人工智能视域下的学习参与度识别方法研究*
——基于一项多模态数据融合的深度学习实验分析
2019-01-22曹晓明张永和闫海亮
曹晓明 张永和 潘 萌 朱 姗 闫海亮
(深圳大学 师范学院 教育信息技术系,广东深圳 518060)
一、引言
参与是学习得以发生的前提。在当前的在线教育领域,MOOCs遇到的一个突出问题就是学习保留率和结业率较低,学习者的学习参与度不高是其中的重要原因[1]。学生参与度识别是研究如何量化评估学生的学习参与情况,进而对学生的行为参与、认知参与、情感参与等维度进行精确刻画分析的专门技术。其目标是协助教师了解学生的参与情况,以便进行及时干预,帮助学生反思自己的学习,并促进其深入参与学习过程。学习参与度被一些研究者看作是在线学习的先决条件,并对学生的课程持续性、学习成绩和结业起到关键性影响[2]。在传统教学领域,精准教学(Precision Teaching)的价值获得越来越广泛的认同。不少学校将精准教学同因材施教和高效互动课堂教学相联系,认为精准教学是实施因材施教的前提和基础。学习参与度是精准教学的重要依据,而人工智能可使学习参与度的识别表现更为准确、便捷,这将为精准教学注入更强大的生命力。
目前,学习参与度的识别在操作上以测量、记录学生的学习表现为基础,以分析频率数据为基本技术,因此,具体采用何种技术对识别的准确率与便捷度有着重要影响。从理论上说,只要有足够多的数据和证据被采集,学习参与度识别就可以做到高准确率,但这容易变成“劳动密集型”(Labour-intensive)的任务(尤以传统的识别方法为甚,因其常以纸笔观察记录或小规模的学习日志数据为媒介),在效率和可信度方面都存在挑战。在过去的二十年中,人工智能研究人员一直试图赋予机器识别、解释和表达情绪的能力;在这一领域进行的研究越来越多,加上信号处理和深度学习的进步,其有可能为学习参与度识别技术的突破提供支持。同时,当前业界对人工智能教育应用的重要性已达成共识,但尚缺少具体的应用场景,学习参与度识别应是其最重要的应用场景之一。但如何将这种场景具体化、模型化,特别是如何选择合适的人工智能方法,以达到较高的学习参与度识别率是亟待深入研究的问题。近年来,在人工智能领域兴起的深度学习方法,从技术架构层面上弥补了传统识别方法的不足,为研究高准确率的识别方法问题提供了新的视角。本文试图采用文献分析与实验研究相结合的方法,在目前已有单模态识别方案的基础上,设计学习参与度识别的多模态融合深度学习模型,并在实验中进行拟合训练,审视该方法与单模态方法的性能比较,以期为相关研究与实践提供借鉴。
二、研究背景与目的
(一)研究背景
本研究缘起于学习参与度识别在实践领域的广泛需求,但当前的研究积累和技术方法尚不能满足实践需要;而人工智能的快速发展,开启了学习参与度识别自动化与智能化的美好愿景。
1.学习参与度及其典型的测量方法
关于学习参与度的研究,始于上世纪80年代对学习投入(Student Engagement)的关注,概念最早由Fisher等人于1981年提出,他们认为学习投入是“学生在完成规定学习任务中的行为表现方面”[3]。近几十年来,学习参与度的理论一直发展和演进,一个重要的趋向是从行为维度向情感与认知维度扩展,如Beane于1990年就指出,情感是学生参与行动强有力的先导动力[4]。Skinner和Belmont于1993年将学生参与度定义为:学生在学习活动中表现出持续性的行为参与,并伴随着积极的情感体验(如,热情、乐观、好奇以及兴趣等)[5]。至今,获得更广泛认同的界定,是2004年美国著名学者Fredricks提出的:学习参与度应该包含三个维度:行为投入(Behavioral Engagement)、认知投入(Cognitive Engagement)和情感投入(Emotional Engagement)[6]。其中,行为参与指个体参加在校期间的学业或非学业活动的高度卷入;认知参与是一种“思维训练”(Exercise of Thinking), 包括学生在学习时使用的认知策略和心理资源的高度卷入;情感参与又称心理参与(Psychological Engagement),指面向学业任务或他人(如老师和同学)的积极情感反应及对学校的归属感。我国学者杨九民进一步指出,这三者是彼此关联且相互伴随的,需对比进行综合评估[7]。
学习参与度的实践发展也催生了其测量的发展,对其已有较丰富的理论论述,但常规的技术方法较落后。我们通过系统梳理近四十年(1980-2018)国内外关于学习参与度测量的1260余篇文献,特绘制了学习参与度测量的研究图谱,如图1所示:
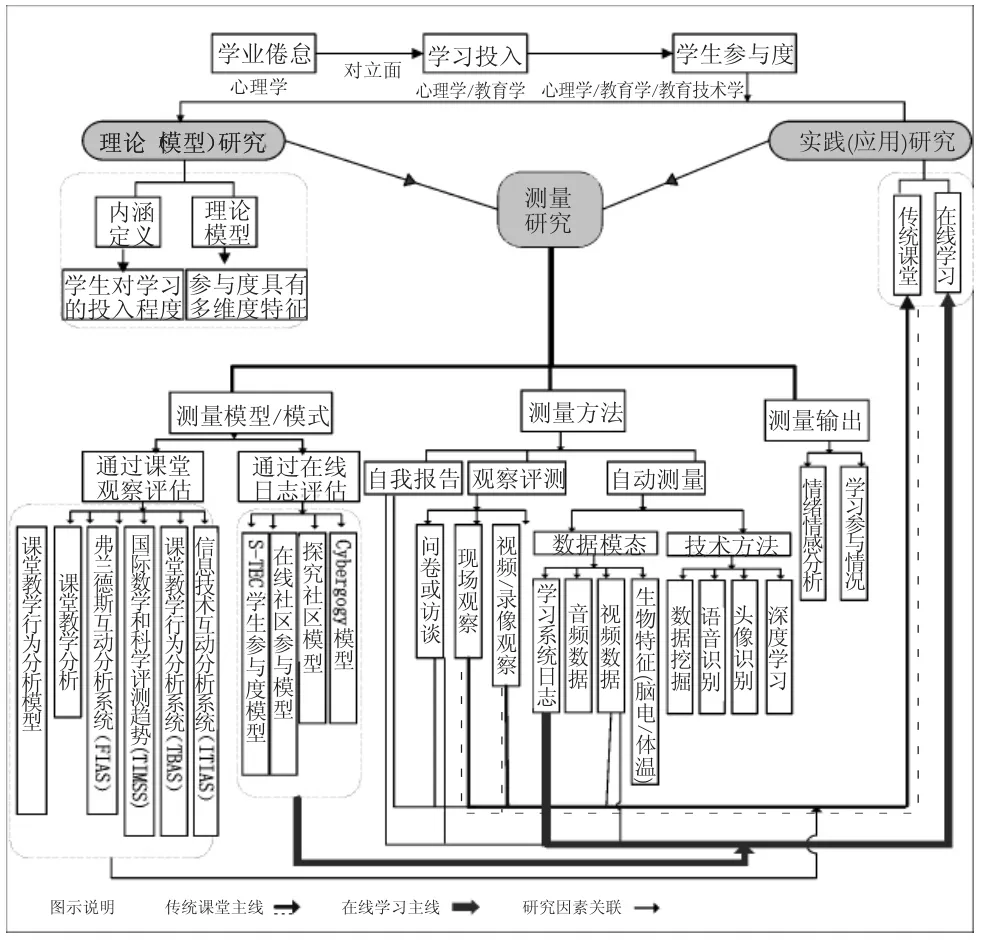
图1 国内外学习参与度测量的研究脉络分析
从图1可见,学习参与度测量的研究地图已经比较完整,呈现了明晰的发展主线,如,在实践领域有传统课堂与在线学习两条主线。自2000年开始,国际上对学生投入(Student Engagement)的研究已从理论研究转向关注测量方法研究,提出的方法主要包括自我报告、观察评分、自动测量三类,其中自我报告被认为是最常见的测量学生参与的方法[8-9]。在这三种方法中,自我报告及观察评分是人工的方法,具有主观性和人力成本方面的局限性,无法大规模实施应用;而作为自动测量方法的学生参与度识别(Student Engagement Recognition),是近年来出现的重要的基于情感计算的学习分析技术,具有多种重要的应用价值[10]。
由于学习参与度识别对教学系统的数据有较高的依赖度,因此自2010年代开始,国际上更加注重教学系统内可识别数据的挖掘和建模研究。该研究通常采用学习分析的思想,将特定的教学场景的识别规律抽象为模型,进而推广到一般教学场景,这种研究一般依赖于场景中可获取的数据类型。目前,主要有三类方法:(1)基于在线学习数据的方法;(2)基于生理和神经传感器数据的方法;(3)基于计算机视觉数据的方法。其中,基于在线学习数据的方法主要面向在线学习场景。学习参与识别在MOOC等“互联网+”教育实践日渐普及的情况下,得到了较多的关注,产生了在线学习学生参与度模型等一系列理论和实践成果。其输入数据有学生答题的反应时间、答题结果、在线交流,用来评估学生在线学习的参与度[11-13]。但这种方法只能在学生在线的情况下才能使用,具有局限性。基于生理和神经传感器数据的方法,是通过生理测量(如脑电图、血压、心率或皮肤电流反应等)来反映参与度和警觉性[14]。但是,这些措施需要专门的传感器,由于经济因素、技术实用性、可穿戴的便捷性等因素,基于生理和神经传感器数据的方法,难以在一般课堂中大范围使用;特别是当前可穿戴设备主要是面向个体的,而面向校园群体应用的智能可穿戴技术仍有待于发展成熟。基于计算机视觉的方法可以通过实时、非接触的方式来采集学生学习的图像数据。这方面的研究,近年来随着机器视觉的发展,而日益受到研究者的关注。
2.人工智能在学习参与度识别中的应用现状与问题
当今,人工智能正在成为新一轮技术变革中的核心,其为学习参与度的识别提供着数据智能(如融合多类型的数据)与技术智能(如深度学习算法)的支持。特别是人工智能中的情感计算技术,可直接用于学习参与度的第二维度(情感投入)的评估,已引起了较广泛的关注。国外已有多名学者通过视频分析脸部特征,来评估学习者的学习参与度[15-16]。国内的相关研究也已经开展,如,程萌萌等提出一种将表情识别与视线跟踪相结合,作为获取表情形式反馈信息的方法。该方法通过摄像头采集学习者面部图像,利用视线跟踪技术定位学习者当前的学习内容;利用表情识别技术监控学生的表情,判断学习者对当前学习内容的兴趣、注意力、知识点的理解和掌握情况,以此为及时调整教学活动、教学进度和方法提供依据,并为学习者提供个别化的学习环境[17]。
