灰灾变多项式模型的小麦产量预测*
2019-01-02闫海霞刘素兵
闫海霞 刘素兵 张 华
(西安理工大学高科学院 西安 710019)
1 引言
农业是一个国家的国民经济的基础,而粮食生产则是农业的关键。因此,搞好粮食产量的预测十分重要[1~3]。预测粮食产量的方法有很多:神经网络预测方法[4],回归分析法[5~6],灰色预测法[7~8]等。灰色系统是针对信息不完全的对象进行研究,它克服了概率统计的弱点,可以从有限的、离散的数据中找出规律,建立灰色系统模型,然后用它来进行相应的分析[9]。
灰色灾变预测模型[10~12]的特点,关注数据序列中出现突高突低的数据所对应的时刻,称为预测异常值或“灾变”点出现的时间。我国粮食作物主要以玉米、水稻、小麦为主,而小麦主要有春小麦[13~14]和冬小麦两种。春小麦的抗旱能力强,生长周期短,适合春天播种,主要分布在冬季很冷的地方,开春以后播种,秋季收获。我国种植春小麦的地区,主要是在长城以北,如黑龙江、新疆、甘肃、山西和内蒙古。本文研究我国春小麦产量,小麦产量会受到自然“灾害”的影响,比如降水太多会发生“涝灾”,降水太少又会出现“旱灾”,以及病虫灾害都会影响小麦产量[15]。本文将多项式模型与灰色灾变预测模型相结合,预测我国春小麦产量。
2 基于多项式的灰色灾变组合预测模型
2.1 灾变预测
灾变预测[16]:定量求时,是预测异常值或“灾变”点出现的时间。
原始数据序列,规定一个阈值(临界值),把原始数据序列中大于该临界值(上灾变)和小于该临界值(下灾变)的数叫做异常值,将其选出来形成一个新的数据序列,该数据序列就被称为灾变序列。同时以这组数据中各个数据出现的对应时刻(即做灾变映射)。组成灾变时刻序列(日期集)。利用日期集数据序列建立GM(1,1)模型进行灾变预测。
2.2 组合模型原理
多项式数据拟合,是依据原始数据散点图,分析变量间的相关程度与相关关系,构建多项式拟合方程,得到数据的拟合值,然后计算拟合残差。残差反应了实际值与拟合曲线的偏离程度。本文以拟合残差数据为依据,在给定的临界值基础上找出异常值和异常值对应时刻,利用残差将原始数据分为两大类:偏离较多的一类,偏离较少的一类。偏离较多的数值点的日期作为灾变日期点,形成灾变序列,构建GM(1,1)模型,预测出下一个或几个灾变日期点,同时以跳变日期点的原始数据构建GM(1,1)模型,预测下一个或几个灾变值。为更好地反应原始序列的灾变点的变化趋势,不妨以残差的正负符号将灾变点分为两类:上灾变点和下灾变点。然后在分别使用GM(1,1)模型进行预测,对于偏离较少的点,用原始序列中去除灾变点后的序列重新进行数据拟合,同时也可用其预测未来的非灾变时刻的春小麦产量值。
总之,在进行预测时,如果预测点是灰色灾变模型预测出的灾变日期点,则由灰色模型预测灾变值,如果预测时刻不是灾变日期点,则用多项式函数预测。
2.3 灰色灾变预测模型与多项式方程相结合的具体步骤
灰灾变GM(1,1)模型与多项式拟合方程的具体步骤:
1)符号假设
2)建模方法
由原始数据序进行拟合,得到三次多项式拟合公式和残差序列。
若该点的残差绝对值大于给定的临界值,则认为该点为灾变点,否则为非灾变点。根据残差的正负号,将灾变点分为上灾变点(残差值为正)和下灾变点(残差值为负)。将上灾变点日期和相应原始数据灾变值分别组成灾变日期序列P0=(p(1),p(2),…,p(r)) 和 对 应 的 灾 变 值 序 列=(X0(p(1)),…,X0(p(r)))。同理下灾变点日期和相应原始数据灾变值分别组成灾变日期序列Q0=(q(1),q(2),…,q(s)) 和 对 应 的 灾 变 值 序 列=(X0(q(1)),…,X0(q(s)))。建立GM(1,1)模型。
3)GM(1,1)模型原理

