基于条件生成式对抗网络的数据增强方法
2018-12-14陈文兵管正雄陈允杰
陈文兵,管正雄,陈允杰
(南京信息工程大学 数学与统计学院,南京210044)(*通信作者电子邮箱zhengxguan@163.com)
0 引言
卷积神经网络(Convolution Neural Network, CNN)是一种有监督学习模型,在视觉处理和图像分类中性能优越[1-7]。 LeCun等[1]提出的LeNet-5网络是CNN的最初模型,该模型采用基于梯度的反向传播(Back Propagation, BP)算法对网络进行有监督的训练;经过训练的网络通过交替连接的卷积层和下采样层将原始图像转换成一系列的特征图,再通过全连接层实现对图像特征图分类或识别,卷积层中的卷积核发挥人类视觉的感受野功能,卷积核将图像的低级局部区域信息转换成人类视觉的更高级形式。Krizhevsky等[2]提出一种AlexNet网络架构,该架构在大小为1 400万张样本、涵盖2万个类别的图像数据集ImageNet上参加图像分类竞赛,它以准确度超越第二名 11%的巨大优势夺得了2012年冠军,这一惊人的成绩引起了研究人员的普遍关注, 并使得CNN成为近年的研究热点。Simonyan等[3]基于AlexNet针对CNN深度进行了专门研究,并提出了VGGNet网络架构,该网络架构的各卷积层均采用3×3的卷积核,通过对比基于不同深度网络架构的图像分类性能,证明了增加网络架构的深度有助于提升图像分类的准确度。近年来,对CNN模型架构的研究及应用仍然在迅速发展之中,在模型架构研究方面, GoogLeNet[4]、ResNet[5]等受到广泛关注; 另一方面,由前述模型的训练、测试及分类应用可以看出,良好性能的取得依赖于大规模图像数据集的支撑,如LeNet-5采用的训练集是样本数为60 000、分类标签个数为10的MNIST(Modified National Institute of Standards and Technology)数据集, AlexNet、VGGNet等均采用训练集大小为1 400万张、涵盖2万个类别的ImageNet数据集进行训练、测试。由此可见,训练集的规模对CNN性能发挥着至关重要的影响。
然而,在现实世界中由于受自然因素的影响和数据记录条件的限制,得到大尺度有标签的数据集通常是不现实的,往往仅有少量的、带标签的数据样本。如某地区为了建立基于浓雾天气形势场的智能预报模型,由于天气形势场实际上就是一些等高线组成的纹理图,雾型与纹理之间具有高度的关联性,因此,利用CNN建模是解决这一问题的最佳选择。然而,该地区仅记录了2010年以来的天气形势图及其对应的出雾记录,样本集收集了386个样本,对应的雾型12类(即分类标签数12个)。若直接采用该样本集训练CNN模型,则训练出的模型必然缺少泛化性[8],因此缺乏可信性及可靠性。 因此,在建立可信性及可靠性CNN模型之前,需要寻找一种可靠的扩展数据样本及多样性的方法,即所谓的数据增强(Data Augmentation)方法。
