基于边缘特征的视频字幕定位及字幕追踪方法
2019-01-22赵义武张晓东李慧莹
赵义武,张晓东,李慧莹
(1.长春理工大学空间光电技术研究所,长春 130022;2.长春理工大学计算机科学技术学院,长春130022;3.上海海事大学信息工程学院,上海 201306)
0 引言
随着互联网服务的快速发展,视频传播已相当便利,每分钟都有数百小时的视频内容被上传到视频服务网站。目前视频检索主要使用标签标题匹配关键字等方式[1],检索方式相对单一,视频标题对视频内容的反映也不够细致,为此,根据视频字幕内容进行检索可以作为补充方法之一。当前视频传播全球化已经成为趋势,人们可以方便地观看到不同国家用户上传的优秀视频,但因此也可能会遇到文字不通的情形,所以实现对视频字幕的自动翻译可大幅提升观看体验。
视频字幕分为软字幕和硬字幕,软字幕即外挂字幕,是与视频内容分开的单独文件,该类型的字幕无需从视频中提取,可直接对其文本做内容分析。在视频制作过程中,为了有更好的兼容性,往往将视频字幕内嵌在视频中,再去传播,用户看到的字幕多数时候也都为该类型字幕,称为硬字幕。硬字幕如同水印一样与视频画面相结合,无法简单分离,不能直接对其做内容分析。硬字幕需要经过字幕提取与识别,转换成文本形式的字幕之后,才可实现检索和翻译等后续功能。本文讨论的视频字幕均为硬字幕,对其提取过程中的字幕定位和字幕追踪方法做详细地研究。
1 字幕定位
视频字幕往往只占据了视频画面的一小部分,画面的大部分都是与字幕无关的视频背景,本文不对背景中可能包含的场景文本[2]做分析,所以该背景区域可被视为干扰区域。字幕定位[3]即是准确找出包含字幕的区域,并将字幕之外的干扰区域全部标记删除。
本文提出基于图像的边缘特征[4],统计边缘图像跳变次数的字幕定位方法。
1.1 算法设计
(1)由于视频字幕在画面中停留时间往往在1秒以上,每秒视频又包含24帧或更多帧,所以无需对视频每一帧都做处理,每4帧选取1帧做处理不会遗漏任何一条字幕,后续所有步骤均不再包含被剔除的视频帧,可大幅减少运算量。
(2)将筛选得到的视频帧做灰度化处理,得到的灰度图像由于存在复杂的背景,无法避免产生大量的噪声,为防止噪声对字幕定位产生干扰,需要再对灰度图像进行去噪处理,以提高对图像边缘的检测效果。在此阶段,对灰度图像添加强度为0.01的椒盐噪声,再使用大小为3×3的方形窗口对图像进行中值滤波。采用中值滤波不仅能够覆盖大部分的噪声区域以消除干扰的噪声点,也可以较好地保护图像边缘信息[5]的特征。
(3)利用Sobel边缘检测算子对灰度图像进行边缘特征提取,得到边缘二值图像。
(4)对筛选过的每一帧的边缘二值图像中的每一行(列)进行扫描,统计各行(列)的跳变次数(像素值由0变为1或者由1变为0均计一次跳变),得到边缘图的行区域(列区域)的跳变次数分布。
(5)将每一帧同行(列)的跳变次数做加和运算,得到关于整段视频的行区域(列区域)的跳变次数分布。后续步骤全部使用所得到的整段视频的行区域(列区域)的跳变次数分布。
(6)找出整段视频跳变次数最大所在行和最大所在列的交点,将该交点作为字幕区域的中心点。
(7)从中心点向上扫描,若连续5行的行跳变次数均小于最大行跳变次数的0.5倍,则停止扫描,并记该行为字幕区域的上边界。同理从中心点向下扫描,找到字幕区域的下边界。
(8)从中心点向左扫描,若连续5列的列跳变次数均小于最大列跳变次数的0.2倍,则停止扫描,并记该列为字幕区域的左边界。同理从中心点向右扫描,找到字幕区域的右边界。至此,得到字幕区域的上下左右四个边界,完成字幕定位步骤。
1.2 算法分析
该算法得到的字幕区域是应用于整段视频的字幕区域,是一个固定的窗口,适用于字幕出现区域相对稳定的视频。在视频时长越长,字幕条数越多的情况下,由于包含了更多的字幕边缘信息,该字幕定位方法得到的效果会越好。
图1所示为未经过字幕定位的灰度图像。

