基于双重二元粒子群优化的高效用项集挖掘算法
2019-01-02靳晓乐刘峡壁
靳晓乐,刘峡壁,马 骁
(北京理工大学 智能信息技术北京市重点实验室,北京 100081)
0 概述
关联分析用于寻找隐藏在大型数据集中有意义的关联关系,是数据挖掘的一项重要技术[1-2]。传统的关联分析主要包括频繁项集挖掘和关联规则挖掘,其中,关联规则挖掘是基于频繁项集挖掘的结果,而频繁项集挖掘较为耗时。因此,频繁项集挖掘算法受到广泛关注[3-5]。然而,这类算法的计算目标是找出共现概率高于用户定义的最小支持度的项集,从而只关注项在事务中的有无和事务的频次,并没有考虑到项在事务中出现的次数和项自身的价值,即没有考虑到项之间的区别,而用户不仅仅对数据中的高频次项集感兴趣,更关心的是具有高价值的项集。高效用项集挖掘思想[6]旨在发现效用价值高的项集,项本身的价值和项在每一条事务中出现的次数能够反映项集的效用。
目前,高效用项集挖掘算法[7]存在以下问题:
1)最小效用阈值是人为设定,在对数据集没有一定了解的情况下,很难确定最小效用阈值,若最小效用阈值设置过高,则可能导致没有高效用项集产生。
2)传统高效用项集挖掘算法是在全部搜索空间中通过剪枝来减小搜索空间,搜索空间较大。
针对上述问题,本文提出一种基于双重二元粒子群优化(Double Binary Particle Swarm Optimization,DBPSO)的高效用项集挖掘算法。该算法利用最小相对效用阈值与效用上界乘积得到最小效用阈值。通过挖掘候选子空间内的高效用项集代替全部搜索空间,并给出分散子空间方法作为候选子空间的确定方式。
1 相关工作
高效用项集挖掘是关联分析的关键问题之一,由于是指数级搜索空间,挖掘效率一直不高。目前高效用项集挖掘算法主要包括3种:两阶段算法,一阶段算法和基于智能优化的算法。
两阶段算法是通过产生-测试2个过程来挖掘高效用项集:通过一定的策略产生候选集、计算每个候选集的真实效用得到最终的高效用集。文献[8]提出用于剪枝的TWU(Traction Weighted Utilization)模型和Two-Phase算法,该算法以Apriori算法和TWU模型产生候选集,通过扫描数据库计算候选集的真实效用值。由于Apriori多次扫描数据库的问题,文献[9]提出基于模式增长方式的挖掘算法(Incremental High Utility Pattern,IHUP),需要两次扫描数据库,即可产生候选集。文献[10]提出IHUP的改进算法UP-Growth,减少候选项集的个数。文献[11]为减少基于树结构建树产生的耗时,将项集信息存储在数组中,提出基于投影的高效用模式挖掘算法(High Utility Pattern Mining on Projection,HUPMP)。从本质上看,上述算法均是产生-测试的两阶段算法框架,无论采用Apriori类方法还是FP-growth类方法,虽然在一定程度上进行剪枝,但仍然会产生大量候选项集,具有较大的内存需求且生成候选项集的过程相当耗时,降低挖掘高效用项集的性能。因此,研究人员提出一阶段算法,即直接产生挖掘高效用项集而非候选项集。文献[12]提出HUI-Miner属于一阶段算法,该算法通过使用高效用列表的数据结构避免产生候选集,效用列表存储项集的效用信息和剪枝的必要信息。文献[13]在HUI-Miner基础上进行优化,有效降低了挖掘过程中产生的项集个数。文献[14]继续在模式增长方式基础上进行研究,提出HUPM-FP算法,与IHUP和UP-growth不同,该算法采用模式增长直接挖掘高效用模式,而不是候选项集,属于一阶段算法。
除了上述利用各种数据结构和剪枝策略挖掘[15]全部的高效用项集外,同样可以将智能计算的优化算法应用到高效用项集挖掘问题中,该算法虽然不能保证得到全部的高效用项集,但可以通过探索较小的子空间来得到尽可能多的高效用项集,如使用遗传算法的HUIM-GA[16]、使用基本粒子群优化算法的HUIM-BPSO[17-18]。其中,HUIM-GA是首次引进进化算法到高效用项集挖掘问题,该算法允许负效用的存在。但由于遗传算法参数较多,文献[17]提出使用基本粒子群算法解决高效用项集挖掘算法。基于上述研究,本文使用二元粒子群优化算法。
2 本文方法
在高效用项集挖掘中,最小效用阈值的确定直接关系到高效用项集的个数及算法的运行时间。目前最小效用阈值的确定是通过总效用的比例设置,然而对效用数据库来说,总效用和项集效用差别很大,在某一个数据集上合理的比例在其他数据集上可能就变得过高,导致过多耗时却没有高效用项集产生。
挖掘高效用项集是在项集中搜索出效用高于最小效用阈值的项集,其本质是一个搜索过程,通过搜索子空间代替全部搜索空间可以提高搜索效率。由于粒子群算法实现简单,性能良好,可以通过离散粒子群算法来确定候选子空间,相当于在指数搜索空间中建立大小为O(kn)的子空间。其中,k为最大迭代次数,n为粒子数。传统离散粒子群算法的子空间是在效用最大的项集周围,导致挖掘的高效用项集个数较少。如何在不增大候选子空间的情况下使O(kn)的子空间覆盖更多的高效用项集是本文的研究目标。
本文算法通过改进最小效用阈值的确定方式,避免了不会产生高效用项集的情况,利用改进子空间确定方式,可以实现在和传统离散粒子群算法相等子空间大小情况下挖掘到更多的高效用项集。DBPSO算法框架如图1所示。
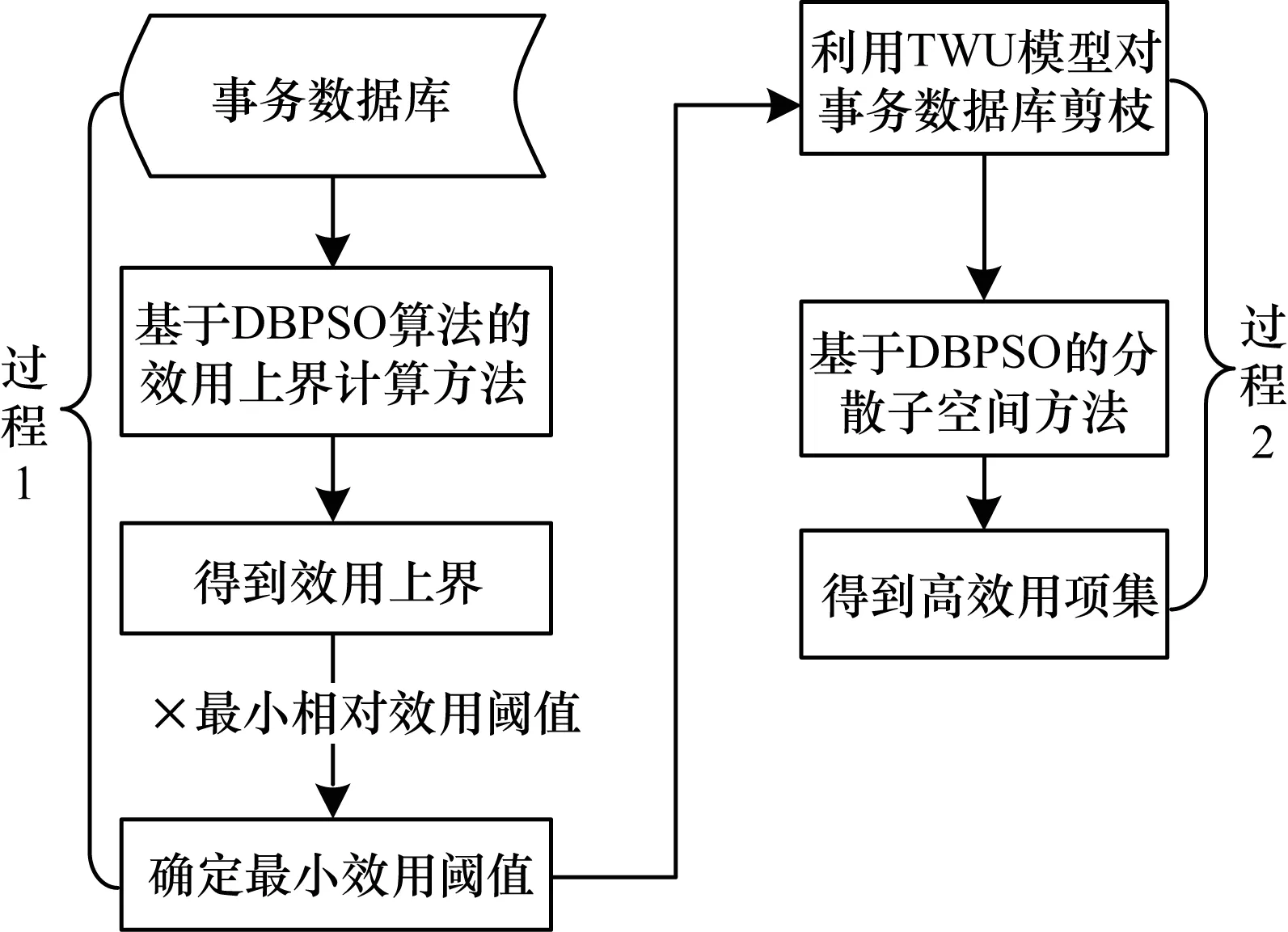
图1 DBPSO算法框图
高效用项集挖掘包含2个过程:一是计算效用上界,和最小相对效用阈值相乘确定最小效用阈值;二是根据最小效用阈值,使用分散子空间方法对数据库进行挖掘,得到高效用项集。由于计算效用上界和分散子空间挖掘高效用项集都是搜索问题,为了提高计算效率,本文对基本离散粒子群算法进行改进,提出双重二元粒子群优化算法。
2.1 DBPSO算法
DBPSO作为智能优化算法,应用于计算最大效用和挖掘高效用项集,包括粒子编码、初始种群生成、更新规则和适应度函数等部分。
粒子初始化是随机产生方式,在0到n之间随机产生数k,用来表示粒子中1的个数,再通过适应度比例选择法即轮盘赌方法产生1的位置,其中每个位置的适应度采用每一项事务加权效用值进行度量。更新规则如下:

gbestk)
(1)
其中,F1为基本离散粒子群更新规则[19],即对速度通过Sigmoid函数处理之后转化为位置取1的概率,具体如下:
(2)
(3)
(4)
由于该方法未考虑到位置之间的关系,F1本质为变异操作,因此引入交叉操作F2和F3,其中,F2表示概率为c1的交叉操作,交叉对象为当前解与局部最优解,F3表示概率为c2的交叉操作,交叉对象为当前解与全局最优解,由于本文方法包含2个粒子群,因此称为双重二元粒子群算法。
迭代前期,粒子的自我认知较社会认知更重要,迭代后期,正好相反,故可以在迭代过程中,通过调整c1和c2控制粒子自我认知和社会认知的比重。随着迭代次数的增加,自我认知比重由高到低,社会认知比重由低到高。即c1和c2采用异步时变方法,定义如下:
(5)
(6)
其中,p0为最小交叉概率,p1为最大交叉概率,curIter为当前迭代次数,maxIter为最大迭代次数。适应度函数对计算最大效用和挖掘高效用项集有不同的表达形式。
2.2 最小效用阈值确定方法
本文提出利用最小相对效用阈值和效用上界乘积作为最小效用阈值的确定方法,保证最小效用阈值不会大于效用上界,必然存在高效用项集,避免项集总效用比例设定方式造成没有高效用项集产生的情况。
以数据集ChessHUI[20]为例,说明本文的最小效用阈值确定方法。该数据集是由真实数据集chess增加人工效用信息而来,其中chess数据集是从UCI数据集中提取用来验证频繁项集挖掘算法的效率和效果,而效用信息分为内部效用和外部效用,内部效用通过[1,10]均匀分布产生,外部效用服从高斯分布。数据集基本参数如表1所示。

