基于改进Apriori算法的运动员多属性训练数据挖掘模型构建及仿真
2018-12-24
(宝鸡文理学院 体育学院,宝鸡 721007)
0 引言
在体育竞技领域中,各项运动所涉及的数据量十分庞大,但就目前来看,这些海量数据的利用率十分低下,难以产生令人满意的效果。因此,如何提高数据的利用率,挖掘出这些海量数据中所潜在的运动员训练规律等有用信息,已经成为了体育竞技领域中的研究重点[1]。随着信息技术的蓬勃发展,数据挖掘技术作为一种涉及众多领域的交叉性学科,逐渐成为人们整合并挖掘海量数据中的有用信息以及规则关联的有效途径。有鉴于此,本文针对数据挖掘技术在运动员多属性训练方面的应用展开研究,以期通过应用恰当的数据挖掘技术,有效地挖掘出运动员训练相关数据中的潜在规则与关联,筛选出其中具有价值的信息,从而实现对运动员训练的数据支持,使训练更加科学、高效[2]。
1 数据挖掘概述
随着社会逐步实现信息化,数据量也随之呈指数地不断增长,如何有效利用这些海量数据中所包含的大量有用信息,成为了整个社会的迫切需求。在此背景下,数据挖掘技术应运而生,它能够从海量模糊而不完全的数据集内发现潜在的关联以及有用信息,还能够根据数据间的关联来实现预测[3]。数据挖掘的算法即关联规则,主要是在相同事件当中探求出所产生的各个项之间的关联。以运动员的训练为例,其中包含了训练强度、身体素质、场地情况等等项,关联规则可以发现各项之间的相关性[4]。通常情况下,主要是通过扫描事务数据库来统计出各项在其中所出现的概率来实现,即这些项的支持度。除此之外,还需要对各项以及各项的组合所出现的概率即条件概率进行计算,也可将其称之为各项以及各项组合的可信度[5]。
目前对关联规则的分类有众多方式,比较典型的如根据关联规则中所包含数据的维数进行分类,从而将其分为单维关联规则与多属性关联规则。针对运动员训练而言,在实际情况中存在着诸多的影响因素,所包含的数据远远超过三个维度,因此在应用数据挖掘技术来探求各因素之间的相关性时,应将其归为多属性关联规则[6]。相对于单维关联规则而言,多属性关联规则所涉及的内容较为复杂,因此实现起来也更为困难。作为一种精准而高效的数据挖掘技术,多属性关联规则通常包括了数据预处理、数据挖掘以及知识表达与评估为主的诸多阶段,如图1所示[7]。
