利用网络图像增强行为识别
2019-01-19闻号
闻 号
(安徽大学 电子信息工程学院,安徽 合肥 230601)
0 引 言
随着智能手机、动作相机、监控摄像机等的普及,网络上视频的数量已经超出了人们观看所有视频的能力。由于行为识别问题在视频监控、人机交互和视频内容分析等方面具有很大的潜力,视频中人体行为的识别受到了广泛关注。例如,Wang等[1]提出了一种改进的密集轨迹算法。文献[2]使用了在做小码书情况下的多时空特征。文献[3]使用多种特征来描述行为的整体分布和局部变化。文献[4]使用能量函数对运动区域进行高斯取样,使样本点分布于运动剧烈的区域。虽然这些方法已经在目标检测和跟踪方面取得了惊人的进展,但是从视频中检测出更多的抽象动作和事件仍然具有挑战性。
在训练人体行为模型时需要大量的训练数据来避免过度拟合,然而数据获取需要耗费大量人力物力。相比之下,从网络上收集和处理数据要便宜得多。而且观察到,通过动作名称查询的Web图像通常描述一个歧视性的动作场景,以此可以捕捉并突出显示视频中感兴趣的动作和事件。所以这是一个证明网络图像可以增强行为识别的有力证据。显然在视频中提供的时间信息和图像中描绘的歧视性场景间存在互补优势。
提出的方法与Web learning(网络学习)息息相关。典型的工作有文献[5-6],从这些研究内容可以看出,网络数据域与目标域之间的域差异是个热点问题。域差异问题是一个跨域学习问题,也是一个迁移学习问题。因此,试图通过跨域字典学习的方法,同时对网络图像域和目标域进行字典学习来解决这个问题。
1 方法实现
设计的人体行为识别算法流程如图1所示。
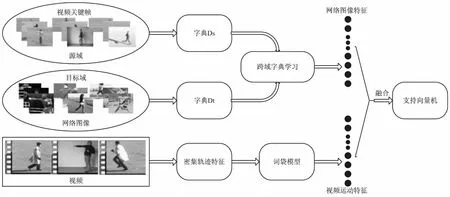
图1 算法流程
获取网络图像作为目标域,获取数据集中每个类视频的关键帧图像作为源域。使用SIFT算法提取的目标域和源域图像的底层特征描述子,分别作为跨域字典学习算法的输入,同时进行字典学习,进而获得网络图像的特征表示;使用文献[1]提出的密集轨迹算法提取数据集中视频的密集轨迹特征,再通过字典学习、词袋模型编码得到视频中人体行为的特征表示。将两组特征进行长拼接,把拼接后的特征向量放入支持向量机中进行训练分类。实验选择的数据集分别是KTH[7]和YouTube[8]。
1.1 获取训练集图像
本节列出了收集和组织网络图像的步骤。借助Google Image API,可以轻松地以几乎零成本获取所需的动作图像。使用每个类别名称作为关键字在Google图片搜索服务中下载检索到的图像。使用照片过滤器删除不太可能出现在视频中的人造图像。收集了大约15 000张网络图像(如图2所示)分别用在KTH数据库中的六种人体行为和YouTube数据库的十一种人体行为的识别实验中。

图2 网络图片(从左向右分别表示骑车、骑马、高尔夫、荡秋千、颠球)
1.2 跨域字典学习

(1)


根据Zhu Fan等[10]提出的方法,对式1转换:
〈Dt,Ds,Xt,A,W〉=
(2)

也可以把式2转换为最简单的形式,上式因子可简写为:
(3)
优化问题目标函数简化为:
(4)
从而优化问题即可使用K-SVD[11]算法通过迭代更新的方式求解。
1.3 词袋模型
根据文献[1]提出的密集轨迹算法获取行为视频的底层特征描述子。为了评估文中方法的性能,使用标准的词袋模型方法,为底层特征描述子构造了一个字典。根据经验将字典的可视化词语个数固定为4 000,使用k-means方法随机选择100 000训练特征进行聚类。初始化k-means 8次,以此提高精度,保证最低的误差结果。特征描述子会根据欧氏距离被分配到它们最接近的词汇,由此产生的视觉词汇直方图被用作视频中人体行为的特征表示。
2 实 验
2.1 数据集
KTH数据集包含六种人类运动行为:散步、慢走、跑、拳击、挥手和鼓掌(如图3所示)。每一种行为由25个人展示数次,分别拍摄在四个不同场景下。数据库总共有598个视频样本。根据文献[7]中的实验设置把样本中(2,3,5,6,7,8,9,10,22)9个人分为测试集,剩下的16人为训练集。
YouTube数据集包含11种人类行为:骑车、跳水、高尔夫、颠球、蹦床、骑马、投篮、排球、秋千、网球和遛狗(如图4所示)。
2.2 实验结果分析
表1和表2分别列出了在KTH数据集和YouTube数据集中的实验结果。可以看出,文中方法比密集轨迹算法表现得更出色,在KTH数据集中准确率提高了1%,在YouTube数据集中提高了2.2%。在具有背景复杂、拍摄时摄像机移动等复杂视频的YouTube数据集中,文中方法明显优于其他方法。实验结果表明,该方法可以有效地增强视频中的动作识别能力。

图3 KTH数据库视频实例

图4 YouTube数据库视频实例

方法准确率/%文献[7]91.8文献[12]93.3密集轨迹93.1文中方法93.9

表2 在YouTube数据集中的实验结果
在对网络图像进行跨域字典学习时引入了视频关键帧,所以不确定视频关键帧有没有对结果产生影响。对此进行了一组对比实验,如表3、表4所示。第一个是只使用视频作为输入;第二个是视频与视频关键帧作为输入;第三个是视频加上视频关键帧和网络图片作为输入。实验结果表明,文中方法有效增强了密集轨迹算法对人体行为的识别能力。

表3 使用不同的训练数据在KTH数据集中的实验结果

表4 使用不同的训练数据在YouTube数据集中的实验结果
3 结束语
通过对网络数据学习理论的研究,提出了一种利用大量的网络数据作为辅助数据来增强密集轨迹算法对人体行为的识别能力的方法。实验结果表明,该方法有效提高了密集轨迹算法对人体行为的识别能力。特别对含有质量低、场景较复杂等复杂视频的YouTube数据库,其表现更突出。下一步的工作是解决图片的收集问题,不再是通过人为筛选图片,而是通过训练的人体行为模型自动筛选图片,这样会大大提高图片获取的速度和数量。