在数据增强研究方面,Bjerrum等[9]通过使用仿射变换生成新样本,将样本和新样本混合作为训练集输入到神经网络中,训练完成后模型的分类结果误差控制在0.35%以下。 Goodfellow等[10]提出的生成式对抗网络(Generative Adversarial Net, GAN)是一种生成式模型, 其主要思想如下: 在结构上受博弈论中的二人零和博弈 (即二人的利益之和为零, 一方的所得正是另一方的所失) 的启发, 由一个生成器G和一个判别器D构成。G捕捉真实数据样本的数学分布模型, 并由学习到的分布模型生成新的数据样本;D是一个二值分类器,用处是判别输入是真实数据还是生成的样本。 二者不断学习,提高各自的生成能力和判别能力。Mirza等[11]提出条件生成式对抗网络(Conditional Generative Adversarial Network, CGAN)模型,该模型是有条件控制的GAN,通过对生成器和判别器添加相同的条件Y(例如数据的标签),从而实现对GAN模型控制条件。目前有很多研究自动编码器(AutoEncoder, AE)、变分自动编码器(Variational AutoEncoder, VAE)结合GAN的工作[12-14],目的在于提升GAN生成图像的真实性和多样性。
将现有的数据增强算法如仿射变换、GAN等应用于天气形势图,实验显示生成的新数据集出现重复率高、多样性低等问题,利用生成的数据集训练CNN模型,所训练模型分类的正确率仍不理想。 综上,为了更好地解决天气形势图问题,提出一种集成高斯混合模型(Gaussian Mixture Model, GMM)及CGAN模型的数据增强方法,该方法不仅生成类似样本的新图像,在提升生成样本的多样性方面与传统方法相比有显著改进。
1 相关数据增强算法
1.1 仿射变换
仿射变换是一种二维坐标(x,y)到二维坐标(u,v)的线性变换,其数学表达式如式(1):
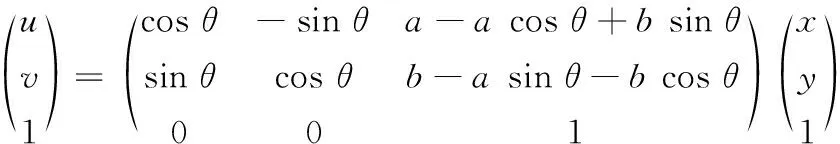
(1)
式(1)中的系数矩阵被称为仿射变换矩阵。其中:θ为图像旋转的角度,a为图像平移的横坐标移动距离,b为图像平移的纵坐标移动距离。
Bjerrum等[9]提出了基于仿射变换(Affine Transformation)的数据增强方法,通过对样本图像进行放大、缩小、平移、旋转以实现生成类似样本。实验中,随机生成x轴的位移为a,y轴的位移为b和旋转角度为θ的仿射变换矩阵A,作用在输入图像x上,变换后的新图像为Ax。 由于仿射变换是一种全局图像变换,因而在聚焦于局部区域的多样性方面该变换无法实现。
1.2 GAN及衍生模型
