基于蚁群算法优化Hadoop平台计算效能方法
2018-12-24
(宁夏财经职业技术学院 信息与智能工程系,银川 750021)
0 引言
许多大型网站公司通过在世界各地建置大量服务器,为其它企业和民众提供庞大服务器群的运算能力与储存资源,让使用者可利用任何具备网页浏览器功能的设备,通过互联网就能够快速使用该公司所提供的软件运算与储存功能,而这样的一种新型网络应用概念,就是“云计算”[1]。随着云计算的大量建置,伴随而来的是大数据(Big Data)[2]。而大数据对云端平台与应用程序所带来了容量大、增加快、多样性、可信度的等四个效能挑战特性[3]。目前云服务的运算架构主要是MapReduce分散式处理架构,而Hadoop MapReduce是对应参考MapReduce运算架构与分布式系统等关键技术[4],以Java程序语言实现同时具备分布式储存与分布式计算能力的整合式解决方式。目前,Hadoop平台已相当普及,但应用程序若是在Hadoop平台上使用预设参数值的情况下执行,其执行效能将不如预期[5]。
因此,本文针对大数据在Hadoop平台数据运算的效能问题,结合基因表达编程与蚁群算法的Hadoop平台云计算效能的优化研究(ACO-based Hadoop Configuration Optimization,ACO-HCO),主要结合基因表达编程与蚁群优化算法等相关技术,基于Hadoop的工作历史纪录,找出Hadoop平台的参数与计算效能关联模型,作为启发式搜寻的目标函数,并利用蚁群算法快速收敛的特性,结合Hadoop平台参数与效能关联模型,搜寻出一组优化参数,从而改善应用程序的执行效能。
1 效能优化机制整体架构
由于Hadoop平台的执行效能除了受到Hadoop参数设定的影响之外,也会受到系统资源、软件与网络的影响,因此,本文所提出的ACO-HCO效能优化机制主要有3个特性:(1)收集Hadoop工作历史纪录,避免产生额外负载,导致潜在的模型错误问题;(2)考虑参数设定与运行时间复杂的非线性关系;(3)能够快速收敛产生优化参数结果。
本文所提ACO-HCO效能优化机制的整体架构图,如图1所示。
