深度学习在现勘图像分类中的应用
2018-12-26白小军申宇飞
白小军, 刘 颖, 申宇飞, 周 冬
( 1 西安工业大学 计算机科学与工程学院,陕西 西安 710016;2 电子信息现场勘验应用技术公安部重点实验室, 陕西 西安 710121 )
现勘图像是现场勘验信息的重要组成部分,其分类和检索可为刑侦破案提供重要线索[1]。图像分类和检索任务都依赖于图像特征[2-3],目前来看,图像特征可分为浅层特征与深度特征两大类。浅层特征是经过人工设计的特征表达方式,主要使用颜色、纹理、形状等信息,由图像专家基于领域知识设计合理的算法提取和表达;深度特征则是近几年被提出,是一种基于数据驱动的自适应特征表达方式,该方式不需要多少领域知识,只需迭代运行一些简单的过程即可获得高质量的特征。
文献[4]中提出了一种两层体系的刑侦现勘图像检索方法,指出不同类别的图像适用的特征有所差异,因此,首先要对图像分类,然后根据类别选择合适的特征执行检索,但文中使用的浅层特征分类效果不够理想。文献[5]提出了一种改进的现勘图像分类算法,提高了分类的准确率,但计算量大,效率不够理想。以上两篇文献都采用浅层特征执行分类任务,本文研究基于深度特征的图像分类技术,采用卷积神经网络,在刑侦现勘图像库上进行训练优化,以优化的深度网络提取图像特征,并进行图像分类。
1 卷积神经网络与训练优化
卷积神经网络是最有代表性的人工神经网络,在深度学习中获得了广泛的应用。一般的卷积神经网络通常由卷积层、池化层、全连接层以及分类层等多个层级构成。纽约大学教授Yann LeCun在1998年提出的LeNet[6]是早期卷积神经网络的代表,在手写数字识别方面取得了巨大的成功;近几年最有代表性的卷积神经网络是由牛津大学计算机视觉组(visual geometry group,VGG)与Google DeepMind研究员一起研发的VGG[7]网络,以及由微软亚洲研究院的何凯明团队提出的深度残差网络[8](deep residual network,Res)等。
VGG通过反复堆叠3×3的小型卷积核和3×3的最大池化层,构筑深度神经网络;面对层数加深时的梯度消失问题,通过逐层训练的方式,成功将网络深度增加到16层以上,在ImageNet数据集上使图像分类的错误率降到了7.3%。Res网络则针对更深层次的网络训练困难的问题,提出了残差学习框架,采用堆叠残差结构块的形式,构建超级深度网络,通过算法优化,使其计算复杂度比VGG网络更低,并使图像分类的准确率首次超越了人类的分辨率。
