基于数据分析的学生行为画像分析
2019-01-02朱梓熙刘文敏徐宝焱黄红梅敖新宇
朱梓熙,刘文敏,徐宝焱,黄红梅,敖新宇
(广东水利电力职业技术学院,广东 广州510635)
一、引言
随着信息技术的不断发展,高校越来越重视数字校园、智慧校园的建设[1][2],各高校的校园建设不断走向数字化。本文通过对高职院校信息进行收集和整理,整合有关学生考勤、成绩和图书借阅情况等方面的数据,寻找学生的行为规律、研究学生的行为特点,对学生分类进行指标判定,最后进行聚类分析,并将分析结果进行可视化展现,为促进和提高学校在教育教学方面的决策提供了有力支撑。
本文用到的学生考勤数据来自于教师上课的考勤记录。本文用到的学生借阅数据来自于学校图书馆的借阅软件系统。
二、数据预处理
在数据挖掘中,由于数据来源的范围广且数量大,使得数据的质量不是很高,为此,需要对数据进行预处理。数据预处理的目标是通过筛除掉有缺失的数据,从而保证数据的质量,使数据处理能够顺利进行,并通过一些操作来合并必要的数据,变换数据的某些分量使得对同种性质数据标准的统一等。
由于数据主要由学校应用系统导出,这些数据主要以Excel表文件的方式存在。其余数据是来自于不同的系统与部门,所涉及的范围较多,采集到的原始数据中数据结构标准没有统一的格式,同时有很多无用属性和本次研究的主题无关。另外,种种原因造成部分数据缺失,如学生休学和缺考等原因,所以需要将这些数据内容进行清除,剔除这部分数据。在收集的数据中,有些数据项被发现出现了重复,需要剔除这些重复的数据。本文采用合并表、学生信息过滤、筛选关键信息、统一数据类型等方法对数据进行清洗,并把清洗后的数据制成数据表的形式保存到数据库中,以保证数据的一致性。
三、数据整合与建表
确定数据表的数据结构是数据分析的首要任务,将所收集到的数据经过整合后可分成以下几类:学生考勤数据、学生图书馆借阅数据、学生历史成绩数据以及学生部分信息数据。结合学生画像的目标,构建学生信息结构表、学生成绩信息结构表、学生缺勤信息结构表、图书借阅信息结构表。如表1-4所示。

表1 学生信息结构

表2 学生成绩信息结构

表3 学生缺勤信息结构

表4 学生图书借阅信息结构
四、确立学生“画像”指标
通过分析现有数据特征和学生的学习行为来构建学生的学习行为“画像”的数据特征,为此,确定哪些行为可以用来构建学生画像是必要的。在本次数据中,学期缺勤次数、学期图书借阅次数在很大程度上体现了一个学生对课堂老师授课内容的重视和学习努力程度,而学期成绩平均分则能直接客观地体现出学生在本学期对所学内容的掌握情况。因此,将学生考勤情况、学生图书借阅情况以及学生成绩等数据用来对学生的学习行为进行画像,并确定相应的指标,指标细分如表5所示。

表5 相关学习行为的数据表征和取值范围
五、聚类分析
K-means算法[3]是一种应用十分广泛的聚类算法,它的目标是将n个数据点划分到m个类簇中,以距离作为数据对象间相似性度量的标准。在K-means算法中,需要预先设定k个初始质心,由于K-means算法采取局部最优,所以初始质心的选择直接关系到数据集中的最终聚类效果。
不同属性往往具有不同的量纲和量纲单位,之间的差别可能很大,如本次处理中的学生成绩与学生缺勤次数。对这些差别较大的属性值不进行处理可能会影响数据分析的结果,在以距离为基础的算法中,取值较大的属性会起到主导作用。在进行K-means聚类前,要对数据进行标准化处理,消除属性间量纲与大小差距过大的影响,提高聚类效果。
K-means算法计算高效,但是有一个缺点,就是要事先设定初始质心的数量k,而k的选取直接关系到最终的聚类效果,所以一般要经过多重分析来确立k的值,但这在实际项目中是比较难以确定的,特别是在处理一个高纬度、难以进行可视化数据的时候。本文根据聚类模型内部误差平方和来确定聚类模型的好坏。获得簇内部的误差平方和。基于这个属性值,采用肘部方法[4],对给定的任务估计出最优簇的数量。算法如图1所示。在算法中,n_jobs是并行的进程数,n_clusters是初始的簇的个数。

图1 “肘”算法
六、实验结果与分析
本文实验数据的来源是某高校校园各部门所积累的历史数据,由于之前的数据过于杂乱,在此收集了该校某系学生的2017年9月到2018年2月这段时间内的学习、考勤数据与图书借阅数据,总共35808条数据,将这些数据进行整合后存放到数据库中用以分析实验。本次实验选取学生“画像”特征库中部分重要指标来建立学生行为模型,在此使用python等语言来编写相关的K-means代码,进行模型的构建与分析,并将分析结果进行可视化展示。
使用算法1处理结果如图2所示。从图3中可以知道聚类数为4时的拐点最为明显,也就意味着针对本次数据来说,最优簇的数量为4,一般而言,肘部方法所得出的结果并不是绝对的,还要结合对该数据的讨论与设想才能得出较好的答案,在本次实验中,结合数据类型等各个方面情况,最终确立了簇的数量为4。

