基于卷积神经网络的黑白人物图像多种合理着色的研究
2019-01-11陈国栋潘冠慈
田 影,陈国栋,潘冠慈
在计算机图形学中,存在两种广泛的图像着色方法:用户引导的编辑传播和数据驱动的自动着色.Hertzmann等人通过将其与数据库中的示例性彩色图像进行匹配,并从该照片中非参数地“窃取”颜色,或通过从大规模图像数据中学习从灰度到颜色的参数映射,但效果并不好.2006年,Larsson[2]和 Zhang[3]等人使用深度网络方法进行图像着色,并且实现全自动化.虽然这样做可以轻松获得彩色照片,但结果往往包含不正确的颜色且着色效果单一.2015年,Zezhou Cheng等人[4]利用全连接网络进行图像着色,但由于该网络是逐个像素进行着色,一张图片着色需要花费较长时间并且有些图像着色效果不理想.
考虑到人物照片衣服颜色以及背景颜色的多样性,为了能够高效快速地获得多种合理的着色效果,本文利用大规模的数据来学习自然人物色彩图像的特征,同时结合传统编辑传播框架的用户控制,通过训练一个卷积神经网络[5]直接将灰度图像与稀疏的添加点输入映射到输出着色.
1 颜色多样性着色算法
网络系统的输入灰度人物图像X∈RH×W×1,H是图像高度,W是图像宽度.输入用户张量U,灰度人物图像是L,或CIE Lab色彩空间通道中的亮度.系统输出为∈RH×W×2,即图像ab颜色通道的估计值.该映射是通过一个CNN的F函数来学习的,参数为θ.然后训练网络用来最小化方程(1)中的目标函数,D代表灰度图像的数据集,用户输入和所需的输出着色.损失函数L描述了网络输出照片颜色与地面真实的接近程度.
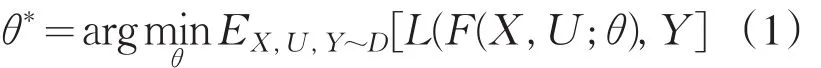
然后训练着色网络的两个变体,本地用户提示Ul和全球用户提示Ug.在训练期间,提示是通过分别使用函数φl和φg给网络“窥视”或投影地面真实颜色Y而产生的.

接下来在等式(3)中描述本地和全局提示网络的最小化问题.因为使用函数φl,φg以组合方式生成用户输入,所以数据集只需要包含灰度和彩色图像.卷积神经网络的训练图像使用的是LFW(Labeled Faces in the Wild)数据集[6]和ImageNet数据集[7].其中,正样本全部来自LFW中的人脸图片,而负样本是从ImageNet中选择的背景(例如树木,花朵,家具等图片).

损失函数是衡量网络性能和指导学习的重要参量,选择合适的损失函数十分重要.卷积神经网络的训练目标就是最小化网络的损失函数L.本文使用smooth-ℓ1(或Huber)损失.本地提示网络从输入角度出发,从保守的彩色化开始,允许注入着色所需的颜色,而不是从更有活力但容易出现伪影的设置开始,并且可以修复错误,只需要几次点击就可以快速解决问题的多模态含
1.1 着色网络的目标
糊性.如图1所示,在衣服的着色过程中,背景被错误着色出现伪影(中间图),但只需要添加一个点便可以很好的控制背影颜色(右图).

图1 人物图像着色的错误修复
此外使用等式(4)中描述的δ=1回归损失,能够在没有固定推理步骤的情况下执行端到端学习.
列宁明确指出,社会主义意识形态教育对象是“千百万劳动者”。这“千百万劳动者”不仅仅包括无产阶级,还包括半无产者、小农、小资产者等。列宁特别强调了教育农民的重要性。他认为,在俄国“无产阶级不但是少数,而且是极少数,占大多数的是农民”[5],列宁认为,要赶快用我们的一切宣传手段、一切国家力量、一切教育、一切党的手段和力量来说服非党农民[6]。

在每个像素处评估损失函数lδ,并将它们相加在一起以评估整个图像的损失L.

1.2 人物图像的界面功能
本地提示网络使用稀疏的添加点作为输入,用于描述输入,模拟添加点以及定义界面的功能.给定用于训练的彩色图像,将图像转换为灰度和CIE Lab色彩空间.模型的输入是灰度图像,而目标输出是CIE Lab颜色空间的a、b分量.
图像着色系统输入.灰度人物图像的添加点被参数化为 Xab∈RH×W×2,提供的添加点具有ab值的稀疏张量,并且 Bab∈BH×W×1是指示提供哪些添加点的二进制掩码.(a,b)=0时,掩码将未指定的点与指定的灰点区分开.张量一起形成输入张量Ul={Xab,Bab}∈RH×W×3.
模拟添加点交互.抽取小补丁并显示网络的平均补丁颜色,对于每个人物图像,点数是从几何分布 p=1/8绘制的.每个添加点位置都是采用取样.显示的补丁大小从1×1到9×9均匀绘制,补丁内的平均ab显示给网络.最后,为了正确地限制特性——由用户给出的所有点,网络应该简单地将输入中的颜色复制到输出.
如图2所示,(a)为输入灰度图像(.b)~(d)以单个居中添加点为着色输出彩色化(.e)用于(f)添加点的位置.(f)为给出不同添加点输入颜色的输出.通过本文的算法和颜色推荐系统的交互性,可以看出图像中所添加的点具有非常明确的限制特性.

