基于负载感知和QoS的多中心作业调度算法
2018-12-20冯鸣夏伍卫国邸德海
冯鸣夏,伍卫国,邸德海
(1.西安交通大学 电子与信息工程学院,陕西 西安 710049;2.西安交通大学 管理学院,陕西 西安 710049)
0 引 言
随着高性能计算的高速发展,超级计算机的发展进入了一个蓬勃发展的新时代。由国内自主研发的神威太湖之光[1]实现了处理器核心全部国产化,整个系统拥有1 000万核,处理速度达到了每秒12.5亿亿次,在2017年11月的top500排名中再次位居世界第一。高性能计算是战略性、前沿性的高新技术,是世界各国争夺的战略制高点,是国家创新体系的重要组成部分。国内已经拥有了由19个高性能计算中心组成的中国国家网格[2],计算资源能力位居世界前列。
高性能计算中心都运行着独立的作业调度系统如OpenPBS,Slurm,Condor等。主流的资源管理系统主要由资源管理和作业管理两个部分组成。资源管理服务主要负责对计算中心的计算资源进行管理,为被调度的作业分配计算资源。作业管理服务主要维护用户的作业队列,根据调度策略选择合适的作业进行提交。目前对大规模作业调度系统的研究主要集中在单计算中心内部的作业调度策略,这些调度算法的设计主要考虑到系统吞吐率、利用率和公平性。N.Rathore等[3]通过网格内作业迁移实现计算中心内的负载均衡;李荣盛等[4]提出了基于价值密度和相对截止期的作业调度算法以提高资源利用率;梁毅等[5]提出的RB-FIFT策略有效地减少了资源碎片;Niu Shuangcheng等[6]提出的基于检查点的回填策略提高了作业响应时间;Dan Tsafrir等[7]通过系统产生作业预测时间提高作业回填调度的准确性;蒋江等[8]研究了单集群内基于多种资源的负载均衡算法;曹宗雁等[9]提出的基于用户评价的集群作业优先级调度提高了用户服务质量。这些调度策略只能尽量保证计算中心内部资源的高效利用,并不能保证各个计算中心的负载均衡。于珊珊等[10]针对多数据中心任务调度,提出了基于SLA的最大化收益任务调度算法。这种调度算法仅适用于云计算数据中心,而对于高性能计算中心并不完全适用。