孙波等基于面部表情识别的情感分析框架,通过将个体特征和表情特征分离开来,在表情子空间中进行表情识别,排除无关因素对表情识别的影响,提高了表情识别的准确率,并在三维虚拟学习平台Magic Learning的师生情感交互子系统上,实现了基于面部表情的学习者情感识别及情感干预[18]。詹泽慧结合表情识别和眼动追踪技术,构建了基于智能Agent的远程学习者情感与认知识别模型,将眼动追踪与表情监控迭代识别、情感与认知识别过程相耦合,提高了远程学习者状态的识别准确率,改进了Agent对学习者的情感和认知支持[19]。韩丽等结合现有智能监控设备设计的课堂教学评价系统,利用多姿态人脸检测和面部表情识别技术,及时获取学生在学习过程中的情绪变化,反馈给教师,帮助教师准确全面地掌握所有学生在课堂教学中的参与情况,还可指定跟踪对象,对指定对象在课堂中的状态进行统计分析,以便进行个体的针对性指导以及学习问题的及时矫正[20]。刘邦奇等人则基于某中学智慧课堂常态化应用的真实数据,构建了师生互动指数分析模型,并进行了实证分析,为教育大数据的分析和应用,提供了一个应用参考实例[21]。
从文献综述来看,目前,关于人工智能支持的学习参与度识别研究,主要针对的是面部表情识别,这依赖于可信的大数据集。美国心理学家Paul Ekman对5000多种面部运动,进行了分类,建立了开放的数据集,以帮助识别人类情绪,将这项研究提升到了一个新的层次。而我国尚没有建立面向学生面部识别的开放数据集,这有待于后续继续完善。同时,该方向的研究也已经扩展到应用领域。在过去三年里,美国有不少企业把面部识别技术应用到了一线教学当中,如SensorStar实验室用相机捕捉学生上课反应,使用一项叫做EngageSense的技术,运用算法来确定学生注意力是否转移,通过测量微笑、皱眉和声音来测定学生课堂参与度[22]。
法国巴黎商学院于2017年9月,在两门在线课程中使用人工智能工具Nestor,其工作原理是利用计算机网络摄像头,跟踪学生的眼球运动和采集面部表情,再对收集到的数据进行分析,以评估学生的课堂参与度和注意力集中程度。我国的在线教育机构“好未来”,近日重点投资了基于表情识别技术研发的学习状态测评系统FaceThink,其情绪识别引擎可通过人脸检测、关键点跟踪检测,以及情绪识别等,准确识别用户的喜怒哀乐,实时分析用户情绪反馈。课堂场景的应用也已展开,如杭州某中学在2018年5月部署了“智慧课堂行为管理系统”用于对班级环境下学生的课堂行为进行分析,其结果为老师开展精准教学、调整教学策略提供参考。
纵观上述研究与应用,目前已有的分析方法,大多假定依赖某一类数据集即可直接测量学习参与度。但实际课堂教学场景和在线学习场景都并非如此,例如,当前中小学课堂较多采用的平板电脑教学,学习现场经多种传感器采集,在教学过程中得到的包含视觉、声音、学习系统日志记录三种模态的数据,是一种普遍存在的带有领域特征的多模态情境。其中视觉数据和声音数据是按一定频率采样的连续信号,而学习系统日志的产生,属于离散事件(相邻记录的间隔时间没有规律)。尽管,学习参与度识别向目前相对成熟的人脸识别和情感识别方向重点发展,具有一定的合理性。但其完全基于视觉研究的局限性,也是显而易见的(如遮挡问题、专注地闭眼冥想问题等,容易造成误判)。这种视觉自动化系统要在实际学习环境普及与应用,还有很多工作要做。
3.基于多模态进行学习参与度识别的可行性分析
多模态(Multimodality)的概念起源于计算机人机交互领域信息表示方式的研究,其中术语“模态”一词,被定义为在特定物理媒介上信息的表示及交换方式。多模态信息处理技术主要应用于对象识别、信息检索、人机对话等与智能系统及人工智能相关的领域[23]。其它领域的研究业已表明,针对多模态信息融合,通过各模态的交叉检验,将有助于提高正确率。如,由Frome等人开发的DeViSE(深度视觉语义嵌入)的深层架构,是多模态学习的典型例子,其中文本信息被用于改进图像识别系统[24]。在该系统中,训练使用的损失函数,采用了点积相似度、最大间隔和铰链等级损失相结合的方法。结果表明,文本提供的信息显著提高了零样本图像的预测效果,实现了图像模型从未见过的数千个标签的出色命中率。
上述研究成果显示,采用多模态理念的信息处理算法和方法,往往会得到比传统方法更好的性能和效果。学习参与度中情感表达的模态,包括面部表情、语音、姿势、生理信号、文字等,情感识别本质上是一个多模态融合的问题[25]。这些环境和目标参量,单一利用视觉系统、语音系统、日志记录或传感器的描述往往是不充分的。鉴于其它模态也附着丰富的情感语义表达的属性,引入多模态学习参与度识别是顺理成章,且可行的。但从文献看,现有该类别的研究较少,国外也仅见一项基于ENTERFACE数据集进行的初步实验;多模态系统的准确度达到87.95%,超过了最佳单模状态系统的10%以上,或相对而言降低了56%错误率[26]。这显示该领域应是当前学习参与度识别研究中亟待加强的部分。
(二)研究目的
综上所述,对于学习参与度的测量,国内外已经开展了近40年的研究与实践。课堂研究主线和在线学习主线在前30多年的重点并不相同,但近年来随着人工智能技术的再兴起,研究重点开始向人工智能支持的解决方案汇聚。研究人员聚焦于如何利用人工智能中的人脸识别与情感计算等新技术,进行学习参与度的自动化识别。
但仍有几个关键问题尚未解决:(1)相关研究和实践严重依赖人脸的表情,忽视了同样附着丰富情感信息的其它模态信息;(2)国内尚未建立起面向本国各类学习者人群的开放数据集(包括公开的人脸数据集),也缺少建立数据集方法的科学论述,导致相关工作难以展开;(3)已往研究片面地将基于人脸的情感识别等同于学习参与度识别,存在局限性;(4)缺少系统化的基于深度学习的学习参与度识别的论述。据此,本研究的目的主要是:(1)探讨依托深度学习开展学习参与度识别的系统化的方案,厘清其中最重要的几个关键技术点;(2)通过实验,检验提出的多模态学习参与度识别模型的有效性;(3)目前国内的学习参与度识别尚缺少公开的数据集,希望通过本研究能够形成一个针对开放教育领域的学习参与度识别多模态数据集,并开放给相关的研究者参考与采用。
三、研究过程与方法
(一)实验的组织
本研究招募了大学校园中的50名(男18名,女32名)学生参加实验,年龄范围是18岁~25岁;被试中有5名研究生,其余均为大学生,涵盖各年级,且被试专业多数为理工类;实验前要求被试关于实验内容的认知能力无差别。实验工具为脑电设备、摄像头、MOOC视频、视频内容相关的测试题等;MOOC视频截取自中国大学MOOC网的三段10分钟的视频(分别是《马克思哲学原理精粹九讲》、《网络与新媒体应用模式》、《数字营销:走进智慧的品牌》)。选取的片段内容相对完整且趣味程度各不相同,同时,经过初步现场观察,学生在三段视频中学习参与度存在明显差异,以确保能够采集到不同学习参与度的实验元数据。测试题均来自视频的内容,针对每个视频设计了10道单选题。实验数据采集工具为研究团队自行研制的可采集脑电波数据和定时拍照的程序Brain-Analysis,实验环境模拟学生在线学习场景(为便于图像分析加了白色背景幕)。实验场景如图2所示。