图1 未经过字幕定位
图2所示为选取的三条经过字幕定位的图像。

图2 经过字幕定位
2 字幕追踪
每一条相同的字幕会出现在若干帧画面当中,对每一帧经过字幕定位之后的画面都做文本识别处理不仅会浪费大量运算时间,而且无法避免同一条字幕出现不同种的识别结果。按照字幕出现状态,视频的每一帧可以分为无字幕和有字幕两种[6],如果有字幕出现,则需要进一步判断该画面和上一帧画面是否包含的是同一条字幕。字幕追踪主要完成对每一帧画面的归类,判断该视频帧属于哪一种字幕状态,便于后续对包含相同字幕的画面只做一次文本识别。
本文提出利用相邻若干帧边缘图像,对比重叠度的字幕追踪方法。
2.1 算法设计
取经过边缘提取和字幕定位之后的每一帧图像,该图像是只包含字幕区域的二值图像。由于视频末尾1秒钟通常情况下不会有新字幕出现,所以放弃对末尾4帧的字幕追踪,只对从第1帧开始,到倒数第5帧结束的所有视频帧做字幕追踪。
(1)将所有视频帧赋初始编号值为0,用0表示该帧无字幕出现。使用i记录当前操作的帧的序号,使用j来记录当前已经出现的字幕条数,使用temp来记录该次运算中出现的字幕是否为新字幕,设i,j,temp的初始值均为0。
(2)取第i帧和其后4帧的图像,由于所取图像全部是二值图像,所以可以做矩阵加和运算,得到新矩阵,该新矩阵中的每个元素值最大为5,最小为0。
(3)如果该5帧包含相同字幕,其边缘图像会有大量完全重叠交织的地方,在新矩阵中体现为等于5的元素值数量占比会较大。如果该5帧中包含不同字幕,或者不包含字幕,那么该5帧的边缘图像完全重叠部分较少,在新矩阵中体现为等于3和等于4的元素值数量占比会较大。用x记新矩阵中等于5的元素值的数量,用y记新矩阵中等于3和等于4的元素值的数量之和。
(4)比较x和y,若x大于y,则认为该5帧中均包含相同的字幕,转到步骤(5),若x不大于y,则认为该5帧中并非均包含相同字幕,转到步骤(6)。
(5)若当前temp等于0,则j加1,若当前temp等于1,则j不变。将第i帧和其后4帧的编号值均改写为 j,令temp的值等于 1,转到步骤(7)。
(6)不改变任何视频帧的编号值,只令temp的值等于 0,转到步骤(7)。
(7)令i加1,如果i等于倒数第4帧的序号值,则字幕追踪全部完成,否则转到步骤(2)。
完成字幕追踪后,每一帧都被赋予了一个编号值,该编号值代表了字幕状态,编号值等于0表示该帧无字幕,编号值相同的帧代表字幕也相同,编号值的数值代表该条字幕是整段视频的第几条字幕。
2.2 算法分析
该算法要求一条字幕至少出现在20帧的画面中,且对字幕文本区域较大且边缘轮廓较明显的视频帧图像具有较好的字幕追踪效果。如果一条字幕出现在少于20帧的画面中,由于其存在时间过短,则有可能该条字幕为特殊符号或语气词,该算法则会忽略该条字幕。
3 实验结果
字幕提取的前期处理步骤包含字幕定位与字幕追踪,在字幕追踪完成之后,所有视频帧均已经标记出字幕所在区域,并且已经按照相同字幕分为一类的规则进行了分类,之后只需在每一类中选取一帧图像做字幕识别[7],即可完成所有的字幕文本转化。
3.1 实验数据
选取10段时长在40秒左右的电影视频,对其做字幕定位与字幕追踪实验,主要记录字幕定位阶段是否能将字幕区域完整标识,以及字幕追踪阶段能否准确将每一帧图像进行归类。实验结果如表1所示。
表1中“字幕追踪误认字幕”表示字幕追踪过程误将无字幕的视频帧判断为存在字幕。

02号和06号视频均由于最后一条字幕出现时间少于1秒,导致字幕追踪没有成功识别出该条字幕。
07号视频由于边缘信息明显且背景相对固定,导致字幕追踪误将无字幕的视频帧判断为了存在字幕,如图3所示。
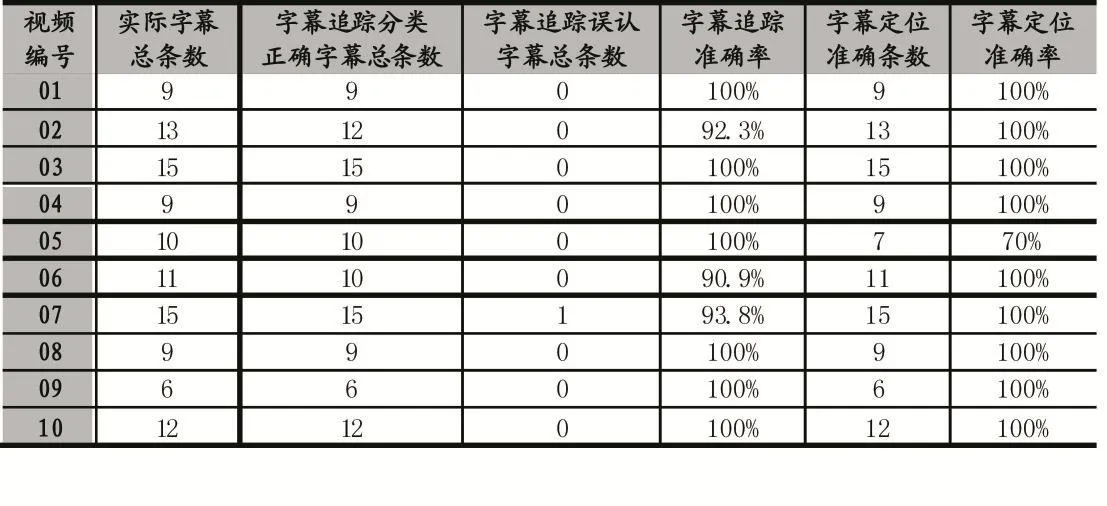
表1 实验数据

图3 误识为包含字幕的追踪结果
05号视频由于整段视频字幕左侧的边缘信息较少,导致一些最左侧的汉字没有被完全划分进来,出现了字幕定位不准的情况,如图4所示。

图4 不完整的字幕定位区域
3.2 结果分析
基于边缘特征的字幕定位,由于字幕是横向排列的原因,对于字幕上下边界的定位非常准确,相比之下对于左右边界的定位可能会稍微出现偏差。字幕追踪对视频中间出现的字幕基本可以做到精确分类,但是对最后一秒出现的新字幕的检测还有待完善。