在国家高性能计算环境中,由于网络带宽和地域等因素,可能会造成不同计算中心资源忙闲不均[11]。针对多计算中心作业调度,采用基于负载感知和QoS的多中心作业调度策略,充分考虑各个计算中心的负载情况和用户对作业的QoS需求,对作业进行分流,以提高计算中心的服务水平。
1 基于排队论的多计算中心服务性能分析
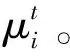
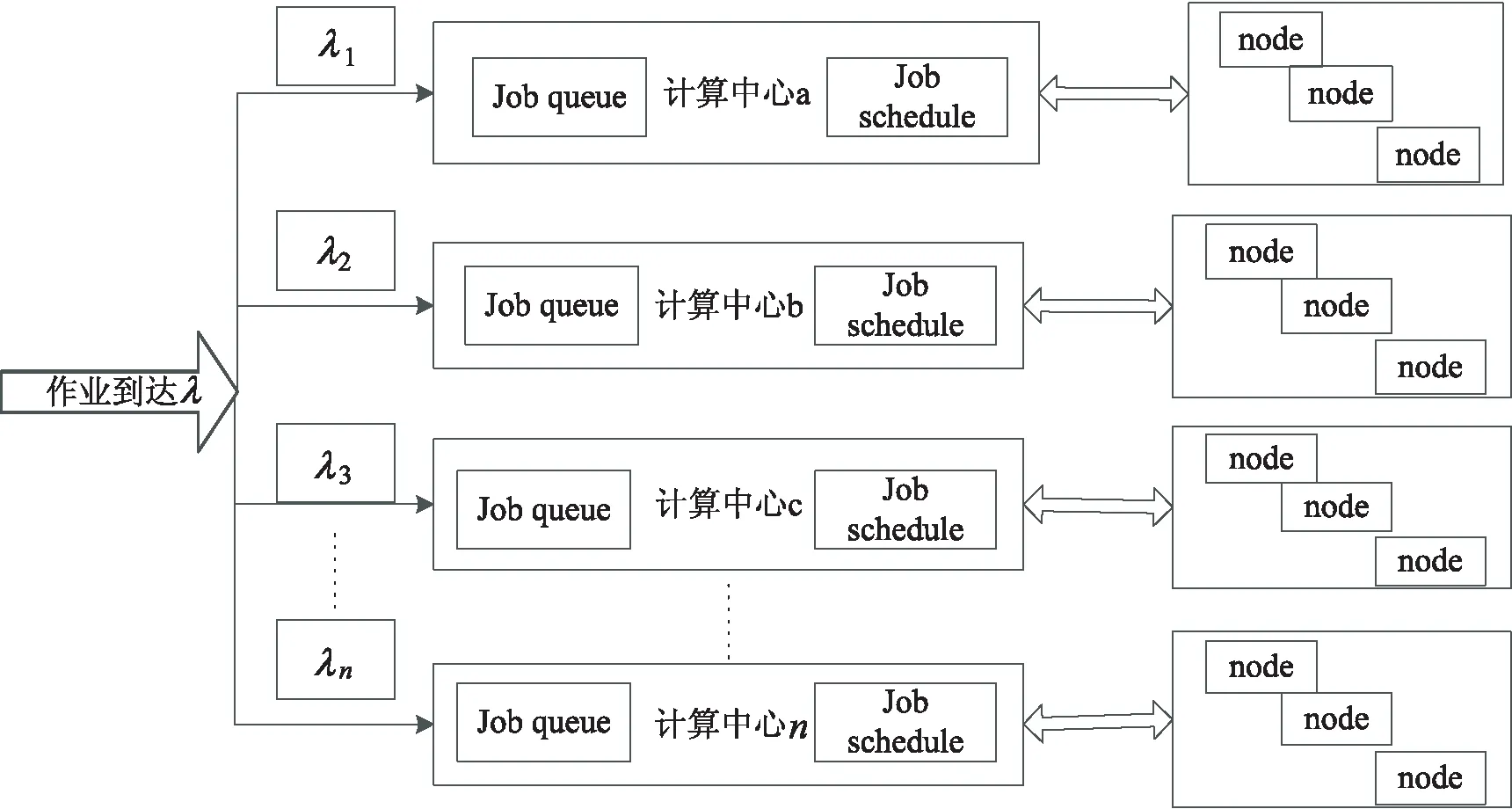
图1 多中心作业服务示意图
任务到达间距遵循参数为λ的泊松分布,任务的服务时间遵循参数为μ的负指数分布,这样的假设是合理的,并且在许多研究文献中都支持这种假设。
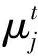
(1)
(2)
(3)
根据式1~3可得:
(4)
单个计算中心的服务满足M/M/1的排队论模型。根据little公式可知:
计算中心Ci的等待队长为:
(5)
多计算中心排队总长度为:
(6)
计算中心Ci的等待时间为:
(7)
多计算中心平均等待时间为:
(8)
2 计算中心负载模型
2.1 计算节点负载模型
高性能计算节点的负载包括CPU的负载、内存使用率等。与此同时,节点温度也是负载的重要指标。定义一个负载指数load_index衡量物理节点的综合负载程度。
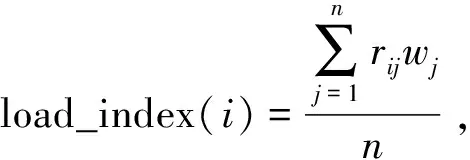
2.2 计算中心负载模型
对计算中心的负载进行划分:
(1)轻载:当空闲节点比例超过α时,表示该计算中心处于轻载状态。
(2)正常:当正常节点的比例超过β时,表示该计算中心处于正常状态。
(3)过载:当过载节点的比例超多γ时,表示该计算中心处于过载状态。
在计算中心内部负载正常的情况下,作业直接分配给最近计算中心完成,如果计算中心处于过载或者故障状态,这个作业就会分配给其他计算中心完成。
3 基于负载感知和QoS的作业调度算法
3.1 用户的QoS目标约束