ACO-HCO效能优化机制的主要运作过程为三个阶段:(1)在ACO-HCO特征分析阶段,通过Hadoop工作特征分析器(Job Log Parser)读取Hadoop程序输出路径中的工作历史日志目录[6],输出符合参数关联建模方法所需的模型输入数据格式;(2)在ACO-HCO参数与效能关联建模阶段,将Hadoop特征分析的结果区分为训练资料与测试数据集,利用基因表达编程法[7],建立Hadoop参数与效能关联模型;(3)在ACO-HCO参数优化阶段,蚁群算法会依据Hadoop参数与效能关联模型,针对荷尔蒙与状态转换机率完成初始化,然后通过蚁群算法的启发式搜寻过程[8],产生Hadoop平台优化参数结果。最终,在Hadoop丛集上,针对给定的Hadoop程序、原始输入数据与ACO-HCO的优化参数设定,观察Hadoop应用程序的执行效能变化情形。

图1 ACO-HCO效能优化机制的整体架构图
2 ACO-HCO参数关联建模
2.1 GEP应用设计
在GEP应用设计部分,针对Hadoop参数设定与运行时间而言,Hadoop的运行时间ET是参数集(x0,x1,…,xn)的一个函数。根据GEP演化机制,能够挖掘出重要Hadoop平台参数与效能关联模型。ACO-HCO利用GEP的染色体储存Hadoop平台参数,每个GEP染色体是由以Hadoop平台参数作为输入,经由演化程序最终产生预测运行时间与实际运行时间最为接近的染色体[9],并译码为表示树,输出形式为f(x0,x1,…,xn)。
2.2 GEP实际结果
在GEP实际结果部分,GEP算法[10]的输入项是一组经由Hadoop工作特征分析器所过滤产生的Hadoop工作的执行样本,作为GEP方法的模型输入数据。而这些数据的产生方式是通过实验环境的Hadoop平台,实验所使用的Hadoop程序包含内建的WordCount与Sort程序,并使用5GB、10GB与15GB的输入数据。每次实验过程随机调整参数设定,母种Hadoop程序执行三次计算后的平均执行时间。
当GEP演化过程的世代数量从20 000个调整至80 000个时,可以得到最终染色体质量(适应值与训练样本数量的比例)大于90%的结果。因此,实验过程将GEP演化过程的世代数量设定为80 000个,并采用典型的基因调整活动发生概率参数,包含单点重组率(0.3)、插入转换率(0.1),反转率(0.1)与基因突变率(0.44)。在完成80 000个迭代的GEP演化过程后,GEP最终输出一个能够代表Hadoop程序的运行时间与10个重要参数间的关联函数:
f(x0,x1,…,xn)=
(x6+x4)×(x8+x9)
(1)
