省略恢复研究。但这些研究多关注省略的恢复,同时对于省略的检测多采用规则方法。
在问答、对话等短文本的省略研究方面,代表性工作包括: Huang等[15]对中文口语对话系统中的省略现象进行研究。此中文口语对话系统是清华大学的校园导航EasyNav,对话的形式一般是用户主导的连续型请求模式。Huang等基于此中文口语对话系统提出了一种基于主题结构的省略恢复方法。但他们提出的方法一方面是基于他们的导航系统EasyNav,不具有通用性;另一方面,他们提出的方法也只是停留在理论基础上,并没有提出一种具体的可计算模型。Yin等[16]主要针对对话中的零代词省略进行恢复,提出了零代词恢复和零代词消解的框架,并采用联合模型减少管道模型带来的误差传播。但其采用的OntoNote 4.0语料,是经过标注的具有句法规范的语料,无法体现中文口语对话的随意性和不规范性,并不具有代表性。Kumar等人[17]针对英文问答中指代消解问题分别构建了基于句法和语义的序列到序列模型,并结合这两种模型生成的联合模型来学习英文问句的语义和语言学的模式。
综上所述,我们发现在中文方面,相关工作大都集中于规范的长文本数据集,而关于中文短文本的省略恢复研究很少;此外,这些研究工作都是基于传统机器学习方法。本文首次针对中文不规范的短文本中的省略识别及恢复任务展开,提出了一个完整的端到端的神经网络模型,并通过实验验证了该模型在短文本的省略检测和恢复上的有效性。
2 省略恢复模型
本节主要介绍本文应用在中文短文本省略识别和恢复任务中的序列到序列的神经网络模型。序列到序列模型是在2014年被提出的,起初应用在机器翻译中,之后在摘要生成、语音翻译等其他领域都得到了广泛应用。
本文首次将序列到序列模型应用到中文短文本省略补全的研究中,从实验结果可以看出该模型在实验任务中也取得了不错的表现。图1是本文模型的一个神经网络结构图,该框架主要包含三个层次,即嵌入层、编码层和解码层。接下来本文将从模型的这三个层面分别展开进行模型详细细节的说明。

图1 序列到序列的省略补全模型
2.1 嵌入层
嵌入层(embedding)的主要作用是获得词的分布式表示。它会维护一个嵌入矩阵D∈V*f,其中V表示词表长度,f表示词向量的维度。如图1所示,假设输入序列为{“吃”,“了”,“吗”},在预处理中首先会将该输入序列用填充符“
其中,x1,…,xm表示输入序列中的单词在词典里的序号,这里m=5。 嵌入层会根据标签序列的值xj从嵌入矩阵D中找到序号所对应的向量wj∈f,最终标签序列X都会对应一个分布式表示,也就是词向量,如式(2)所示。
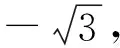
2.2 编码层
2.2.1 LSTM
循环神经网络(RNN)因其能够捕捉时序信息而在自然语言处理任务中得到广泛应用。但面对较长的序列时,循环神经网络会出现梯度消失和梯度爆炸的问题。而LSTM[18]于(Long Short-Term Memory)1997年被提出,作为RNN的一个变体,可以解决梯度消失的问题。一个LSTM神经单元由3个门组成。分别为输出门,输入门和遗忘门。这三个门会控制传输到下一个时序信息的多少。一般地,LSTM神经单元在t时刻的更新规则如式(3)~式(8)所示。
其中,σ是sigmoid函数,⊙是对应元素相乘,Xt是t时刻的输入(经过嵌入层后的向量),ht是t时刻隐层状态向量。Ui,Uf,Uc,Uo表示输入X的权重矩阵,Wi,Wf,Wc,Wo表示隐层状态的权重矩阵,bi,bf,bc,bo表示偏置。
2.2.2 Bi-LSTM
一般的单向LSTM网络只能学习历史信息,而Bi-LSTM的思想是将前向传播的状态和后向传播的状态进行拼接,并且已有实验[19]证明这种双向结构可以捕捉历史信息和未来信息,如图2所示。

图2 编码层双向LSTM结构图
在本文的序列到序列模型中,用编码层来获取源端句子的语义表征。Bi-LSTM模型可以获得源端序列的历史信息和未来信息,能够更好地表征句子的语义信息。所以,在编码层我们采用Bi-LSTM的神经网络结构。它的具体运算过程如下。
标签序列X在经过嵌入层得到的词向量序列W。在Bi-LSTM中,前向和后向LSTM网络都是单独计算的。故而,W会分别传给前向和后向LSTM作为输入向量。假设在第i时刻(i≤m),前向LSTM中,第i时刻的输出如式(9)所示。
在后向LSTM中,第i时刻的输出如式(10)所示。