事实上,这个学习优化过程是一个极小极大博弈(Minimax game)问题,即寻找二者之间的一个平衡点,如果达到该平衡点,D无法判断数据来自G还是真实样本,此时G达到最优状态。大量的实践已经证明可利用GAN解决训练集中样本数量过少的问题,如Gurumurthy等[15]利用改进的GAN增强小数据集以提升训练器的分类精度;王坤峰等[16]提出多个GAN衍生模型以增强数据集。
GAN的结构如图1所示,D和G分别表示判别器和生成器,它们的结构都为CNN。D的输入为真实数据x,输出为1或0;G的输入是一维随机噪声向量z,输出是G(z)。训练的目标是使得G(z)的分布尽可能接近真实数据的分布pdata。D的目标是实现对输入数据的二值分类,若输入来源于真实样本,则D的输出为1;若输入为G(z),则D的输出为0。G的目标是使自己生成的数据G(z)在D上的表现D(G(z)) 和真实数据x在D上的表现D(x)尽可能一致,G的损失函数按式(2)计算:
(2)
式(2)描述的是,G在不断对抗学习的过程中,生成的数据G(z)越来越接近真实样本,D对G(z)的判别也越来越模糊。D的损失函数按式(3)计算:
Ez~pz(ln (1-D(z))))
(3)
综上,G和D的总体损失函数可以描述如式(4)所示:
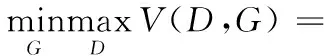
Ez~pz(ln (1-D(z))))
(4)
传统的GAN模型一次只能学习一类数据,对于包含多个类的数据样本集,需逐类学习及生成相应类的被增强样本集,因此,效率低是模型的主要缺陷。为了解决以上问题,Mirza等[11]提出了CGAN模型,CGAN的结构如图2所示。该模型通过对生成器和判别器添加相同的条件Y(例如:数据的标签),从而使GAN模型具有多类数据的生成能力。

图1 GAN结构示意图
与传统GAN对比,CGAN模型仅对前者的总体损失函数进行了修改,新的总体损失函数如式(5):
Ez~pz(ln (1-D(z|Y))))
(5)
然而, GAN及CGAN在训练样本过少的情况下,均存在G和D过早达到平衡点现象,致使G生成的数据重复度高,数据多样性不足。
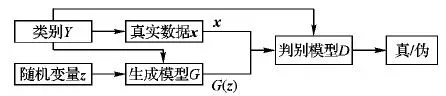
图2 CGAN结构示意图
2 GMM-CGAN
如前所述,生成器G通过单一分布描述训练数据样本的分布,不难理解单一分布对样本数据特征多样性难以反映,其直接后果是训练的生成器G生成的数据样本特征单一,难以达成样本数据集增强的目的。而高斯混合模型(GMM)的实质是利用m(m≥3)个正态分布来刻画样本整体的多样性特征,通过训练学习后,建立由m个组件(即m个正态分布)构成的混合分布模型。一方面多组件构成的混合模型能够更好地刻画样本的多样性特征,另一方面这种数据特征的多样性又受到每个组件的约束,使得混合模型生成的新样本既具有多样性又保持与原样本之间特征的相似性。基于此,为了解决上述存在的问题,将GMM集成到CGAN模型进而提出一种全新的GMM-CGAN数据增强框架,这个框架在理论上是可行的。
