采用超售策略的在线订单配送时隙运能分配
2019-01-08刘鹏宇陈淮莉
刘鹏宇,陈淮莉
(上海海事大学物流科学与工程研究院,上海 201306)
0 引 言
随着互联网的高速发展,越来越多的零售商开通线上交易服务,然而在为销售商提供便利的同时,在线交易的激烈竞争也给订单配送提出了更多更高的要求。为尽可能地增加收益、降低成本,零售商不仅要把控好货物质量还要尽可能合理安排运能。时隙(time slot)在B2C模式中是互联网零售商在互联网平台上提供给客户选择的订单货物到达时间区间。[1-2]如菜鸟联盟、京东等,都是通过让消费者选择到货时隙安排运输,一方面有利于消费者根据自身情况接收货物,提高客户满意度,另一方面方便协调零售商与消费者、物流服务商的配送安排,合理规划运能、时间、人力等资源,提升整体竞争力。
在运能分配方面,母柏松等[3]针对铁路行包作业量小的车站容易产生的人力资源浪费问题,以作业量小的车站行包尽可能集中到发为优化目标,建立了行包运能分配的线性混合整数规划模型,降低了铁路行包运营管理成本。在电商领域,陈淮莉等[4]考虑价格和交付期对消费者选择行为的影响,建立了Logit模型,采用强化学习对到达的订单进行运能分配,解决了在线订单配送效率低、时隙运能分配不均衡等问题。
在时隙定价方面,陈淮莉等[5]为尽可能地利用时隙配送能力,通过动态调整价格来诱导消费者的选择行为,制定了合理的定价方法。DYE等[6]针对在参照效应背景下的时效产品动态定价和保鲜问题构建了连续参照函数,探讨了参照效应对产品动态定价的影响。NASIRY等[7]构建了离散模型进行求解,他认为消费者锚定的参考价格是历史上最低和最近的价格,偏好回避损失的消费者对损失比对参考价格更为敏感,他还指出相对应的动态定价问题有很多固定价格是最优的,如果更多的消费者将价格锚定在最低价格上,那么相对应的价格区间也就越宽。徐朗等[8]研究了在B2C背景下,在配送时隙均可用和某一时隙不可用两种情况下的客户替代时隙选择问题。陈淮莉等[9]同时考虑区域和时隙宽度的影响,并动态估计订单的交付成本,最终得到了在不同时隙宽度和效用下的激励定价方案。
在实际问题中常用动态规划方法处理动态订单接受问题,但由于不确定因素很多,当问题规模变大时,采用动态规划方法求解困难,容易面临维数灾难。强化学习算法是一种较好的求解方法。在强化学习的研究中,一般都是假设研究对象满足马尔科夫性质,随后将其形式化为马尔科夫决策过程[10]。王薇等[11]把可变限速过程通过控制定义为马尔科夫决策过程,利用强化学习无模型的特点对高速公路主线流通进行了主动控制。对于强化学习在不确定环境下订单处理中的应用,郝娟等[12]基于收益管理思想,采用平均强化学习算法研究了不确定环境下订单生产方式企业的订单接受策略,证明了用强化学习算法解决订单接受问题的可行性。