图2 被试参与实验及实验过程场景
整个实验,包括数据集构造阶段与深度学习实验阶段两个阶段(见图3)。
数据集构造阶段主要是通过被试采集多模态的原始数据集及标签数据与测试数据,包括四个步骤:(1)依次观看视频。每一名被试在实验环境中,登入BrainAnalysis,脸对着摄像头,头戴脑电设备。在视频播放期间,摄像头会每间隔3秒拍摄一张被试的面部照片,同时脑电设备会记录被试此时的脑电数据,两者按照一致的时间戳标记存储,以便于后续的融合分析。(2)自评学习参与度,打标签。每次提取一张所拍摄的被试自己的面部照片,被试自评照片中自己的学习参与度情况,划分该照片中自己的学习参与度等级(等级3、等级2、等级1,分别对应高参与度、一般参与度、低参与度)(见图4),并为照片打相应标签。(3)他评学习参与度,打标签。每张照片除了自评参与度外,还需要有其他3人进行学习参与度评判。所以系统会自动随机提取未完成他评的其它三个被试的面部照片,然后对照片中被试的学习参与度进行评判,同样为其划分参与度等级(高参与度、一般参与度、低参与度),并为照片标记相应标签。(4)掌握情况后测。在上面步骤完成后,被试需要作答三份测试题,以此检验视频学习效果。