GAN中的生成器G的目标是使得pdata(G(z))尽可能接近样本分布,其中pdata(G(z))是描述G(z)的分布。 根据概率的乘法公式,pdata(G(z),z)可写成一个已知的先验分布密度函数pz(z),乘以pdata(G(z)|z),如式(6)所描述。 结合前面的分析,通过提升先验分布的多样性,从而提升G(z)的多样性,达到生成样本多样性的目的。 首先,假设先验分布的密度函数pz(z)是有m个组件GMM,如式(7),同时假设每个高斯组件的协方差矩阵为对角阵。
(6)
(7)
其中N(x;μi,σi)表示高斯混合模型的概率密度函数,具体形式如式(8),在GAN训练的过程中,由于参数πi不能被优化,设πi=1/m以简化计算:
(8)
接着,利用Kingma等[12]提出的重复调参技术(Reparameterization trick)生成服从先验分布的一维随机噪声向量z,z如式(9)计算:
z=μi+σiδ;δ~N(0,1)
(9)
其中:μi、σi为第i个高斯组件的均值和标准差。 重复调参技术优点在于:可将高斯组件的参数看作为网络参数的一部分进而与网络参数一起训练及优化。
综合式(6)、(7)、(9),可导出式(10):
(10)
式(10)中,u=[u1,u2,…,uN]T,σ=[σ1,σ2,…,σN]T,m为高斯组件个数,N为z的维度。高斯组件个数与生成样本多样性密切相关,实验分析表明,当m在[20,30]内变化时,生成的样本效果较好。为了防止在实验中σ的值变为0,在生成器G的损失函数中添加关于σ的L2正则化项,修改后的生成器损失函数如式(11):
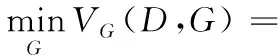
(11)
GMM-CGAN模型结构如图3所示。 GMM-CGAN的参数需初始化,由于对应于不同Y条件(样本的标签)的数据分布不相同的,因此,对于每一Y条件需要对μ,σ向量初始化,令μi~U(-1,1),σi∈(0,1),其中U(-1,1)表示区间(-1,1)上的均匀分布,标准差(0,1)区间上随机选取。
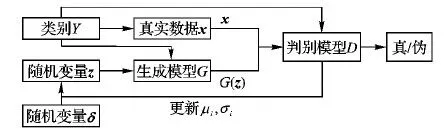
图3 GMM-CGAN结构示意图
参数μ、σ按上述方法初始化后,令z=μk+σkδ,δ~N(0,1),k按照顺序从1到m取值,将z输入G进入CGAN的训练程序,从而达到逐个训练、优化高斯组件参数μk、σk,k∈(1,m)的目的。
在CGAN被训练后,利用G生成新的样本,步骤如下:
1)选定需生成样本的标签;