超售在收入管理研究中有很长的历史,它最早用在民航客运业,指售出的机票多于飞机的最大允许座位数,主要是为了减少退票和误机带来的座位浪费。陈敬光[13]分析了决策者的风险偏好因素,利用CVaR (conditional value-at-risk)风险度量法研究了在不同风险容忍水平下的超售策略。GE等[14]在超售模型中额外考虑了旅客换乘(即无法按时登机的旅客可以选乘下一航班)的影响。周蔷等[15]将预售期内的旅客订票过程看作泊松过程,并以此建立了超售模型,并结合枚举法求解。SIERAG等[16]的研究表明不考虑客户取消订单的销售策略可能导致20%的巨额收入损失,其模型特殊之处在于同时考虑了客户选择、取消订单行为和企业超售策略。
目前在线订单的研究焦点一直是时隙定价问题,少有文献把车辆运输能力和超售策略考虑进去。因此,在研究如何合理分配运能的同时,借鉴航空业的收益管理经验,结合电商订单时隙配送的特点,研究消费者选择时隙的概率和时隙运能限制,充分考虑消费者的取消订单行为,采用超售策略对时隙运能进行超售,提出通过强化学习有效解决考虑取消订单行为的时隙运能分配问题。
1 基于强化学习的订单处理过程
从强化学习的角度看,在订单处理策略中,每个随泊松分布概率λ到达的订单都会使系统(把系统当作强化学习中agent)进入一个新的状态。在每个状态下,设定系统只会做出一种动作,即接受、取消或放弃。取消表示取消的是当前订单之前客户下达的订单。系统在采取动作后分配订单配送时隙和配送车辆,然后进入下一个状态,对下一个订单再选择动作。可以看出在线订单运能分配符合马尔科夫决策过程,即一旦当前订单运能确定,当前订单运能分配结果就会直接影响下一订单的运能分配。由于马尔科夫决策过程是强化学习的理论基础,故本文选择强化学习中的Q学习算法来解决在线订单运能分配问题。
1.1 参数定义
T为时隙集合,T={1,2,…,t0}。M为车辆集合,M={1,2,…,m0},m∈M。N为订单集合,N={1,2,…,q0},q∈N。S为强化学习的状态集合,S={sq},q∈N。A为强化学习的动作集合,A={a00}∪{a0m}∪{atm},t∈T,m∈M,其中:a00表示放弃订单;a0m表示系统接受的订单由车辆m在0时隙配送,即在客户取消订单后系统做出取消动作,此时运能分配出去但不安排配送时隙;atm表示接受的订单由车辆m在时隙t配送。D为超售点过大时产生的惩罚成本。W为超售点过小时产生的失销成本。Cmax为每辆车的最大运能;θq为系统为当前订单q选择的动作对应的订单配送计划表的实际运能。lq为订单q的商品价格。εt(t∈T)为效用函数的随机变量,服从Gumbel分布。β为消费者对价格的偏好系数,0<β<1。U0为订单q初始最大效用。α和γ分别为状态函数更新迭代的学习速率和折扣因子。hqt(t∈T)为订单q的配送时隙t的时隙价格。λ为订单到达率,服从泊松分布。k为取消订单行为发生时收取消费者费用的比例,这里默认为与取消率相同。Uqt(t∈T)为订单q选择时隙t的效用,t=0时表示放弃订单。Pqt(t∈T)为订单q选择时隙t的概率,Pq0为放弃订单q的概率。Rqt(t∈T)为订单q选择时隙t的即时收益。Q(sq,atm)为强化学习中的Q函数,具体为当前订单q选择动作atm所获得的累计收益,t∈T。Q(sq+1,atm)为当前订单q选择动作atm时,下一订单q+1能够获得的累计收益,t∈T。
1.2 消费者时隙选择
