基于自编码器的图像去噪设计与实现
2019-01-02潘伟民
陈 琦,潘伟民
(新疆师范大学 计算机科学技术学院,新疆 乌鲁木齐 830054)
随着数字信息时代的到来,尤其是计算机技术的迅速发展以及图像数字化设备普及程度的提高,人们接收到越来越多的多媒体信息[1]。据统计,其中70%是来自图像的视觉信息[2]。但图像在数字化过程中,会不可避免地遭受噪声污染,这将使得图像质量恶化。这些噪声不仅降低了人们阅读图像的主观体验,而且会对计算机图像识别带来负面影响[3]。因此,在图像处理领域,图像去噪研究成了一个非常热门且十分重要的研究方向[4]。
传统去噪方法通常是使用滤波器对图像噪声进行滤除,例如中值滤波算法可有效地滤除椒盐噪声,均值滤波算法则适用于滤除高斯噪声,但这些滤波算法通常只对特定的噪声模型有效[5]。实际情况中图像很可能被不同类型的噪声污染[6]。所以传统的去噪方法不具有通用性。文章基于深度神经网络的图像去噪模型主要针对自然场景中图像最常见的两种噪声,椒盐噪声与高斯噪声开展研究。为了提高图像去噪速度,借鉴了自编码器的网络结构,并将其改进以符合图像去噪的要求。文章提出的方法不仅训练参数更少,而且经过实际检验发现,此网络模型能够获得比传统去噪方法更好地去噪效果,原图细节能得到较好的保留,而且对混合噪声也有不错的去噪效果。
1 研究现状
近年来,深度神经网络的快速发展倍受瞩目,这种深层神经网络结构能够拟合复杂的样本特征。基于这种特性,在图像去噪领域出现了使用FSRCNN神经网络模型进行去噪的方法[7],基本实现了对图像中的混合噪声进行滤除的目标。但FSRCNN网络最初是被设计用于图像超分辨率处理任务,并不能很好地适用于图像去噪任务,所以文章对网络的最后一部分反卷积网络进行了改造。整个处理过程分成了:1)特征提取;2)维度收缩;3)非线性映射;4)维度放大;5)图像重构等过程,环节较多结构复杂。最初的FSRCNN网是为完成超分辨率任务而被专门设计的,整个网络采用了平行结构,即每层网络只对特征图的数量进行了放缩处理,而所有卷尺层的长宽尺寸不发生变化。为完成去噪任务而改进的FSRCNN网络继承了这一结构,这导致了整个网络的参数较多,增加了运算量。Wang cun等人发现这种网络结构在应用于真实场景图像去噪任务时,FSRCNN网络不能很好地区分噪声和自然纹理,可能造成图像细节丢失[8]。
针对以上情况,文章的目标是在不降低图像去噪效果的前提下,设计一个更快速的网络模型实现图像去噪。Goodfellow[9]等人提出深度自编码器能够指数级减少训练数据和计算需求。文章采用了基于自编码器的神经网络去噪模型,以加快网络的运算速度。这个网络模型不仅在每层的特征图数量有放缩处理,在卷积层尺寸上也有变化,最明显的是采用了哑铃形状的自编码网络结构。卷积层的长宽尺寸与特征图数量成反比,这大大减少了网络的参数数量。通过计算可以得到FSRCNN去噪网络一次前向计算过程共需要移动64*8=544次卷积核,而文章基于自编码器的去噪网络,同样的一次过程卷积核只需要移动2*(32+16+8+4)=120次。
2 模型与算法
模型的整体算法流程如图1所示,其过程表述为:
(1)构建图像数据集:选取自然场景中的人物、风景、建筑等图像,这些图像是无噪声的清晰图像数据,分成训练集和测试集,比例为9:1。
(2)将图像训练集加入噪声后送入神经网络的输入层。通过前馈运算得到一个输出结果,将这个输出结果与清晰的图像数据对比,计算出损失函数从而对网络进行反向优化,更新各隐层的参数。经过这样多次迭代后得到自编码器网络模型。
(3)利用测试数据集对得到的网络模型进行仿真测试,模型输出即为去噪网络模型。

