基于SVM的学习兴趣度分析方法的研究
2019-01-09常佳薇
张 童,常佳薇
(北方工业大学 电子信息工程学院,北京 100144)
0 引言
在计算机视觉和机器学习领域中,自动识别人类自然交流时的表情已经是可以实现的一件事。在之前的许多探究性研究中都在试图去分类视频和图像中所谓的“基础表情”(anger, disgust, fear, happiness, sadness and surprise),因为基础情绪表情被认为是普遍表达的,它们的动态在日常生活中也是常见的,这就使得基础情绪成为开始训练表情识别系统的自然选择。
但是不同的诱发刺激源,人脸常能表现出相同或相似的表情。在现实世界里,人们交谈时观察到对方脸部的表情变化,或许可以理解这种表情变化意味着什么,但在利用机器领域工具去分辨这方面还面临着不少的挑战。
在课堂的老师与学生的互动中,可以观察到很多同学产生了微笑的表情,但是这个微笑表情是否与课堂内容相关,有时候老师用肉眼根据经验就可以直接判断。在本实验研究中,本课题希望建立一套实验,让机器也能更好地理解学生在上课过程中发出的微笑背后,到底是一个怎样的心理状态。
论文的剩余部分如下:第1部分描述了前人相关的工作;第2部分描述了所做的数据实验和实验对象介绍;第3节描述了数据的处理、特征的选取以及对性能分析进行了一般性的讨论,并对问题进行了更深入的分析。第4节、第5节研究了“认真学习的笑”和“不认真学习的笑”的特征向量,并提出了一种算法来区分。
1 相关研究
基础情绪的研究以及分类已经很成熟了,在研究基础情绪的过程中,也极大地促进了情绪识别分类等技术和工具的产生。这些用于将FACS与基础情绪关联的技术和工具可以与表演的数据或者其他有限制的数据有很好的效果。但是对于自然数据,这些技术可能无法产生令人满意的效果。在前期的数据采集上,可以采用基础情绪研究所衍生的技术工具。谷歌、百度、旷世face++、腾讯等知名的公司就已经有了开源的成熟的API可供调用,这对前期的数据采集提供了便利。

图1 现场课堂录制状态Fig.1 Classroom recording status
Mohammad(Ehsan)Hoque的研究在分类Frustrated和Delighted的笑容时,也是基于自然引发的实验数据进行的[1]。Mohammad和他的团队的工作是创造了两个实验情景引出两种情感状态,在区分这同一表情下的表现出的两种情感状态过程中,论文中提出的算法实现了总体准确率为92%,比人类略高。此研究方法给了人们很大的参考借鉴意义,但是对于Mohammad在处理笑容强度的维度上,该项目做出了改变,提出了自己的创新性方法。
2 实验
最主要的挑战之一就是数据集的收集,这也是本实验最耗时,最昂贵的部分。以往数据集的收集过程都是参与者表演、重现和互动的,只有很少的数据集是自发的,而且也没有一个数据集是专门针对上课场景的。
因为本研究是区分课堂上笑容表情的内在状态,所使用的数据集也必须是来自课堂教学环境下学生的人脸表情数据资料,所以实验的目的也就是要录取到学生上课和老师交流互动时的脸部表情变化。
在实验视频录制方面,该项目采用的是海康威视的DS-2CC597P超宽动态针孔摄像机,输出设置为1080p、28fps的实时图像。
共有20名小学生(3名女生和17名男生)参与了这项研究。他们都不了解研究的假设。这20名参与者都是横跨三年级到五年级的学生,年龄在9岁~13岁之间。在这20名参与者中,研究成员收集了71段“认真学习”时的笑容表情和“不认真学习”时的笑容表情(收集的每个参与者的片段数都是不固定的)。在数据集中,两种状态的笑容过程剪辑的平均时间长度略多于7s左右。
3 分析
在以上收集的这些数据中,面部表情是都存在的。下面是用于分类的面部特征的描述。
3.1 人脸识别数据的预处理
在收集到课题所需要的面部表情数据片段后,由于教室环境的复杂性,老师和同学的交流互动过程中都会造成一个单独摄像头的视频帧画面不止是一个人脸的情况出现,这就需要对视频帧图像进行预处理。

