Hadoop集群中给定候选任务集的最大利润问题
2018-12-20胡积宝
郑 羽,胡积宝
(1.安庆师范大学 现代教育技术中心,安徽 安庆 2460112.安庆师范大学 物理与电气工程学院,安徽 安庆 246133)
0 引 言
随着计算机网络和传感器网络的迅速发展,数据呈指数级增长,特别是在因特网上。为了有效地处理大规模数据,需要具有良好的可伸缩性、灵活性和容错性的并行分布式集群。由Google提出的MapReduce[1]架构,应用分而治之的方法来处理数据密集型任务,是大数据领域一个既成事实的标准。Google使用了一个运行MapReduce和相关技术的大型集群,诸如GFS[2]和Bigtable[3],每周处理PB级数据以上。在这种服务过程中,企业与客户之间的服务细节通常是通过服务水平协议来(SLA)[4-5]描述的。SLA分两种,根据数量定价和根据有效性定价。根据数量定价的SLA向客户收取与硬件规模和服务时间成比例的费用。根据有效性定价的SLA依据服务效能向客户收费。以垃圾邮件检测服务为例,该服务必须在一定时间内完成,因此,只有服务在规定时间内完成,才会支付款项。文中研究了如何安排客户的任务以使得Hadoop集群的总利润最大化。在研究中,主要关注的是定时MapReduce任务,它是以时间的有效性为代价的,即任务必须在给定的时间内完成。在这里将每个任务抽象为四个部分,即用户定义的Map/Reduce函数、完成时间、利润和惩罚,并试图找到一种最大化Hadoop集群总利润的调度算法。
1 相关知识
1.1 MapReduce环境
MapReduce是一种流行的面向数据密集型任务的编程模型,在许多领域得到了广泛应用[6-8]。Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的优势进行高速运算和存储。Hadoop实现了一个分布式文件系统(Hadoop distributed file system,HDFS)。HDFS有高容错性的特点,并且可以部署在低廉的(low-cost)硬件上;而且它提供高吞吐量来访问应用程序的数据,适合那些有着超大数据集的应用程序。
图1为MapReduce框架,在用户定义的map函数中,输入是一个键值对,输出是零或多个键值对。在组步骤中,具有相同密钥的系统组键值对会被发送到相同的还原节点。在自定义的Reduce函数中,组合键值对处理产生的结果。MapReduce任务通常需要多次Map/Reduce迭代。
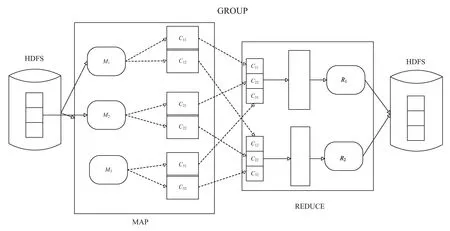
图1 MapReduce框架
1.2 相关工作