2)在该标签下从μ、σ向量中任选一对分量μh、σh,h∈(1,m),并计算z=μh+σhδ,δ~N(0,1);
3)将z输入生成器G后,即为生成的新样本G(z);
重复1)~3),即可生成需要更具多样性的被增强的数据样本集。
3 实验分析与评价
3.1 原始数据集
3.1.1 浓雾天气形势图
江苏省气象科学研究所整理收集了自2010年以来所有雾型天气形势图,雾型个例77个,每个雾型个例由记录一个完整成雾过程的若干幅天气形势图组成,一般由4~5张纹理类似、尺寸为1 600×1 500图像组成。气象工作人员根据雾型将这77个例分为12类别。然而,深入分析这12个雾型类别对应的天气形势图发现,即使两个个例同属于一个类别,不同个例的形势图纹理间的差异性却很大,故样本的标签不能以类别进行标记,而以个例标记更为适当,采用77个分类的one-hot编码编制样本标签。在这样的编码机制下,每个类中有至少4张形势图,由于在首个历时及最后的历时天气形势图未入型,故剔除首尾历时未入型图后构成对应个例的样本集。通过这样的预处理后,样本数据集中样本数为386,标签类别数为77。对样本集按标准的70%对30%随机划分,分割后训练集样本个数为231,测试集样本个数为155。
3.1.2 MNIST
MNIST[1]是机器学习的常用数据集,它由数字0~ 9共计10类别6 000张手写数字图像组成。从每个类别中随机抽取50张,可以得到样本数为500的子集。对这样的数据集按标准的70%对30%随机分割,将样本个数为350的数据集作为训练集,样本个数为150的数据集作为测试集。
3.1.3 CIFAR 10
CIFAR 10是另外一个机器学习的常用数据集, 它由10个类别,每个类别6 000张图,共计60 000张彩色图像组成。实验中将所有图像进行灰度化预处理,从每个类别中随机抽取50张图像,可以得到样本数为500张灰度图像的子集。对样本数为500张图像的子集,按70%对30%随机分割,将样本个数为350的数据集作为训练集,样本个数为150的数据集作为测试集。
3.2 数据预增强
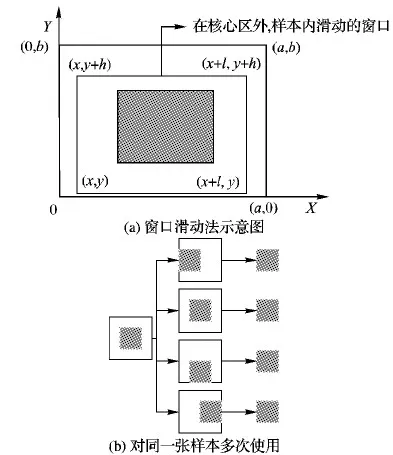
将样本中影响CNN分类的关键区域称为核心区域。在样本个数较少时,通过滑动围绕核心区域的窗口反复重采样以实现数据的初步增强。
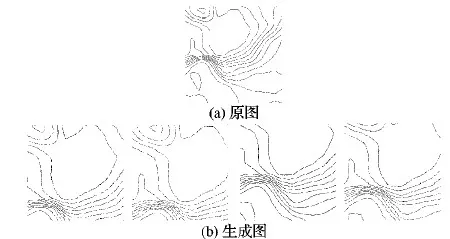
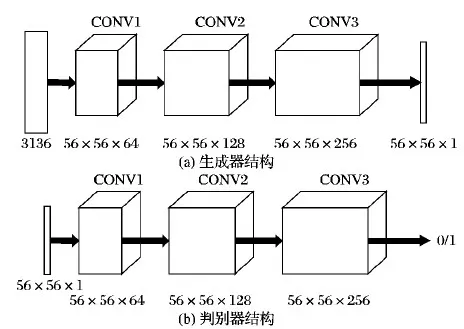
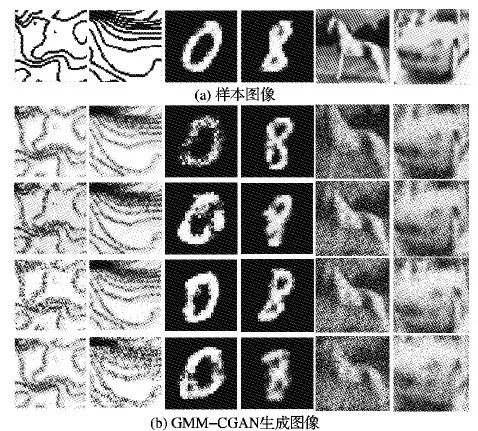
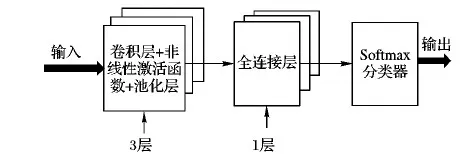
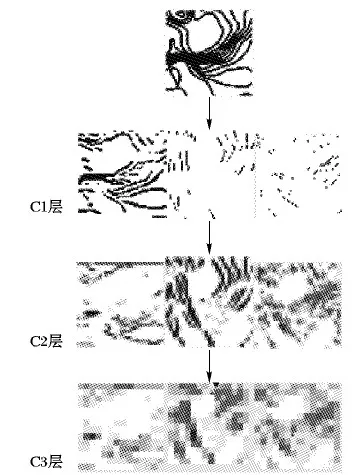
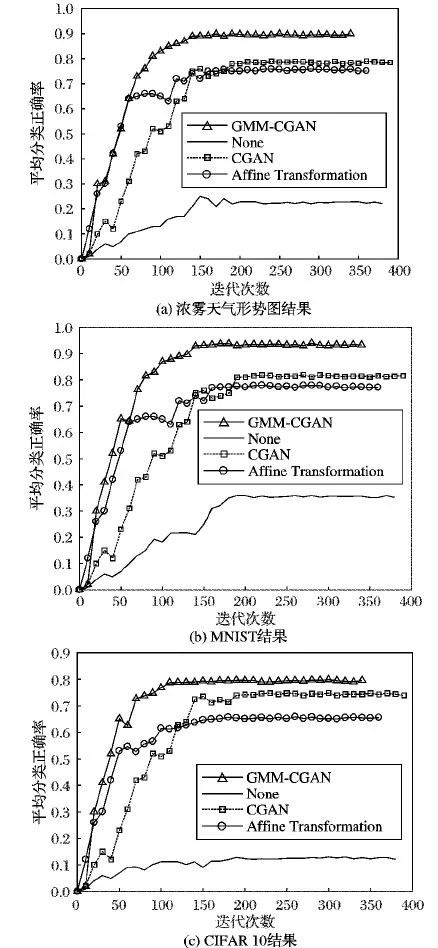
