基于改进蝙蝠算法的软件缺陷预测模型
2018-12-20杨晓琴
杨晓琴
(太原广播电视大学,山西 太原 030002)
0 引 言
软件缺陷预测是一种根据以往开发软件模块特征来预测未来开发软件缺陷性的模型。软件缺陷预测能够预测软件存在的缺陷位置和数量,能够知道测试工作,提升测试工作效率,节约成本。
软件缺陷预测技术涵盖了动态、静态两种。以往的动态缺陷预测技术主要有Rayleigh分布模型、指数分布模型和S曲线分布模型。Rayleigh分布模型应用广泛,Trachtenberg等开展了一系列实验,进而实现对缺陷数据的验证,从结果来看这些缺陷数据符合Rayleigh分布模型。Rescorla等在一系列研究之后,阐述了著名的指数分布模型,其将研究重点放在软件验收的测试阶段,通过深入研究,确定了此阶段软件缺陷累计分布规律[1]。基于S曲线的分布模型能够了解到,从软件开发一直到回归测试,在缺陷累计数量方面是符合S型的,最终意味着来到了软件成熟阶段。Alhazmi等在一系列研究之后,阐述了著名的AML模型,该模式作为S曲线模型中的代表模型,和实验数据的拟合度较高,性能较好[2-3]。Joh等在对软件生命周期中软件缺陷模块占比变动规律进行描述的过程中,主要基于Weibull统计分布来实现[4],该方法能够有效地评估软件风险。
与动态软件缺陷预测技术不同,静态软件缺陷预测技术一般将软件预测问题进行转化,最终变为机器学习中的一种分类问题,具体就是基于缺陷预测模型有效划分待预测模块,分为无缺陷以及有缺陷的模块两类。传统分类技术相对丰富一些,如支持向量机(support vector machine,SVM)[5]、贝叶斯网络(Bayesian network,BN)[6]、决策树(decision tree)[7]、神经网络[8]以及K最近邻分类算法[9]等。
支持向量机的两个关键参数的选择非常重要,会影响到支持向量机进行分类的最终效果。由于基于支持向量机软件缺陷预测模型有着比较低的准确率,笔者为了解决这个问题,基于改进蝙蝠算法来完善支持向量机的软件缺陷预测模型。改进蝙蝠算法能够优化支持向量机的关键参数,能获得更好的分类模型,提高模型的分类准确性。为了验证该预测模型的预测性能,利用NASA的MDP数据集进行测试,并与已有的缺陷预测模型进行比较。
1 相关工作
1.1 软件缺陷预测模型
静态缺陷预测技术可以根据历史数据信息有效预测模块缺陷倾向性,不过专家将负责抽取标记软件模块,同时软件缺陷预测的性能也受度量元设计的影响。虽然动态的软件缺陷预测技术能够掌控软件生命周期中所有缺陷的变动状况,但是特征提取难度比较高,有着比较窄的覆盖面,运行环境对其影响较大,文中主要对静态软件缺陷预测技术进行研究。
模型构建包含三个步骤:
(1)选取软件模块,全方位分析软件代码,对全部的属性值进行统计,有效标记模块所具有的缺陷性,这样就可以获得相对应的训练数据集。在软件模块中,有效挑选n个样本数据集为Dn={(x1,y1),…,(xn,yn)},其中软件模块i的度量属性是向量xi∈Rk,所有向量均包含多维的度量元,并表示为xi=(a1,…,ak)。yi∈Y是第i个模块的类标记。专家将负责抽取标记软件模块数据集。