图1 自编码器去噪网络的训练流程
2.1 自编码去噪网络模型
由于不同的去噪网络模型直接决定着图像去噪的整体性能,是整个图像去噪研究的核心环节,因此设计自编码去噪网络模型是文章研究的重点。自编码器(Autoencoder)的概念在1986年由Rumelhart提出,并将其用于复杂数据的降维处理,促进了深度神经网络的发展。自编码神经网络是翻译型网络模型,它使用了反向传播算法,并让目标值与输入值建立某种对应关系。而图像去噪本质上也是一种翻译或转化过程,需要将含有噪声的图像按照某种对应关系转化为清晰图像。文章将自编码器设计成了带有多个卷积层与反卷积层的深度学习网络。一共有7个卷积层,可将自编码器分成两个部分,分别是编码器和解码器,其网络结构如图2所示。
为了使去噪网络模型能够处理自然图像,文章将每幅图像的数据转化为一个3维矩阵。实际训练过程中,为了加快网络的训练速度,每次送入网络64个图像数据,所以传入到输入层的数据为一个4维矩阵。自编码器在每一层的最后都加入了激活函数f(x),目的是使模型能够学习到非线性的数据模型,具有更强的学习能力。在encoder部分的输入至第3层采用了leaky relu(x)激活函数,在第4层卷积层上使用了sigmoid(x)激活函数。在decoder部分的第5至第7卷积层使用了relu(x)函数,最后一层使用了tanh(x)激活函数。这四种激活函数的公式和图形如图3所示。
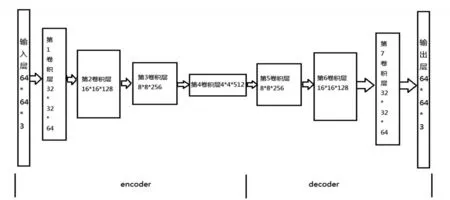
图2 自编码器网络结构图

图3 文章用到的四种激活函数
文章采用卷积核为(5*5)的卷积层来组建整个自编码器模型。卷积神经网络通过共享权值的方法大大减少了参数的数量。卷积神经网络的前向传播如公式(1)。使用来表示网络中正向传播节点矩阵中的第i个节点,卷积核输入节点(x,y,z)的权重,这是一个3维矩阵,使用bi表示第i个节点矩阵对应的偏置值,则单位矩阵中的第i个节点的计算值为g(i):

其中ax,y,z为卷积核中节点(x,y,z)的取值,f(x)为所选择的激活函数。
对网络进行训练时,将图像矩阵送入输入层后通过公式(1)与激活函数可以得到最终的输出矩阵。输出的矩阵同输入的矩阵结构相同。将这两个矩阵通过公式(2)计算得出均方误差,将均方误差作为损失函数,对损失函数做梯度下降算法,更新自编码网络中每一层的参数。整个网络就完成了一次迭代学习。

2.2 训练数据集的数据增广算法
深度神经网络有时会发生过拟合(overfitting)的问题,导致这一问题的重要原因是训练集数量不足。但现实中收集足够的符合要求的数据集,并对其制作标签费时费力。为了解决以上问题文章使用了数据增加的方法来扩充噪声图像数据集以提高网络的健壮性。具体方法是在图像数据集中通过模拟这两种噪声的概率分布模型来添加噪声。文章采用的数据集均为彩色RGB图像,像素值取值范围为[0,255],有3个色彩通道。因此在加入噪声时需要限定取值范围并分别对3个色彩通道进行处理。
2.2.1 生成高斯噪声图像
高斯噪声是一种符合正态分布的随机噪声,也是最常见的噪声分布。如公式(3):

其中,Z是噪声数据,符合期望为μ,方差为σ的正态分布,k是噪声强度,X(h,w,c)图像的像素,最后公式(3)对加噪声后的图像像素取值进行限制,避免数据溢出。
2.2.2 生成椒盐噪声图像
椒盐噪声是一种脉冲噪声,在图像中的某些位置随机产生,并将这些位置的像素点赋值为0或255,即暗点或亮点。如公式(4):

其中,X(h,w)是图像中某一位置像素3个通道的整体取值,Y服从参数[0,1]的平均分布,Z满足P(1)=0.5的0-1分布,SNR为设定的信噪比,范围在[0,1]。当Y的取值处于[0,1-SNR]时,像素点有0.5概率取值(255,255,255)为白色盐点,0.5概率取值(0,0,0)为黑色椒点。
2.2.3 生成混合不同噪声的图像
生成混合图像为两种图像的叠加。为了充分训练去噪网络,文章使用了两种叠加噪声的顺序。一种是先叠加高斯噪声再叠加椒盐噪声,第二种是采取了相反的过程。实际上这两种效果区别不大,如图4所示。