在MapReduce,有一些通用的任务调度程序,如FIFO调度器、基于容量的调度器和基于公平的调度器。在具体应用中,Sandholm和Lai等提出了一种调度算法,允许用户根据MapReduce任务的重要性动态调整需要的计算资源。Zaharia等提出了一种异构集群环境下的调度算法。Kwon等提出了skewtune算法处理MapReduce任务的过程偏度。此外,还有一些调度算法,涉及到在给定时间内完成的MapReduce任务[9-15]。
1.3 存在的问题
文中研究的目的是最大限度地提高同类的Hadoop集群的总利润,其中所有节点的计算能力是相同的。在一个Hadoop集群中,有M个Map任务,M个Reduce任务,对于每个提交的任务j,假设以下参数:
j.Nm:j中的Map作业数。
j.Nr,j中的Reduce作业数;为了获得高效率,j.Nm和j.Nr是M的整数倍。
j.deadline,j所规定的时间或期限。
j.profit,j在截止时间前完成所获得的利润。
这里必须注意,如果j没有在截止时间之前完成,那么j的惩罚是j.profit.α。当许多客户同时向Hadoop集群提交任务时,这些任务形成一个候选任务集J={j1,j2,…,j|J|}。Hadoop集群需要从J中选择一个可接受的任务集J={j1,j2,…,j|J|},通过适当的算法调度选定的任务以完成它们。对每一个任务ji∈A,如果ji比jideadline完成得早,则ji是有效的,利润是ji.profit;反之,如果ji没有在jideadline前完成,那么ji不是有效的,惩罚是j.profit.α,也就是说,利润是-j.profit.α。因此,Hadoop集群的总利润是:
(1)
其中,E()表示给定的任务是否有效。
1.4 调度算法
在这一部分中,首先提出了一种基于序列的任务调度策略,然后提出了一种基于该策略的调度算法,最后给出了一种处理超时的方法。
1.4.1 基于序列的调度策略
对每一个任务j∈J,可以估计Map任务j.Tm的处理时间和Reduce任务j.Tr的处理时间。如果所有任务槽都用于处理任务j,完成所有Map任务的时间是TCm(j)=「j.Nm/M⎤×j.Tm,完成所有Reduce任务的时间是TCr(j)=「j.Nr/M⎤×j.Tr。
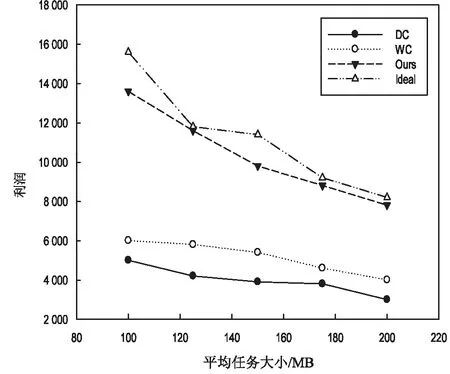
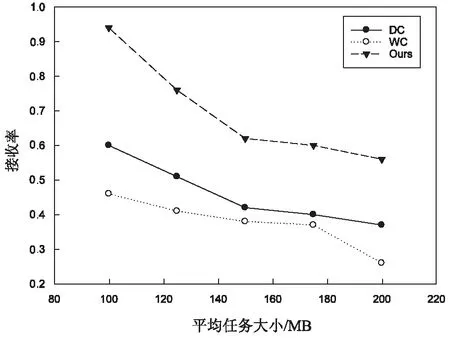
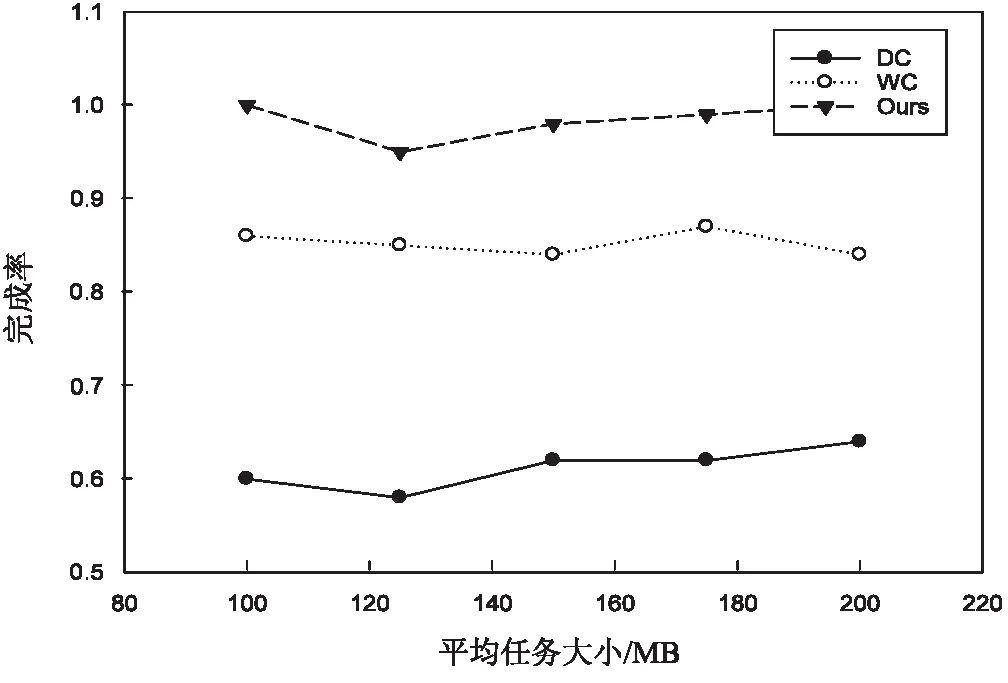
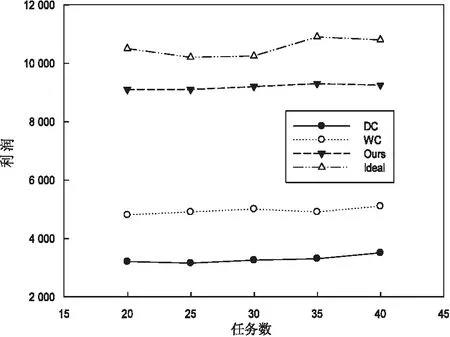
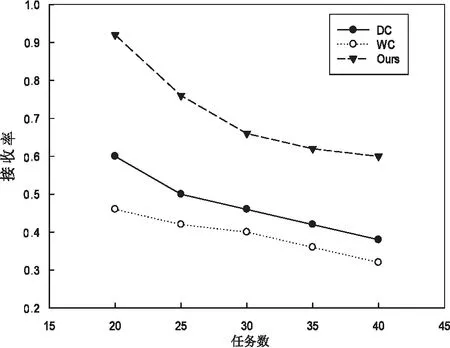