在数据预处理阶段,主要是对数据进行采集、筛选、变换、集合以及规则约束等,是数据挖掘过程中最耗时的阶段;在数据挖掘阶段,主要是通过关联规则、决策树、神经网络等数据处理技术,对经过预处理的数据集进行分析,以此得到数据集中的有用信息以及关联规则[8];在知识表达与评估阶段,主要是将数据挖掘阶段所获得的有用信息以及关联规则表达展示给用户,或者将其以新知识的形式提供给相关应用程序。
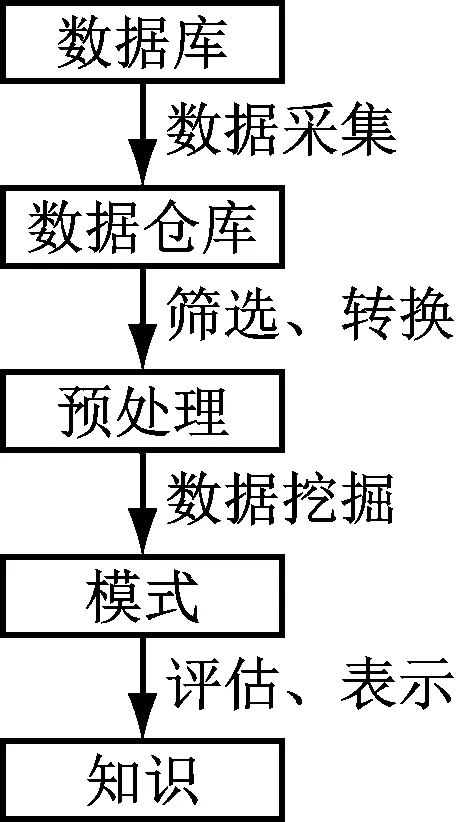
图1 数据挖掘过程
2 运动员多属性训练的数据挖掘算法
针对运动员多属性训练的实际需要,本文初步选择了基于关联规则的Apriori算法来执行相关的数据挖掘工作[9]。在关联规则中具有数值型与布尔型两种分类,而该算法属于布尔型。
2.1 Apriori算法
Apriori算法的流程如下:
步骤1,对事物数据库进行扫描,并计算其中各数据项的支持度,以此获得频繁项集L1;
步骤2,根据频繁项集L1连接得到候选项集C2,并对其执行剪切操作;
步骤3,对事物数据库进行扫描,并计算候选项集C2的支持度,以此获得频繁项集L2;
步骤4,循环执行步骤1-步骤3,直至得到的频繁项集Lk为空;
步骤5,将所得出的全部频繁项集合并为L[10]。
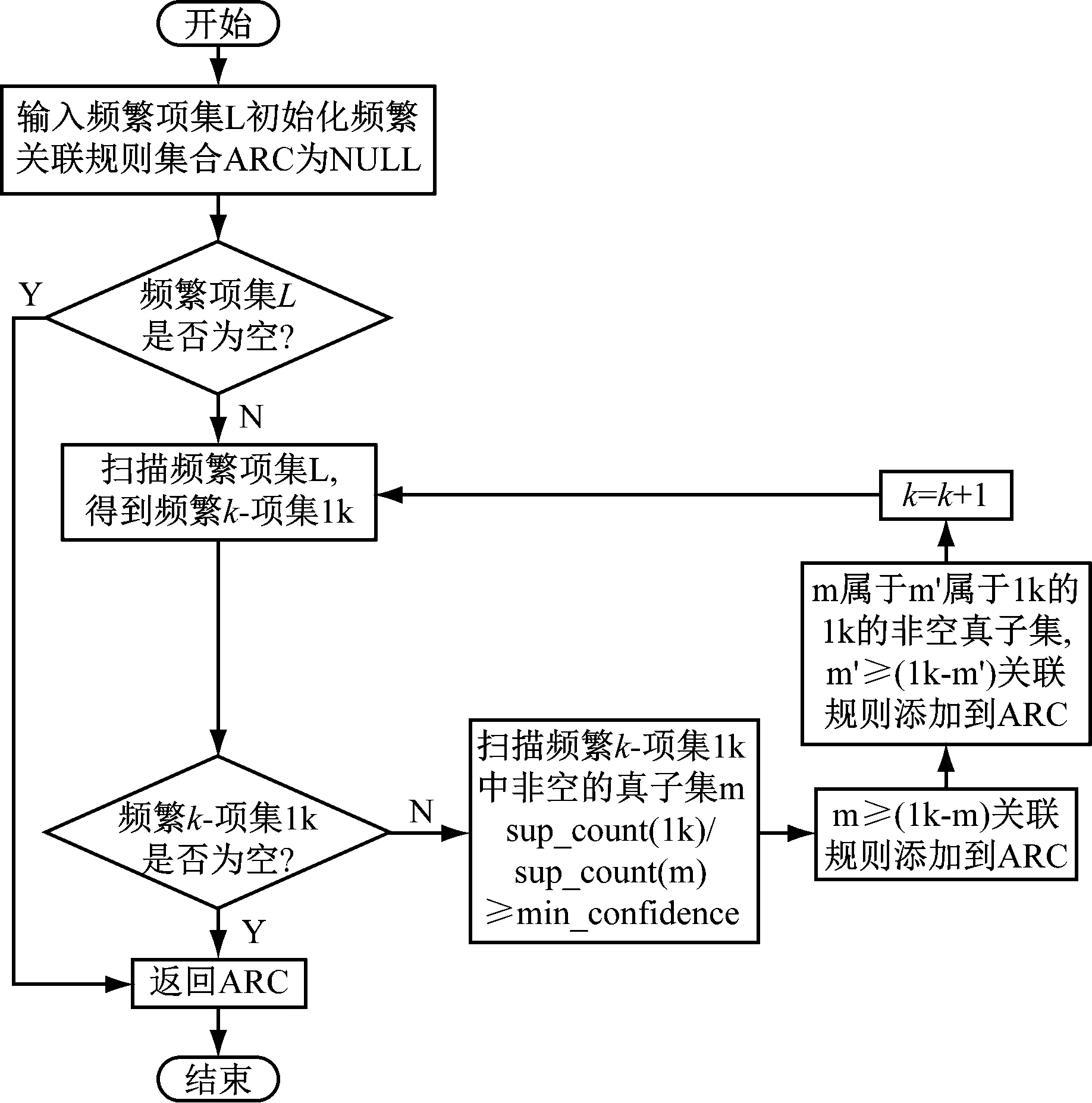
其中,得出频繁项集的具体过程如图2所示。

图2 Apriori算法流程
对图2所示的Apriori算法获得频繁项集的过程进行分析,可以发现其中存在几点问题:
第一,在对频繁项集Lk-1进行连接从而得到选项集Ck的过程中[11],需要通过多次对比来最终判定是否满足生成条件,由此可得其判定的时间复杂度为O((k-1)×n2);