VGG网络的典型结构如图1所示。图中Conv1~Conv5为5组卷积,每组中又可包含多层卷积,每组卷积后都带一个最大池化层(max pool);其后有3个全连接层(fc1-fc3),中间使用dropout技术解决过拟合问题;通过卷积、池化和全连接等步骤,提取到图像的深度特征。最后一层是Softmax分类器,根据fc3层的输出实现图像分类。
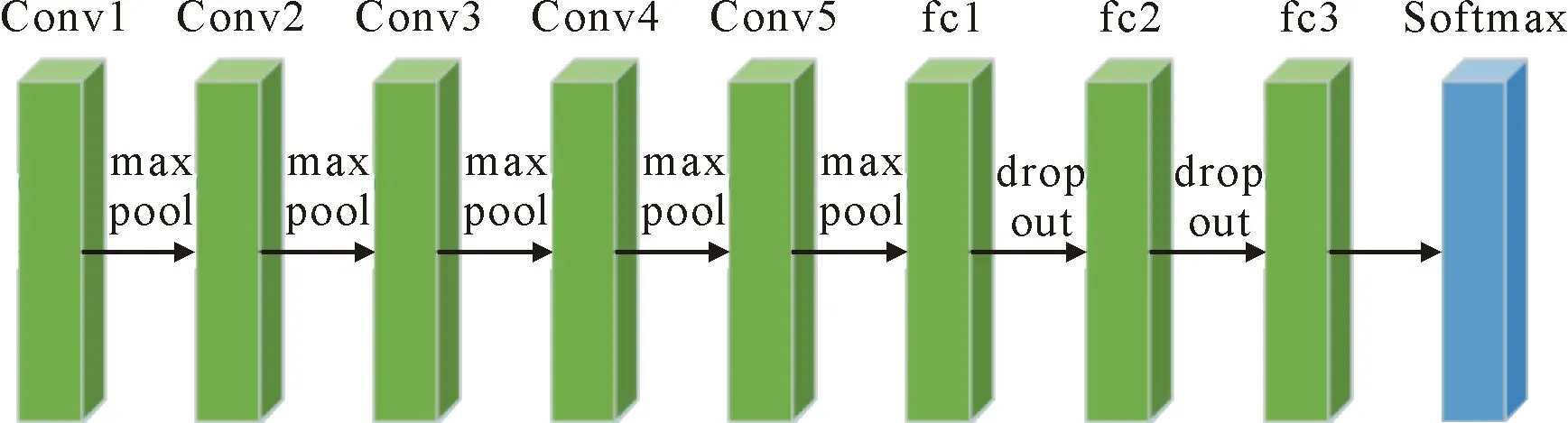
图1 VGG网络结构示意
对于Softmax分类器,输入向量V,用(V1,V2,…,Vn)表示,输出为代表图像标签的向量S,用(S1,S2,…,Sn)表示,每一个分量代表属于某个类别的概率,Si的计算公式[9]为
(1)
其中i∈(1,n),j∈(1,n)。
fc3层的输出经过Softmax分类器后,转换为分类到n个类别的概率。例如当n=3时,假设Softmax的输出向量为[0.09, 0.67, 0.24],则说明分类到第二个类别的概率为67%。
多层的神经网络中蕴含着海量的参数,能够拟合任意复杂的分类模型,为使网络参数达到最优,需要经过很多轮的迭代训练。训练的目标是使分类损失最小化[9],通常使用的损失函数为
(2)
式中lossk代表第k个样本的分类损失;S为分类器的输出向量,根据式(1)计算得到;ti为期望的输出向量t的分量,若正确的类别维度则取值为1,其它类别维度取值为0。将所有样本的分类损失累加起来,即可得到训练集上的总损失。
为实现最优化目标,神经网络训练中使用梯度下降算法[10]找到损失函数的极值点,具体迭代公式为
wi+1=wi-ηloss(wi),
(3)
其中,loss(wi)为第i轮迭代后的分类损失,wi为第i轮的模型参数,常量η代表学习速率。该式的含义是根据第i轮训练的模型参数和损失,通过求偏导的方式找到损失下降最快的方向,进而调整下一轮训练的模型参数。训练的过程就是迭代执行梯度下降算法,直到达到最大训练次数,或使损失达到收敛。
Res网络的结构过于复杂,这里不做详细介绍。同VGG网络一样,Res网络也分为特征提取网络与分类器两部分,同样使用SoftMax分类器,其训练和优化方法与VGG网络相同。
2 基于深度网络的现勘图像分类
考虑到卷积神经网络不但分类准确率高,而且具有良好的跨域通用的特性,因此,使用预训练的网络模型,在新的数据集上进行微调(再训练调优)后,一般都可以很好的适应新的数据集。所以本文分别选择了16层的VGG网络和50层的Res网络,在具有10个类别、2900张图片的刑侦现勘图像库上进行训练和测试,过程如图2所示:
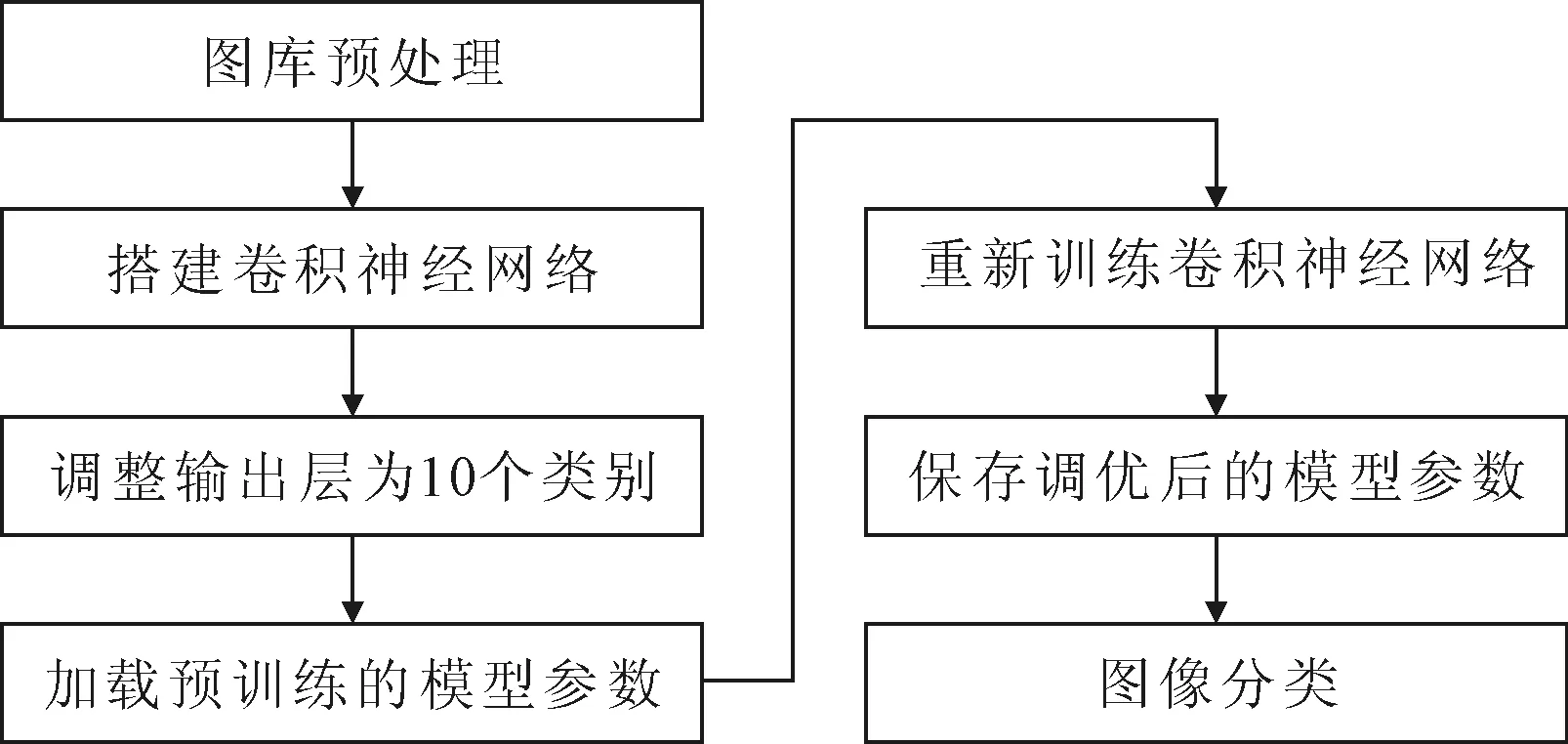
图2 现勘图像分类任务训练与测试过程
第1步对现勘图库中的图片进行预处理,主要是为每张图片标注类别;
第2步基于TensorFlow平台,选择一个开源的神经网络项目,在本地搭建自己的深度网络;
第3步调整全连接层(fc3)的输出类别数。考虑到一般的神经网络都在ImageNet数据集上训练和测试,其输出类别通常在1000个以上,所选用的项目只包含10个类别,所以调整最后一个全连接层(fc3)的输出类别数为10。
第4步加载预训练的模型参数。对于深度网络,从头训练使其达到最优是一件非常困难的事情,利用卷积神经网络具有良好的跨域特性,使用预训练的模型参数作为初始参数,可以快速训练获得局部最优解,所以在网络初始化时需要要加载预训练的模型参数;
第5步获得最优刑侦图库的模型参数。使用标注好的刑侦现勘图库,在初始网络模型上进行再训练,对模型参数进行微调,以得到最优刑侦图库的模型参数;
第6步导出保存这些模型参数。调优后的模型参数将用于后续的图像分类、检索等任务,所以需要导出保存这些模型参数;
第7步使用优化好的卷积神经网络,对测试集中的现勘图像进行分类。
本文的实验数据集采用某省公安厅刑侦局提供的2900幅刑侦现勘图像,共分为10个类别,包括车辆、房屋、道路、门窗、指纹、脚印、血迹、凶器、轮胎以及草图等,部分实例图像如图3所示。

图3 现勘图像数据库例图
实验中将2900幅图像分为3部分:取2500幅作为训练集,200幅作为验证集,200幅作为测试集。测试集用于最终测试分类的准确率,而验证集主要用于确定最佳的训练迭代次数。
由于引入了预训练模型参数,训练的迭代次数可以大幅度减小。在训练过程中,既要防止训练不足造成的“欠拟合”,还要防止过度训练造成的“过拟合”。在训练中将学习速率设置为0.001,mini-batch参数设置为30(一次输入30幅图像进行训练),每迭代100轮,导出一次模型参数,并输出一次损失值。实验中得到VGG网络和Res网络的损失下降曲线分别如图4所示。
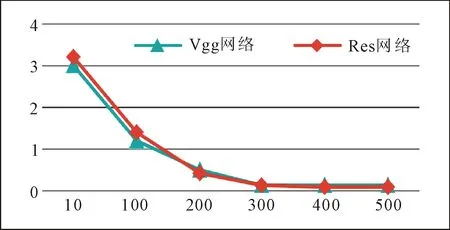
图4 网络训练中的损失下降曲线
为获得最佳模型参数,在验证集上分别导入各次迭代训练产生的模型参数,并分别计算分类任务损失,损失变化曲线如图5所示。可以看出,在训练集上经过300轮迭代后,损失已经下降到了合理的水平;而在验证集上的测试表明,300次迭代后损失产生了震荡,所以确定300次迭代产生的模型为最优解。以该模型为依据,在测试集上进行图像分类实验,测试分类准确率结果如表1所示。