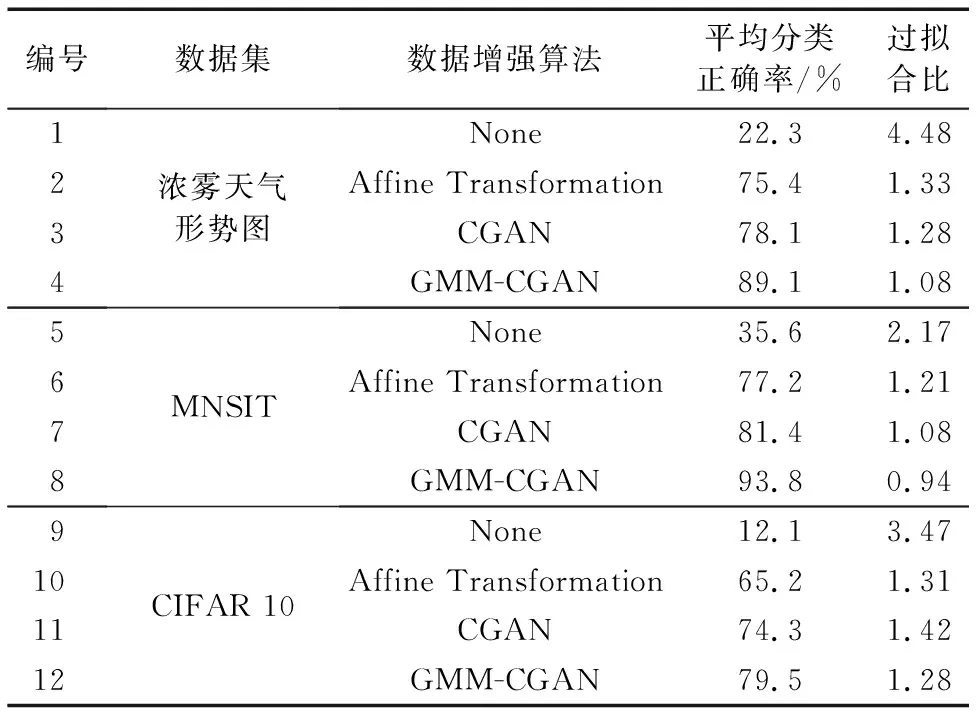
如图5所示,设在长为a、宽为b的样本图像上取长为l、宽为h的区域为核心区域,该核心区域左下角坐标为(x,y)。再设滑动窗口长为α、宽为β(l<α 第1步 随机生成参数δ∈[0,a-α],ξ∈[0,b-β]。 第3步 若满足第2步,则输出截取的窗口图像;否则返回第1步。 将滑动窗口法应用于样本集中的每个样本,可得到一个以核心区域为主导的、被初步增强的样本集,图4展示了该方法的演化过程。 图4 窗口滑动法 具体到浓雾天气形势图数据集,由于图像的经纬度及大小均一样,这里设定图像中心的800×800正方形区域为核心区域。 在滑动窗口法中设窗口长a=1 000,宽为b=1 000并应用该方法,对每一张样本作用100次,可使得样本个数扩展100倍,图5所示是部分预处理结果,训练集及测试集的样本数分别达到23 100、15 500,总38 600张。 随机抽取的MNIST和CIFAR 10子集无需预增强操作,直接进入GMM-CGAN处理阶段。 图5 滑动窗口法生成图 LeNet-5、AlexNet等CNN模型,为了保证网络学习的效率以及限制参数的数量级在可控范围内,在保持原有图像特征不丢失的情况下尽可能压缩输入图像的尺寸,使CNN的参数在可训练的范围内。 例如,LeNet-5的输入图片尺寸为28×28;AlexNet的输入图片尺寸为224×224。 浓雾天气形势图经过前面的预增强,其尺寸由1 600×1 500转化为1 000×1 000,仍需进一步压缩处理。 对比多种压缩算法的处理结果后,最优的压缩方法为下采样法,在保留纹理的情况下图像的尺寸由1 000×1 000压缩到56×56,如图6所示。 3.3.1 实验采用的CGAN结构 实验中使用的CGAN,生成器G和判别器D为CNN,具体的结构如表1~2所示。 表1 CGAN的生成器结构 CGAN的其他训练参数如下,输入、输出图像尺寸为56×56,条件信息Y为数据集的标签,训练批次为50个样本一组,最大迭代次数设置为1 000,梯度优化算法选择的是Adam优化器。 CGAN的结构图如图7所示。由于CGAN的生成器和判别器的结构都被设置为浅层卷积神经网络,而且卷积核尺寸较小,通道数量较少,CGAN需要学习的参数规模不大。GMM为非神经网络结构,计算量小,故GMM-CGAN训练的计算复杂度与CGAN相比变化不大。 表2 CGAN的判别器结构 图7 CGAN的实例结构 3.3.2 基于GMM-CGAN模型生成的样本 浓雾天气形势图数据集已通过滑动窗口法进行了预增强,得到新样本集。以预增强的浓雾天气形势图新样本集,随机抽取的MNIST和CIFAR 10子集作为训练集,按照上述步骤训练GMM-CGAN模型。训练后模型中的生成器生成的3个数据集上的新样本与原样本对比如图8所示。 