表1 数据集参数
先验知识和项集效用上界未知,设定最小效用阈值只能通过总效用的百分比确定,由表1中项集效用上界与数据集总效用的比值可以看出,若把比例设置高于0.32,则最小效用阈值将高于690 130,项集效用上界为685 719,因此,不会有高效用项集产生。为了得到相对合理的最小效用阈值,需要不断调整比例,耗时且盲目。
多次调整总效用比例的原因在于不合理的总效用比例会导致最小效用阈值高于效用上界。若项集效用上界已知,可以通过项集效用上界的比例即相对效用来设定最小效用阈值,得到的最小效用阈值必小于效用上界,避免没有高效用项集产生。
效用上界通过DBPSO算法快速计算得到,粒子X的适应度值fitness(X)=utility(X),具体算法如下:
算法1DBPSO计算效用上界算法
初始化粒子群;
Do
引理 1 对于样本模型Yi=m(Xi)+εi,i=1,2,···,n.^mH(x)为m(x)具有带宽矩阵H的局部线性估计,并满足文献[13]中的正则条件.设x为一个非边界点,则在给定X1,X2,···,Xn 下^mH 的偏倚为
For 每个粒子Xi
计算其适应度f(Xi)
If (适应度优于粒子Xi的历史最优值)
用Xi更新历史最优个体pbest
End
选取当前粒子群中最佳粒子作为gbest
For 每个粒子
按式(2)更新粒子速度
按式(3)、式(4)更新粒子位置
End
While(最大迭代数未达到)
得到gbest和f(gbest)
2.3 分散子空间方法
传统进化算法和群智能算法的高效用项集挖掘是将项集的效用作为适应度值,导致搜索空间集中在最高效用附近,增大迭代次数,只能得到较少的高效用项集。本文提出分散子空间方法,在不增大搜索子空间大小情况下,使子空间更加分散,挖掘到更多的高效用项集,如图2所示。

