海量文档桌面全文检索终端设计与实现
2018-12-22张俊飞
张俊飞
(广州医科大学,广州511436)
0 引言
信息技术的发展,推动了高校信息化教学和无纸化办公,出现了越来越多的非结构化数字文档。如何快速对非结构化的海量文档进行检索成为当前研究的热点。传统的方法是对每一个文档进行遍历,然而对于海量文档来说,这是一件很耗费时间和精力的事情。全文检索是一种高效的信息检索技术,可以快速地从海量文档中查询内容,提高检索效率。
Lucene是一套用于全文检索的开源程序库,是Apache软件基金会Jakarta项目组的一个子项目[1]。Lucene不仅可以被用来构建具体的全文检索应用,还可以嵌入到各种系统软件中。近几年,Lucene已在各个领域中的应用得到了研究,如音视频资源检索[2]、学科领域的应用[3-4]、行业应用[5-6]。文献[7]通过对倒排索引的研究,实现了基于正向减字最大匹配分词方式的中文索引,提高了中文分词效率。文献[8]研究了Lu⁃cene索引查询与关系数据库的差异。文献[9]利用Ha⁃doop和Lucene的结合,实现云存储网络文档共享服务。随着信息技术的发展,Lucene技术及其配套的组件也发生了变化,本文着重于文档解析、中文分词器、查询结果的显示处理等方面进行论述。
1 系统结构设计
全文检索是指计算机对检索的数据源中每一个文档通过文档解析、分词操作,对其进行创建索引库,然后检索索引库,采用倒排索引技术把查找到相关文档反馈给用户的过程。
本研究采用Swing技术对Lucene及其配套组件进行整合,开发基于桌面应用的全文搜索终端。Swing是面向Java应用程序用户界面的开发工具包,采用抽象窗口工具包(AWT),使应用程序具有跨平台性,并且可以使用任何可插拔的外观风格。Swing丰富、灵活的功能和模块化组件使得Swing开发人员更加容易的创建优雅的用户界面。
本研发的桌面全文检索终端包含文档读取模块、索引模块、检索模块等全文检索核心功能。系统结构如图1所示。