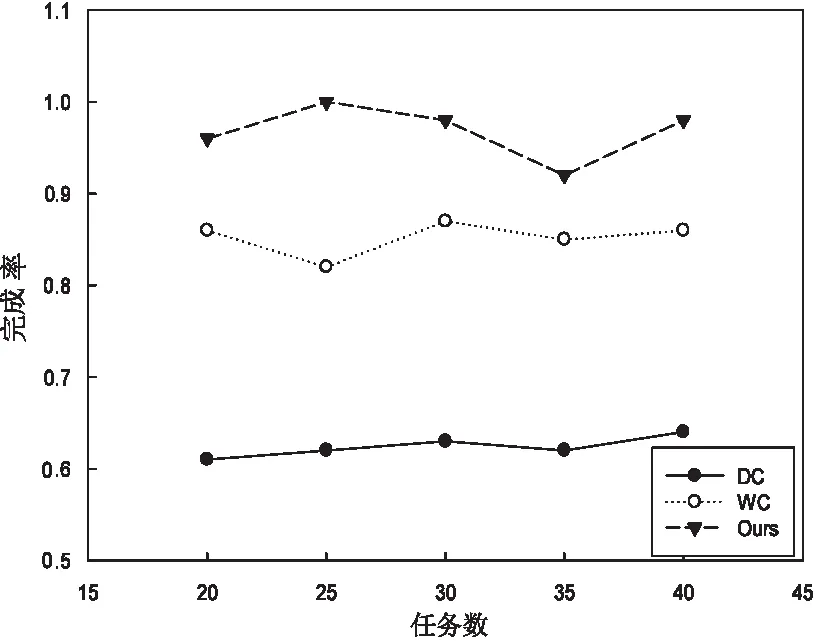
定义1:序列对于任务集JS(任务数是|JS|),序列S是|JS|中所有任务的排列,并根据完成时间指定作业的顺序。如果在Map步骤中完成j的时间是COTm(j),那对于给定的序列S={j1,j2,…,j|JS|},COTm(j) 基于给定的序列S,提出了如下的调度策略: (1)Map当空闲任务槽需要一个Map作业时,按顺序选择第一个任务的映射作业。当分配S中第一个任务的所有Map作业时,从S中删除第一个任务。 根据以上的调度策略,对于一个给定序列,可以计算出Map步骤的完成时间COTm(j)和Reduce步骤的完成时间COTr(j)。COTm(j)和COTr(j)的计算如下: 基于上述调度策略和完工时间的计算,给出了有效序列的定义。 定义2:对任意序列S给定任务集JS,基于上述调度策略,有COTr(j)≤j.deadline,则S是一个有效的序列。 定理1:对于任务集JS和序列S,拟议的调度策略可以确保,对∀ji∈JS,在S的约束下,ji可以用最少的时间完成Map步骤。 定理2:对于任务集JS和序列S,如果使用建议的调度策略时发生任务超时,则使用任何调度策略,不可能按时完成JS中的所有任务,因此,S必须不是有效的序列。 证明:从定理1知道,提出的调度策略在Map步骤中是最优的。这里,只考虑Reduce步骤。假设j是基于调度策略的超时任务,可以分为两种情况: (1)COTm(j)+TCr(j)>j,如果j的Reduce步骤在它的Map作业完成时立即运行,但仍不能按时完成,那么无论采用什么调度策略,j都不能按时完成。 在上述两种情况下,都不可能按时完成JS中的所有任务,因此S必须不是有效的序列。基于定理1和定理2,可以得出结论,所提出的调度策略对于固定序列S是最优的。这意味着如果在提议的策略下存在超时任务,那么它们必须存在于任何其他调度策略中。 1.4.2 调度算法 在提出的基于序列的调度策略的基础上,文中提出了一种调度算法。首先,当候选任务设置是静态的,使用的评分策略为所有任务指定优先级,将找到可接受的任务并为其设定一个有效的修剪策略,并发现一个有效的序列。其次,当候选的任务集实现了动态更新,会执行增量法判断可接受的任务集和更新有效序列是否必要。 为了提高判断可接受集的效率,首先对j中的所有任务进行排序,然后确定每个任务的优先级。根据MapReduce任务的特点,主要考虑以下两个方面: (2)在MapReduce中,如果某个任务j的运行时间太长,那么当运行j的Map/Reduce任务时,大多数任务槽将是空闲的。这样会浪费大量资源,影响其他任务的接受。 在此基础上,提出了一种以总利润最大化为目标的评分函数。