在电商领域,考虑客户在线选择的随机性和客户取消和放弃订单的行为,选择Logit模型对Q学习法中当前状态下的动作进行选择。
在经济学中常用效用度量消费者通过消费行为使自己需求得到的满足。[17]受时隙效用(受欢迎度)的影响,客户在线选择行为具有随机性的特点,网络零售商无法准确预知每个时隙选项的实际效用。因此,假设只考虑价格对消费者选择行为的影响,则效用函数为
Uqt=U0-βhqt+εt,t∈T,q∈N
即当时隙价格增长时,其实际效用会有所减少。
综上,基于Logit模型的选择概率公式[18]为
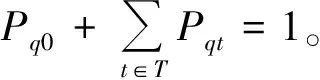
这里假设接受、取消、放弃订单这三个动作相互独立,且仅与当前客户有关。时隙选择概率是通过零售商根据消费者对时隙价格的偏好建立的Logit模型,预测消费者选择特定时隙的概率,通过该概率选择相应动作,得到即时收益。这里默认消费者选择概率为系统预测的消费者选择概率。
1.3 基于超售策略的时隙运能分配模型
(1)状态空间。根据系统对当前订单采取的动作计算Q(sq,atm)后,再次更新订单配送计划表和已经获得的收益。
(2)超售点的确定。一般,与取消的订单相对应的运能是无法或很难“收回”的,故采用运能超售策略,即承诺出更多的运能来平衡由于订单取消而闲置的运能。利用由订单取消行为导致配送资源浪费而产生的机会成本建立时隙运能超售点,研究取消订单行为下的时隙运能超售策略。如何确定一个合适的超售范围是一个重要问题。如果超售范围过大,虽然能在第一时间满足客户,但是没有足够的运能或者存货提供给消费者,则产生商家口碑下降、赔偿等一系列问题,从而产生惩罚成本D;如果超售范围过小,则没有了采取超售策略带来的电商利润的提高。同时,超售范围过小将会导致订单量与库存量的不平衡,从而产生失销成本W。因此,当前订单采取超售策略产生的总成本表达式为
minf(b)=Dmax{b+Cmax-θq,0}+
Wmax{θq-b-Cmax,0}
式中,b为超售点,即b为比车辆最大运能多承诺出的运能。通过软件模拟找出即时收益Rqt中涉及的最优超售点b*。这里默认每辆车的最佳超售点相同。
(3)即时收益的建立。强化学习的目标是经过若干次迭代后获得最大值,因此系统在处理每个订单时都会产生一个即时收益Rqt:
其中:式(1)为系统接受并完成订单的即时收益,其中f(b*)为最优超售点下的惩罚成本;式(2)表示系统取消订单,但由于促销期间的特价商品数量有限,取消订单时将收取部分费用,k∈[0,1);式(3)表示系统放弃订单。
1.4 Q学习算法求解
采用Q学习算法来进行订单决策,其基本更新规则如下:
Q(sq,atm)←(1-α)Q(sq,atm)+
α(Rqt+γmaxQ(sq+1,atm))
(4)
从式(4)可以看出,学习速率α越大,新的Q值保留上一个Q值越少,即Q值变化越快,α∈[0,1]。如果α→0,那么Q(sq,atm)的估计值将以概率1收敛到最优值。
式(4)中γ为折扣因子,反映未来收益对当前收益的影响程度,故Rqt+γmaxQ(sq+1,atm)为订单q在当前状态sq下选择动作atm的即时收益与订单q在下一个状态sq+1选择动作atm后获得的最大累计收益之和。