QoS服务质量是来源于网络性能机制的参数,但在计算中心用QoS表示用户提交的作业所需求的各种服务特征参数。用户在向计算中心提交作业时,对于计算平台的服务质量有一定的要求。用户可能将成本的开销、完成时间、响应时间、平台可靠性等作为QoS目标约束。满足用户对QoS参数的要求,可以提高计算中心的用户满意度。因此,计算中心保证QoS,对于它向用户提供的服务至关重要。用户每次提交作业时,可能会根据作业的特点对QoS的属性有不同的偏好。用户在提交作业时,同时会对本次作业的QoS属性的偏好进行选择。选取计算中心5个服务质量属性作为目标约束。
(1)计算价格(P)。
用户将要执行的作业和数据上传到计算中心,并提交作业到作业调度系统等待获取可计算资源,计算中心会根据作业请求的计算核数以及作业的执行时间收取费用。计算中心的计算资源通常按照核每小时进行收费。
(2)排队时间(Q)。
当用户提交作业到计算中心的作业调度系统,如果当前计算中心的资源无法满足作业提交时申请的资源时,作业会进入排队状态。当有空闲资源时,调度系统会重新调度作业,给作业分配资源。
(3)计算能力(C)。
不同的计算中心可能采用不同的硬件资源和不同的网络拓扑。计算中心的计算能力存在差异。如果作业对计算能力有要求,用户可能会选择计算能力强的计算中心。
(4)上行传输速度(Bin)。
用户使用计算中心资源时,首先需要将程序执行需要的运行数据上传到计算中心的登录节点。对于大输入应用,生物计算领域,如BLAST[12],计算数据主要由比对文件和比对数据库两部分组成。比对数据库文件通常很大,用户上传需要很长的时间。
(5)下行传输速度(Bout)。
当用户的程序执行结束后,用户需要下载程序执行结果时,需要从计算中心的存储节点下载到本地。对于大输出应用,选择分子动力学和工程学中用于产生运动轨迹的应用软件。如Fluent[13],随着计算步数的增加输出数据会明显增加。
用户根据作业的性质,对各个属性进行打分。分数的范围设置为0~10。当用户对某一项评分为0时,表示不关心此QoS属性。
3.2 计算中心QoS属性向量
