基于改进的几何约束算法与卷积神经网络的车辆检测*
2019-01-02周马莉张重阳
周马莉 张重阳
(南京理工大学计算机科学与工程学院 南京 210094)
1 引言
互联网移动通讯等技术的迅速发展给汽车工业带来了深刻的影响,最明显的就是智能汽车开始成为潮流。智能汽车从发展的角度看可以将其分为两个阶段,第一个阶段是智能汽车的初级阶段,即辅助驾驶阶段;第二个阶段是高级阶段,即无人驾驶的应用。而车辆检测是二者的重要组成部分。车辆检测主要任务是对自身车辆周围的行车进行检测,从而使车辆能够及时规避障碍,正确行驶。由此可见,车辆检测效果的好坏至关重要。但在实际检测中面临着光照条件,姿态,遮挡等影响,会造成检出率低,误检测数量多的现象。
国内外已经有许多研究学者提出了一些有效的车辆检测算法。主要有基于视觉的方法和基于运动的方法以及基于神经网络的方法等。光流法中的HS光流法[1]能在运动背景下检测出完整的运动目标,但由于计算量大,对噪声敏感,并且在纹理平滑区域检测不到光流,使其很难直接应用于实时运动目标检测。在基于视觉的方法中。许多早期的研究主要利用车辆的局部对称性,计算一幅图像块关于图像平面竖直轴的对称性。通常情况下,在计算边缘算子后计算图像块上对称性,以识别车辆的后方的垂直边[2~3]。Mahdi Rezaei等[4]使用水平边缘检测与角点检测;文学志等[5]使用纵横比和车底阴影的方法来产生候选区。这些车辆的外观特征容易受到光照,噪声等干扰,使得这些方法不具有鲁棒性。近年来,出现了从简单的图像特征,如边缘和对称性向一般和强大的车辆检测特征集过渡,比如 HOG 特征[6]、Haar-like特征[7]、Gabor特征[8]、LBP特征等[9]。Cheon M等[10]在一个给定的图像块中提取对称的HOG特征用于车辆检测。HOG特征最主要的缺陷是计算起来速度太慢。Haar-like特征是对不同的图像块求和的矩形特征。计算起来很高效,Haar-like特征对于竖直的、水平的以及对称结构很敏感,这使它们能够很好地适应车辆以及车辆部件的检测。Zakaria Z和Suandi SA[11]直接将Adaboost分类器与神经网络分类器结合起来进行人脸检测,取得了较高的检测率,但增加了检测时间。支持向量机(SVM)[12]是一种基于统计的机器学习方法,该方法从一定程度上解决了维度灾难,局部极小值点等问题。AdaBoost[13]也被广泛地应用于分类,通过改变样本数据分布不断更新样本权值来实现分类。Adaboost具有可以快速拒绝负样本的特点,具有较高的检测率但也会产生较多的误检测。近年来,深度学习在分类识别领域取得了十分瞩目的成绩,也吸引了大量的研究者。其中卷积神经网络CNN模型[14]广泛应用于目标的检测,分类与跟踪方法的研究中。在目标检测中,CNN能够在样本量足够的情况下,自学习图像固有的本质特征,具有较高的检测准确性,但是耗费时间较长。因此本文通过Adaboost分类器快速拒绝大部分非车辆区域,再用训练好的CNN模型对Adaboost分类器输出的目标矩形框进行分类判别,以减少车辆误检数,同时本文结合改进的几何约束算法有效地提高了车辆检测的速度。在车辆检测过程中,采用积分图来加速特征的计算。算法的流程图如图1所示。
2 基于改进几何约束算法的感兴趣区域的产生
基于滑动窗口的目标检测方法中利用的是滑动窗口大小与目标大小相等的关系来检测目标。根据相机投影原理可知,同一个目标在图像中会呈现“近大远小”的现象,即距离拍摄点较近的目标较大,距离拍摄点较远的目标较小。对于固定大小的滑动窗口,需要用不同缩放尺度来缩放图像以检测到不同大小的目标。同时,在一个特定的缩放尺度的图像中,由于滑动窗口是个定值,所以只能检测到特定大小的车辆,即只能检测到距离拍摄点特定距离的车辆(假设车辆大小是个定值)。Patrick Sudowe等[15]利用这个关系,提出了几何约束方法。该方法找出了不同缩放尺度图像下的有效检测区域,仅在该有效区内进行滑动窗口目标检测,从而节约了大量的滑动窗口搜索时间。Patrick Sudowe等[15]提取HOG特征,利用该方法进行行人检测,其实验结果表明在保证准确率的情况下,速度较原始的滑动窗口提高了3.6倍。同时,该算法可以在一定程度上提高准确率,因为对于一个缩放尺度,该方法找出理论上车辆可能出现的区域,仅在该区域内进行滑动窗口检测,从而避免了当前窗口在其他区域内的误检。
Patrick Sudowe等[15]方法有效地减少了滑动窗口检测所需要的时间,避免了滑动窗口一些没有意义的搜索。但是该方法对于各个缩放尺度图像都需要计算其与世界坐标系的映射关系Hπ,k与nk,即对于各个缩放尺度图像要想计算出它对应的有效检测区域,需要重复计算相应的映射矩阵,这就增加了大量的矩阵运算。因此,本文对此提出改进。本文的方法与Patrick Sudowe等[15]方法使用相同的坐标表示,本方法并不直接寻找世界坐标系与各个缩放尺度图像的映射关系。而是仅计算世界坐标系与原图像坐标之间的映射关系。依然保证缩放图像的滑动窗口是个定值,然后根据缩放尺度计算出原图像中对应的滑动窗口大小,再根据原图中滑动窗口大小与车辆在大地坐标系中大小对应关系来找出车辆在原图中的有效检测区,然后再将该有效检测区映射到缩放图像中。这样就可以避免重复的矩阵运算。
由于本文采用与Patrick Sudowe等[15]相同的坐标表示,所以,先简单介绍目标点在大地坐标系和图像坐标系中的坐标表示方法以及坐标系之间的坐标转换关系,之后再介绍本文改进的几何约束算法。
2.1 目标点的坐标表示
大地坐标系中地平面位置U=[U,V,1]Τ上,车辆底部距地面高度记为Sb,车辆顶部距地面记为St=Sb+Sobj。车辆底部和顶部的点在图像中投影x=[x,y,ω]Τ分别为 xb,xt:
其中P=K[R|t]为相机的投影矩阵,N是地平面π的法向量。其中,Q0为地平面局部坐标系的原点,Q1,Q2是两个正交的基向量。Hπ=PQ为单应性矩阵,n=PN[15]。
2.2 改进的基于几何约束算法
由车辆在原图像中高度应当对应于原图像中滑动窗口的大小,可以得到以下等式:

其中swindow=simgσk为原图中使用的的滑动窗口大小。σk为缩放尺度,simg为缩放图像中滑动窗口大小,是个常量。
根据式(1)、(2)、(4),带入 yt,yb可得:
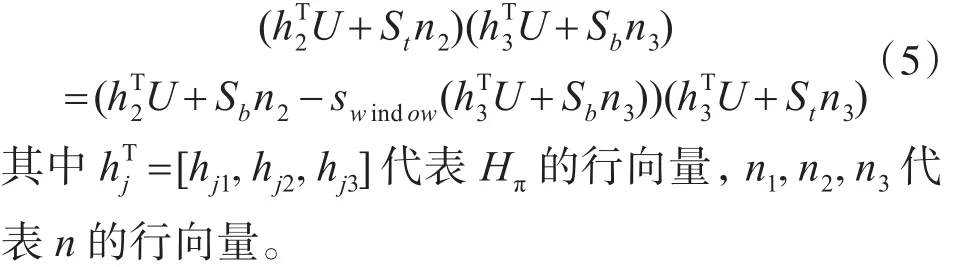
整理上式得到满足等式的地面上的一系列点U组成一个满足下面公式的二次曲线C:

然后将该二次曲线投影到原图像中得到D:

由于 St=Sb+Sobj,Sobj∈[Smin,Smax] ,可以根据Smin,Smax求出 Dmin和 Dmax,然后根据图像像素坐标 xmin和 xmax,求出图像像素坐标 ymin和 ymax。至此,我们求出了在原图中滑动窗口大小为simgσk时,原图中有效检测区域为 (xmin,ymin,xmax,ymax),然后将该有效区域根据缩放尺度σk映射到缩放图像中的有效检测区域 (xmin,k,ymin,k,xmax,k,ymax,k)。至此,我们已经得到了不同缩放尺度图像的有效检测区。
在Patrick Sudowe等[15]提出的几何约束算法中,为了检测不同尺度的物体,滑动窗口检测器以固定间隔的缩放尺度σk下采样的方式处理输入图像。通过调整相机内参矩阵K来达到相同的效果。以下为缩放尺度为σk时,相机内参Kk:

即为求得不同缩放尺度图像的感兴趣区域,需要对每个尺度缩放的图像计算Hπ,k,nk。而在本文的改进的算法中,仅计算Hπ和n。即式(6)中h2,h3,n2,n3都是个常量,不需要对于各个缩放尺度重复计算。
如图2为原始图像,图3为缩放尺度分别为1.00,0.51,0.29,0.16,0.09,0.05时,通过改进的几何约束算法求得的缩放图像的感兴趣区域。固定大小的滑动窗口只需要在这些感兴趣区域中进行搜索来检测车辆,相对于在对应缩放尺度的整幅缩放图像中搜索,该方法有效地减少了搜索时间。