图1中,编码层最终将输入序列{“吃”,“了”,“吗”,“
2.3 解码层
2.3.1 注意力机制
注意力机制最初是指人的心理活动指向或集中于某些事物的能力,引入到神经网络中就是指神经网络模型对一些输出向量“注意”,对另一些输出向量“忽略”。而模型的这种“注意”和“忽略”是用权重来动态模拟的,与当前状态相关的向量会被分配高权重,不相关的向量会被分配低权重。那些被分配高权重的向量在数值计算中影响较大,而被分配低权重的向量对数值运算的结果影响较小,这就是模型会动态选择“注意”相关的内容而忽视不相关内容的原因。注意力机制的原理[20]如图3所示。

图3 注意力机制原理图
2.3.2 解码
根据RNN网络结构具有捕捉时序状态信息的特点,传统的编码解码(Encoder-Decoder)模型认为编码层最后一个时序的输出向量可以作为源端序列的语义表征。这种做法存在两种弊端,一方面,是在对长序列进行处理时,很难把握长句的依赖关系,不可避免会造成语义信息的丢失;另一方面,是这种表征方式也无法获得源端序列的焦点信息。因此,我们采用了Bahdanau Attention,对编码层的输出向量计算求得注意力权重,并得到上下文向量(Context Vector)加入到解码层的输入。具体做法如下:
首先,在解码第一步,序列开始标志符“
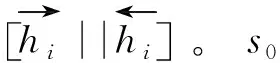
k≤m,m是源端序列的最大长度,在图1中的最大长度为5。所以,上下文向量c1通过式(15)计算得到:
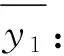
同时,第一个时序的预测标签作为第二个时序的输入标签,如式(17)所示。
图1中,第一步解码预测标签通过词典映射后就是符号“你”。
至此,第一步解码计算完成,之后解码步骤类似,直到输出结束符号“
在训练模式中本文采用式(18)negative log-likelihood来计算损失。
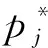
在推理模式下,本文模型采用的标签选择策略是beam search算法,在下面的章节中会详细介绍。
2.3.3 Beam Search
在推理过程中,常用的方法使用的是贪心算法搜索。这种方法实现简单,但是结果往往不是最优解。因此,为了增加候选预测序列集合,提高模型的性能,我们采用了一种beam search的解码方法。假设beam size大小为K,词典维度为V,它的思想是每次从概率分布中选择最高的K个值所对应的标签作为预测结果。设第i时刻的最高的K个得分结果按照式(19)计算为:

在下面的实验章节中我们会选取不同的beam size进行实验,并分析选取不同的beam size后对系统的性能影响情况。
3 实验
3.1 数据集
本文使用的实验数据集是通过网络以及其他各种途径搜集的问答和一些真实场景中的单轮短文本对话,以此为基础人工标注形成的。最终的语料包括14 000多个短文本问题/回答对,经过人工标注后得到的省略情况如表1所示。
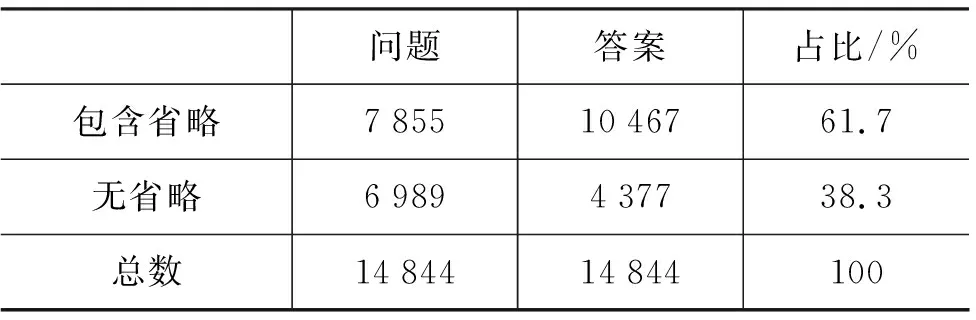
表1 短文本语料中省略分布情况统计
从表1中可以看到,包含省略的实例在全部语料中的总占比为61.7%,无省略的实例在全部语料中总占比为38.3%,包含省略和无省略样例的比例约为1.6∶1,正负样例比例较为均衡。
表2给出了摘自标注语料库的部分示例,其中省略成份以“(*)”表示。