图3 实验过程框架图

图4 不同参与度等级标记的图示样例
深度学习实验阶段主要包括六个步骤:(1)数据集划分。需将总体数据集划分为训练集(80%)、验证集(10%)、测试集(10%)三个部分;(2)数据预处理。完成数据过滤、数据增强与数据归一化,确保数据的可用性;(3)模型设计。需要设计多组分类模型用于后续训练中的对比;(4)模型训练。通过深度学习的算法用训练集训练模型;(5)模型选择。用验证集选择最佳模型;(6)模型评价。用测试集评价最佳模型。
(二)模态选择
现有研究已经证明,在大多数场景下,多模态的效果要优于单模态,但在具体场景中采用何种模态仍需要有针对性地筛选。具体到本研究中预设的在线学习场景,学习者主要通过看视频来进行自主学习,附着面部表情的图片应是第一模态。同时,由于学习参与度包括情感、认知与行为角度,现在已有一些研究者开始关注到脑电波与学习者认知状态的关系(特别是专注度)。
Ramesh Srinivasan等人的研究表明,脑电信号可清楚地包含关于注意方位的信息,可被用来预测注意力方向和水平[27]。李小伟在撰写的博士论文里,开展了基于脑电数据分析的学习过程中注意力识别相关问题研究。他发现当注意力水平被分为三类时,其最高识别率为88.44%;分为五类时,可以达到83.11%[28]。A.Basu等人从面部表情和受试者的脑电图(EEG)信号,提出了一种新的情感识别方法,即从面部表情和EEG信号帧中,提取包括132个小波系数、16个卡尔曼滤波器系数和功率谱密度的EEG特征;然后,通过主成分分析(PCA)减少这些大量的特征;再为5种不同的情绪构建特征向量,采用线性支持向量机分类器,将提取的特征向量分类为不同的情绪类别。实验结果证实,既使噪声的平均值和标准偏差分别高达个体特征的5%和20%,情绪的识别准确度仍保持在97%的水平[29]。
俄勒冈州立大学的Rime Elatlassi,使用实时生物识别技术测量,模拟学生在线环境中的参与度,并将敏锐度、表现和动机作为学生参与的维度;将实时生物识别技术(包括脑电图EEG和眼动追踪测量)用于模拟敏锐度、性能和动机。该方法使用混合模型ANOVA来研究生物特征测量是否可用于预测学生参与,结果表明,眼动追踪和脑电图测量可用于预测学生参与的维度[30]。因此,若具备脑电波的采集条件,脑电数据应可作为学习参与度识别的第二模态数据。而在线学习的自主学习环节产生语音的情况较少(在实验过程中,仅有少部分同学偶尔的哈欠声与询问语音),因此附着的参与度信息较少。我们考虑到深度学习算法的分析效率,因此,暂未纳入本研究的多模态数据集。
(三)数据预处理
数据的规范化和归一化对深度学习的运算效果非常重要,需要对数据进行预处理。本研究的数据预处理按照以下步骤进行:
(1)数据过滤1。对于同一个样本,如果3个评分一致则为有效样本(共有4个独立观察者的评分),保留使用;否则抛弃。
(2)数据过滤2。对于学习参与度为3分(高分)的样本,附加标签为1;学习参与度为0分(低分)的样本,附加标签为0;学习参与度为2分(不确定)的样本,舍弃。经过数据过滤之后,每个学生对应的样本数量会有所差异。
(3)数据集划分。按机器学习的研究规范,将过滤后的样本集进行人工划分:训练集(用于训练模型,约占80%)、验证集(用于选择模型,约占10%)、测试集(用于最终评价模型的准确率,约占10%)。由于训练深度学习模型需要较多的训练数据,因此,一般训练集的样本占比会比较大(50%~90%,各个类别的样本量一般在一千以上);验证集和测试集的样本数量一般相同。
数据集的划分满足约束条件:第一,同一个学生仅出现于一个数据集中,避免用于训练和模型选择的样本出现在测试集中,即测试集相对于所训练的模型是完全未知的;第二,优先保障每个数据集中不同分数段的样本数量均匀;其次,尽量满足不同数据集上男女比例一致(约为1:3)。经过多次调整,最终的划分结果如表1所示。其中,所有数据集中的高低分样本比例都较为均匀;训练集和验证集的男女人数比例一致;由于不同学生的样本数量存在差异,测试集中的男性比例稍高于总体比例。