图2 子空间分散的挖掘高效用项集示意图
算法搜索n个子空间,将n个子空间挖掘到的高效用项集合并作为高效用项集。n个子空间由适应度函数决定,当算法搜索第k个子空间时,其项集X(k)的适应度函数f(X(k))为:
(7)
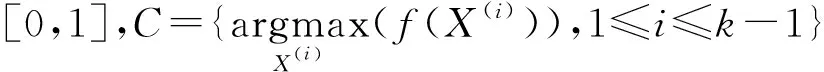
适应度函数确定以后,通过DBPSO算法挖掘高效用项集,具体算法描述如下:
算法2基于DBPSO的分散子空间挖掘
初始化子空间K=1
Do
Do
初始化粒子群
For 每个粒子Xi
计算其适应度f(Xi)和效用值u(Xi)
If (效用值大于最小效用阈值)
将Xi加入高效用项集HUI中
If (适应度优于Xi的历史最优值)
用Xi更新历史最优个体pbest
End
选取当前粒子群中最佳粒子作为gbest
For 每个粒子
按式(2)更新粒子速度;
按式(3)、式(4)更新粒子位置;
按式(1)更新粒子位置
End
While(HUI个数连续40次增加)
K=K+1
While(最大迭代数未达到)
得到高效用项集HUI
3 实验结果与分析
3.1 实验设置
3.1.1 实验环境与实验数据
实验环境如下:Intel Core i7-2600 CPU,10 GB内存计算机,操作系统为64位Windows,IDE为IDEA,编程语言为java。实验数据使用ChessHUI[20]。
3.1.2 参数设置
在本次实验中,粒子群大小设置为30,最大迭代次数为1 000,即搜索子空间为O(30×1 000)。
HUIM-DBPSO算法参数确定,包括w、c1、c2、d1、d2和Vmax。
从数学上分析惯性因子w和学习因子c1(d1)和c2(d2)是等价的[21],故在实验过程中选择w的值为1,通过更改c1(d1)和c2(d2)调整参数。收敛情况与c1和c2的关系如图3所示。