表2 中文短文本省略样例
3.2 实验设置
在语料的预处理工作中,为了方便模型训练,本文在一个batch中将长度不足最大长度的短句填充零元素标识符“
关于实验中超参数的设置。实验中设置隐层神经元个数为1 536个,编码端神经网络层数为2层,batch size大小为50,学习速率为初始值0.001的指数衰减。每50步进行一次衰减,衰减速率为0.98。每个神经单元的dropout为0.2,训练集、验证集、测试集以8∶1∶1进行分割,迭代次数为200次。
关于评价指标,由于在省略恢复任务中,没有一个统一的评价标准。我们借鉴了阅读理解SQuAD中完全匹配的方法,即预测结果必须和标准答案完全一致才算一个正确预测,并采用准确率对模型性能进行衡量。具体方法如式(20)所示。
其中,有省略预测正确是指模型补全后的实例和标准补全后的实例一致,无省略预测正确是指模型未补全的实例和标准未补全的实例一致,具体会在下一小节进行详细的解释。
3.3 实验结果
首先,为了研究不同beam size对模型实验结果的影响,本文选取了beam size从1到20并分别进行实验。实验结果如图4所示,横坐标表示beam size大小,纵坐标表示准确率。
从图4中可以看出,在解码层加入了beam search后系统性能有从0.451到0.550的大约十个百分点的明显提升,这也证明了beam search确实可以增加模型预测结果集合,提高模型的性能。但是,从beam size为2开始,准确率的提升就逐渐放缓。当beam size到17时,准确率几乎没有变化。这说明已经达到模型的性能上限,继续增加beam size只会增加模型训练时间。对于图4中出现的准确率抖动现象,一方面这是由于模型中可学习的变量参数都是随机初始化的,不同的初始化参数通过梯度下降可能会得到不同的局部最优值;另一方面为了节省模型训练时间,本文采用了一种神经网络训练中常用的方法early stop。即在模型训练时,同时观察验证集的损失变化。当验证集损失到达最小时,会提前结束训练。这也就会导致当提前结束时,模型可能没有得到充分学习,从而带来准确率抖动的情况。

图4 不同beam size对模型准确率的影响
另外,本文除了对beam search进行实验,为了能够客观地反映本文中的省略恢复模型的性能,我们还将beam size设置为1。即采用简单的贪心搜索策略,采用语料集上十折交叉验证的评测策略。十折交叉验证的结果分布如表3所示,准确率如表4所示。

表3 十折交叉验证结果分布表

表4 十折交叉验证准确率
表3中,有省略预测正确是指训练样例中目标端序列是存在省略现象的,且模型预测后的补全结果和目标端完全一致,算一次正确的预测;无省略预测正确是指训练样例中目标端没有省略现象,且模型的预测结果并没有对源端序列进行省略补全,与目标端序列完全一致,算一次正确的预测;有省略没有补是指训练样例中目标端序列存在省略,但模型的预测结果并没有进行补全操作,和目标端结果不一致,算错误预测;有省略补错是指训练样例中目标端序列是存在省略的,模型对源端序列进行补全操作后与目标端序列不一致,即补错的情况,算错误预测;无省略预测错误是指目标端序列不存在省略现象,而模型却进行了省略恢复操作,算错误预测。下面本文通过从表5到表9中分别用一个例子来对这五种类别进行更直观的解释。

表5 有省略预测正确的样例

表6 无省略预测正确的样例

表7 有省略没有补的样例

表8 有省略补错

表9 无省略预测错误
由表3可见,在十次实验结果中,有省略补错的现象占有很高的比例。由表8可见,模型在预测时,没有考虑句子的语义信息,故存在“病句”情况,这也在很大程度上制约了模型的性能。另外,从省略恢复结果中可以看出,省略补全的内容大多以主语等语法结构单元为主。这虽符合中文表达的特征,但考虑到省略恢复是为其他任务服务的,对于语义信息的补全可能会比语法结构的补全更加重要。这些问题在后续工作中会重点考虑。
4 总结
本文首次提出了一种基于序列到序列的中文短文本省略恢复模型。该模型在编码层采用Bi-LSTM学习源端序列的抽象表征,在解码层采用beam search算法进行解码,并引入注意力机制让模型自动学习焦点信息。最后,在中文短文本问答和对话语料上的实验表明序列到序列的模型在处理中文短文本省略恢复问题上有较好的表现。
之后的工作会重点处理预测结果中出现“病句”的情况。一方面考虑在模型训练中增加规则限制;另一方面在beam size一定的情况下借助语言生成的相关策略通过后处理对答案进行二次评估,选择更符合要求的结果。
