基于数据挖掘的监控信号辨识研究
2018-12-17邓梅余剑峰
邓梅,余剑峰
(国网宜昌供电公司,湖北 宜昌 443000)
1 引言
随着电力行业改革逐步深化,部分电网已经完成了智能化改造,能够极大降低实时监控工作人员的工作强度,并且提升了监控效率,降低了潜在风险发生概率。较为典型的是110kV以上变电站通过集中监控的管理方式将监控信息进行集中处理,使得电网监控工作人员能够对这些信息进行集中处理并及时进行调控措施。
我们现阶段对于电网实时监控工作的模式主要表现为通过人工管理来实现,但是有较多的客观因素会对人工监控的流程造成困扰,并且对监控效率造成影响。由于工作人员的精力有限,因此长时间对大量的电气信号进行识别的过程中,会出现由于工作人员精力降低而出现的各种失误与低效,如果出现对故障的判断失误,将会对电网造成较大程度的损失。由此要加强电网监控功能就需要依靠自动辨识方法来提供一种能够辅助工作人员及时判断电网信息,可以有效减轻监控人员的负担、加快电网事故处理的流程、避免信号漏看导致的电网事故。
因此本文所研究的监控方式,能够以聚类信息识别分类为理论基础,相对传统人工监控而言,能够在数据处理的基础上,按照监控信息发出时间为依据进行分段,将原本连续的监控信息切分成多个文本,而后采用统计学的方法对文本进行预处理形成对应特征向量,并通过数据挖掘的方法对特征向量集合进行聚类分析得出聚类规则。最终能够让对大量监控信息进行智能化处理,为工作人员的具体工作提供较严谨的辅助功能,及时发出的告警信号,维护电网安全稳定运行的目的。
2 监控信息数据样本的预处理
2.1 建立电网监控的信息熵模型
对固定时间的信息进行获取。电网设备能够在自身发生异常时进行告警,告警信息发出的同时会附加具体时间。根据时间尺度来对信息进行获取并处理为数据样本,需要以3秒为间隔对就近时间段内信息数量进行统计。具体如下式所示:

上式中的S、t、m分别表示处理后获取的监控信息、具体时段、时段中的信息数量,其中(tn,mn,cn)表示时间区间tn里获取的具体信息数量mn,包括文本cn。
下一步需要对信息熵模型进行构建。一般出现设备故障后的10秒内将会发出告警信息,将时间跨度设置为30秒能够对有效信号进行全部获取,所形成的告警信号文档为S,对其信息熵进行计算的公式为:

其中φ、n分别表示常数以及状态数,数值范围为告警信息数量的上限值,P(k)表示出现概率,通过下式来进行获取:

最后,基于信息熵的告警信息文档筛选。在监控系统中单独的告警信息不能作为故障判断的依据,每当设备异常或电网故障时,总是伴随着大量的一次设备的电气、物理信号和二次设备的动作信号;与之相对应的,单一出现的告警信号往往是电网辅助设备发出的告警信号,不能作为设备故障(或异常)的判断依据。因此,对应时段的监控信息熵越大,则该时段告警信号发出不会是规律的,其熵越大出现设备故障(或异常)的几率越高。为此,本方法以30s为时间跨度,每隔10s进行一次采样,计算对应的监控信息文档S的熵。将信息熵H (S) <0.3的监控信息文档筛选掉,即排除监控告警信号发出特别规律的时段。
其他信息文档中记录有30s内的告警信息,远高于10s的设备故障信息送到标准,因此需要进行二次筛选来对有效文本内容进行确定。需要通过以下筛选流程来完成:(1)对(ti, mi, ci)进行删除,并对删除后的熵H'(S)进行计算;(2)以处理后数据变化最大的项为中心,从边缘对数据项进行处理,直至H (S') <H(S)。

图1 信息剔除方案
由以上步骤可以得到任意监控系统在任意时段得到的监控信息文档集合{Si}。其中为含有有效告警信息的文档。
2.2 文本的空间特征向量表示
第一,进行文本提取步骤要根据统计分词的特征项进行,通常设备告警信息文本具有较为明确的描述标准,所以运用统计分词来进行处理,对2个汉字进行互现信息系数统计可用下式来进行:

上式中M(X,Y )与P(X,Y )分别表示两个汉字的互现信息系数以及两个汉字的相邻出现概率,P(X)、P(Y )表示两个汉字在告警信息文本中的出现概率。两个汉字在文本中的出现次数以及是否相邻决定了其成为关键词的可信程度。需要在文本特征中设置M(X,Y)>0。
第二,还需要对无意义词汇进行去除。如“的”、“了”等无意义汉字进行剔除以提高特征项集合的有效性,处理后表示为:其中δ表示处理完成后的最终词。再通过TF-IDF公式来对词条权重进行确定,其算式表现为:
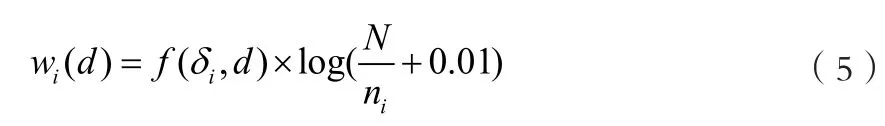
上式中,f(δ1,d )表示文档中出现δ1的频率,N表示总文档数量,ni表示文档中包含δi的文档数量。通过TF-IDF公式来对词条权重进行确定,wi与δi与特异性呈正比关系,假设其在单个文档中出现的频率远高于在多个文档中出现的频率,那么可以判断δi用于表征文档d的可信度越高。
第三,建立文本特征空间向量。通过文本特征量的提取可以计算得到不同词条在文档中的权重。但是这样得到的权重没有进行归一化处理,归一化处理后的权重为:

因此任意文档可以表征为一个二维向量,其形式如下式(7)所示:

通过不同词条建立一个坐标轴后,能够对在该坐标空间中确定该二维向量确实是在该空间中。
3 基于K-means算法的聚类分析
对多个对象进行选择,并且用k来对其数量进行表示,建立初始簇集合,表示为。总数为k的对象通过来进行表示,即特征向量集合。通过夹角余弦公式对新获取文本与特征向量的相似度进行计算,该算式表示为:


重新整合后形成新的函数,成为评价函数,具体算式如下所示:

式(10)中,J 表示为任意数值与特征向量的均方差之和,即为具体的评价函数数值。xn为文本文档Sn对应的特征向量,为第k个簇的特征向量,为文档Sn与第k个簇的相似度。Zk为第k个簇中含有的元素个数,K为所有簇的个数。
重复样本归入聚类簇中心的步骤,当评价函数的数值没有出现任何变化后,能够对K个簇的正交形态进行确定,告警信号能够根据其表示的特征向量进行模板对应。最后,采用人工识别的方式来对完成的簇进行检查确认,对告警信号的文本文档具体告警内容进行明确。通过以上所有步骤可以对任意时间长度的告警信号进行聚类分析,将其转化为对应的k个典型特征向量(即k个典型故障告警文本模板)。
4 基于聚类挖掘的告警信号辨识实施步骤
步骤1:每隔10s统计一次最近30s的告警信号,形成新增文档S。
步骤3:计算新增文档S与各个簇中心特征向量的相似度,对其进行分类。
从上述方法可以发现,本问研究内容提出的一种基于聚类的电网运行监控信息智能辨识分类方法。本文的方法能够在电网监控研究中对科学分析法进行应用,通过聚类分析对历史告警信息的特征向量进行分析提取后,建立有效的特征向量信息文本集合,并且通过聚类分析法对特征向量空间进行构建,在对典型告警信息内容的空间特征向量进行确定后,在出现新告警信息后能够对其进行有效的分析计算,通过计算其与特征向量的相似度来对具体的有效告警信息进行确定,能够有效提升监控工作人员对于告警信息的辅助处理,并且在信息自动分类的状态下,提升对于告警信号的识别效率与准确度,对人工监控可能出现的失误情况进行有效弥补,促使电网运行安全系数的提升。