(2)通过所选择预测方法或技术对数据集进行训练,最终将获得所需的训练样本。对样本的数据集进行学习,能够在软件模块的属性以及缺陷性间实现识别标准的有效构建,将多个模块属性向量进行输入,这样就可以获得特定输出,有助于全方位了解模块所具有的缺陷性,得出软件模块属性和缺陷相关的映射关系。
(3)对软件缺陷预测技术、方法性能进行验证。首先需要取得预测所获得的结果,有效地评估技术或方法所具有的性能。相关指标主要有准确率、误报率、AUC取值和缺陷检出率等。不同的软件或系统对于成本和安全性的要求不同,对于不同指标的要求不一样,但是目的都是尽可能地节约软件的测试成本,检测出尽可能多的软件缺陷。
单目标启发式搜索算法在软件缺陷预测中有着较多的应用,对软件缺陷预测技术进行不断完善,这样软件预测将达到更高的准确率。分析启发式搜索算法可以了解到,其表现为搜索速度快,搜索精度高,能够为NP难的问题搜索到满意解,可以对缺陷预测技术的参数进行选择,搜索出符合要求的参数值。
支持向量机在学习完训练样本之后,能够找出最优分类面和支持向量,并且对训练的数据集的有效类型进行划分,这样分类面尽可能远离于每一类的距离。若数据表现出线性不可分,依托核函数映射到高维的特征空间,这样数据将获得最优的分类面。支持向量机在泛化能力方面表现十分出色,同时可以有效解决非线性分类问题。Elish等横向对比了支持向量机以及其他的分类算法,由实验结果了解到,支持向量机表现出了更好的性能[10]。
启发式搜索算法在一定程度上可以优化支持向量机,尤其是惩罚因子以及径向基带宽等层面,主要是对其取值进行优化。王男帅等[11]使用遗传算法做最佳度量属性的选择,避免有用的信息被过早筛除。姜慧研等[12]针对数据集,基于主成分分析法有效降维处理数据集,这样模型将有更高的运算速度,之后再利用蚁群优化算法对支持向量机的参数进行选择。
1.2 支持向量机
1995年,Cortes和Vapnik第一次阐述了SVM。后者对非线性分类问题能够进行有效的处理。支持向量机的原理是在空间中寻找一个分类面作为两个类的分割,这个分类面距两类样本的距离越大越好,这样可以更好地分开两类样本。支持向量机突出的一点是可以经过核函数映射,在高位空间来处理线性不可分的情况。
支持向量机处理的样本可以表示为(x1,y1),…,(xl,yl),x∈Rn,y∈{+1,-1},其中l为样本数量,n为x的维数。支持向量机通过训练寻找到支持向量进而找到一个离两类间隔最大的分类面,作为两类样本的分界,表示为:
wTx+b=0
(1)
其中,wT表示最优分类面的法向量;φ(x)表示将x映射到高维空间的核函数。
数据集中用于测试的样本去掉类别标签,最后的分类结果与原类别得出的结果进行对分类模型的性能衡量。
当遇到线性不可分的样本集时,可以通过核函数的复杂计算,将这些样本映射到维数更高的特征空间,在新特征空间中进行训练找到分类面。这里使用径向基函数(RBF),公式如下:
(2)