在一个计算中心Ci中,计算价格是由计算中心的管理人员制定的,在一段时间内不会发生改变;计算能力由硬件资源和网络拓扑决定,在一段时间内不会发生改变;上行传输速度和下行传输速度由当前网络环境决定,需要定时测量;影响排队时间的因素主要由计算中心内排队的队长决定。
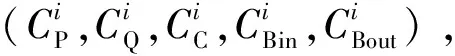
计算中心Ci的计算价格属性维度为:
(9)
计算中心Ci的排队时间属性维度为:
(10)
计算中心Ci的计算能力属性维度为:
(11)
计算中心Ci的上行传输速度属性维度为:
(12)
计算中心Ci的下行传输速度属性维度为:
(13)
该方法实现对原始数据的等比例缩放,其中X_norm为归一化后的数据,X为原始数据,Xmax、Xmin分别为原始数据集的最大值和最小值。
3.3 算法描述
多中心作业调度算法首先考虑各个计算中心的负载情况,当作业到来时,首先将轻载或负载正常的计算中心作为备选计算中心。在此基础上,考虑用户作业对服务质量的需求,对作业和计算中心进行QoS匹配,通过计算作业提交的QoS属性向量和计算中心QoS属性向量的余弦值,找到与作业亲和度Affinity最高的计算中心。算法描述如下:
算法:基于负载反馈和QoS约束的多中心作业调度算法
输入:用户对QoS属性的打分,计算价格(s1),排队时间(s2),计算能力(s3),上行传输速度(s4),下行传输速度(s5)
输出:最优计算中心
1.for each hub in hubsList do
2.getcurrentState(hub);//获取每一个计算中心的负载
3.if(hub.state==idle||hub.state==normal)then
4.candidatesList.add(hub);
5.end if
6.end for
7.for each candidate in candidatesList do
8.tmpAffinity=calculteCos(s1,s2,s3,s4,s5);//计算作业和计算中心的亲和度
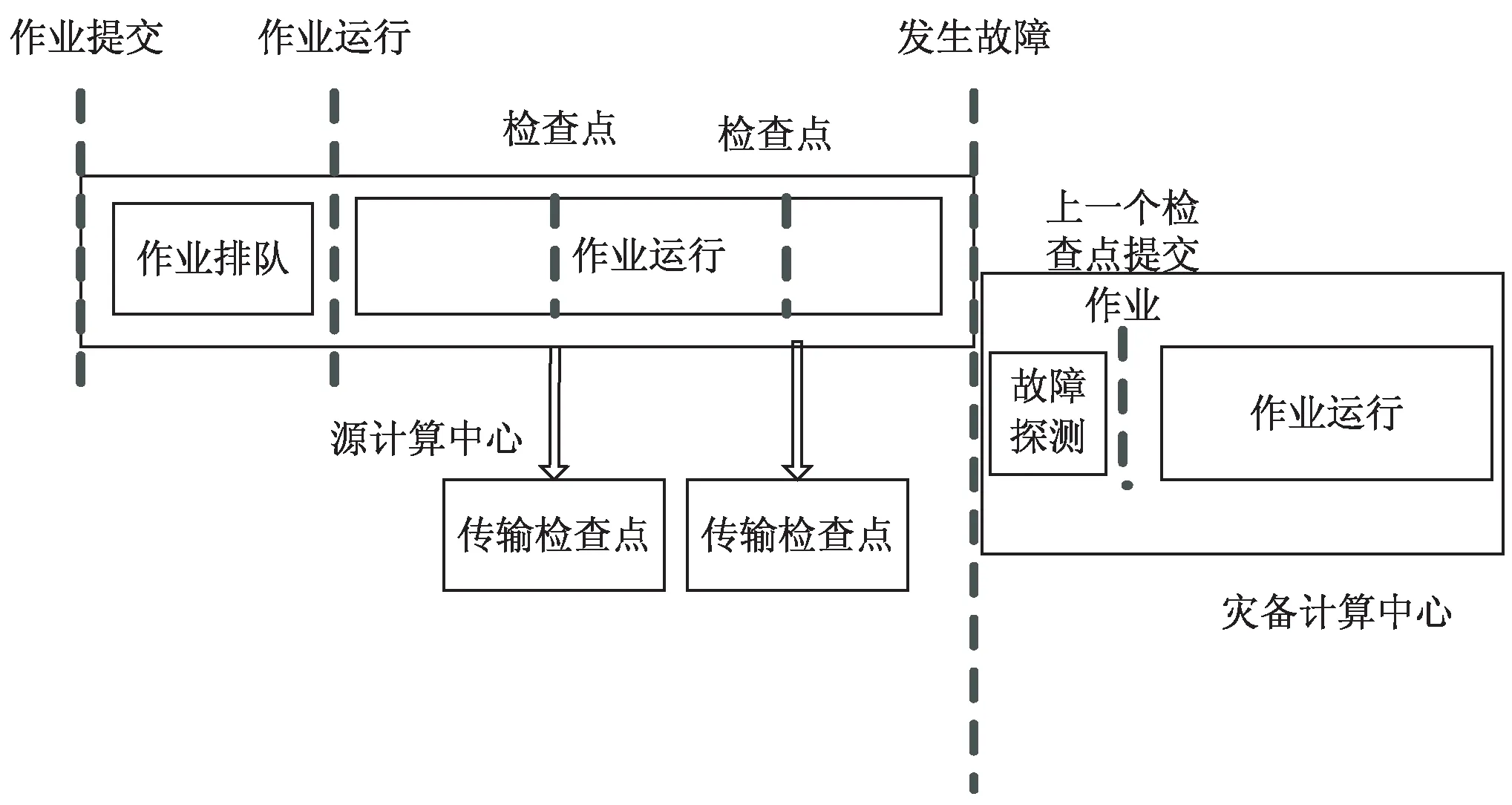
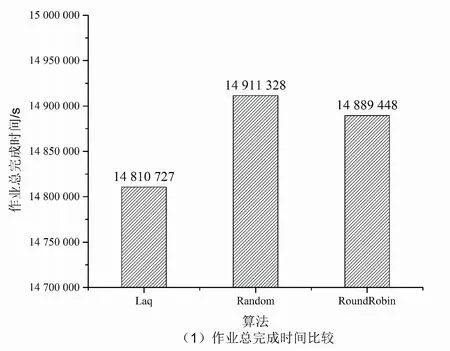