其中,a=sqrt(x0×x8+x3×x1),b=pow(x5,(x2+x1))。当输入参数x0至x9的设定值时,即可通过上式得到Hadoop程序的预估运行时间。因此,上式将作为ACO-HCO参数优化阶段,蚂蚁选择下一个参数节点的目标函数,预估运行时间越短的Hadoop参数节点对蚂蚁的吸引力则越强。
3 ACO-HCO参数优化算法
ACO-HCO参数优化的执行步骤如下:
步骤1:初始化及ACO参数设定
给定程序运行时间上限(tmax)、蚂蚁数量(S)、初始荷尔蒙浓度(τ0)、探索或追随偏向程度参数(q0)、荷尔蒙衰退参数(ρ)、荷尔蒙重要程度参数(α)、执行时间长短重要程度参数(β)。
步骤2:建构最佳参数节点路径
若x0为起始状态,则将S只蚂蚁随机放置在Hadoop参数节点上。每只蚂蚁从目前所在节点出发,计算转换规则[11],以便选择下一个拜访节点、逐步完成一趟完整的里程。
转换规则如式(2)。
(2)
其中,Js(i)是位于节点i的蚂蚁s尚未拜访的邻近节点集合,而不属于Js(i)的节点或是拜访过的节点,其选择机率为0,这样的设计可避免蚂蚁重复经过相同节点;τiu(t)为线段(i,u)在时间t的荷尔蒙浓度,ηiu是选择候选参数值的期望值。q为(0,1)间呈现均匀分布的随机数,q0为设定参数,0≤q0≤1。maxf(x)是找出高荷尔蒙浓度(τ)及GEP目标函数最小预测运行时间成本(η)的节点u,而p为选择下一节点的转换机率,由下式计算得到式(3)。
当q>q0时,虽然荷尔蒙浓度高且预测运行时间最短的节点被选择的概率较高[12],但因蚂蚁仍以随机方式选择节点,因此概率最高的节点未必会被选到,因此其行为较偏向探索。当q≤q0时,蚂蚁被设定必须选择荷尔蒙浓度高及预测运行时间短的节点,故其行为较偏向追随。
步骤3:局部更新荷尔蒙浓度
每只蚂蚁在找寻一个可行解(可能路径)的过程中,每经过一个边(i,j),即对该边进行一次荷尔蒙更新,以避免其它蚂蚁收敛在局部解,并增加路径找寻的多样性。更新幅度与目前这群蚂蚁的表现及选择结果无关,计算方式如式(4)。
τij(t+1)=(1-ρ)τij(t)+ρτ0
(4)
其中,ρ为荷尔蒙衰退比例参数,(1-ρ)为荷尔蒙残留因子,0<ρ<1。区域更新法使拜访过的路段的荷尔蒙减少,因此拜访过的路径对蚂蚁的吸引力越来越小,故可诱导蚂蚁偏向开发新路径,避免蚂蚁局限在定义狭小范围内[13]。返回步骤2直到每只蚂蚁均产生一条完整路径为式(5)。