图2 原始图像
3 基于Haar-like特征与Adaboost分类器的车辆检测
3.1 Haar-like特征提取
本文选用对于竖直的、水平的以及对称结构很敏感的Haar-like特征作为初分类阶段使用的特征。Haar-like特征是一种矩形特征,由Viola与Jones[16]应用于人脸识别系统。它定义为图像中相邻区域内像素灰度值总和的差,即白色区域的像素和减去黑色区域的像素和,它反映了白色区域到黑色区域的梯度变化情况。Lienhart等[17]进一步扩展类Haar矩形特征库,使得扩展后的特征集为{f1,f2,…,f15}共15种。车辆图像的Haar-like特征是通过积分图像integral image(ii)计算出来的,图像坐标A(x,y)的积分图像是其左上角的所有像素之和,表示如下:

图3 缩放尺度分别为1.00,0.51,0.29,0.16,0.09,0.05时,该算法得出的有效检测区域

其中ii(x,y)表示积分图,i(c,r)表示图像坐标点(c,r)处的像素值,对于灰度图像,是0~255的灰度值。利用积分图像能够快速、方便地求取车辆图像的Haar-like特征。
3.2 Adaboost分类器
AdaBoost由 Yoav Freund 和 Robert Schapire[18]在1995年提出。Adaboost算法在人脸检测上并取得了较好的效果。Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器,然后把这些弱分类器集合起来,构成一个更强的最终分类器。由于Adaboost分类器具有快速拒绝负样本的特性,本文采用Adaboost分类器作为初分类阶段的分类器。
具体说来,整个Adaboost迭代算法就三步:首先,初始化训练数据的权值分布。如果有N个样本,则每一个训练样本最开始时都被赋予相同的权值:1∕N。其次,训练弱分类器。具体训练过程中,如果某个样本点已经被准确地分类,那么在构造下一个训练集中,它的权值就被降低;相反,如果某个样本点没有被准确地分类,那么它的权值就得到提高。然后,权值更新过的样本集被用于训练下一个分类器,整个训练过程如此迭代地进行下去。最后,将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,使其在最终的分类函数中起着较大的决定作用,而降低分类误差率大的弱分类器的权重,使其在最终的分类函数中起着较小的决定作用。
4 基于卷积神经网络(CNN)模型的车辆识别
CNN由纽约大学的Yann LeCun等[19]提出。深度神经网络是一种类似人脑的简单模型,CNN是神经网络中的一种,它的权值共享网络结构使之更接近生物神经网络,降低了网络模型的复杂度,减少了权值的数量,缩短了网络训练的时间。该优点在网络的输入是多维图像时表现更为明显,使图像可以直接作为网络的输入,避免了传统识别算法中复杂的特征提取和数据重建过程。在二维图像处理上有众多优势,如网络能自行抽取图像特征包括颜色、纹理、形状及图像的拓扑结构。在处理二维图像问题上,特别是识别位移、缩放及其它形式扭曲不变性的应用上具有良好的鲁棒性和运算效率等。LeNet是一个经典的CNN网络模型,该模型是针对手写字体和计算机打印字符识别而设计。其网络结构如图4所示。

