基于多特征融合编码的神经网络依存句法分析模型
2019-01-22刘明童张玉洁徐金安陈钰枫
刘明童,张玉洁,徐金安,陈钰枫
(北京交通大学 计算机与信息技术学院,北京 100044)
0 引言
依存句法分析一直是自然语言处理中的关键技术之一,广泛应用于机器翻译[1]、信息抽取[2]和语义角色标注[3]等自然语言处理任务中。目前主流的依存句法分析框架主要包括基于转移(transition-based)[4-5]和基于图(graph-based)[6]的两种模型。近年来,基于神经网络的依存句法分析方法日益成为关注热点,是自然语言处理的重要方向之一。本文主要针对基于转移的依存句法分析模型的分析栈和决策层的表示方法开展研究。
早期的方法主要依赖人工定义特征模板提取依存分析过程中的特征[4-7]。主要问题是特征模板的构建需要大量专家知识,而且系统在特征提取上的计算代价较大[8]。后来,基于神经网络的依存句法分析模型显示出了优势[9-12],研究者利用神经网络建模分析栈、缓冲区和决策序列,通过神经网络进行特征的自动提取,将依存分析过程中每一时刻各个部分对应的状态表示为低维稠密的特征向量,不需要人工定义大量的特征模板,避免了复杂的特征工程。基于神经网络的模型主要研究分析过程中特征的表示和利用方法,已有模型[9-11]在局部信息和全局信息的表示上存在以下问题。一方面,没有对单棵依存子树独立编码表示,导致无法利用各个依存子树的局部特征,而依存关系的判断是针对当前两个节点(节点可以是依存子树根节点,也可以是单词)预测正确的转移动作,因此依存关系的建立需要直接考虑依存子树的信息作为特征;另一方面,这些模型没有对历史生成的依存弧信息和转移动作信息进行编码,以致整个分析过程丢失了全局信息,而依存树的建立需要从句子整体的视角考虑更多的全局特征[7]。为了利用更多的局部特征和全局特征,针对分析栈的表示,本文提出基于依存子树和历史已生成的依存弧表示分析栈,利用TreeLSTM网络编码依存子树信息,利用LSTM网络编码历史生成的依存弧序列,以更好地表示分析栈的局部信息和全局信息。针对决策层的表示,本文提出基于LSTM网络的转移动作序列预测,引入历史决策动作信息作为特征辅助当前决策。
本文组织如下: 第1节介绍相关研究;第2节针对多特征融合编码中的局部特征和全局特征,描述基于依存子树和历史生成依存弧的分析栈表示方法,以及基于LSTM网络的转移动作序列预测方法;第3节介绍依存句法分析模型的实现和训练细节;第4节介绍评测实验和结果分析;第5节对本文研究进行总结。
1 相关研究
在基于神经网络的依存句法分析方面,Chen和Manning[9]利用神经网络将单词、词性标签和依存类型标签表示为连续、低维、稠密的向量,只利用少量人工定义的特征模板,就比传统完全基于特征模板的方法取得了更好的性能。该方法主要利用核心特征模板抽取局部特征作为决策输入,其主要问题是没有考虑依存子树的局部特征,而且该方法没有提供历史分析信息参与决策。为了利用更多的历史信息,Dyer[10]等人提出基于转移的Stack-LSTM依存分析模型,Wang[12]等人进一步改进Stack-LSTM模型中依存子树的编码方法。Stack-LSTM模型采用三个单向的LSTM网络编码依存分析过程中的信息,将传统的缓冲区、分析栈和转移动作序列的历史均记录在LSTM单元中,使用LSTM的最后一个隐藏层表示作为决策输入,最后利用多层感知机预测转移动作。该方法实现了完全自动的特征提取,模型精度得到提升。其主要问题是利用LSTM累计的信息表示当前分析栈的状态,无法表示依存子树的局部特征,而依存关系的建立需要考虑节点所在依存子树的信息。Kiperwasser和Goldberg[11]采用BiLSTM网络获取单词的上下文特征表示,用分析栈栈顶的多个元素作为特征,考虑了依存子树根节点单词表示对转移动作的影响,但是没有考虑依存子树的整体信息,也没有考虑历史分析信息,导致决策丢失了全局信息。针对这些问题,本文研究基于依存子树和依存弧相结合的分析栈表示方法,同时研究历史转移动作信息的表示方法,通过多特征融合编码,以有效利用分析过程中的局部特征和全局特征,改进转移动作决策的精度。
2 基于多特征融合编码的神经网络依存句法分析
我们提出基于多特征融合编码的神经网络依存句法分析模型,采用基于转移的依存句法分析框架,主要框图如图1所示。下面从分析栈表示方法、缓冲区表示方法和转移动作序列表示方法三个模块详细介绍我们的模型。