参数σ用于控制RBF的半径。分类函数为:
(3)
其中,ai∈[0,C],C叫做惩罚参数。
支持向量机的两个参数C和σ很大程度上影响了分类性能。然而,传统上是按照经验给定参数值。为了提供适当的参数,提出应用LBA来优化支持向量机,该混合算法称为结合LBA和SVM的混合改进算法(简称LBA-SVM)。
2 LBA-SVM的软件缺陷预测模型
2.1 蝙蝠算法
蝙蝠算法[13-14]是基于模拟蝙蝠捕获猎物行为的启发式群智能优化算法,该算法是在受该物种独特的回声定位行为的模拟启发下提出的。标准蝙蝠算法的结构如下:
fi=fmin+(fmax-fmin)β
(4)
(5)
(6)
其中,β∈[0,1]是一个随机向量,X*是当前全局最佳位置。根据所求解的问题类型,在固定λi(或fi)的同时改变fi(或λi)。在实际求解过程中,可以根据问题的领域大小确定fi的取值,比如使用fmin=0和fmax=100。开始时每只蝙蝠随机分配频率,频率是从[fmin,fmax]平均得出的。局部搜索时,每只蝙蝠的更新公式如下:
Xnew=Xold+εAt
(7)
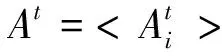
(8)
其中,α和γ是恒量,α类似于模拟退火算法中冷却进程表中的冷却因素。
基于以上分析,蝙蝠搜索算法的主要步骤可以描述如下:
(1)初始化蝙蝠各参数:位置Xi(0),速度Vi(0),响度Ai(0),脉冲发射速率ri(0)以及脉冲频率fi(0);
(2)按照式5和式6更新蝙蝠个体的速度和位置;
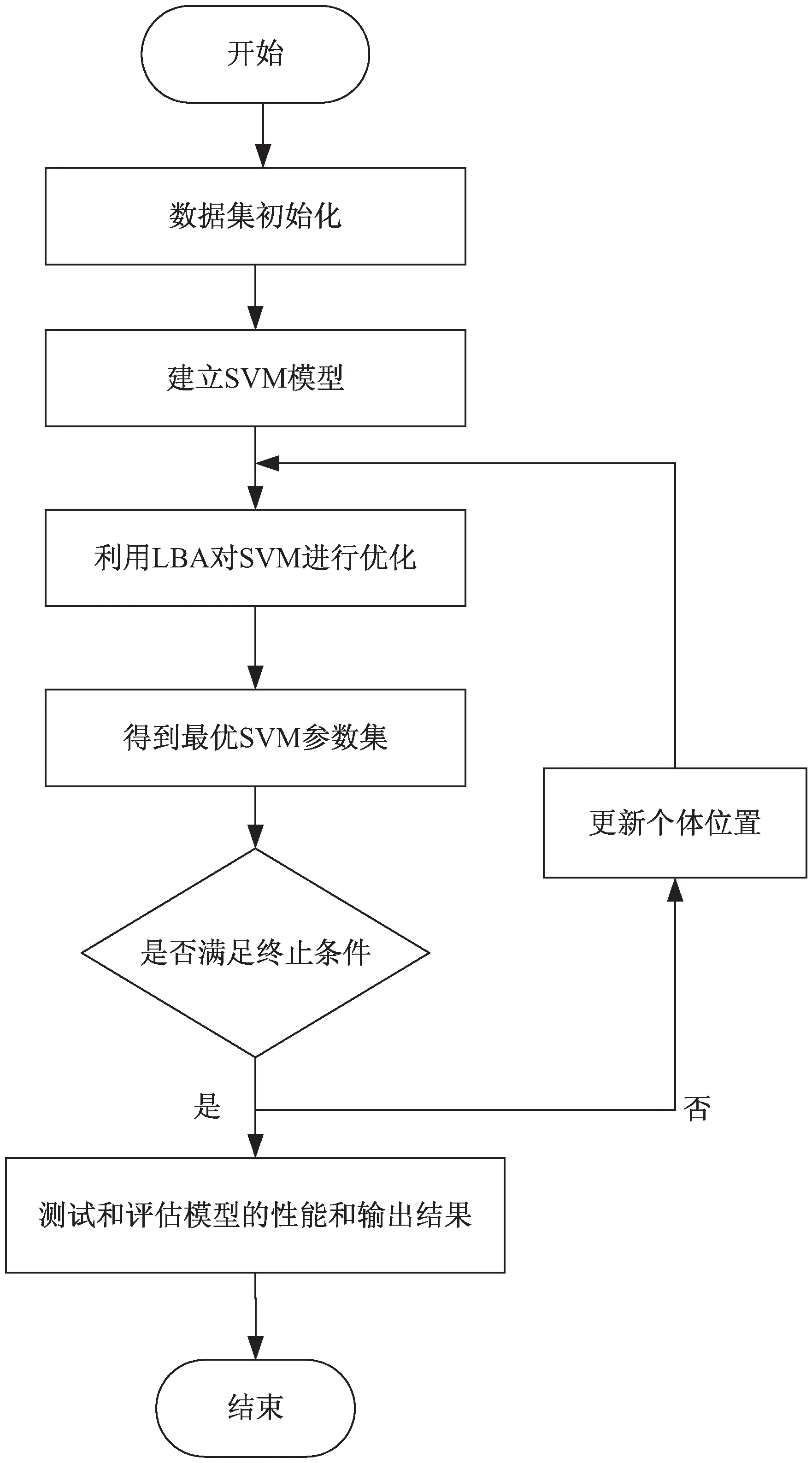
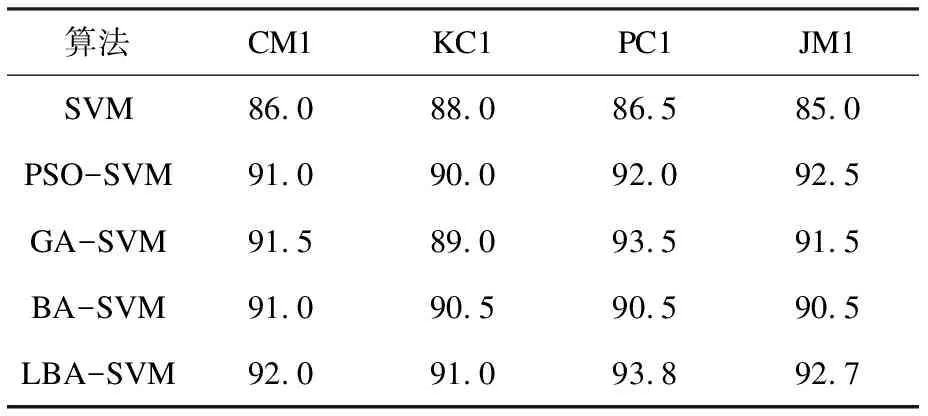
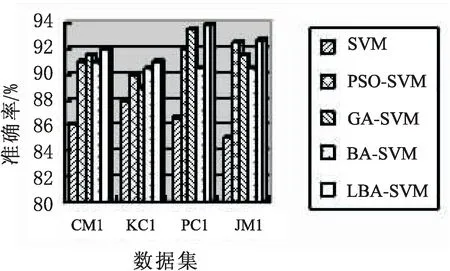
(3)对于每个个体i,产生一个介于(0,1)之间的随机数rand1,如果rand1 (4)随机产生(0,1)之间的随机数rand2,如果rand2 (5)更新群体最优位置p(t); (6)如果满足结束条件则终止算法,否则转入步骤2。 自然界中的动物寻找食物地点的行为具有随机性,包括搜索方向以及步长。动物的一般活动路径也是一个随机的移动过程。后续的行为方向和步长取决于动物当前所处位置(或状态)。Levy飞行可以描述为一个运动的实体,通常会进行小步长的移动,能够偶尔迈出异常大的步子,从而改变一个体系的行为。它的运动方向是随机的,但是其运动步长是按照幂次率分布的。Levy飞行的一个特点是小步的移动占多数,但是也会少数时刻选择大步的移动,这能够保证个体搜索的不重复性。 在标准蝙蝠算法中,所有蝙蝠个体的速度更新公式中受到个体当前最优位置的影响,导致蝙蝠个体比较容易陷入局部最优,而且很难从局部极值点跳出。文中在局部搜索中引入Levy飞行[15-16],利用Levy飞行随机游走的特性,利用随机步长以有偏方式进行随机移动,使得蝙蝠个体在局部搜索中进行随机游走,从局部最优中跳出,获得更好的解。