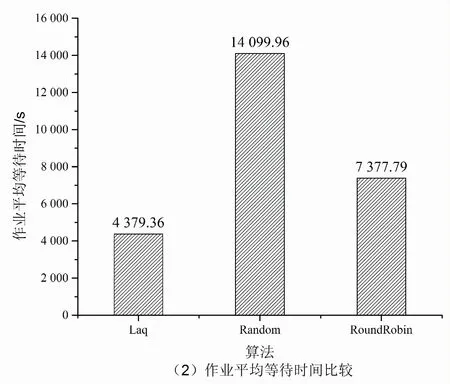
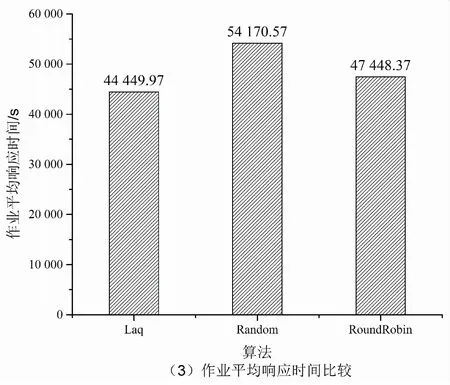
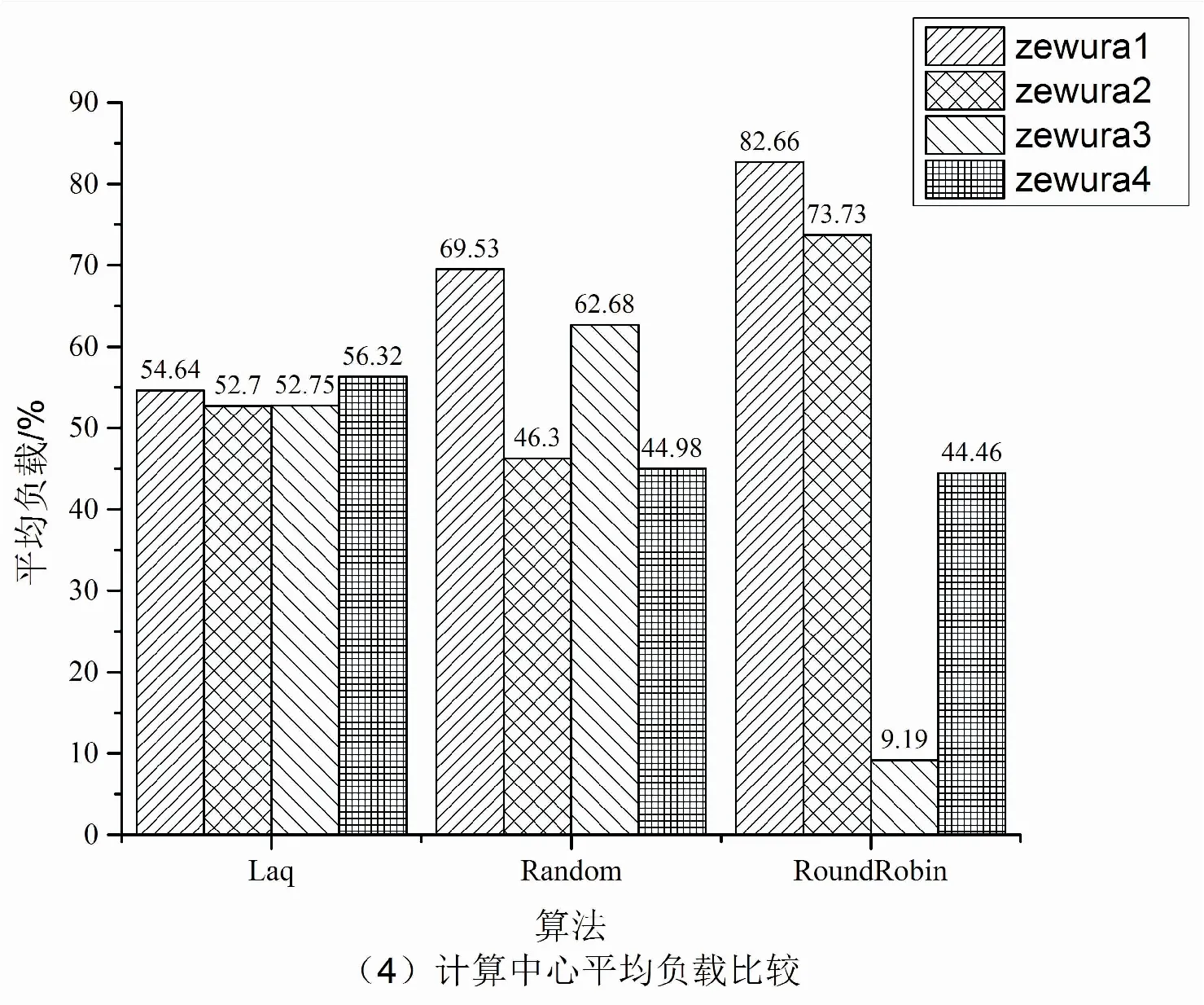
9.if(Affinity 10.bestSelect=candidate; 11.tmpAffinity=Affinity; 12.end if 13.end for 14.return bestSelect 随着系统规模不断扩大,系统的故障率也在不断增加,需要在多中心作业调度系统中添加作业迁移容错机制,以保证用户作业得到更好的服务。基于检查点的多中心间作业迁移容错策略一方面支持传统的用户手动的检查点恢复功能,另一方面解决大量长时应用在作业运行时出现异常中断的问题。一些科学计算作业通常都采用并行处理,需要多个计算节点协同完成。在作业任务量比较大的情况下,需要较长的时间开销。如果在运行过程中出现异常中断,只能从头开始计算。即使作业支持检查点机制,也需要用户显示地恢复作业,这就造成了系统吞吐率下降,影响作业的响应时间。 当计算中心遇到例行维护等工作时,系统会将正在运行的作业挂起,当系统恢复正常时再重新执行挂起的作业。定期将程序检查点文件迁移到灾备计算中心。目前在计算中心的调度系统中,如果某一个计算节点出现问题而导致整个作业被中断,必须重新被调度从头开始运行,当作业运行时间较长时,非常耗费资源且无法保证用户的服务体验。多中心间作业迁移是指将一个计算中心的作业迁移到另一计算中心运行的方法。作业迁移可以提高计算中心的负载均衡,实现高效的容错,为用户提供更加优质的服务。 检查点技术广泛应用于程序运行中间状态的保存和运行状态的恢复。当前该技术并未应用在多中心作业迁移的容错策略中。根据用户设定的检查点同步时间间隔,当检查点同步时间到期时,主计算中心将当前作业检查点数据同步到灾备计算中心,检查点的网络传输和作业运行是并行的,并不会对作业产生多余的时间开销。当灾备计算中心在一定时间内没有收到主计算中心的同步信号时,则灾备计算中心根据作业检查点信息重新提交用户作业,当作业获取调度器分配的资源时,作业从检查点处恢复作业的执行。 