第二,在对候选项集执行剪切操作的过程中,若候选项集Ck中存在一个属于该集的c,而c中某个子集不在频繁项集Lk-1中,此时将剪切c项集。但在此执行过程中,为了判断c中各子集是否全部在频繁项集Lk-1中,需要耗费较多时间来多次对事物数据库进行扫描;
第三,在获得频繁项集Lk的过程中,Lk的生成条件为≥min_suppor,因此需要多次执行步骤1,并将每次的计算结果与min_suppor进行对比[12]。
通过上述问题分析,可以发现Apriori算法所存在的问题可能导致以下两种情况的发生:第一,可能出现多次扫描数据的情况;第二,可能出现生成海量候选项集的情况[13]。这两种情况会造成支持度的计算量过于庞大,从而影响性能。对此,本文采用了结合DC_Apriori算法的方式,在Apriori算法的基础上对其进行改进。
2.2 DC_Apriori算法
DC_Apriori算法的执行过程如下:
步骤1,对原始数据库D进行扫描;
步骤2,对原始数据库D的存储结构进行重组,将事务Tid与数据项Item重组为Item-Tid;
步骤3,对重组后的Item-Tid排序,然后进行存储;
步骤4,扫描数据库,获得候选项集C1;
步骤5,对比各事务列表长度,筛选出满足≥min_support条件的所有项,从而获得频繁项集L1;
步骤6,判断频繁项集是否满足生成候选项集的条件,若满足条件,则进入下一步骤;
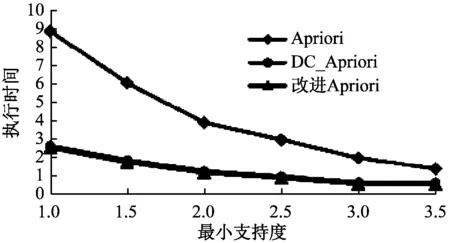
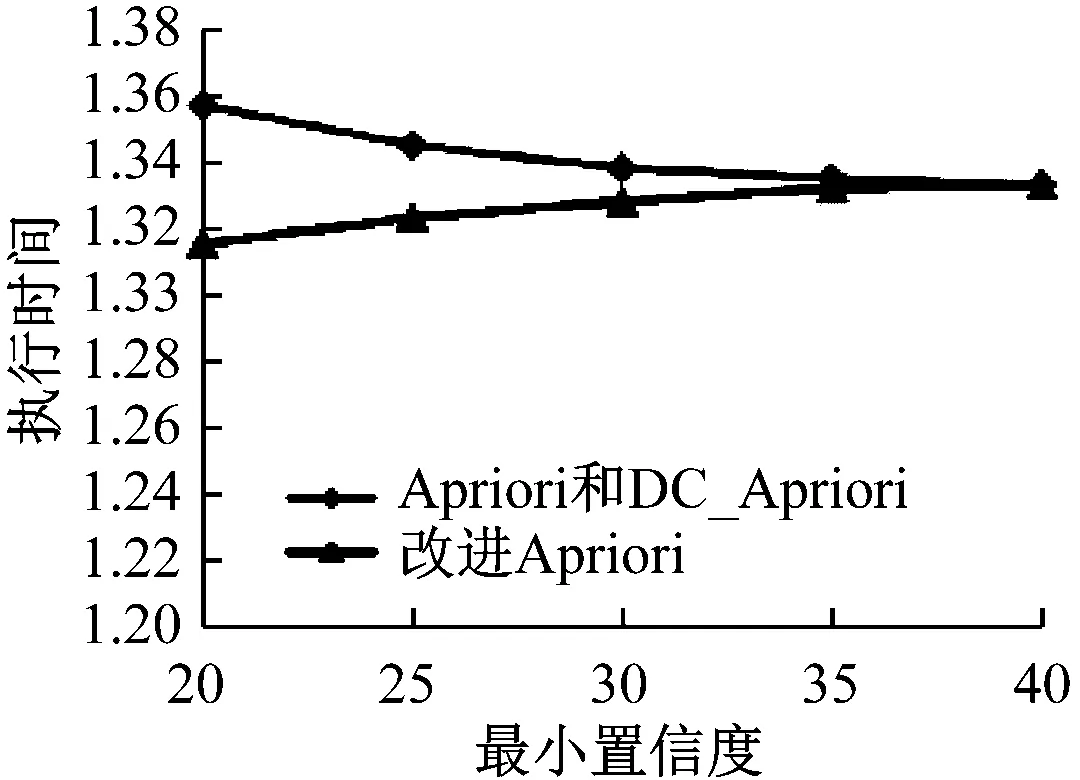
步骤7,比较候选项集的最后一个元素m和l1在频繁项集L1中的索引位置,若m 步骤8,以满足最小支持度为条件对c进行筛选,以此得到频繁项集Lk[14]。 本文结合DC_Apriori算法对Apriori算法进行改进,主要思路为:通过重组事务数据库结构,减少多余的连接及剪切步骤,以此降低频繁项集的计算量。