对任务J而言,得分是: (2) 其中,Ad(j)为J的调整系数,STC(j).Ad(j)为J的调整时间。从式2可以看出,得分高的任务将获得更高的优先级。 现在,分析了如何提高查找有效序列的效率。假设候选集通过式2的计算进行了排序,即穷举搜索法需要(|A|+1)!遍历所有候选序列的复杂性。为了提高搜索速度,给出了以下两种方法。 定理3:给定一个任务集A和它的一个序列J={j1,j2,…,j|J|},对于一个新的任务jnew,有n+1个位置可以插入它,如果TCm(jnew)+COTm(ji)+TCr(ji)>ji.deadline,那么jnew就不能被插入到[1,i]中的位置。 证明:很明显,如果jnew被插入到[1,i]中的任意位置,jnew就会超时。 定理4:给定一个任务集A和它的一个序列S={j1,j2,…,jn},对于一个新任务jnew,如果TCm(jnew)+COTm(ji)+TCr(jnew)>ji.deadline,那么jnew就不能被插入到[i+1,n+1]中的任意位置。 证明:假设jnew被插入到[i+1,n+1]中的任意位置,根据提出的调度策略,得出jnew最早完成时间等于或者大于TCm(jnew)+COTm(ji)+TCr(jnew)。因此,jnew肯定会超时。 基于定理3和定理4,提出了一种快速找到可接受集及其相应有效序列的算法,其细节在算法1中。利用该算法,可以得到候选任务集的最大利润。 算法1: 输入:提交工作集J={j1,j2,…,j|J|} 输出:接收的工作集A及其有效的序列φ 用式2为每个工作计算出得分并排名 将J中的工作按照得分降序排序 假设A←{j1},φ←{{j1}} For每个ji∈Jandi≠1 do 假设φi←{} for 每个S∈φi-1do 判断jj能被插入的最小位置a 通过定理3 Ifa≤bthen For每个p∈[a,b] do 在位置p将jj插入S并得到S' 计算所有工作需要的完成时间 IfS'符合SEQ策略 IfS'是一个有效的序列 then 使φi←φi∪S' Ifφ≠φthen 使A←A∪ji 返回A和φ|J|中的有效序列 在实验中,Hadoop集群包含一个主节点和40个从节点,每个节点包含一个英特尔酷睿i3 3.1 GHz处理器,8 GB的内存和500 GB的存储,运行的操作系统是RedHat Linux 6.1。在从节点中,每个节点配置两个Map任务槽和两个Reduce任务槽。实验中的数据是enwiki(https://dumps.wikimedia.org/enwiki/20150204/),运行了三个经典任务的数据集,即统计词频、倒排索引、分布式grep。数据存储在Hadoop文件系统(HDFS)中,每一块是64 MB,每个数据块有三份拷贝。