图3 最大效用与c1和c2关系变化曲线
从图3可以看出,当c1和c2呈负相关时,随着迭代次数的增加,c1减小,c2增加时,收敛最快,证明算法采用异步时变的正确性。
算法收敛情况与d1和d2关系如图4所示。由图4(a)可以看出,不同的d2值对算法收敛性有一定影响,较大的d2值收敛较快,但当d2大于6之后,收敛性基本不变。由图4(b)可以看出,不同的d1值对算法收敛性没有明显影响。同时由图4(a)看出,采用从2到10均匀变化的d2值并不会提高收敛速度,故在本文实验中,设置d1=0,d2=6。

图4 最大效用与d1和d2关系变化曲线
算法收敛与Vmax的关系如图5所示。由图5可以看出,当Vmax>4时,收敛速度小于Vmax=4;当Vmax<4时,不仅收敛速度慢,同时收敛值也不是最优,即陷入局部最优,故实验设置Vmax=4。

图5 最大效用与Vmax变化曲线
3.2 实验结果
下文从收敛速度、高效用项集数量和执行时间证明方法的正确性和有效性。
3.2.1 收敛速度
计算效用上界和挖掘高效用项集过程使用对基本二元粒子群优化算法改进的DBPSO算法,通过对比BBPSO和DBPSO在计算效用上界过程的收敛速度证明DBPSO算法更新规则的合理性和有效性,结果如图6所示。

图6 2种算法效用值对比
从图6可以看出,BBPSO算法能够在第62次迭代时收敛到最优值685 719,融入交叉操作后的DBPSO算法能够提高收敛速度,在第51次收敛到最优值,证明本文方法是可行的。
DBPSO算法将交叉算子以粒子群的方式融入BBPSO算法中,其实质是利用交叉算子将项与项之间的关系信息加入到粒子更新过程,相比BBPSO,使用了更多的信息,因此加快了算法的收敛速度。
3.2.2 高效用项集数量
原始适应度函数使用效用信息,在进化过程中,只搜寻最高效用区域,但对高效用项集挖掘问题,高效用项集不集中在某一块区域,本文提出的改进适应度函数能够使得在不增大子空间的前提下,使子空间更加分散,从而覆盖更多的高效用项集。
高效用项集个数和适应度函数的关系如图7所示。从图7(a)可以看出,使用原始适应度函数,即用文献[18]算法,当算法收敛后,增加迭代次数,只能在最大效用项集附近搜索,得到的高效用项集较少,而使用改进的适应度函数后,随着迭代次数的增加,搜索的区域也不断增加,得到更多的高效用项集。算法结束后所挖掘到的高效用项集个数对比如图7(b)所示,可以看出,使用改进的适应度函数,可以产生接近全部的高效用项集,而使用原始适应度函数,得到的高效用项集为全部高效用项集的一半左右甚至更低,证明了分散子空间方法的正确性和有效性。

图7 高效用项集个数与适应度函数关系
3.2.3 执行时间
基于粒子群优化算法的高效用项集挖掘属于二阶段算法,是在产生候选项集后通过精确计算项集的效用确定是否为高效用项集。与传统二阶段算法的区别在于粒子群算法通过迭代遍历的位置成为候选项集,而传统的二阶段算法是在指数空间中剪枝不合理的子空间,剩余的子空间成为候选项集。UP-Growth算法是目前广泛应用且效果较优的二阶段算法,将分散子空间方法和其进行对比,能够表明方法的高效性。对比结果如表2所示。

表2 DBPSO和UP-Growth对比结果
在表2中,DBPSO算法执行时间低于UP-Growth算法,通过候选项集个数可以看出,DBPSO算法减小了传统算法的搜索空间,虽然没有得到全部的高效用项集,但效率明显提高。
4 结束语
本文提出一种基于双重二元粒子群优化的高效用项集挖掘算法。该算法不仅通过以粒子群引入交叉算子的方式加快收敛速度,而且通过改变适应度函数的分散子空间方法挖掘更多的高效用项集。实验结果表明,相比传统的二阶段高效用项集挖掘算法,本文算法节约100倍左右时间,具有较高的效率。下一步将考虑从算法的并行计算角度加快算法运行效率。