表1 样本数据集划分情况
样本数据集的划分步骤如下:
(1)对样本中的脑电数据进行常规的归一化处理,即通过线性变换,使总体均值为0、标准差为1。
(2)在人脸识别领域,OpenCV提供的通过分区域检测的算法,已成为当前较为典型的人脸算法[31]。本实验参考OpenCV的区域抽取方法,对每个样本的图像,进行多种区域抽取,包括人脸、左眼、右眼、鼻子、嘴巴。这些不同的人脸区域可以代表人脸的整体和局部状态。在实验中,我们将通过深度学习,挖掘各区域与学习参与度之间的潜在联系。局部区域的抽取也有利于深度学习模型进行针对性的处理,从而减少对样本数量的过度依赖。
(3)为了避免图像识别模型的过度拟合,通常要在训练过程中,对输入的图像进行随机切割。在本实验中,我们随机切割每一种图像20%区域,并统一格式化为64×64的分辨率(见图5)。

图5 预处理过程中对图片的切割示意图
(四)特征数据集的构建与数据标记
关于特征数据集的构建方面,国际上已出现了采用监督学习范式构建某一模态模型的方法,如采用ISEAR数据集,为文本构建情感检测模型[32];采用CK++数据集构建面部表情情感检测模型[33];采用eNTERFACE数据集建立一个从音频中提取情绪的模型等[34]。这些模型为本研究在表征对应模态特征模型时提供了参考,同时也使本研究在多模态数据特征集的提取及标记时,有了较成熟的处理方法。参考相关研究,我们将每一个时间段所采集的数据总和作为一个样本,通过多名观察者评估,并只保留一致性较高的评估值。
在数据集的标记方面,众包是当前对海量数据进行标签的常用方法。一个典型的案例是Kamath于2016年开发了一个数据集,模拟MOOC环境的实际情况,将采集到的图片发布到网络平台上,使用众包标签进行参与识别[35]。我们也采用了类似众包的方式进行标记,由被试志愿者完成数据集中的所有图片记录的标记,并通过自评和3名他评的4个数据进行一致性人工标记的校验。特征数据的提取与人工标记过程,见图6。

图6 特征提取与人工标记
(五)多模态融合模型的设计
1.多模态融合策略的选择
多模态数据融合是发掘数据价值的重要条件。在本研究的多模态环境中,计算机可采集学习活动相关的多种信息(包含学习现场监控视频及语音,脑电波数据、在线日志学习记录等),如何根据计算机所采集的这些多模态信息,来综合判断学习参与度,需要选择一种合适的多模态融合策略。目前,深度学习领域典型的多模态融合策略主要有三种:前期融合、后期融合与混合融合[36]。三者的具体策略及优缺点,见表2。

表2 多模态融合策略对比
综合考虑时间尺度和测量值的不同,并考虑到已有人类决策者对数据进行了相对可信的标记,本研究采用后期融合策略,将多个单模态二元分类器进行集成,设计了多模态融合框架,见图7。该模型中的分类器及合并模块,均可采用深度神经网络实现(如卷积神经网络、多层感知机等),从而构建出一体化的多模态深度学习模型。比较非一体化的模型,这种统一模型的优势在于:(1)采用相同的数学理论进行求解,有利于进一步深入的研究;(2)在训练过程中,该模型可以对比多模态融合前后的效果,有利于从训练过程上获得更好的融合结果。
2.深度学习模型设计
(1)多模态融合框架设计。图7显示的是二维向量,yi=fi(xi)代表两个学习参与度级别的预测概率(概率大的级别则为所得的预测级别),其中(i=1,2,…,8)代表不同的信息模态。通过拼接向量的方式实现多模态信息融合,即 xi=(y1,y2,…)。 函数 f1,f2,fs的输入为图像,均为卷积神经网络结构(Convolutional Neural Network,CNN);函数 f6,f7输入为向量,均为多层感知机结构(Multi-Layer Perceptron,MLP)。

图7 基于后期融合策略的深度学习模型
图7 中各符号的具体含义如下:①二元分类器:输入特定模态数据,输出一个0到1之间的值(代表学习参与度的预测值,0代表最低分,1代表最高分),结合阈值则可用于二类判别;根据输入的不同,二元分类器可以选择不同的神经网络结构实现,如采用CNN实现图片(实为矩阵)的分类,采用MLP实现向量的分类;②合并运算:将多个标量合并为一个向量,起多模态信息融合的作用;③基于脸部的预测模型f1:采用CNN结构,输入人脸整体图像x1,输出预测值 y1=f1(x1);④基于左眼的预测模型 f2:采用CNN 结构,输入左眼图像 x2,输出预测值 y2=f2(x2);⑤基于右眼的预测模型f3:采用CNN结构,输入右眼图像 x3,输出预测值 y3=f3(x3);⑥基于鼻子的预测模型f4:采用CNN结构,输入鼻子图像x4,输出预测值 y4=f4(x4);⑦基于嘴巴的预测模型 f5:采用 CNN 结构,输入嘴巴图像 x5,输出预测值 y5=f5(x5);⑧基于综合图像的预测模型f6:采用MLP(多层感知器)结构,输入向量 x6=(y1,y2,……,y5),输出预测值 y6=f6(x6);⑨基于脑电的预测模型f7:采用MLP结构,输入脑电信号 x7,输出预测值 y7=f7(x7);⑩总预测模型 f8:采用MLP 结构,输入向量 x8=(x6,x7),输出预测值 y8=f8(x8)。
(2)总预测模型与各子预测模型之间的关系。总预测模型是对各子模型预测结果的融合,可实现上文所介绍的后期融合策略。每一种子预测模型有各自的优势和劣势,通过总预测模型对预测结果进行综合,以期达到“扬长避短”的效果,提高最终的预测效果。
(3)CNN分类模型的选择。卷积神经网络是一类多层神经网络,在图像分类识别方面有着较出色的研究成果,在其发展过程中,先后出现了许多优秀的网络模型。根据Canziani A.等人在2016年对各种网络模型的性能比较[37],以及查阅ImageNet大规模视觉识别挑战赛(ILSVRC)中出色网络模型的相关论文[38],目前主流的分类模型有 Vgg16、Vgg19、Inception v3、ResNet50和Xception等5种。为了确定选用何种模型,研究团队针对上述5种模型,进行准确率与训练时间的对比实验。实验的结果如表3所示。
根据实验结果,ResNet架构的综合表现最好(其在ILSVRC 2015比赛中获得了冠军,取得3.57%的top-5错误率,是目前最好的CNN架构之一),因此,本研究选择ResNet50作为学习参与度识别的分类模型。