蝙蝠个体局部搜索进行莱维飞行根据代数决定,到了一定代数进行一次,这样既兼顾了原本的局部搜索方案,又不至于陷入局部极值点。根据经验设置每10代在局部搜索中进行一次莱维飞行。 LBA-SVM软件缺陷预测模型利用加入莱维飞行局部搜索策略的蝙蝠算法优化支持向量机,其流程如图1所示。 (1)样本数据集初始化。将数据集带入模型,对样本进行初始化处理。 (2)建立基于SVM的分类模型。将样本数据集带入支持向量机,通过十折交叉法进行训练和测试。 (3)利用LBA算法对SVM进行优化。初始化LBA中的个体位置为随机的SVM参数,将LBA个体位置带入SVM,通过SVM分类模型,测试参数的好坏,当迭代次数未达到最大迭代次数时,进行个体位置更新,不断优化参数选择。 (4)结果输出。在代数达到最大迭代次数时,测试和评估模型的性能。 图1 LBA-SVM软件缺陷预测模型 该数据为NASA提供的MDP数据集中的四个数据集:CM1、KC1、PC1、JM1(http://mdp.ivv.nasa.gov/)。数据集信息如表1所示。 表1 数据集 分类问题的软件缺陷预测根据正确预测和错误预测模块数统计并计算相应比例来对模型进行评价,实际操作中,通常使用混淆矩阵对结果进行分析。实际上为缺陷模块,分类结果一致的称为TP,被误分为非缺陷模块的为FN;实际上非缺陷模块被正确分类的总数为TN,被误分为缺陷模块称为FP,如表2所示。 表2 混淆矩阵 准确度(accuracy)是最常用的指标,可以理解为预测正确的模块数与总软件模块数的比值,如下: (9) 为了验证文中提出的软件缺陷预测算法的性能,对其进行了仿真实验,主要基于MatlabR2013a平台来开展。使用十折交叉验证方法设计仿真实验。每个数据集平均分10份,其中9份做训练,剩余1份对模型性能进行测试,最后取10次预测结果的平均值作为对算法预测能力的评价。 支持向量机两个参数的范围都是(0,1 000)。蝙蝠算法参数设置如表3所示。 表3 实验参数 实验结果如表4和图2所示。 表4 实验结果 图2 实验结果 与传统的SVM模型、PSO-SVM模型、GA-SVM模型、BA-SVM模型进行比较,通过表4和图2可以看到,传统SVM的精度无法到达90%以上,而优化过的算法中,准确率都有所提升。说明通过智能算法优化参数,可以有效地提高传统SVM模型的准确率。通过比较发现,在改进的模型中,提出的LBA-SVM的准确度明显优于其他算法,说明莱维飞行策略能够有效地帮助传统BA算法跳出局部最优。利用改进后的算法优化软件缺陷预测模型使得准确度得到了进一步的提升。 支持向量机作为软件缺陷预测模型的核心,具备很好的分类能力。文中从对支持向量机的两个关键参数进行优化出发,以提高软件缺陷预测模型的准确率为目标,改进了标准蝙蝠算法的局部搜索能力,加入了莱维飞行,保证在隔一定代数后能够有一次局部最优点附近进行随机游走,减少了蝙蝠算法陷入局部极值的可能性。通过四个数据集的实验对比表明,LBA-SVM显著提高了准确度。2.2 基于Levy飞行的蝙蝠算法
3 仿真实验
3.1 数据集及评价标准


3.2 实验参数

3.3 实验结果
4 结束语