由时间响应函数来预测,由于模型的预测值是数据处理后的预测值,所以需要对预测值进行累减后就还原为原始数据系列x(0)的模拟预测值,即

3 预测模型在我国春小麦预测的应用
3.1 数据处理
采集到1995年~2014年我国春小麦产量(见表1),运用本文的组合模型对我国春小麦产量进行分析、拟合、预测。
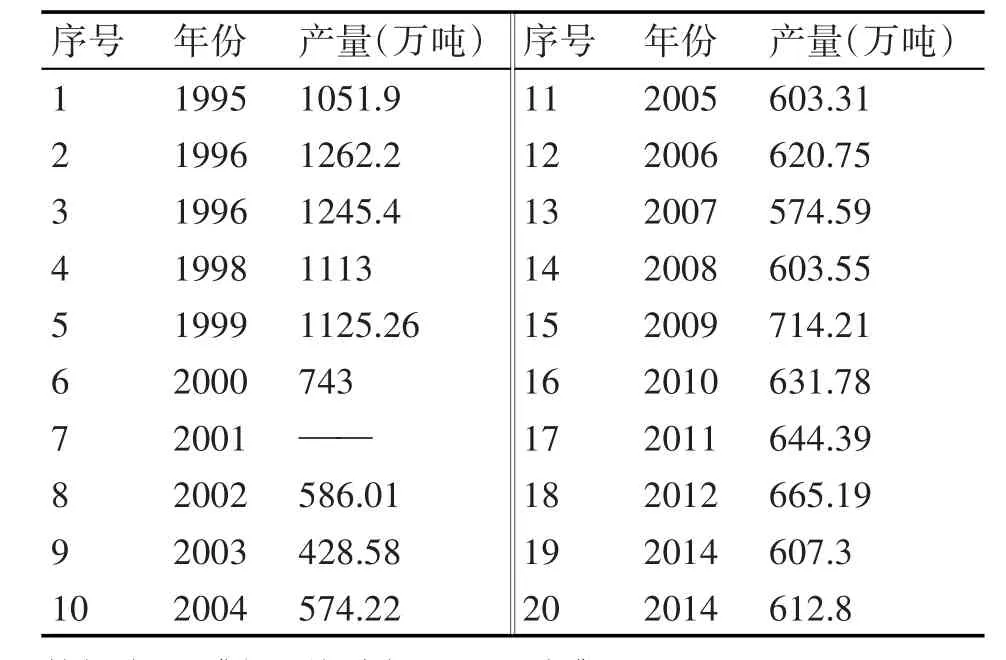
表1 1995年~2014年我国春小麦产量(单位:万吨)
从数据表中看到2001年为缺省数据,这里使用移动平均法补足数据,2001年的春小麦产量以664.54万吨计入计算方法中。使用Matlab软件,对数据进行三次多项式拟合,得到拟合方程:

3.2 模型检验
对灾变日期序列和灾变值序列,运用GM(1,1)模型计算灾变日期序列P0、Q0和灾变值序列的 预 测 函 数 P̂0Yk+Y 、Q̂0(k+) 和(k+)。
上灾变日期和上灾变值预测函数为

下灾变日期与下灾变值预测函数为

从表2和表3看出,灾变灰色模型的拟合残差比三次多项式拟合残差小,说明灰色灾变模型的拟合程度较好。

表2 上灾变点的三次多项式与GM(1,1)拟合结果比较
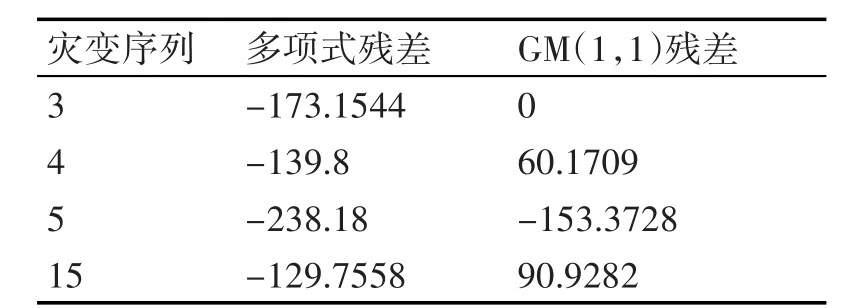
表3 下灾变点的三次多项式与GM(1,1)拟合结果比较
原始数据序列中除去灾变点数值的其他值为非灾变值,相应日期点为非灾变日期点T0=(2,6,7,10,11,12,13,14,16,17,18,19,10),用非灾变日期点及相应数值,重新使用三次多项式拟合,有

由R2显然得出,对数据进行分类的拟合精度明显得到改善。
3.3 模型预测
使用新的模型对我国春小麦产量进行预测,由上下灾变时间点预测函数知道,下一个下灾变点是2017年,下一个上灾变点时间点是2004年。从数据表中可以看出2004年用多项式拟合划分为非灾变点,但是按照上下灾变点的划分,2004年拟合残差为正值,基本符合模型条件。2015年、2016年不是灾变点,故使用三次多项式模型预测,2017年为灾变点,用下灾变预测函数预测,2017年我国春小麦产量为667万吨。
4 结语
总体来看我国春小麦产量,1995年~1999年春小麦产量相对稳定,2000年由于种植面积减少,产量减少近35%,之后几年小麦产量虽有起伏但相差不大,2001年缺省,2003年产量最低只有400万吨,2009年春小麦产量超过700万吨。本文通过分析春小麦产量的变化趋势,将三次多项式模型与灰色灾变模型相结合,首先对原始数据进行筛选,将原始数据分类,组成灾变时间点序列,灾变是序列,非灾变值序列。同时对未来的灾变时间点及相应的产量值进行预测,减少了单一模型的长期预测误差。
本文的灰色灾变多项式组合模型,在一定程度上能反应我国春小麦产量的变化规律,符合我国经济发展情况,也提高了预测精度。当然也存在不足,本文没有考虑影响春小麦生长的环境、气候、病虫等方面,所以在预测上还是有一定的出入。