图1 系统结构
2 关键技术
2.1 倒排索引
为了实现快速检索,Lucene采用倒排索引的数据结构[10]。倒排索引是根据属性值查找记录数据,每个属性包含该属性归属的记录数据地址。通常认为单词是文档的组成部分,反转认为文档是依附单词存在,这样的索引就称作倒排,由属性值查找记录数据的位置因而称为倒排索引。倒排索引以文档形式存储,形成倒排文档。
全文检索的关键步骤就是建立倒排索引,倒排索引一般表示为一个关键词,并记录它出现的频数、地址等相关信息。好比书本的目录结构,可以直接根据目录提示信息,查看到章节信息摘要、页码等,从而获取章节信息,不必对书进行全部遍历。
Lucene的索引结构可以分为索引(index)、索引段(segment)、索引文档(document)、索引域(field)和索引项(term)五个层次。五个层次之间是具有包含关系的,每个索引由一个或者多个索引段组成,每个段包含一个或者多个索引文档,每个文档又管理一个或者多个索引域,每个域由一个或多个索引项构成,而每个索引项就是一个索引数据。Lucene 5.2.1生成的索引文档类型如表1所示。
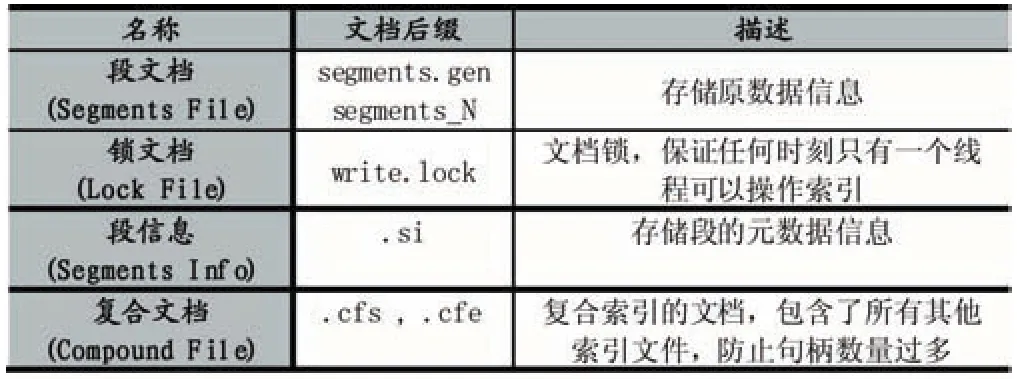
表1 索引文档类型
2.2 分词器技术
本研究终端主要针对中文文档进行全文检索,目前中文分词算法大概分为两大类:①基于词典分词法。扫描字符串,按照正向或逆向最大匹配,最小切分等策略。②非词典分词法。基于统计以及机器学习的分词方式。
第一种分词算法比较常见,在实际应用中,通常是多种算法整合使用,同时加入多个属性值如词频、词性等以辅助分词处理,达到理想的输出效果。这种算法形成的分词器分词速度快,时间复杂度较低,实现简单。第二种分词器目前常见的是HMM、CRF等,主要运用了机器学习、概率统计等领域的方法。这种分词器需要提前对文件进行建模,根据标注好的语料库对模型参数进行训练,通过对模型分词概率的计算,将概率最大的分词结果作为输出结果。这种分词方法对未知词语的分词处理较好,能够根据训练出的领域模型提高分词精度,但是需要大量的前期准备,实现比较复杂。
Lucene是开源高性能的Java全文检索引擎架构,提供了完整的查询引擎、索引引擎和部分文本分析引擎。Lucene内部自带了一些分词器,如:StandardAna⁃lyzer、SimpleAnalyzer、WhitespaceAnalyzer、StopAnalyz⁃er、SmartChineseAnalyzer等分词器。但是在本研究中主要是针对中文分词,Lucene内部这些分词器不能满足要求。故本研究采用MMSeg4j分词器,它是基于MMSeg算法实现的中文分词组件。
MMSeg是一种基于词典的分词算法,采取正向最大匹配策略,同时加入多种消除歧义的规则。其算法实现方式分为两种:①SimpleAnalyzer,简单的按照匹配上的最长词条做切分;②ComplexAnalyzer,在正向最大匹配的基础上,添加了相邻词的词长策略,设计了四个去歧义规则指导分词。四个规则分别为:备选词块的长度最大、备选词块的平均词长最大、备选词块的词长变化最小、备选词块中单字的出现词自由度最高。在实际应用中,一般都整合使用ComplexAnalyzer和四个过滤规则。
本文重点比较了Lucene自带的两种中文分词器:SmartChineseAnalyzer、StandardAnalyzer和 MMseg4j分词器的ComplexAnalyzer实现方法。以“计算机软件工程教育技术全文搜索引擎”为例,并在MMseg4j词库中添加了“计算机软件工程”和“教育技术”两个词条,测试结果如表2所示。
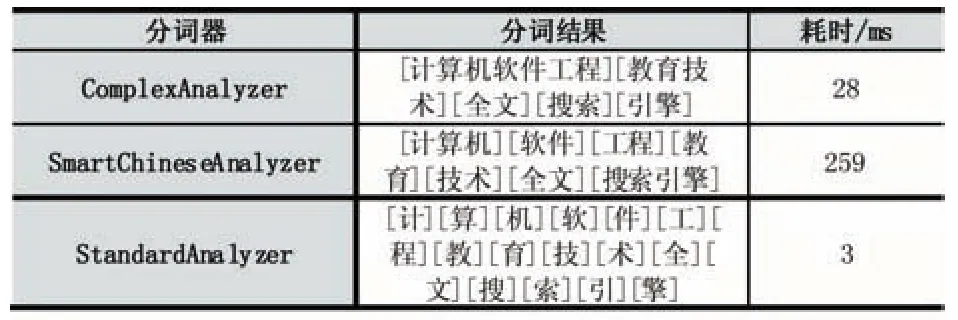
表2 分词器对比分析结果
从表2中可以看出,StandardAnalyzer分词器实现了对中文单字的分词,不能满足用户基于词的分词效果;SmartChineseAnalyzer实现了基于词的分词,但是不能够得到用户指定的词条,且耗时较长。MMseg4j分词器的ComplexAnalyzer能够提供用户自定义分词词条,且耗时较少。
2.3 基于组件的文档解析
在创建索引时,一个最重要的步骤就是从文档中提取文本。然而海量文档格式繁多,如Outlook、MS Of⁃fice、PDF、RTF等,对不是同一编码格式的文档内容提取处理将不是一件简单的事情。
Apache Tika是一种简单易用的程序框架,针对不同的文档类型使用相同的API。Tika本身并不完成任何文档的过滤提取,而是通过外部独立的解析程序完成对文档的解析。除了文本文档之外,Tika还可以提取元数据[11]。Tika使用内部解析类库实现对文档的解析,对应的文档格式和Tika类如表3所示。