综上,基于Q学习算法、考虑取消行为的在线订单运能分配问题算法如下:初始化Q函数和配送计划表;输入每辆车的运能限制Cmax和即时收益矩阵;设定强化学习迭代次数,开始处理订单。订单处理过程:第1步,根据订单价格,基于利用Logit模型得到的接受、取消、放弃概率来选择动作,得到即时收益Rqt。如果订单配置的时隙t和车辆m未超过最大运能Cmax则选择动作atm(t∈{0}∪T,m∈M),否则系统自动选择同时隙其他车辆。a0m为客户取消订单,此时收益只有klq。如果所有时隙和所有车辆都超过了最大运能则选择动作a00,即放弃订单。第2步,根据式(4)更新Q(sq,atm)。第3步,完成当前订单,状态初始化为sq+1→sq。最后,计算下一个订单直至结束。
2 算例分析
为分析超售策略在在线订单时隙运能分配问题上的有效性,利用MATLAB 2014a进行算例模拟,模拟中的假设条件均从实际出发。
假设促销期间的配送时间区间为6:00—21:00,时隙长度为3 h,时隙1~5对应的时间区间分别为6:00—9:00、9:00—12:00、12:00—15:00、15:00—18:00、18:00—21:00。共有4辆车配送。订单初始配送计划(也称车辆与时隙的初始运能分配)见表1,定义了每辆车在对应时隙下需要完成的初始订单任务数。假设每辆车在每个时隙的初始运能限制为50 unit,为每个订单随机分配的运能为1、2、3 unit,随机产生的商品收益为100~400元/unit,时隙价格依次为25、20、15、10、5元。假设在促销期间0:00—6:00内按照泊松分布到达300个订单,参数λ=3。对这部分订单进行运能配置。设置强化学习次数为500,α=0.98,γ=0.99,U0=20,β=0.1。运能超售点b=2 unit,失销成本W=4元,惩罚成本D=2元,取消率k=1/10。
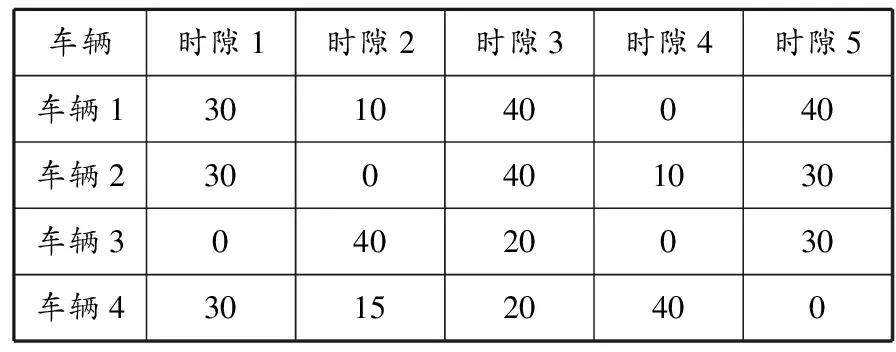
表1 订单初始配送计划 unit
2.1 运能分配
当今促销活动,如双十一、双十二等,都是在0点开启的,在6点开始配送时已有大量订单等待配送,这说明假设符合实际情况。同时,电商权衡收支时会尽可能降低成本,充分利用配送能力,在已有的配送任务基础上,加入新订单,既节省成本,也均匀分配每辆车在每个时隙的配送任务。虽然订单的到达、价格是随机的,但是经过多次运算,在指定超售点和取消率的情况下,得到的平均收益与运能分配状况匹配,说明模型结果具有普遍性,符合实际。分配结果见表2。300个订单中有32个订单放弃,有25个订单取消。结果也证明Q学习算法适用于在线订单运能分配问题。
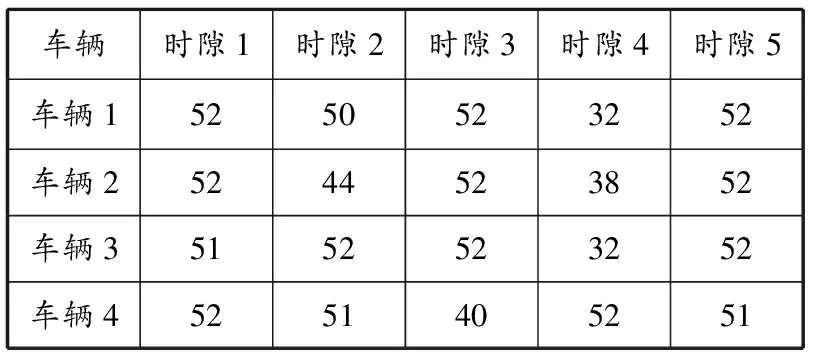
表2 订单最终配送计划 unit
分析表1和2可以发现,初始配送计划中有车辆在某些时隙没有配送任务,如车辆3在时隙1(6:00—9:00)的被安排的运能为0,这无疑是一种运能浪费。通过Q学习算法对到达的订单分配后,车辆在不同时隙上的运能得到均衡分配。从结果看,顾客从0点开始下单,订单从6点开始配送,在中午12点之前和晚上18点之后(对应时隙1、2和5)配送车辆几乎全部到达其运能限制,而时隙3(12:00—15:00) 次之,这符合顾客需求的实际情况。