改进Apriori算法的流程如下: 步骤1,对原始数据库D进行重组,以最小支持度为条件进行筛选,以此获得频繁项集L1; 步骤2,判断频繁项集是否满足生成候选项集的条件,若满足条件,则进入下一步骤; 步骤3,根据频繁项集L1连接得到候选项集C2,执行剪切操作后得到频繁项集L2; 步骤4,重复执行步骤2-步骤4,直至不再生成频繁项集时结束,最终得到L。 改进Apriori算法获得频繁关联规则流程图如图3所示[15]。 为了验证本文所提出的改进Apriori算法是否有效,以Apriori算法、DC-Apriori算法以及改进Apriori算法进行仿真实验,并对结果进行对比分析。实验采用Eclipse进行开发,基于Java语言进行测试程序的编写,具体测试环境为:win7操作系统,4G内存,500G机械硬盘,CUP为酷睿i7[16]。 实验所用的数据样本为某市羽毛球队的相关属性数据,如表1所示。 图3 改进Apriori算法频繁关联规则流程 表1 某市羽毛球队的相关属性数据 表1中,Tid为事务的数量,Item为数据项数量,Avg为各事务平均数据项数量。 在不同最小支持度和最小置信度下,Apriori算法、DC-Apriori算法以及改进Apriori算法的执行时间对比结果如图4、图5所示。 图4 最小支持度下的执行时间对比 图5 最小置信度下的执行时间对比 从图4所示的对比结果可以看到,在事务数量Tid以及数据项数量Item较小时,本文所提出的改进Apriori算法在性能上优于其他算法。 从图5所示的对比结果可以看到,在事务数量Tid以及数据项数量Item较小时,本文所提出的改进Apriori算法在性能上优于其他算法,这种差距随着置信度的增大而逐渐缩小,最终趋同。 本文针对数据挖掘技术在运动员多属性训练中的应用展开研究,主要对Apriori算法所存在的问题进行了探讨,提出了结合DC_Apriori算法的算法改进方法,以期提高Apriori算法的性能[17]。通过仿真实验,以Apriori算法、DC-Apriori算法以及改进Apriori算法等三种算法的实验对比结果,证明了本文所提出的改进Apriori算法在性能上具有优越性。2.3 改进Apriori算法
3 仿真实验分析

4 总结