对于一个候选任务集j,主要考虑以下三个影响性能的参数: (1)平均任务尺寸L,即L中所有任务的平均尺寸(块数); (2)任务数N,即L中任务的数量; (3)平均期限D,即L中所有任务的平均期限(完成时间)。 总利润的计算见式1。此外,定义接收率和完成率如下: (3) (4) 实验中使用的基线算法是DC和WC。首先评估了任务数对总利润的影响,结果如图2所示。在图2(a)中,理想曲线是理想的利润,随着平均任务规模的增加,所有利润值都减少,但此方法接近理想值。在图2(b)中,所画的三个接收率逐渐降低,但此方法具有最高的价值,意味着该方法可以获得最多的候选任务。在图2(c)中,提出的方法比另外两种方法有更高的完成率。 图2 任务数对总利润的影响 由于该方法不仅接收到最多的候选任务,而且完成大部分任务,因此可以带来最大的利润。 同时,观察了任务数和平均截止期对总利润的影响,结果如图3所示。 图3 任务数的影响 由于同样的原因,方法不仅接收到最多的候选任务,而且完成大部分任务,因此可以带来最大的利润。此外,对三种情况的总利润非常接近理想值。 最后,动态地将任务提交给Hadoop集群,观察总利润的变化。从数据可以看出,该方法不仅接收到最多的候选任务,而且完成大部分任务,因此可以带来最大的利润。这说明所提出的方法也适用于动态提交的任务。 研究了Hadoop集群中的最大利润问题。为了使利润最大化,基于候选任务集的有效序列选择了一些高利润率的任务。此外,为了提高查找有效序列的效率,设计了一些修剪策略,并给出了相应的调度算法。实验结果表明,该算法的总收益非常接近理想的最大值,在不同的实验环境下明显优于相关的调度算法。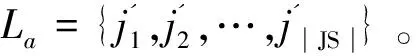



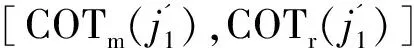
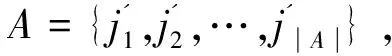
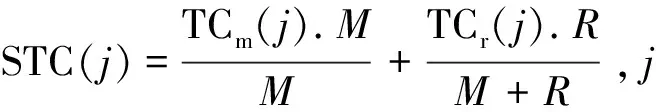
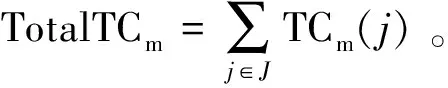
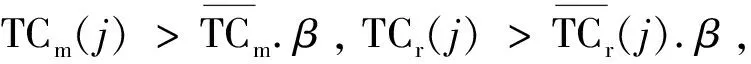
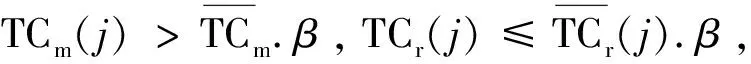
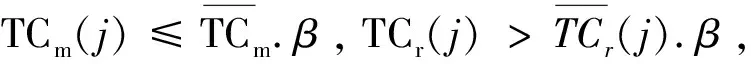
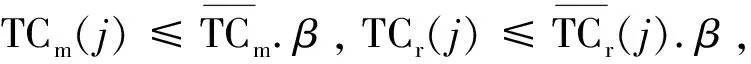
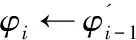
2 实 验
2.1 实验设置


2.2 实验结果
3 结束语