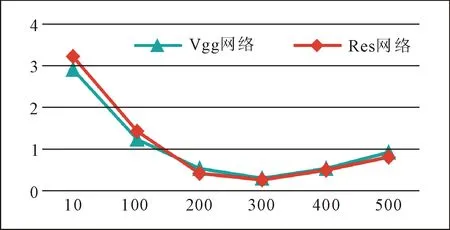
图5 验证集上的损失变化曲线

表1 两种网络下的图像分类任务测试结果
可以看出,Res网络采用更深的层次结构,分类准确率较之VGG网络稍有提高。而与文献[4]中采用传统浅层特征分类的结果相比,采用深度特征分类的准确率有了大幅度提高。
3 改进的特征提取方法
在VGG和Res网络中,最后一个卷积层的输出经过池化进入全连接层,在全连接层自适应的生成图像特征,这可理解为单尺度的特征表达。本文希望找到一种多尺度的特征表达方式[11],以改善特征的质量,进而提高图像分类效果。具体做法是将原来的最后一个池化层,改为金字塔池化层[12]。如图6所示,最后一个卷积层的输出为一系列特征图,对这些特征图分别进行多尺度池化,以增强图像的特征表达能力。
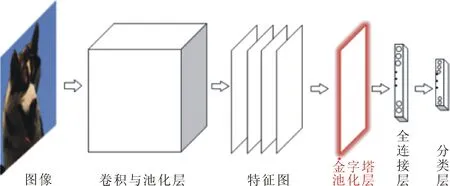
图6 改进的网络结构示意
金字塔池化层的实现方法如图7所示。使用不同尺度大小的网格将特征图分成一个个小块,对于VGG网络提取每个小块中的最大值;而对于或Res网络,提取每个小块中的平均值,分别组成一个特征向量。图中使用了4×4、2×2、1×1的网格将特征图切分别分成16块、4块和1块,对这些小块分别进行池化,得到16维、4维和1维的特征向量,最后将这些特征向量组合起来生成21维的特征向量,这样就完成了对特征图的多尺度表达。
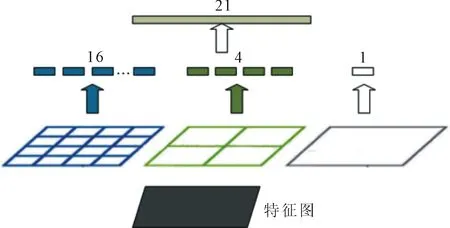
图7 金字塔池化层的实现方法示意
引入金字塔池化后,其对上述刑侦现场图像的测试数据如表2所示。可以看出,改进后的VGG网络分类准确率较之前提高了3.3%,而改进后的Res网络较之前提高了3.5%。
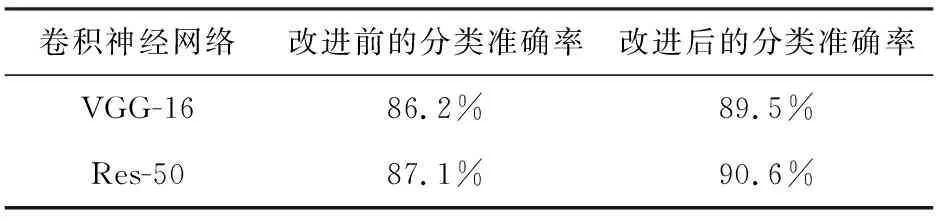
表2 网络优化前后测试效果对比
4 结语
鉴于深度学习广泛应用于图像处理领域所得了传统方法难以比拟的效果,本文尝试将深度卷积网络应用于刑侦现勘图像分类工作,采用先进的VGG网络和Res网络,在现勘图像数据集上进行再训练优化,进而提取图像深度特征进行分类;刑侦现勘图像实验测试结果表明,深的层次结构VGG网络和Res网络特征提取方法相比传统方法准确率均有大幅度提高。另外,采用金字塔池化的方法分别对VGG网络和Res网络进行了优化和改进。实验表明,改进后VGG网络和Res网络的刑侦图像特征分类准确率得到了进一步提高。可见,本文所研究的方法,能够适用于刑侦现场图像处理。