图2 段内多个点的颜色交互
实时人物图像着色界面.如图3所示,黑白人物图像的着色界面包括颜色板,基于当前点的常规色域,为给定位置建议可能的颜色,以及显示覆盖在灰度输入图像上的添加点,实时更新着色结果的显示器.在给人物图像着色期间,可以随时添加、移动、删除或更改任何现有添加点的颜色.如图3所示,人物的着色只需要3个点即可实现,一个控制肤色,一个控制头发的颜色,另一个则可以控制背景.短短几秒就可以实现图3的效果.

图3 黑白人物图像着色界面
数据驱动的颜色板.选择合理的颜色是实现逼真着色的重要一步.对于每个像素,我们预测输出颜色概率分布为∈RH×W×Q,其中Q是量化色箱的数量.本文使用2016年Zhang等人[3]提出的CIE Lab色彩空间的参数,ab空间被分成10×10个分箱,并保留了色域中Q=313个分箱.从输入灰度图像和添加点到预测颜色分布的映射用网络Gl学习,由ψl参数化.地面真实分布Z也用来自Zhang等人[3]软编码方案的地面真彩色Y编码,真实的ab颜色值表示为其10个最近的箱中心的凸组合,用σ=5的高斯核函数进行加权.我们对每个像素使用交叉熵损失函数来测量预测人物图像和颜色地面真实分布之间的距离,并且对所有像素求和.

训练网络Gl以最小化训练集上的预期分类损失.

为了提供离散的颜色建议,通过软化查询像素处的softmax分布,使其不那么高峰,并执行加权k均值聚类(k=9)来查找分布模式.例如,系统通常会根据人物对象、衣服材质、场景类型推荐合理的颜色.对于具有不同颜色的对象,系统将提供广泛的建议范围.一旦选择了建议的颜色,系统将实时生成着色结果.随着人物图像中添加点位置的变动,颜色建议将不断更新.
1.3 融合全局信息
端到端学习框架的一个优点是它可以很容易地适应不同类型的用户输入,任何像素的人物图像都适用.用户提供全局统计量,由全局直方图 Xhist∈ΔQ和平均图像饱和度 Xsat∈[0,1]描述.是否提供输入分别由指标变量Bhist,Bsat∈B进行索引.系统的用户输入是Ug={Xhist,Bhist,Xsat,Bsat}∈ R1×1×(Q+3).通过使用双线性插值将颜色Y调整为四分之一分辨率来计算全局直方图,在量化的ab空间中对每个像素进行编码,并对空间进行平均.通过将地面真实图像转换为HSV色彩空间并在空间上平均S信道来计算饱和度.在训练过程中随机地向网络显示地面真实颜色分布,以及地面真实饱和度.
2 网络架构
黑白人物图像的着色网络架构如图4所示.黑色表示输入层,蓝色表示全局提示网络层,橙色表示主着色网络层,绿色表示本地提示网络层.本文研究了交互着色的两个变体,即全局提示网络和本地提示网络,两种变体都使用橙色层来预测输出着色.本地提示网络使用绿色层来添加用户点Ul和预测颜色分布.全球提示网路使用蓝色层,将全局输入Ug转换1×1个卷积层,并将结果添加到主着色网络.每一个框代表一个卷积层,垂直尺寸表示特征图空间分辨率,水平尺寸表示通道数.分辨率的变化通过二次采样和上采样操作实现.在主网络中,当分辨率降低时,特征通道数量增加一倍.将快捷连接添加到上采样卷积层.