步骤4:整体更新荷尔蒙浓度
当所有蚂蚁均完成一条完整路径后,便执行荷尔蒙“整体更新法”以强化目前最佳路径的荷尔蒙浓度,计算方式如下所示:
τij(t+1)=(1-ρ)τij(t)+ρΔτij
(5)
其中:若路径(i,j)∈T+,则Δτij=Q/L+;否则Δτij=0,而T+是先前所找到的最佳路径,L+是先前所找到最佳路径的总运行时间。Q为表示荷尔蒙强度的参数,在一定程度上会影响到收敛速度,一般设为100。
只有表现最好的那一只蚂蚁才有遗留荷尔蒙的权力,原因是只在最好的解上增加费洛蒙的设计,有助于蚂蚁尽快搜寻到最佳解。而目前最佳路径未必是目前这群蚂蚁所找到的,可能是先前蚂蚁的搜寻成果。
步骤5:更新最佳路径
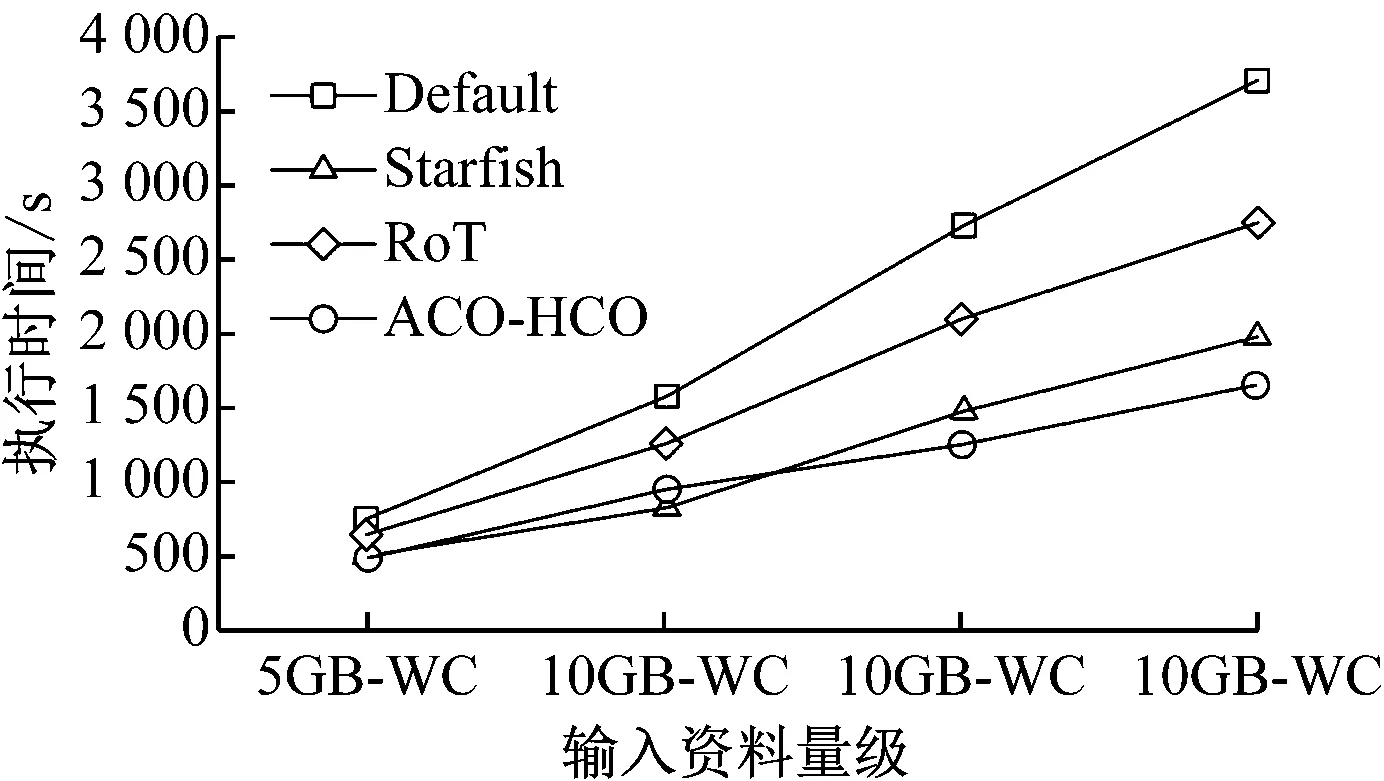
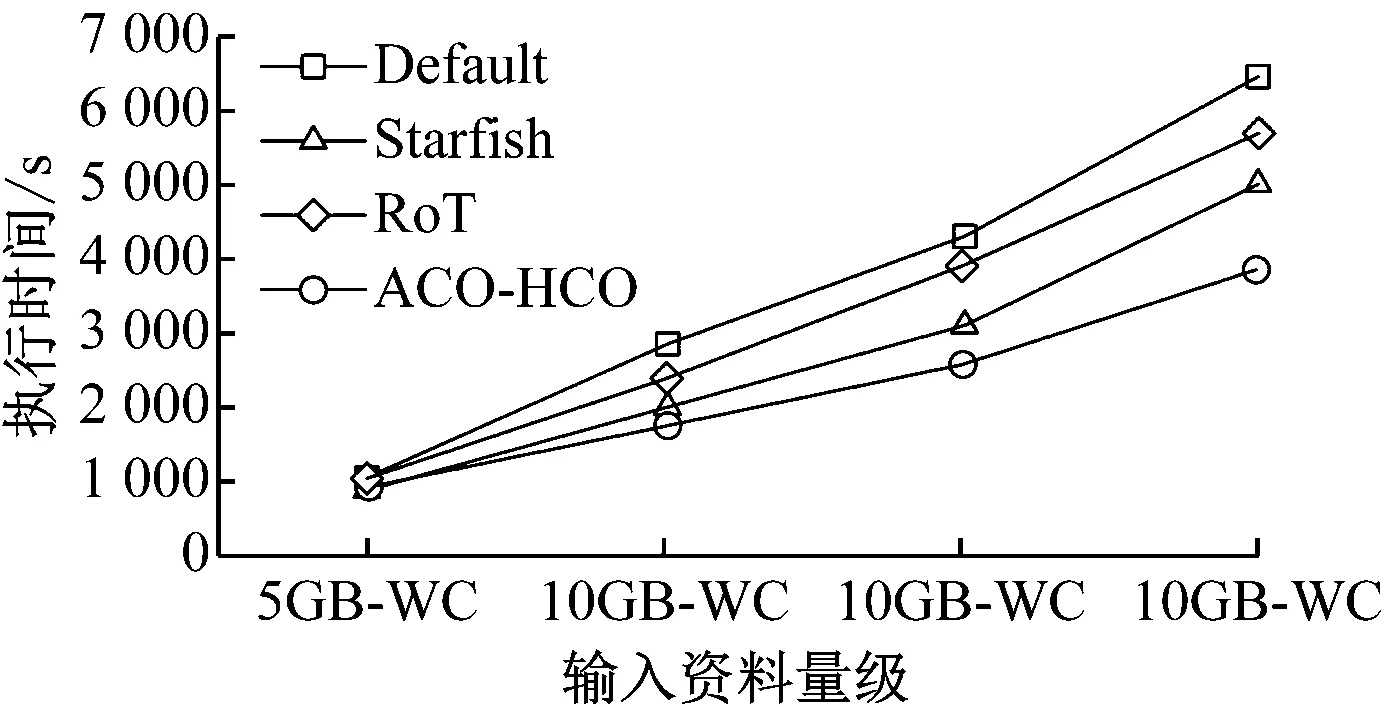
若min(Ls) 步骤6:测试停止条件 ACO停止条件一般设定为时间到达时间上限时间tmax停止。此时,T+为找到的最佳路径,L+为其总运行时间;否则,回到步骤2。 利用所建置的Hadoop实验丛集环境,比较ACO-HCO机制、经验法则(RoT)、Starfish机制以及预设的Hadoop参数(Default)下Hadoop执行效能。通过配置不同的Hadoop平台参数后,在Hadoop实验丛集环境,分别执行典型的WordCount、Sort效能测试工具程序与特殊应用的MR-based LSB程序。其中,WordCount与Sort效能测试工具程序的输入数据量区分为5GB、10GB、15 GB与20GB四个实验量级,输入资料的形态为文字内容,而MR-based LSB程序的输入数据固定为1 500张载体影像图片文件(Lena.bmp),用以比较藏密与取密的运行效能的差异。每组实验执行3次,并取运行时间的平均值作为执行效能结果。 如图2所示。 图2 WordCount程序执行效能比较 在四种不同输入数据的量级下,ACO-HCO机制的WordCount程序执行效能比默认值Hadoop平台执行效能的效能改善率为49%,比经验法则的执行效能的效能改善率为34%,比Starfish机制的执行效能的效能改善率为10%。其中,在输入数据级距为20GB时,最大效能的效能改善率能够达到53%。 不同机制下Sort程序的执行效能比较如图3所示。 