图1 本文提出的基于多特征融合编码的神经网络依存句法分析模型
2.1 基于转移的依存句法分析器
基于转移的依存句法分析框架[4-5]由以下三部分组成: 分析栈S(stack)存放已完成的依存子树,每个元素存放依存子树的根节点;缓冲区B(buffer)存放待分析句子的单词序列;依存弧A(dependency arcs)存放已生成的依存关系(head-modifier pairs)。分析栈栈顶的第一个元素定义为右焦点词,分析栈栈顶的第二个元素定义为左焦点词,它们分别是两颗子树的根节点。三种动作的定义如下:
① SHIFT: 将缓冲区的第一个元素移入分析栈中。
② LEFT-ARC(l): 针对栈顶两个元素,建立左焦点词依存于右焦点词的依存关系。
③ RIGHT-ARC(l): 针对栈顶两个元素,建立右焦点词依存于左焦点词的依存关系。
依存关系的建立发生在左焦点词和右焦点词之间,即子树的根节点。一旦LEFT-ARC(l)或RIGHT-ARC(l)动作发生,两个焦点词中的一个会成为另一个的子节点,即生成一棵依存子树。由此,依存句法分析转换成转移动作决策问题,基于当前分析状态的信息预测下一步转移动作,其核心是依存分析状态的表示和利用,分析状态包括分析栈、缓冲区、依存弧以及转移动作序列。本文的工作集中在基于神经网络的分析状态表示方法,通过设计神经网络结构有效地提取和利用分析状态作为特征,用于转移动作决策。
2.2 分析栈表示方法
分析栈状态包括依存子树(dependency subtrees)和历史已生成的依存弧(head-modifier pairs)。对此,我们提出基于TreeLSTM网络的依存子树表示方法和基于LSTM网络的依存弧序列表示方法。
(1)基于TreeLSTM的依存子树表示方法
我们设计基于TreeLSTM[13]神经网络的结构对已完成的每棵依存子树单独编码,通过门控制机制(gate mechanism)选择输入信息,在合成子树表示时选择性地关注诸如动词、名词等重要节点,从而更好地编码依存子树的表示。已有的分析栈表示方法[10]累计LSTM的最后一个隐藏层向量表示整个分析栈的状态,该结构无法利用依存子树的信息。同时,已有方法[10]采用Recursive Neural Network(RecNN)编码依存子树,该结构在处理较深的依存子树时会出现梯度消失的风险。在此,我们关注每棵依存子树的信息,对于新建立依存关系的头节点和修饰节点,我们定义hhead和chead为建立依存关系的头节点的隐藏层向量和记忆单元向量,定义hmodi和cmodi为建立依存关系的修饰节点的隐藏层向量和记忆单元向量。对于新合成的依存子树,定义hst和cst为依存子树根节点的隐藏层向量和记忆单元向量,hst和cst的计算如式(1)~式(3)所示。

(2)基于LSTM的依存弧序列表示方法
我们提出基于LSTM网络的依存弧序列表示方法,对已生成的历史依存弧序列编码作为全局特征。具体地,当一个依存弧生成时,我们将头节点和修饰节点作为LSTM[14]网络的输入,利用LSTM网络的门控机制选择性的记忆历史信息的特性,累计已生成的依存弧信息,得到全局特征表示辅助转移动作决策。依存弧序列编码计算如式(4)所示。
其中,hhead和hmodi分别表示头节点和修饰节点对应的隐藏层向量。
由此,我们用TreeLSTM对依存子树编码获取局部特征,用LSTM对依存弧序列编码获取全局特征,通过增加对分析栈中局部特征和全局特征的编码表示获取更多特征参与转移动作预测。
2.3 基于LSTM的转移动作序列表示方法

由于基于转移的依存分析框架是一种局部的决策式处理方法,因此需要更多的全局信息帮助句法结构消歧,我们分别累计依存弧和转移动作的历史信息获取全局特征,参与转移动作决策。
2.4 缓冲区表示方法
我们设计基于BiLSTM的缓冲区表示方法,对构成句子的所有单词进行累计的表示,即使单词移除缓冲区,信息也不会丢失,从而避免了单向LSTM编码方式丢失移出缓冲区单词信息的问题[10]。为了获取更加丰富的上下文信息表示单词特征,我们结合LSTM每一时刻的隐藏层向量ht和记忆单元向量ct表示缓冲区中的每一个单词如式(9),式(10)所示。
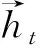
3 模型训练和实施细节
我们利用上面提出的多特征融合编码方法,搭建神经网络依存句法分析模型,模型的训练目标和实施细节描述如下。
首先,我们利用端到端的方法训练整个模型。目标函数采用交叉熵损失函数,添加l2正则化项防止过拟合,通过超参数λ调整目标函数权重,如式(11)所示。
其中,θ表示模型中所有的参数。在选取转移动作时,我们只计算当前状态下有效的动作,例如,当分析栈中元素为空、缓冲区存在单词时,只能执行SHIFT转移动作。最终,在训练阶段,每一步决策按照标准的动作执行分析操作;在测试阶段,我们采用贪心决策算法选取当前概率最大的动作执行分析操作。

