基于并行算法的数据挖掘平台研究
2019-01-10李文明
王 霞, 李文明
(福建船政交通职业学院 a.信息工程系; b.航海技术系,福州 350007)
近年来,随着IT信息技术和应用的蓬勃发展,数据挖掘平台的构建已经发展成为一个用户数量多、信息量巨大的数据信息库[1].随着网络普及,许多用户已经逐渐习惯网络上针对重大数据挖掘进行讨论,分享自己的观点[2-3].在互联网时代,对大数据信息进行并行化处理是挖掘数据的主要方法之一.此方法的实质是依次抽取大数据,通过对大数据的特征值进行分析,找到其随着时间变化而改变自身特性的现象,接着将具有一样特性的信息数据进行高效聚合,最后形成数据挖掘库[4].但是,目前学者的研究大多集中在数据批量处理方面,而如何对大数据进行并行运算处理研究的比较少[5].
针对上述问题,本文通过在数据挖掘平台的基础上进行数据并行化运算,此数据挖掘方法伴随着网络大数据的不断增加,用户开始使用网络进行信息共享与交流,所以可以通过分析网络数据库中数据态势变化趋向以完成挖掘数据价值信息的目的.最后通过实验结果验证,本文设计的算法可高效挖掘出数据的价值信息,具有一定的实用性和价值性.
1 数据挖掘平台的构建
1.1 数据挖掘的定义
定义1 大数据中的数据
定义2 序列
E=
其中,ei表示一类数据符号,包含一种或多种相似的符号,n为种类的个数.
定义3 并行数据挖掘向量
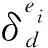
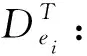
1.2 并行算法的实现
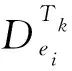
(1)
对于每个数据组特征项,运算其在并行处理时间T内的值来表示评价其重要程度,选用余弦相似度来分别验算大数据占据的空间及其相似度数值.数据组di和dj的相似度表达式如下:
S(i,j)i≠j=Sim(di,dj)=
β·SimNE(di,dj)+(1-β)·SimO(di,dj)
(2)
式中,β为平滑系数且β>0.5.
假如S(i≠j)的中值大小为η,第i个数据组d包含的待挖掘数据量为μ,数据组的平均可挖掘数据为ζ,使用Sigmoid函数对数据参考度进行设置:
(3)
2 实验结果及分析
2.1 实验结果
假设数据并行运算时间T的值设定为1 h,最短时间间隔t*的数值为1 min,来验证本文所提算法的实用性.设需要使用并行算法进行处理的待挖掘数据为maxits=1 000,在数据聚类中心之间反复出现的数据次数为convits=20,挖掘数据重合度θ1为0.6,采用的余弦相似度的数值θ2和θ3全部选定0.8,为了验证本文设计的算法的有效性,在大数据网络环境下,如果使用人工分析数据将会耗费大量时间,所以,使用从以下几个指标来评价本文算法.
(1)挖掘数据覆盖率
数据覆盖率是本文使用并行算法得到待挖掘数据占参考数据的比重,它主要能够反映出并行算法的数据运算能力.本文在参考各种数据处理算法的基础上,用此算法作为基础进行数据运算能力的判断.从并行算法实现的过程,可以得出该算法能够挖掘出数据的价值信息.所以,使用在实际数据处理中的挖掘数据很少会出现遗漏情况.
(2)挖掘数据准确率
准确率是对并行算法运算后得到待挖掘数据精准程度的描述.对于待挖掘数据集合,可以随机抽取数据库中的50个数据,经过并行运算后,对挖掘数据的准确率进行比较.各种算法对比结果如表1所示.