图2 误差和聚类数的关系
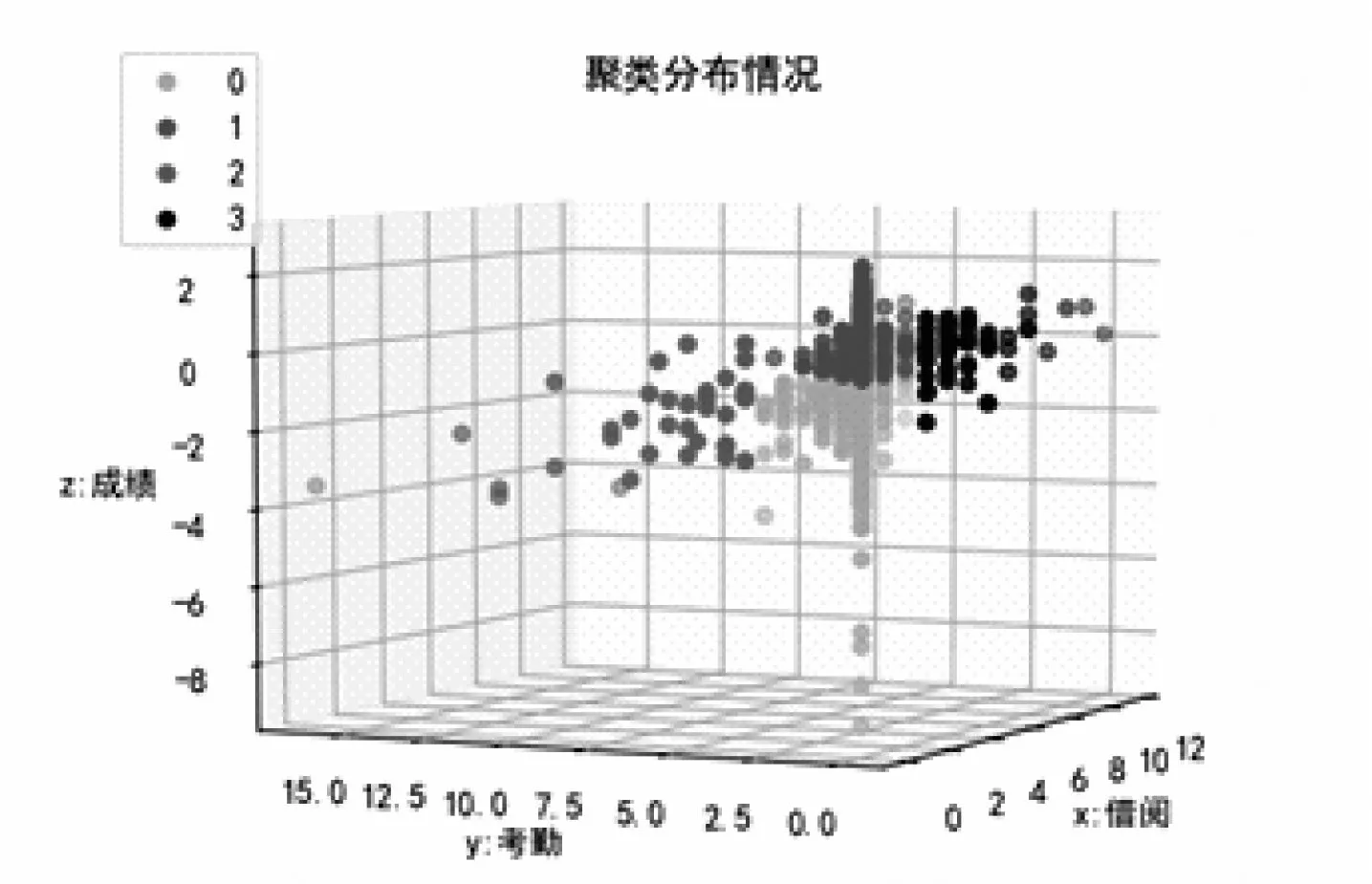
图3 三个指标构成的聚类图
学生“画像”特征搭建的时候选取三个指标(借阅、考勤、成绩),这三个指标正好可以用三维的方式来进行展示,并且效果是最好的,图3是聚类完成后的可视化三维视图,从图3中可以看出,在本次的聚类中,各点分得较为均匀,聚类效果较好。

图4 聚类雷达图
图4的聚类雷达图展现了本次聚类后每个类别的具体情况,在图中可以看到,编号0的类别属于借阅次数较低、考勤率高、成绩较为普通的学生;编号1的类别属于借阅次数较低、考勤率高、成绩优秀的学生;编号2的类别属于借阅次数高、考勤率高、成绩优秀的学生;编号3的类别属于借阅次数低、考勤率低、成绩较差的学生。并由此得出表6,结合表6可以看到努力学习且学习成绩较为优异学生占到学生总数的65%,成绩一般的学生也占到学生总数的33%,可以看出该校大部分学生学习还是比较刻苦的,只有极少数学生的努力程度不够,努力程度不够且成绩较差的学生占学生总数的2%,对这方面的学生可以加以督促,以便提高他们的学习成绩。
另外一个有意思的发现是平均借阅次数和平均成绩的相关性不大,而且,第一类学生借阅次数比第二类学生借阅次数少很多,但成绩还要高一些。似乎暗示图书馆的图书借阅功能和学生学习成绩没有太大的相关性,而与考勤次数是息息相关的,可能需要更加细节的数据才能更好地分析图书馆学习资源是该如何被利用。

表6 每个类别的具体情况
七、结束语
本文通过对校园学生数据的处理和聚类分析,对学生行为进行画像,一方面是可以对学生进行一个行为描述;另一方面可以通过模型反馈,了解学生指标间的影响因素,得到学生的行为特征以及学生的初步画像。目前,由于数据类型较少,得到的学生行为特征还不够详细,仅在学生学习行为画像上做了初步尝试,如果想要更加全面地对学生行为进行画像,可以对学生的学习和生活各方面行为数据进行补充,增加分析维度和分析内容,从而能得到更加详细的分析结果,为智慧校园的管理决策提供准确、详细的数据支持。