图4 加入了噪声的图像
图4 通过以上方法,每幅原图可以生成若干幅噪声图像样本,使得训练集的数量成倍提高,为去噪网络提供足够的训练样本。而且这种方法也可以避免人工对原图与噪声图像进行匹配标定时所出现的错误。
3 实验验证
基于自编码器图像去噪算法的实验环境包括硬件设备和软件配置两部分,测试所用硬件配置为Intel Core i5 CPU,GPU为NVIDIA GeForce9600 GT,内存为16GB。文章的软件环境为Window10 64bit,CUDA Toolkit,OpenCV 3.0,Python 3.5与Tensorflow 1.1.0。
本次实验使用的数据集为ImageNet图像库,共有10.4万张图像,选取其中1万张图像为测试数据集,剩余的9万余张图像作为训练数据集。
对图像质量的评估主要使用主观观察与客观分析相结合的方法。文章首先做图像去噪的展示,之后引入一种在图像评价体系中广泛使用的SSIM(Structural Similarity)结构相似性算法,对几种去噪方法得到的图像进行比较。
3.1 主观观察图像去噪效果
3.1.1 自编码去噪网络与传统去噪方法的比较
传统的中值滤波、均值滤波与基于深度学习的自编码器去噪网络,对不同图像噪声进行滤除时的效果展示如图5所示。

图5 不同去噪方法的图像展示
其中图(a-c)分别为在原图上增加了椒盐噪声、高斯噪声以及混合噪声后的图像;图(d-f)为对不同的噪声图像使用中值滤波后得到的图像;图(g-i)为对不同噪声图像使用均值滤波后得到的图像;图(j-l)为文章中的自编码器图像去噪网络对噪声图像的去噪效果图。
从图5可以看出,中值滤波可以很好地处理椒盐噪声,但是对高斯噪声的去噪效果欠佳,而均值滤波与之相反,经过均值滤波处理过的椒盐噪声图像中椒盐噪声依旧存在,并且两种传统的去噪方法都使得图像部分细节丢失。当面对两种噪声叠加的图像时,传统的去噪方法无法有效地去除噪声,使得图像失真严重。从图5中可得,文章介绍的基于卷积神经网络的自编码器的降噪效果明显好于前两种传统方法,图像去噪效果明显。在噪声叠加且噪声强度十分大的情况下,图像的噪声被基本滤除,没有明显的噪声残留,并且图像细节基本得到了保留。
3.1.2 自编码去噪网络与FSRCNN网络的去噪效果对比
对比FSRCNN去噪网络的去噪效果图6,可以看出原文中图像的噪声强度比文章中采用的噪声强度小,图像经过去噪处理后基本滤除了混合噪声,但是有明显的椒盐噪声残留。

图6 FSRCNN网络中的去噪图像展示[1]
3.2 使用SSIM算法对不同去噪方法的效果进行统计
SSIM(structural similarity index)为结构相似性算法[10],是一种衡量两幅图像相似度的评判标准。文章将SSIM的取值规范在(0,100)范围,得分越高说明图像的去噪效果越好,其统计结果如表1所示。

表1 SSIM值统计表
SSIM的统计值也表明了文章的自编码器对噪声图像的去噪效果得分高于传统的去噪方法,而且对于混合噪声也有很好地去噪效果。
4 总结
文章对图像的去噪算法进行了简单阐述,针对各种算法的不足设计了用于去除噪声的基于卷积神经网络的自编码器,并设置了适当的算法参数,得出了令人比较满意的去噪结果,与传统的去噪方法相比图像的去噪效果更好,健壮性更强。与当前其他基于神经网络的去噪模型相比,同样能够有效处理图像中的混合噪声,并且网络结构更简洁、计算量更少、网络收敛速度更快。必须指出,文章中的方法对图像的大小尺寸有严格的要求,更大尺寸的图像会使得整个神经网络收敛、速度变慢。未来要不断改进网络结构与算法参数才能满足实际应用的需要。