在源计算中心,作业迁移发送模块根据用户作业提交的信息,设定作业检查点迁移周期和灾备计算中心。当检查点迁移周期到期时,作业迁移发送模块检查作业的运行状态,如果作业没有运行结束,迁移模块压缩作业的检查点文件并将其同步传输到目标计算中心。 在灾备计算中心,作业迁移接收模块定期会收到源计算中心的心跳信息和保存作业的检查点文件,当迁移接收模块在一段时间内没有收到心跳信息,则认为源计算中心发生故障。迁移接收模块将从检查点处提交作业。 系统可用性(Availability)是信息工业界用来衡量一个信息系统提供持续服务的能力,表示在给定时间系统或者系统某一能力在特定环境中能够满意工作的概率。其计算方法为: (14) MTTF(mean time to failure,平均无故障时间),指系统无故障运行的平均时间,取所有从系统开始正常运行到发生故障之间的时间段的平均值。即使每一个零件有很高的可靠性,但组成的系统的MTTF值会骤然下降。MTTR(mean time to repair,平均修复时间),指系统从发生故障到维修结束之间的时间段的平均值。 在目前的作业调度系统中,如果计算节点发生故障,在节点上运行的作业都会异常退出。用户需要等待计算中心故障修复,然后重新从检查点提交作业。从用户角度,从作业异常退出到作业再次提交的这段时间内,计算中心的计算节点不可用属于MTTR。MTTR取决于用户发现故障的时间和计算中心故障修复的时间。多计算中心作业迁移容错机制保证了灾备计算中心第一时间发现用户作业发生故障,迁移调度模块自动根据作业的检查点信息重新提交作业,大大缩短了由于源计算中心故障修复和用户发现故障不及时带来的时间开销。在多中心间作业迁移容错模型中,当灾备计算中心探测到源数据中心发生故障时,将根据作业检查点信息重新提交作业,减少了人为故障探测和等待计算中心故障修复的时间代价。整个迁移容错过程大大降低了MTTR,从而提高了系统的可用性。基于检查点的作业迁移流程如图2所示。 