图4 着色网络架构
2.1 主着色网
本文的着色网络F的主要分支使用2015年Ronneberger等人提出的U-Net架构[8],已被证明能够适用于各种有条件的生成任务(Isola等人)[9],设计原则参考(Simonyan和Zisserman 2014)[10]和(Yu和Koltun 2016)[11].该着色网络由10个卷积块构成,conv1~10.在conv1~4中,每个块的特征张量在空间上逐渐减半,而特征维数加倍,每个块包含2~3个conv-relu对.在下半部分conv7~10中,空间分辨率被恢复,而特征维数减半.在conv5~6中,不是将空间分辨率减半,而是使用具有因子2的扩张卷积.添加了对称快捷连接以帮助网络恢复空间信息.例如,conv2和conv3分别连接到conv8和conv9,这也可以方便地访问重要的底层信息.例如,亮度值将限制ab色域的范围.conv1~8没有快捷连接,是网络体系结构的一个子集,添加的conv9、conv10和快捷方式连接都是从头开始训练的.最后一个conv层,即1×1内核,映射在conv10和输出颜色之间.由于ab色域是有界的,在输出上添加最后一个tanh(双曲正切)层,例如生成图像时的常见做法(Goodfellow et al.2014;Zhu et al.2016)[12].
2.2 本地提示网络
本地提示网络特定的图层在图4中以绿色显示.稀疏用户点通过与输入灰度图像级联而被集成.作为一项辅助任务,还可以预测每个像素处的颜色分布(以灰度和用户点为条件)以推荐给用户.预测颜色分布的任务无疑与主要分支有关.通过连接主分支多个层次的特征,并在顶层学习一个双层分类器,使用了高列方法(Hariharan et al[13];Larsson et al[2]).网络 Gl由主分支组成,直到conv8,连同该分支.为了节省计算量,以四分之一分辨率预测分布,并应用双线性上采样以全分辨率预测.
2.3 全局提示网络
系统将信息整合到主色彩网络的中间,如图4的顶部蓝色分支所示,输入通过4个conv-relu层进行处理,每个层的内核大小为1×1和512个通道.该特征图在空间上重复,以匹配主分支中的conv4特征的大小,并且通过求和合并,与2016年Iizuka等人[14]使用的策略相似.
3 实验结果与分析
3.1 实验结果
如图5所示,在该方法中,建议颜色按照神经网络生成的可能性排序.通过对灰度图像合适位置添加点,实时生成多种合理的着色结果,大大提高了黑白人物照片的色彩效果.

图5 黑白人物图像多种着色结果
3.2 实验分析
PSNR是“Peak Signal to Noise Ratio”的缩写,即峰值信噪比,是一种评价图像的客观标准,通常在经过图像压缩之后,输出的图像都会在某种程度与原始影像不同.为了衡量经过处理后的图像质量,通常会参考PSNR值来衡量处理能否令人满意.表1为本文所用方法与其他着色方法之间的对比.
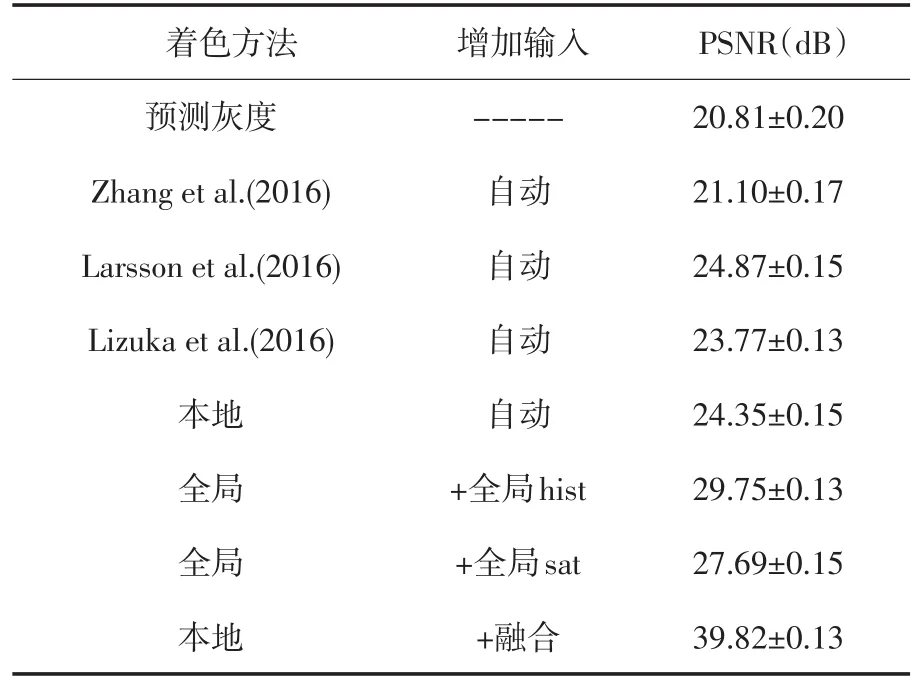
表1 多种着色方法的PSNR对比值
表1通过本文与多种着色方法的对比,全局+全局hist提供色域的全局色彩分布;全局+全局sat为系统提供全球饱和度.本文中所提出的全球提示网络学习融合全球统计数据以获得更准确的色彩.
4 结语
本文通过训练卷积神经网络对灰度人物图像实时着色,能快速获得多种颜色效果,而且可以进行人工修改错误,实现黑白人物图像快速多样化,以及高质量的着色结果.使得人物图像看起来更生动、真实,更能活灵活现地展示它拍摄的意义,给人更好的视觉效果.对于黑白人物图像的保存和珍藏具有重要意义.由于图像颜色只是在ab色域以及建议的色彩上选择,今后在着色的全面性上需要进一步研究.