在此,我们添加“ROOT”词表示根节点,“NULL”词表示可能用到的无效特征组合(例如,分析栈中元素个数小于3时),未登录词通过高斯采样得到。
最后,关于模型实施具体细节描述如下。我们设置预训练的词向量为300维,可学习的词向量为30维,词性标签向量为50维,所有的ReLU层为300维。设置BiLSTM、LSTM和TreeLSTM结构的隐藏层为300维。在实验中,预训练的词向量保持固定不变。我们采用Adam[16]优化算法用于模型参数学习,设置初始学习率α为5E-4,β1为0.9,β2为0.999。在每一轮迭代中,学习率α以ρ=0.95的频率衰减。设置l2正则化强度为1E-6,训练batch的大小为8。为了防止过拟合,我们使用了dropout[17]正则化技术,设置词向量输入层的drop率为0.2,BiLSTM输出层的drop率为0.5,ReLU层输出层的drop率为0.07。我们对预训练的词向量和最终整合的词向量使用了batch normalization[18]正则技术。其中,dropout层作用在batch normalization层之后。
4 评测实验与结果分析
为了验证本文所提方法的有效性,我们在汉语数据上进行了评测实验。
4.1 实验数据
本文使用宾州汉语树库CTB5作为实验数据,我们采用了标准的数据划分[9],利用标注数据中的分词和词性标签进行依存句法分析,表1给出了CTB5汉语数据的统计信息。

表1 CTB5汉语数据统计信息
4.2 评测实验结果
实验过程中,我们使用UAS和LAS两种评测指标评价模型的性能,和先前工作一致,评测结果不考虑标点符号[9],利用开发集选择性能最好的模型参数用于测试阶段。我们和已有公开发表的基于转移的汉语依存句法分析系统进行了性能比较,比较结果如表2所示。UAS和LAS两种评测指标定义如下。