图2 多中心作业迁移容错示意图 检查点生成之后,源中心的迁移发送模块需要将检查点文件传输到灾备计算中心,检查点的传输和作业的运行是异步进行的,影响程序执行的主要因素是作业检查点的开销。由于一些作业生成的检查点文件较大,需要在传输前进行压缩处理。压缩可以有效地减少传输带来的开销。 仿真工具使用GridSim[14],它是澳大利亚墨尔本大学开发的基于Java离散事件的网格仿真工具,基于SimJava开发。该工具支持对网格资源、用户和应用的仿真和建模。它提供了创建应用任务和网格资源管理调度的方法。仿真结束后,用户可以调用GridSim中称为GridStatisties的库函数来收集各种模拟的统计资料。 利用GridSim构建了4个计算中心,计算中心的资源情况如表1所示。 仿真使用的实验数据集是由捷克国家电网基础设施MetaCentrum提供的Zewura工作日志[15]。Zewura日志包含五个月的执行工作(2012年1月-5月)从TORQUE跟踪生成的数据集。该日志包括17 257个作业。 将提出的Laq算法和两种主流的负载均衡算法Random、RoundRobin分别从作业总完成时间、作业平均响应时间、作业平均等待时间、计算中心平均负载等多个维度进行比较,如图3所示。 图3 多计算中心服务性能比较 由仿真结果可得,相比Random和RoundRobin,Laq算法显著降低了多计算中心作业的完成时间、平均响应时间、平均等待时间。在Laq算法的作业调度策略下使各个计算中心保持相对平均的负载,合理利用和分配计算资源,提高了资源利用率。 针对分布在不同地域的计算中心存在计算资源忙闲不均,缺少统一调度和管理的问题,提出了一种基于负载感知和QoS的多中心作业调度算法。该算法根据各个计算中心的负载情况将需要处理的作业分配给负载较轻的计算中心,充分考虑到用户的QoS需求,将作业尽量调度到符合用户QoS需求的计算中心,从而提高计算中心的服务水平。通过与Random和RoundRobin的仿真对比,证明了该算法的有效性。4 基于检查点的多中心间作业迁移容错策略
4.1 多中心间作业迁移
4.2 多中心系统的可用性分析
5 仿真实验分析与比较
6 结束语