图3 Sort程序执行效能比较 从图3可以看出,在四种不同输入数据量级下,ACO-HCO的执行效能比默认值Hadoop平台的执行效能的效能改善率为37%,比经验法则的执行效能的效能改善率为30%,比Starfish机制的执行效能的效能改善率为20%。其中,在输入数据级距为20GB时,最大效能的效能改善率为44%。 ACO-HCO机制执行WordCount程序与Sort程序的效能差异主要原因是由于两者在执行时对系统资源的使用特性不同所导致,WordCount程序执行时是属于CPU密集的运算工作;而Sort程序是属于中等CPU但硬盘I/O密集的运算工作,由于本文所建置的虚拟化Hadoop实验环境,由虚拟化软件管理共享式磁盘,所有VM都必须在队列中排队等候磁盘I/O存取,因此,执行硬盘I/O密集的Sort程序时,效能改善率会明显下降。 ACO-HOC与经验法则、Starfish机制在藏密效能与取密的效能方面的比较,如图4所示。 图4 MR-based LSB程序执行效能比较 从图4可以看出,ACO-HOC 相比于经验法则和Starfish机制的效能改善率分别为6%与3%。由于MR-based LSB程序所处理的输入数据型态是图片文件,有别于输入数据型态为文字型的WordCount与Sort程序能够将输入数据进行切割处理,MR-based LSB程序的Map任务在产生Key-Value数据文件时,是以整个载体图像文件做为Vaule的部分,必须耗量大量读取与写入本机硬盘I/O的处理时间,因此,ACO-HOC的效能改善率明显下降。 在Hadoop平台使用预设参数值执行Hadoop应用程序会存在效能不佳、人工效能调校执行效率差。ACO-HCO机制通过自动化效能调校Hadoop平台参数,改善Hadoop应用程序的执行效能,属于通用性较高的效能调整方法。ACO-HCO效能优化机制主要利用GEP演化机制输入Hadoop历史工作纪录,建立Hadoop参数与效能关联模型,并实作蚁群优化算法进一步搜寻最佳化参数设定。实验结果显示,ACO-HCO机制与采用默认值时相比较,能够明显改善Hadoop应用程序的执行效能。此外,ACO-HCO机制也比目前极具代表性的Hadoop参数优化方法,能够提供更好的执行效能。4 Hadoop执行效能的比较与分析
4.1 实验准备
4.2 WordCount效能测试
4.3 Sort效能测试
4.4 MR-based LSB效能测试

5 总结