2.2 最优超售点的确认
为确定最优超售点,根据以上参数设定运行软件,得到在运用强化学习进行运能分配时不同超售点对总收益的影响,见图1。从图1可以明显看出,在取消率为1/10,b为9 unit时总收益最大。b为0(即不采用超售策略)对应的是陈淮莉等[5]提出的基本订单系统模型,在这个模型中零售商的总收益明显低于采用超售策略的总收益,没有到达最优值。
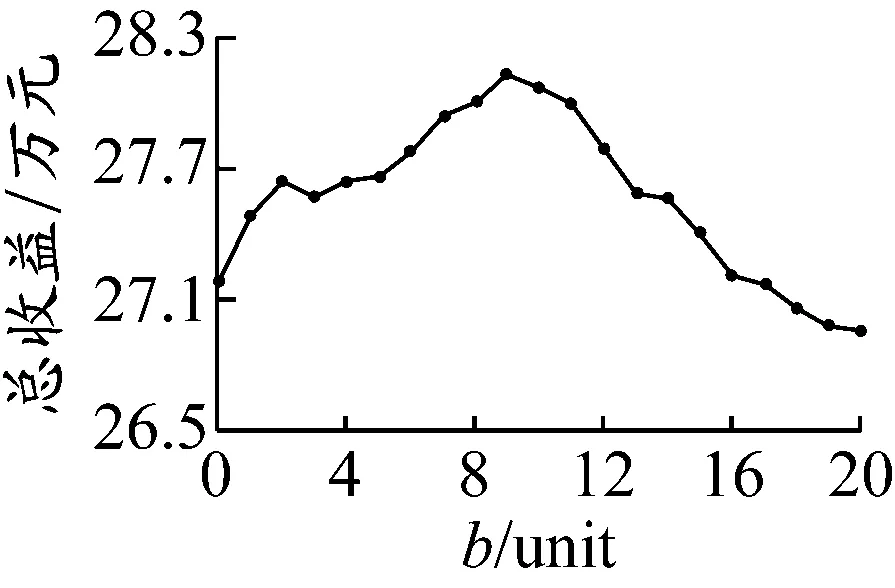
图1 不同超售点对总收益的影响
然而,当b超过9 unit时总收益开始减少,当b超过16 unit时总收益会小于未采用超售策略时的总收益,此时b再增加已没有意义。因此,在当前设定的条件下9 unit为最优超售点。
2.3 取消率对超售点的影响
在取消率为1/10时,最优超售点为9 unit。为进一步探索影响总收益的因素,分析采用不同取消率时零售商的总收益和最优超售点的变化,结果见表3。
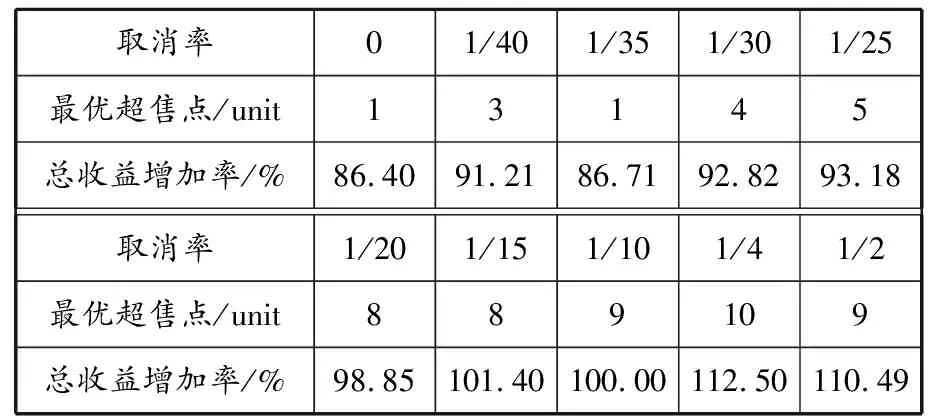
表3 采用不同取消率时总收益增加率和最优超售点的变化
由表3可见,取消率从0开始增加时,总收益和最优超售点大体趋势是增长的。在取消率为0时,最优超售点为1 unit,此时总收益最低;随后总收益和最优超售点持续增长,在取消率为1/4时总收益最大,此时最优超售点为10 unit;当取消率增加到1/2时,总收益和最优超售点出现下降趋势。表3表明,不同取消率对应的最优超售点是不同的,在消费者选择不确定的情况下,互联网零售商采用超售策略提高利润是可行的,并且消费者选择不确定性越大越有益。同时,随着取消率的增加,最大超售点也增加,但存在很大风险,互联网零售商应该慎重考虑。
2.4 惩罚成本对超售点的影响
当惩罚成本D=2,10,20,40,60,80元时,最优超售点为9 unit;当惩罚成本D=100,120,140,160,180,200元时,最优超售点为8 unit。由此可见:惩罚成本D的改变不会对最优超售点产生太大的影响;即使惩罚成本增加了100倍,最优超售点也只降低了1 unit。
3 结束语
在电商领域,对电商商家来说,消费者的需求波动比较大,在线订单取消行为比较常见,采用传统订单处理方式很难在激烈的同行竞争中取得优势。采用超售策略应对在线订单取消行为,“回收”由取消行为产生的空闲配送能力以达到提高收益的目的。
根据消费者对时隙价格的偏好,建立考虑取消率的Logit模型,得出强化学习中的动作选择概率,并设置时隙运能超售点等分配规则。模型结果显示:强化学习能使订单运能均匀分配,有效解决资源浪费问题,降低成本;根据由客户订单取消行为导致配送资源浪费而产生的机会成本建立时隙运能超售策略,相比传统方式,采用超售策略能够提高总收益,且在最优超售点时总收益最大;得出不同取消率对应的最优超售点和收益增加率,为商家制定相关销售运输策略提供参考。今后的研究将考虑在不放弃订单的情况下,通过延迟配送或者提前预定来预分配运能的方式缓解促销期间的配送压力。