表3 CNN分类模型的对比实验结果
(4)ResNet的容量调节。 模型的容量(Capacity)是指模型拟合各种函数的能力,常常影响模型的好坏。如果过小,则会欠拟合(训练效果较差);如果容量过大,则容易导致过度拟合现象(训练效果很好,但是预测未知样本的能力却较差)。标准的ResNet需要十万级的样本量才能让模型达到较好的效果;由于本实验中的样本量较少,在实验中需要减低模型的容量来达到最佳的拟合效果。为了调节ResNet的容量,我们令模型中的所有卷积层的通道数量都表示为C·α的形式。其中C为常量(ResNet中的四个残差模块,先后取 C=1,2,4,8),是可调节参数。通过调节的大小,可以控制模型的容量。在实验中,C的值从1开始,每次增加4,最大不超过48(容量再大的模型,单模型的训练时间过长)。
(六)模型训练与选择
实验中包括 8种容量(取{2,4,8,16,24,32,40,48}),每一种容量下包括8个预测模型,因此共有64个候选模型。每个模型的误差函数采用交叉熵损失函数(Cross Entropy),训练算法采用Adam,训练过程平均迭代100次。模型的准确率(Accuracy)是指正确预测样本量占总样本量的比例。在训练中,实验通过验证集评价模型的准确率,从候选模型中选出验证集准确率最高的模型,作为最佳模型。
四、研究结果
模型训练总时长约为64小时(平均每个模型需要约1小时),所有模型的训练误差都达到收敛,如图8所示。除了基于脑电的预测模型和基于鼻部的预测模型以外,其它模型在训练数据集上的准确率均达到90%以上,说明这些模型达到了训练目标。

图8 模型训练中的训练误差收敛趋势
模型训练后,本研究对模型在验证集上的准确率进行统计,得到如下结果:
(一)候选模型训练结果
模型的选择依据的是模型在验证集上的表现,所有模型在验证数据集上的准确率,如表4所示。

表4 候选模型在验证数据集上的准确率(%)
在实验结果中,α大于24的模型在验证集上的准确率约在75%。具体而言,对于相同容量条件,在预测模型中,总预测模型f8、基于综合图像的预测模型f6、基于左眼的预测模型f2在验证集上的准确率(本段中均简称“准确率”)都超过77%。在候选模型中,总预测模型取α=48时,准确率最高,为87%;其次是基于左眼、右眼、综合图像的预测模型(均高于85%)。基于脸部的预测模型准确率为75.8%,与平均水平(72.5%)相近。基于脑电、嘴巴、鼻子的预测模型准确率均低于平均水平。
(二)最优模型的选择及测试集验证结果
根据表4的结果,我们将总预测模型f8选择为最优模型;将最优模型用于测试集(用于模拟真实环境中完全没有输入过的数据)中,其准确率为81%。表明该模型对测试数据集已有较高的识别准确率。但通过抽取具体的样本,我们发现该预测也存在误判的可能性。详细预测结果如下所示。
(1)正确预测级别 3(高)的例子:

(2)错误地高估为级别3的例子(学习参与度的实际观测值为级别1):

(3)正确预测级别1的例子:

(4)错误地低估为级别1的例子:

通过上述的数据我们也发现,利用深度学习的方法来预估参与度,“误判”的可能性是客观存在的,在于图像模态的数据中尤为明显。究其原因,是学习者某些时刻的表情,孤立来看是模棱两可的(如参与级别高的表情和参与级别低的表情是比较相近的),如果单独地看,难以区分。要提升这方面的准确率,除了扩大数据集的样本量外,还需要考虑动作序列和上下文的图像序列(具体的策略见后文关于时序数据库的表述)。
(三)学习参与度与学习效果的关联结果
在实验过程中,每个被试均要对自己的参与情况打标签(EV1),并对另外三位被试的数据打标签(EV2、EV3、EV4),通过将记录的日志模态的数据导入SPSS,我们发现:自评和他评的数据存在一致性,采用众包(他评)的方法是可行的。同时,每个被试在实验的最后环节,需要针对视频中的学习内容做学习效果测试,得出一组测试分数(Mark),通过统计分析,得出表5。

表5 学习参与度评估值与学习效果(成绩)的相关分析
如表5所示,MOOC视频1、2、3对应的Mark成绩均值依次为:6.66、4.98、3.66;自评分数(EV1)均值依次为:2.28、1.84、1.70;众包分数[(EV2+EV3+EV4)/3]均值依次为 2.55、2.04、1.69。 由此可见,不论是自评还是众包,学习效果(Mark)和学习参与度的评价分数成正比。并且,学习者在视频1中的学习参与度最高,在视频3中的学习参与度最低。
需要进一步说明的是,本实验中的三段视频的选取并不是随意的,而是事先经过被试同群体不同个体的调研,按照学习者对学习内容感兴趣的可能程度,分为“很感兴趣、比较感兴趣、不感兴趣”三个级别分别选取的。被试的学习效果、标签的评分情况也在一定程度上反映了其对视频的学习兴趣变化情况。
五、讨论与反思
(一)基于多模态融合的模型及基于眼部的模型准确率较高
总预测模型的正确率高于其它模型正确率,说明多模态融合模型比单模态模型具有一定的优势。在单个输入模态的模型中,基于眼睛的预测模型较好,接近于综合模型的表现。常识经验符合,即通常人们可以通过眼睛状态来判断个体的学习投入情况。在实验中,我们发现基于左眼的预测模型比基于右眼的预测模型,在平均准确率上高出3%,如图9所示(该项数据是否有统计学上的意义,还需要进一步地扩展数据集进行验证)。