表2 和已有基于转移的汉语依存分析系统的性能比较结果

续表
① 不考虑依存弧类型的依存正确率(unlabeled attachment score, UAS): 修饰关系正确的单词(包括根节点对应的单词)数量占总词数的百分比。
② 考虑依存弧类型的依存正确率(labeled attachment score, LAS): 修饰关系和依存弧类型都正确的单词(包括根节点对应的单词)数量占总词数的百分比。
从表2的结果可以看出,相比于Dyer提出的Stack-LSTM依存句法分析系统[10],我们的模型在UAS和LAS评测指标上分别取得了0.6和1.1个百分点的提高。相比于Kiperwasser 和Goldberg的依存句法分析系统[11],我们的模型在UAS和LAS评测指标上分别取得了0.2和0.7点的提高。和已有模型的比较结果表明,本文提出的基于多特征融合编码的依存分析模型,对依存子树局部特征、历史依存弧信息和历史决策动作信息的编码对于改进依存句法分析性能的有效性。最终,通过引入更多的局部信息和全局信息参与转移动作决策,我们的模型达到87.8%的UAS得分和86.8%的LAS得分,为目前公开的基于转移的系统中最好的性能。
4.3 模型各个部分有效性分析
我们分析了模型中各个部分对最终依存句法分析精度的影响,实验结果展示在表3中。
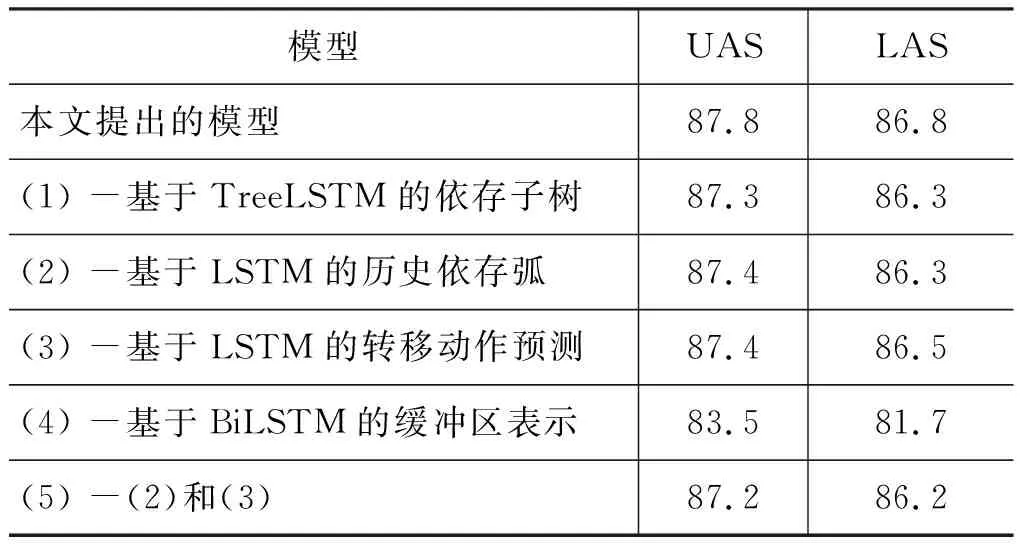
表3 模型各个部分有效性分析结果
从表3的实验结果来看,移除我们模型中的任何一部分(1)~(5)都会降低依存分析的精度,由此证明了我们所提模型中各个部分的有效性。针对分析栈的表示,当移除基于TreeLSTM编码的依存子树表示(1)时,模型没有利用单棵依存子树的信息作为特征预测转移动作,只利用了子树根节点单词基于上下文的BiLSTM隐藏层表示参与决策,模型性能在UAS和LAS评测指标上都下降了0.5个百分点,这一结论表明了依存子树的信息在转移动作预测中的重要性,同时也表明了在预测两个节点之间的依存关系时局部特征需要考虑单棵依存子树节点的完整信息。当移除基于LSTM编码的历史依存弧序列表示(2)时,模型性能在UAS和LAS评测指标上分别下降了0.4和0.5个百分点, 这表明引入历史依存弧的信息作为全局特征用于决策,提高了转移动作预测精度。
针对决策层的表示,当移除基于LSTM的转移动作预测(3),仅利用MLP作为预测函数时,模型性能在UAS和LAS上分别下降了0.4和0.3个百分点。由此可以发现LSTM比MLP在预测转移序列上更为有效,因为LSTM可以传递历史转移动作和分析状态的信息, 从而引入更多的全局特征用于当前决策。
针对缓冲区表示,当我们移除基于BiLSTM的单词特征表示层(4),仅利用词向量表示缓冲区每一个元素时,模型性能在UAS和LAS评价指标上分别下降了4.3和5.1个百分点,由此表明依存句法分析需要从句子整体考虑更多的上下文信息。最终,实验结果表明,本文提出的基于TreeLSTM网络编码依存子树和基于LSTM网络编码依存弧序列的表示方法,以及基于LSTM网络编码的转移动作序列预测模型,通过多特征融合编码,将更多依存分析中的局部特征和全局特征用于转移动作决策,有效提高了依存句法分析的精度。
4.4 不同依存类型的LAS分析
本节针对模型结构对依存分析性能的影响,分别调查了不同类型依存弧的LAS精度,在CTB测试集上的实验结果如图2所示。
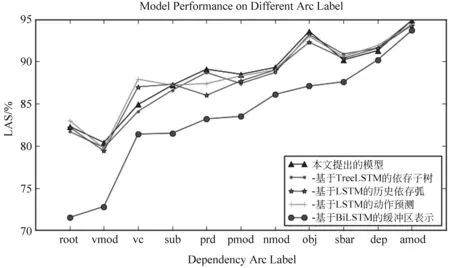
图2 模型结构对不同依存类型的LAS影响结果
从图2的结果来看,root和vmod依存类型的精度较低,表明了这类依存关系较难正确预测。在移除基于TreeLSTM网络的依存子树表示时,图2 的结果展示了利用依存子树作为特征预测转移动作提高了几乎所有依存类型的精度,进一步表明了编码依存子树信息对依存关系预测的重要性。同时,图2的结果也表明利用更多的历史分析信息作为全局特征,包括历史生成的依存弧信息、历史转移动作信息,有效提高了模型在prd、obj和pmod依存类型上的精度。在移除BiLSTM的模型中,图2展示了各类依存关系的精度都呈现了明显的性能下降,这表明基于上下文特征的单词表示,在依存关系预测中有十分重要的作用。
5 总结
本文提出基于多特征融合编码的神经网络依存句法分析模型,采用基于转移的依存句法分析框架。本文基于依存子树和历史依存弧信息表示分析栈,设计基于TreeLSTM网络编码各个依存子树和基于LSTM网络编码依存弧序列,以更好地表示分析栈的状态。同时,设计基于LSTM网络编码转移动作序列,引入了历史转移动作的信息辅助当前决策。最终,在决策时,我们融合了依存子树信息、缓冲区单词信息、历史依存弧信息和历史转移动作信息用于当前转移动作预测,有效结合了局部特征和全局特征。实验结果表明本文所提模型明显提高了依存句法分析的精度。针对未来的研究工作,我们需要利用无标注数据获取更多的依存句法训练数据,以提高模型泛化能力。同时,可以结合基于搜索的技术,如beam-search,进一步改进模型性能。