图2 学生课堂发生的一个微笑片段帧Fig.2 The frame of a smile clip in classroom
在人脸检测及提取技术上,本课题采用的是于仕琪老师的人脸识别技术;该API既可以检测人脸,也可以提取人脸的关键点坐标。
在收集到面部表情数据片段后,要将视频内容进行一次预处理。将微笑视频片段分帧并将图片像素归一化为400×400的规格。这里,每个视频片段的时间长短都是不一样的,这就造成了训练数据维度不一致的问题,这个问题在本文后面的章节回答。
3.2 人脸特征提取分析
本研究使用于仕琪团队的面部特征跟踪器来跟踪人脸部的68个特征点:20个点围绕在嘴部,12个点代表眼部(每个眼睛分布6个点,左右对称),10个点代表眉毛,9个点显示出鼻子的轮廓,17个点代表脸部轮廓。
本课题计算了原始距离(以像素为单位)、一些部位的角度值以及脸部某些部位的灰度值。这些特征点之间的距离等特征在每一帧中都得测量,当作每一帧微笑图片的备选特征,所有的特征都在每一帧被追踪。
3.3 数据集
实验一共有71个片段。对于每个片段,研究者提取了每一个片段每一帧的特征值,连接他们作为一个向量,这样每一帧特征值如下:
V={V1,V2,V3,V4.........VN},在这项研究中,由于微笑过程的随机性,所以每一个微笑片段的帧数是不确定值。
3.4 数据的矫正与优化
本研究在提取微笑视频片段时,发现很多微笑视频片段中,有学生微笑时头部摆动幅度太大,直接检测不到人脸表情的情形。当头部摆动幅度小时,在计算每一帧图片的微笑强度值的过程中,也发现误差过大的情况,本项目也不希望废弃这些偏转角度在一定范围内的微笑视频片段,毕竟这也是以后项目中要解决的实际问题。
图3 数据处理系统流程图Fig.3 Data processing system program flow chart
本实验中采用龚卫国的基于正弦变换的人脸状态矫正的方法,通过这种方法,使得侧面人脸姿态得到一定角度的姿态矫正,从而变换成接近正面人脸的数据[1]。矫正公式如下:
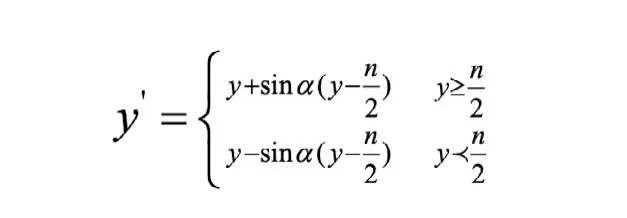
其中,ɑ是偏转角度,n是人脸图像的眉心点的坐标y值。
在观察两种微笑模式数据集的特征向量后,发现不管是“认真学习时的微笑”还是“不认真学习时的微笑”,特征向量的维度的量级上没有大的区别,都有不同长短维度的特征向量。
4 最终数据集
在本部分,依旧采用了分析部分中的微笑模式的数据集,开发一种利用时间模式将数据分类为适当类的算法。
该研究运用计算了每一帧微笑图片的笑容强度值,并作为该帧的特征值[2]。
由于微笑的时间过程的不可控性,所以每一个微笑片段的特征向量是不一样的。本研究并没有采用Mohammad(Ehsan)Hoque的微笑序列的维度长度不同的处理方式,即在特征向量后面添加零向量到相同的长度[3]。本项目研究方法是以统计了微笑强度的柱状图作为笑容片段的特征向量。将微笑强度值域划分成10个分值段,统计每一个分值段中的帧数占整个微笑片段帧数的百分比。这样做的好处一个是降低了数据的维度,另一个是保证了数据的维度的一致性,可用于训练。这样,每个微笑片段的特征数据就都变成了一个维度为10的特征向量。
5 分类
该研究方法使用特征向量和标签进行训练、验证和测试。Svm是使用的libSVM实现的[4],以7折交叉验证。
-s/svm类型选择为2;-t核函数类型为2,对应的是RBF核函数;-c/cost参数选择默认为1;-g/gamma参数设置为0.7。
在系统迭代560次后,准确达到81%,并且稳定不变了。
6 结果
这项实验的结果证明本文方法的工作是有效的。根据训练分类的结果,对分类成功的每一段微笑视频数据进行对比后发现,认真学习的笑容强度数值主要集中在0.6~0.85之间,且0.85以后几乎无分布;不认真学习时的微笑强度数值分布主要集中在0.75~1以上。
同时也比对了错误分类的数据,经过图片对比发现,引起错误分类的影响因素主要有两个原因:一个是有的微笑的过程中伴随着低头向下看的动作,该方向上的数据校正没有解决;另一个是微笑过程中学生的嘴部仍处于说话的状态。