表3 Tika解析文档格式
2.4 查询结果数据的显示模块
Lucene提供两种高亮方式:FastVectorHighlighter和Hightlighter。FastVectorHighlighter是基于项向量实现的,通过对每个域中的Term的位置信息进行标注,实现检索的方便快速定位,但是这就意味着需要额外存储空间和磁盘I/O操作,索引体积会变大,占用更大内存。故采用Hightlighter牺牲高亮标注时间,增加系统松耦合性。
使用Lucene自带的Highlighter就可以实现对原始文档摘要的提取工作。通过对Highlighter类中get⁃BestFragment方法的重载,实现从指定的原始文档中,提取检索关键字出现频率最高的一段文字作为摘要,默认情况下提取100个字符,同时加上自定义的高亮显示代码实现关键字高亮显示。
3 终端实现
终端实现了对本地海量文档的全文检索。通过Swing中的JFileChooser组件实现海量本地文档数据源的定位。通过对MMseg4j分词器的词库文档的编辑实现用户对需要查询词条的添加。索引模块采用Tika框架实现对文档的解析,MMseg4j分词器的MMseg算法实现对字符串流的分词,使用Lucene封装的Index⁃Writer方法创建索引。
SwingX是一个包含Swing GUI工具包的扩展控件,为富客户端应用提供丰富的组件。采用其中的JX⁃BusyLabel组件实现程序加载中的友好提示,如图2所示。

图2 SwingX组件

图3 检索方式
本研究实现的全文检索方式有六种:通过项搜索、组合搜索、短语搜索、通配符搜索、模糊搜索、匹配所有文档搜索。
通过项搜索是对索引中特定项进行搜索的最基本方式。Term是最小的索引片段,每个Term包含一个域名和一个文本值。

组合搜索通过使用逻辑AND、OR和NOT把各种查询类型组合成复杂的查询方式。在本系统中,组合查询整合了两个通过项查询,如下代码所示。

短语搜索根据位置信息查询到某个距离范围内的项所对应的文档。

通配符查询通过使用“*”和“?”进行查询。*代表0个或者多个字符;?代表0个或者多个字符。

模糊查询用于查询与指定项相似的项的一种查询方式,通过Levenshtein距离算法来决定索引文档中的项与指定目标项的相似度。编辑距离越小的项所获得的评分越高,编辑距离公式如公式(1)。


匹配所有文档搜索,顾名思义就是匹配索引中所有文档。文档查询加权默认值是1.0,加权值起到排序作用。

通过项搜索界面如图4所示,其他检索界面布局一致。在检索界面中,查询按钮实现了对输入项的全文查找。详情按钮采用 DJNativeSwing.jar、DJNa⁃tiveSwing-SWT.jar和org.eclipse.swt.win32.win32.x86_64-4.2.jar三个jar包,实现在终端中嵌入一个浏览器,把查询结果以网页形式高亮显示反馈给用户,如图5所示。导出按钮实现把查询到的信息文档复制到指定的文档夹中,便于用户集中阅读。

图4 通过项搜索图

图5 检索结果
Luke是一个针对Lucene搜索引擎,方便开发和诊断的第三方工具,它可以访问Lucene创建的索引,并允许显示和修改。本研究使用lukeall-5.2.1.jar实现对创建索引的查看,如图6所示。


图6 Luke应用界面
最后,Eclipse把开发好Swing程序,发布成终端jar文件,然后采用exe4j工具把终端jar文件和终端运行依赖环境文件夹jre7一起打包成可独立执行的exe文档。
4 实验操作
实验过程,采用普通PC,配置参数为:Intel Core i3-3240 CPU x64处理器,频率为3.4GHz,内存4GB,64位操作系统。选取 MS Office、CAJ、TXT、网页、PDF 等不同格式文档组成四个不同大小的数据源文件夹,总大小分为40.9M、385M、770M、1.1G。终端可以直接拷贝到PC上,运行exe主程序,对选取的数据源进行索引创建和检索操作。
从实验结果表4、图8可以看出,数据源大小对文档索引和检索速率产生了影响,当数据源大小达到某个数值的时候,速率会下降,在本实验中,数据源大小在385M处索引速率和检索速率发生下降;当数据源总大小超过某个数值的时候,索引速率和检索速率变化幅度变小。终端在实际的使用过程中,基本可以实现用户本地海量文档的快速检索,其具备较高应用价值。

图7 终端应用图

表4 实验对比分析结果

图8 实验对比分析图
5 结语
本文针对海量本地文档检索问题,设计和研发了一款全文检索桌面终端软件。该终端具有友好的用户体验,可以针对不同格式文档进行解析,实现基于词典的分词操作,采用Swing配套组件实现查询结果以网页形式显示在桌面终端程序中,并对结果数据进行了高亮处理。后期的实验数据验证了终端的可使用性,其具有一定的应用价值。
