基于K-means聚类的调查问卷动态赋权统计方法
2018-12-21李晓英周大涛
李晓英,周大涛
(湖北工业大学 工业设计学院,武汉 430068)
0 引言
随着调查研究理论的深化,各种调查方法、技术和工具等也获得不断发展[1]。而调查问卷作为获取统计资料的重要手段,既可以收集性别、年龄等简单的人口统计信息,也可以获得体验、行为、情感等复杂信息,并且通过科学抽样,就可以从少量样本数据的研究得到一般性推论,其在企事业单位、大众媒体和学术研究等部门得到了广泛应用。因此,针对调查问卷进行的方法理论研究具有重要的实用价值。
文献研究发现:现阶段的研究成果多是关注于问卷的内容设计[2]、样本选择、实施过程[3]及问卷的效度、信度检验方法[4]等方面,对调查问卷结果的统计方法研究却很少提及;现行的结果统计多采用平均赋权算法,由于未能充分考虑主体人(调查对象)对客体物(调查目标、内容)在不同层次或角度上的认知差异水平,稍有偏差就会导致结果出现不可靠性、误导性等问题。针对这个问题,提出基于K-means聚类的调查问卷动态赋权统计方法,结合某高校图书馆服务质量满意度调查的实证研究,验证其可行性、有效性及优越性。
1 问题的提出
由于客观事物的复杂性、不确定性,在调查问卷中往往需要对个体或事物的属性特征做综合、全面的调查分析。例如,产品市场需求调查中,就会涉及到产品的功能、结构、造型、材料以及经济价值、社会环境影响等多方面的因素调查,这就要求主体人对产品的各个因素有清晰、全面的认识。但由于主体人的经验、专业、文化背景及需求、偏好的不同,缺乏对事物属性特征的全面了解,这在一定程度上导致同一主体对同一客体不同方面的认知程度上趋于不一致而非一致,即被调查者对待不同问题评分结果的可信度或权重是不同的。这一点往往会被调查问卷的设计者所忽略,仅采用传统的平均赋权方法对调查问卷的样本数据进行统计分析,使由调查问卷样本数据获得的理论值和由表征客体属性特征的真实值之间出现一定程度的误差,导致研究结果缺乏可靠性。
2 动态赋权方法的构建
针对上述问题,为了保证调查问卷统计结果的可靠性,在综合考虑主体人对客体物认知差异程度的基础上,提出基于K-means聚类算法的调查问卷动态赋权统计方法,具体的应用流程如图1所示。

图1 基于K-means聚类的调查问卷动态统计方法流程图
首先,为便于客观、真实地表征主体人对客体物在不同层次上的认知差异,需预先编制调查问卷层次量表,即围绕调查问卷评估的总体目标要求,将个体或事物的属性特征分解为若干不同的方面。如表1所示,调查问卷层次量表的总体目标(Z)由一级层次(A)和二级层次(B)的属性特征组成,下一次层次的属性特征是对上一层次属性的不同角度或层面的描述。
其次,采用K-means聚类算法演绎出不同层次下样本数据的归类分布情况:
定义1:设有n个样本的p维调查样本数据为:

每个样本可以看作p维空间的一个点,则任意两个空间点xi和xj之间的Euclid距离为d(xi,xj):

表1 图书馆服务质量满意度调查问卷层次量表

其中,当P=2或3时,d(xi,xj)为二维或三维空间中的两点之间的距离。
定义2:设n个样本需要分成k类,则第k个初始聚类点的集合为:

由公式(1)可记:
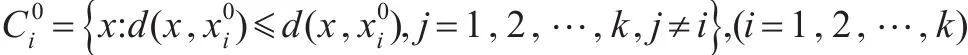
将n个样本聚成了k类,得到了一个初始分类集合C0:
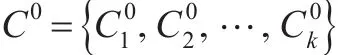
从初始聚类C0开始计算新的聚类点集合为H1,计算:

其中,ni为类C0集合中的样本数量,得到一个新的集合:

从H1开始再进行分类,并迭代上述步骤m次,得:

其中Cm=Cm+1时,则迭代计算结束,获得最终聚类集合Cm。
定义3:由上述K-means聚类算法将n个样本聚成了k类,进一步假设第i个样本属于第t类Ct(显然1≤t≤k),类别Ct中包含的样本个数Ft(Ft可称为类容量)与样本总数n的比值,称为样本i的置信因子Ti,则:

显然,同一类别中的样本具有相同的置信因子,也即同一类中样本所表达的信息可以认为是相似的。其中,Ft较大的类中样本所表达的信息符合多数调查对象的意见,应该被赋予较大的权重,由此有以下权重系数βk的确定原则:

其中:

求解方程组(2)有:

由于属于同一类别的样本具有相同的置信因子,所以:

由式(3)和式(4)得,样本权重系数βk:

最后,通过动态赋权计算某个层次的得分汇总,实现对客体物特定特征的评估,进一步地通过各个层次的得分再加,获得最终的综合评估结果。
3 实证分析
图书馆作为社会的服务性行业之一,与其他服务行业评估在理论、方法模式方面具有通用性。因此,本文以某高校图书馆服务质量的满意度调查为实践案例,进一步阐述和验证该方法的可行性、有效性。
3.1 图书馆调查问卷的层次量表编制
现有的图书馆服务质量满意度调查量表有多种形式,结合某高校的实际情况,在参考美国研究图书馆协会(ARL)的LibQUAL+TM体系的基础上。依据上述层次量表编制要求,绘制了如表1所示的调查问卷层次量表,以开展图书馆服务质量满意度调查工作。
依据心理学中的情感梯度理论[5]确定该层次量表的打分准则,分为7个等级:很不满意、不满意、不太满意、一般、比较满意、满意、很满意,分别对应1分、2分、3分、4分、5分、6分、7分。
3.2 图书馆调查问卷的效度与信度检验
在本次调查中,共发放问卷250份,回收225份,其中有效问卷212份,有效率为94.2%。限于篇幅本文仅给出有形性层次下的部分评分数据,如表2所示。
采用内部一致性系数(Cronbach α系数)检验问卷信度,采用KMO检验和Bartlet球形检验进行因子分析的适用性检验[6],以确定问卷的结构效度,具体检验结果如表3所示。

表2 图书馆服务质量满意度调查结果评分表(部分)

表3 图书馆服务质量满意度调查问卷效度、信度检验结果
由表3可知:Cronbach α系数在0.8以上,说明问卷调查结果具有较高的一致性和稳定性,信度较高;除了关怀性的KMO值(0.587)尚可外,其余层次的KMO值都在0.6以上,效度较高;Bartlet球形检验中的显著性水平p<0.05,表明变量之间具有明显的结构性和相关性,效度较高。
3.3 图书馆调查问卷的动态赋权统计
为了便于计算、描述和说明该方法的可行性、有效性,需进行两个方面的假设:一是认为调查对象对二级层次下的属性特征无认知差异,仅对一级层次下属性特征的认知差异进行考虑;二是采用由样本数据的方差和均值所组成的二维数据演绎归类分布情况。结合定义3中K-means聚类算法的步骤,在Matlab软件中演绎出一级层次下样本数据的归类分布情况。限于篇幅,本文仅说明有形性层次下的归类情况,结果如图2所示。

图2 有形性层次下的样本归类分布情况
由图2可知,212个样本被清晰、明确地聚成了7个类别,证明了K-means聚类算法的可行性。进一步地可以确定各个类别的类容量Ft的大小,有:
Ft={13,19,42,46,11,49,32}
由式(5)可以计算各调查对象的权重系数βk,有:

其中,为有形性层次下各样本类的权重系数。进一步的重复此步骤可以获得其他层次下的样本类权重系数:

为了进一步说明动态赋权统计的概念,进行随机抽样获得4个样本(20号、56号、135号、205号)在不同层次下的权重系数分布情况,结果如图3所示:与平均赋权的水平直线相比,4个样本的权重系数则是动态变化的曲线,会随着各层次属性特征的改变而变化,能够真实地表征主体人对客体物不同方面的认知差异,证明了该方法的有效性。
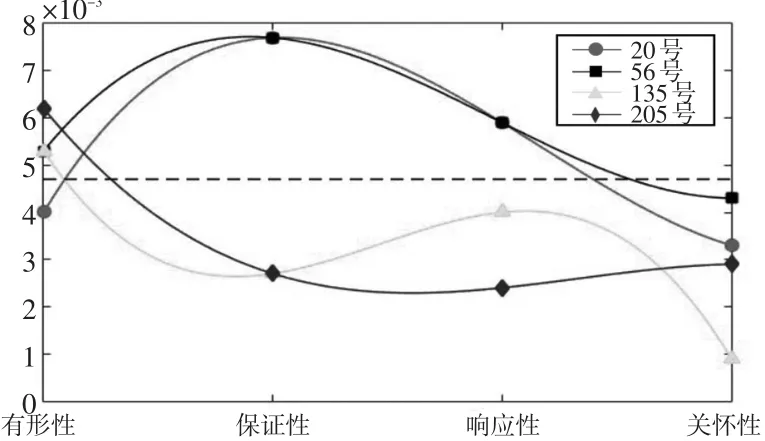
图3 动态赋权与平均赋权的权重系数对比图
3.4 图书馆调查问卷的赋权方法对比
为了进一步证明该方法的有效性、可靠性及优越性,进行平均赋权方法与动态赋权方法下获得的调查问卷综合评分结果的对比分析,具体结果如图4所示。

图4 动态赋权与平均赋权的综合评分结果对比图
由图4可知,两种赋权方法下获得的评分结果存在明显差异:一方面,在某些属性特征上,动态赋权获得的满意度评分较高于平均赋权,尤其在有形性层次下的差异表现最为显著;另一方面,两种方法获得的综合排序结果差异较大。通过数据对比分析发现,导致这种差异的原因是两种赋权方法在调查对象权重大小的确定上存在明显区别,例如,在针对B13(电子资源丰富,数据库全面)的评分数据上,平均赋权对评分较低(3分以下)的31号、43号、104号等14个样本数据赋予了较大的权重(0.0047),而动态赋权对其赋予较小权重(0.0014)。通过回访调查发现,这14位被调查者使用图书馆电子资源的情况不多,甚至从未使用过图书馆电子资源,其评分结果明显不可信。但平均赋权方法下却对其赋予了较高权重,显然该赋权方法下的评分结果缺乏可靠性。相比之下,动态赋权方法获得的评分结果更符合实际情况。
使用同样的方法对其他差异点进行回访调查,结果表明:平均赋权方法未能够识别出调查对象的实际认知情况,导致综合评分结果出现偏差;基于K-means聚类的动态赋权统计方法能够综合考虑主体人的认知水平差异,并减小其对综合评分结果造成的影响,增强了调查问卷结果的可靠性,减少误导。对比结果表明调查问卷的动态赋权统计方法在有效性、可靠性等方面较平均赋权方法具有优越性。
4 结论
针对主体人对客体物的认知差异导致调查问卷综合统计结果出现偏差的问题,提出基于K-means聚类算法的调查问卷动态赋权统计方法。通过图书馆服务质量满意度调查的实证研究,对比不同赋权方法下的评分结果,验证了该方法的可行性、有效性。但K-means聚类算法需要预先指定类别数目,且多数情况下样本数据的类别数目及最优类别数目是无法预知的。因此,下一步的工作重点将围绕样本数据最优类别数目的确定方法而展开,以进一步保证调查结果的可靠性。