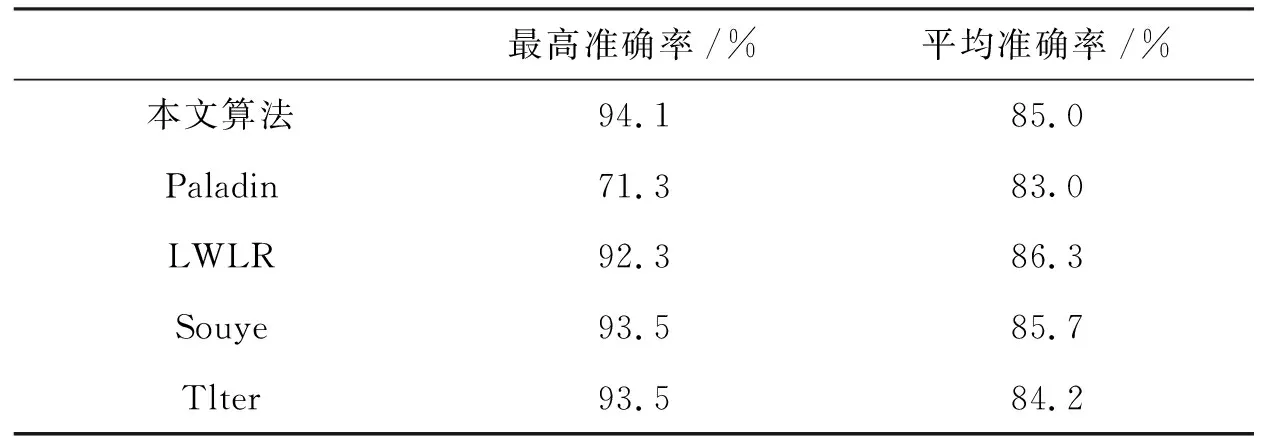
表1 算法准确率比较
从表1可以得出:本文所提的并行算法的准确率很高,平均准确率可达85%.而与其他四个数据处理算法相比,本文算法具有一定优势.
(3)挖掘数据运算时间
挖掘数据处理时间是指从计算机网络获得的大数据与挖掘数据价值信息后,将其价值信息进行反馈的时间段,它是对并行算法处理数据高效率的反映.并行处理挖掘数据越短,则表明算法可以迅速的挖掘出数据价值信息.
2.2 算法及结果分析
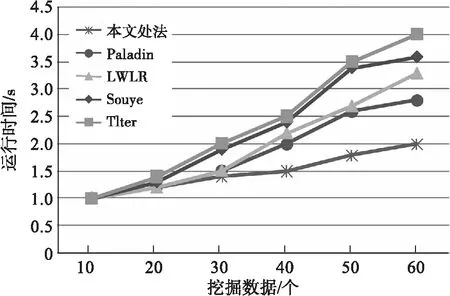
图1 各数据挖掘算法的效率对比
从图1的实验曲线图可以得出,本文设计的并行算法能够迅速的挖掘数据平台的价值信息.实际上,本算法满足网络上大数据实时在线的请求,在并行算法处理后的大数据库内进行挖掘数据的随机抽取,约60%的数据被归类到非挖掘数据,使得在线处理挖掘数据的时间极大地得到了减少.虽然挖掘数据平台一般含有2 000个待挖掘数据,首先通过主成分分析法对挖掘数据进行分析,此方法可以减少算法运行时间,进一步提高并行算法的数据处理时间和精确度.从图1中可以看出,对于相同的数据库,如果数据库相对较小,各算法在处理数据的运行时间上相差不是很大.但如果增加数据规模,算法的运行时间曲线的斜率都会变大,即算法运行所用时间减少的的速度将会变大.随着挖掘数据的变多,本文算法的运行时间趋于稳定,这是因为各数据间的通信随着挖掘数据的增加,计算过程中的额外开销也会总体较小,况且测试数据集本身并不发生改变,实验所搭建的集群也不改变,因此运行时间的差异逐渐减小.
3 结论
随着信息技术的不断创新,大数据已经呈现出爆炸式增长的趋势,大数据产业同时也经历着从IT到DT的巨大转变.如何提高挖掘大数据背后所隐藏的价值信息,成为现阶段许多国内外研究的一个难题.本文针对大数据背景下数据挖掘问题,提出了一种高效的数据挖掘方法,将并行算法应用到数据挖掘平台之中.实验证明,本文提出的方法具有较高的数据处理能力,能够对计算机网络中的大数据进行在线数据挖掘.