图4 LeNet-5网络层次结构
由上图可以看出,输入为32×32的RGB三通道原图像。LeNet-5网络共包括7层,其中,C1层是卷积层,C1层卷积核大小为5x5,因此C1层包括6个大小为28×28的特征图。S2是降采样层,包括6个14×14的特征图。S2特征图中的每个单元与C1中相对应特征图的2*2邻域相连接。每个单元的2*2感受野并不重叠,因此S2中每个特征图的大小是C1中特征图大小的1∕4。C3层也是卷积层,该层的每个特征图与若干S2中的特征图相连接。S4也是降采样层,C5是与S4全连接的卷积层。F6层与C5层全连接。最后,输出层由欧式径向基(RBF)单元构成。卷积层每层通过多个卷积滤波器提取输入的多个特征,通过训练参数,可以提取出能够有效表征图像的特征。池化层利用图像局部相关性的原理,对图像进行子抽样,可以减少数据处理量同时保留有用信息。池化层能够有效地减少参数个数,保持局部范围旋转,平移,伸缩等不变性。
本文使用深度学习框架Caffe[20]中实现的LeNet-5作为神经网络模型,该框架中实现的LeNet-5模型与原始的LeNet-5稍有区别。主要是每层特征图数量增加,同时减少了一个层的全连接,将原C5层作为全连接层。用ReLU取代Sigmoid作为激活函数。ReLU对比sigmoid类函数主要变化是:单侧抑制,相对宽阔的兴奋边界,稀疏激活性。
5 实验结果及分析
本文的实验平台是无人驾驶汽车,选用AVT200W工业相机,采集得到的图像分辨率为1624×1234,能很好地拍摄不同距离的车辆。测试硬件为笔记本电脑,Intel Core i3-2300处理器,主频为2.1GBHz,6GB RAM。软件环境为Windows 7 64位系统下的VS2013编译环境。本文算法基于C++语言结合OPENCV计算机视觉库实现。训练样本和测试样本均来自无人驾驶汽车的车载相机(AVT200W工业相机)在高速公路和城市道路上采集的图像。对于测试集,本文选取两个不同时间段的视频序列,两段共有4700帧图像。这两段视频序列记为dataset1,dataset2。其中dataset1中公路结构简单,光照正常。dataset2中车辆较多,公路结构相对复杂,光照相对复杂,包含相机过度曝光的情况。
首先,为了验证改进的几何约束算法的有效性,在测试集上,用Patrick Sudowe等[15]算法与本文改进的几何约束算法分别得到感兴趣区域,之后均提取Haar-like特征采用Adaboost分类器进行实验。其中,Adaboost分类器由1400个正样本,3000个负样本提取Haar-like特征训练13级得到。本文Adaboost分类器进行车辆检测时使用的滑动窗口尺寸为32×32。根据几何约束关系以及相机投影参数,可以计算该窗口最远可以检测到距离拍摄点前方58m处。因此本文车辆检测范围为从相机拍摄点到前方58m处,车辆检测的准确率和查全率的统计计算均基于该范围。改进的几何约束算法与Patrick Sudowe等[15]算法实验对比的结果如表1和表2所示。实验结果显示本文算法与Patrick Sudowe方法[15]方法在保证准确率与查准率基本相等的情况下,检测速度平均提升了21.23%。

表1 两种算法在dataset1上的比较结果

表2 两种算法在dataset2上的比较结果

表3 不同算法在dataset1上的比较结果

表4 不同算法在dataset2上的比较结果
为了验正本文方法即改进的几何约束算法结合CNN的车辆检测的有效性,本文方法将与传统的Haar-like特征结合Adaboost的车辆检测方法,HOG特征结合Adaboost的车辆检测方法以及LBP特征结合Adaboost的车辆检测方法进行对比。本文的Caffe框架训练样本包括2100个正样本和1700个负样本。本文方法是先通过改进的几何约束算法求得感兴趣区域,在该感兴趣区域内提取Haar-like特征用Adaboost分类器做初步检测得到候选区,之后再用训练好的CNN模型对候选区进行分类。实验结果如表3和表4所示。其中,所有的车辆检测方法都结合了本文改进的几何约束算法来进行加速检测。实验结果表明本文方法准确率最高,LBP特征结合Adaboost方法相对于本文方法具有较高查全率,同时也具有较高的虚警率,无法应用于实验平台。因此,本文方法在较高的查全率下能够有效地减少误报。同时,本实验也说明CNN提取到的车辆特征是Haar-like特征的有效补充。同时,本文方法比仅用Adaboost分类器时间开销大,但本文未用到GPU加速,不需要其他加速计算的硬件条件,对1624×1234图片处理速度大约为3.7帧∕秒。

图5 傍晚光线较暗条件下车辆检测结果

图6 逆光行驶条件下车辆检测结果

图7 相机过曝条件下车辆检测结果
最后,针对复杂光照条件下车辆检测结果如图5,图6和图7所示,其中正确检测结果用白色矩形框表示,黑色矩形框为漏检,灰色矩形框为误检。由图5可以看到,傍晚光线较暗时,能够检测出全部车辆。由图6可以看到车辆逆光行驶,使得车辆的颜色信息发生变化,同时,丢失部分结构信息,在该图中,本文算法存在一个漏检。图7为在相机过曝并且存在遮挡的条件下检测结果,车辆全部被正确检测到。综上,本文的算法对于复杂光照以及遮挡条件下的车辆检测具有一定鲁棒性。但本文算法还有待进一步完善,下一步研究方向是针对复杂环境下的车辆检测进一步提高检测率,减少误报与漏报。
6 结语
传统车辆检测方法容易受到光照、姿态以及局部遮挡等影响,造成漏检测和误检测。对此,本文提出了一种基于改进的几何约束算法并结合Adaboost与卷积神经网络的车辆检测算法,该算法首先对几何约束算法进行改进,避免了其重复的矩阵运算,从而进一步提高了车辆检测的速度,得到了感兴趣区域。然后在该感兴趣区域内,计算积分图和提取Haar-like特征,用Adaboost分类器进行粗分类,分类结果通过训练好的CNN框架来进一步分类。实验结果表明,本文的方法对于光照、姿态以及局部遮挡都有一定的鲁棒性,能够满足实时性要求并且达到较高的检测率和较低的误检率,算法性能较优。