图9 不同模态输入下的模型准确率对比
(二)基于脑电的预测模型准确率较低
图10 脑电的时序模态图
基于脑电的预测模型准确率较低(60%),其原因可能与脑电本身时序性的波动性质有关(如图10所示)。对于相同的学习参与度观测值,对被试测量的专注度和放松度均出现波动现象,这种现象说明,预测模型本身需要具备时序分析能力(如LSTM),才可以挖掘输入数据的时序模式。
我们对这一现象进行了进一步的文献分析,发现在多模态融合实验中脑电波数据的准确度不高,这一结果也同样出现在其他研究者的实验当中。如Yongrui Huang等提出,两种用于情绪识别的脑与外周信号之间的多模式融合方法(其输入信号是脑电图和面部表情),共有20名健康受试者参加了两次实验。研究发现面部表情的准确率为74.38%,脑电图检测的准确率为66.88%,但两者融合则可达81.25%。这说明尽管EEG的准确率不高,但信息的组合补偿了它们作为单个信息源的缺陷[39]。Soleymani M.等提出了从脑电(EEG)信号和面部表情瞬间检测视频观众情绪的方法,结果也发现面部表情的结果优于EEG信号的结果[40]。原因可能在于面部肌肉活动污染对EEG信号的影响。但最终统计分析显示,在面部表情存在的情况下,EEG信号仍然带有补充信息。除此之外,也不能排除脑电波采集设备本身的影响,即采用更多通道的EEG设备,是否对提升准确率有帮助仍有待后续验证。
(三)容量自动调节机制支持高效的模型选择
容量越大的模型,准确率越高;但是当达到一定程度时,准确率提高的幅度会越来越小。通过自动化地增加模型容量进行逐步实验,可以减少人工调节模型,自动地搜索出容量合适的模型。本实验中的模型容量与准确率的关系见图11:

图11 模型容量(横轴)与准确率(纵轴)统计关系
(四)模型具有一定预测能力,但其泛化能力不够理想
模型的泛化能力越强,表示模型的通用性越高,更适合处理未曾处理过的数据;否则,模型的泛化能力弱。实验中选取的最佳模型在测试集上的正确率(67.5%)高于50%,说明模型具备一定的预测能力。然而,模型在测试集上的正确率低于在验证集上的正确率(87%),这说明模型的泛化能力没有达到理想的目标,即不能对未知样本作出较为正确的判断。
(五)模型泛化能力不足的原因探究
经过分析,主要的原因应是验证集和测试集的数据分布不一致。模型选择依赖于验证集,如果验证集与测试集的数据分布差异太大,则会直接影响模型在测试集上的准确率。我们搜索在测试集上准确率最高的模型,具体如表6所示。其中“α=48,总预测”一项为实验中选出的最佳模型,在测试集上的准确率仅排在第10位;而“α=24,左眼”则以非常高的准确率(90.6%)排在第1位。这说明,虽然本实验所选取的验证集和测试集分别在性别和参与度级别方面都较为平衡,但是仍然有性别、参与度级别以外的其它未知因素,影响其数据分布规律,其中可能的因素包括被试的表情习惯、行为习惯等。
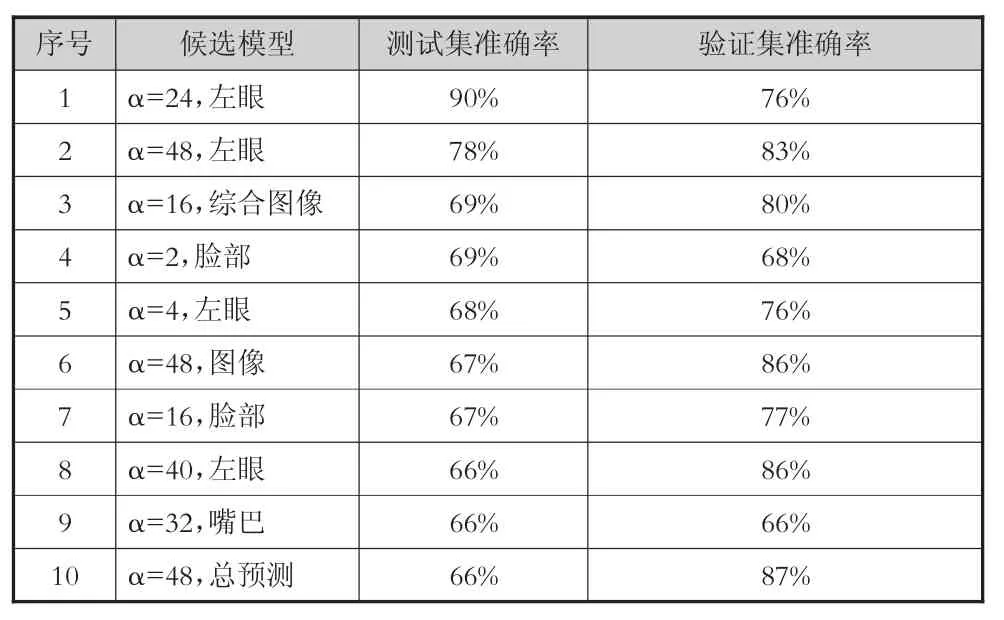
表6 候选模型在验证数据集上的准确率(%)
(六)数据集采集中的“霍桑效应”
作为一项实验研究,比较容易对结果造成影响的就是霍桑效应(Hawthorne Effect)。所谓“霍桑效应”,是指当被试在意识到自己正在被关注或者观察的时候,会刻意去改变一些行为或者是言语表达的倾向[41]。本实验中采集数据的过程是在实验室中完成的,被试开始MOOC学习前即被明确告知是一项教学实验,尽管已经不断和被试强调用放松的状态自然地完成学习过程,但这仍然有别于现实世界中的数字化学习环境(个别被试的画面显示其在镜头前是拘谨的),数据集有可能存在一定程度的误差。若要有效避免这一问题,需要选择真实的MOOC课程的用户,进行过程性数据集采集,但这又可能涉及到数据伦理的问题。可行的解决方法是采用“事前不告知、事后告知”的方式,来减少“霍桑效应”的影响。
六、研究结论
深度学习的实验有别于传统的社科实验,是对某一项具有精确解的问题的求解过程。本研究设计了三段不同风格的MOOC视频,采集了学习者在学习过程中的图像模态数据、脑电模态数据及学习日志模态数据,并通过自我标签和众包标签的方法,对数据集进行标记,形成学习参与度识别的原始数据集。通过完整的深度学习实验,我们发现学生的学习参与度识别的一些共性规律,即学习参与度的识别与自动识别有很高的复杂性,不同模型的识别效率和准确率差异很大。总结以上实验结果和发现,本研究得出如下结论:
第一,针对学生的学习参与度识别,基于多模态融合的模型优于单模态模型;在单模态模型中,基于眼部图像的模型最接近于多模态融合模型的准确率,这也显示眼部可能是学习参与度识别中最重要的单模态数据。
第二,图像模态的准确率可达80%,显示其已有一定的可信度;脑电模态的准确率为60%左右,但相对图像模态准确率的测试结果更为稳定,可补偿图像作为单个信息源的缺陷,将两者融合可达到87%的多模态融合准确率。这表明尽管增加一个模态,深度学习的时间消耗和运算复杂度会呈指数级上升,但带来的准确率提升也是客观的。
第三,容量自动调节机制支持高效的模型选择。本研究所选择的最佳模型在测试集上准确率为81%,说明其具有一定基础的预测能力。
第四,由于验证集和测试集的数据分布不一致,所得到的最佳模型泛化能力可能不够理想。因此,构建规模更大的数据集,将有望改进现有模型。
七、未来展望与建议
学习参与度识别的应用前景广阔,既包括普通的教室场景,也包括在线教育领域,未来将是人工智能教育应用的重要实践场景。在教室中应用学习参与度识别技术,可帮助教师收集更多的数据来了解学生的学习参与程度(包括针对学生个体的学习诊断和针对班级群体的学情分析),以提醒老师动态调整教学策略;在在线教育领域,学习参与度识别也有可能成为MOOC质量保障的重要评估维度,并为个性化学习提供证据支持。虽然学习参与度识别在人类看来是个直观观察的简单过程,但对机器来说,却是个需要利用丰富数据进行推演的复杂过程。本研究尝试提出了一种基于多模态数据融合的深度学习参与度识别方法,但由于被试是在模拟环境而非真实环境中学习(尽管每个被试实验前已通过言语沟通使其尽量放松)、模态还不够多样(考虑效率后选用两个最重要的模态)等客观因素的限制,不可避免地存在一些局限性。为此,结合本研究的过程并参考其它已有相关研究进展,我们对学习参与度识别的未来研究,提出以下四点建议:
(一)通过协作机制建立更大规模的本土数据集
深度学习的一个经典隐喻就是 “更多的数据会打败一个聪明的算法”,因此,数据集是开展深度学习训练的基础。但目前关于学习参与度识别的主要开放数据集来源于国外。如,Kamath A.等人通过众包技术,建立了基于在线课程的学习视频图像参与度等级自定义数据集[42];Whitehill J.等人收集了学生在使用iPad学习时的视频图像数据,构建了该场景的自定义数据集[43]。同时,MIT媒体实验室研究员Joy Buolamwini与微软科学家Timnit Gebru于 2018年初的一项联合研究显示:商用的人脸识别方案可能存在种族准确率差异,如识别准确率黑人比白人差很多,肤色较黑的女性识别误差率甚至高达35%[44]。这显示当前建立面向本国学习者人群的开放数据集,存在必要性和迫切性。本研究提供的开放数据集容量已经有3万多条记录,但数据规模还不足够大,且是18~25岁的成人学习者,尚不能直接应用于中小学生的评估场景。当下,在缺少大型企业介入建立免费数据集的情况下,各研究团队通过协作共享的方式建立数据集,就显得尤为必要。
(二)通过众包的方法提高数据标记的质量
对采集的各模态数据进行标记(即打标签)是一项费时、费力、经济成本又高,但却对深度学习至关重要的工作。众包是当前对数据集标记的常用方法。通过众包我们很容易获得大量的带有标签的数据,速度快且费用低廉(如在亚马逊众包平台标注一个图像数据,通常都不到1美分)。众包方法可以同当前的共享经济理念结合,让更多熟悉学习者参与度特征的教师,参与到数据标记的工作中来,这将大大提高当前学习参与度识别的数据标记质量。
(三)扩展学习参与度识别的技术方法
现有的相关研究和实践,严重依赖通过对人脸的表情识别来判断学习的参与度,忽视了同样附着丰富情感信息的其它模态信息,得到的证据是不全面的,也难以覆盖所有的学习场景和学习的全过程。目前在传统课堂、完成纸质作业等非在线领域,已遇到很大挑战。而在国外也有了一些研究开始关注其它技术方式:一种趋向是从人脸扩展到身体的其它部分,如A.Kapoor等利用身体姿势来评估学生参与度[45],J.Grafsgaard等利用手势来判断参与度[46];另外一种重要趋向就是多模态,从当前依赖于视频采集的图片单模态,扩展到多模态的数据。目前,除声音模态外,包括脑电波传感器、眼动仪、电子手环等学习者生理与认知状态相关的传感器,已经可以为学习参与度提供一些可信的证据数据,有可能通过“无感”、“自然”地采集学习者的生物特征信号,从而识别更多类别的情感。
(四)从注重切片转向注重时序
当前的学习参与度识别主要是基于视频切片获取的,在时间轴上是点式非连续的;同时,由于运算效率的要求,切片的间隔不能太短,而学习参与度(特别是其中的情绪投入)是连续的变量,切片导致当前的学习参与度识别失真。从2017年开始,一种叫做“时序数据库”的新技术开始风靡,如Facebook开源了Beringei时序数据库、PostgreSQL推出了时序数据库Time ScaleDB,在智慧城市等领域已有较丰富的应用。时序数据是基于时间的一系列的数据,能够揭示数据的趋势性、规律性、异常性。因此,适合大数据分析和机器学习以实现预测和预警,这恰恰是学习参与度识别迫切需要解决的。因此,今后一种显性的变化应是基于图片的参与度识别,有可能要转向基于视频片段的参与度识别。
深度学习多用于工业商业领域,很少用于教育领域。本文实验展示了深度学习用于学习参与度识别的具体方法;除去客观原因,采用多模态融合的方法,对学习参与度识别准确率的提高效果是较显著的。同时,我们还可以将实验分析得到的最佳模型,用于后续关于学生学习参与度识别的项目中,这体现了深度学习在教育领域中的一种潜在应用。相信随着技术的不断优化和成熟,深度学习会越来越多地应用于教育领域,特别是在开放教育领域。