图8 GMM-CGAN的生成器生成结果 3.4.1 CNN结构参数设置及卷积操作可视化 GMM-CGAN模型的性能体现在其增强后的样本集上,如增强后的样本集训练出的CNN具有很高的分类准确率,那么认为所提模型是高效的。CNN的结构选择是一个重要的问题,因为近年提出的一些高性能CNN模型,例如GOOGLE-NET、 VGG and ResNet等。与传统的CNN相比,这些网络的特殊模块可以一定程度上减弱模型过度拟合数据,例如:残差模块[5]、Incepetion模块[4]、Dropout层[3]等。 如果使用以上提到的高性能CNN作为测试网络,在分析CNN分类效率时会产生困难,因为无法区分数据增强算法增强对分类结果的影响还是这些网络的结构使然。 综上,自定义了被称为TestNet的CNN模型,结构如图9所示,可以更加精确比较和分析不同数据增强算法应用到浓雾天气形势图集的数据增强的效果。 图9 TestNet的数据流图 该模型共有3个卷积层,其中第一卷积层(C1层)中的卷积核尺寸为5×5,第二卷积层(C2层)和第三卷积层(C3层)的卷积核尺寸为3×3,卷积核选择尺寸较小利于减小网络的复杂度;三层卷积层的卷积核尺寸由大变小的目的是为了先总体后局部的学习样本特征;设置多个不同的卷积核有利于网络学习样本图像中不同的特征,卷积操作后生成的图像被称为特征图,C1层共有96个特征图, C2和C3分别有256和384个不同的特征图, 网络具体的结构参数设置如表3所示。 选择ReLu函数为网络的非线性激活函数,如式(12)所示: fReLu=max(0,x) (12) ReLu函数与其他非线性激活函数[13]相比,具有计算简便、不易发生梯度爆炸等特点;在卷积层后设置下采样层,用于减少CNN整体的参数量。TestNet的其他训练参数如下,输入图像尺寸为56×56,训练批次(Batch)为50,最大迭代次数设置为1 000,损失函数为交叉熵,梯度优化算法是Adam算法。 为了观察逐层卷积后的特征图,每一层卷积后图像的输出结果,如图10所示。 表3 TestNet的结构 3.4.2 对比实验设计及评价指标 为了对比所提GMM-CGAN模型与传统数据增强算法的增强效果,设计了其他3个对比实验,其中一个为空白对照组,即不使用数据增强算法(None),其余对比实验的数据增强算法为仅使用仿射变换、仅使用CGAN。将在不同数据集上,实现这4个实验。在相同数据集上,除各个实验使用的数据增强算法不同,训练集、测试集中的样本数量相同等其余控制变量均相同。实验环境的配置如下,硬件方面:CPU是Intel Core i7 9280,内存为16 GB DDR4,GPU采用的是NVIDIA GTX1080。软件方面:操作系统是Windows 10 64 b版本,实现的平台是基于Python的Tensorflow框架,其中有CUDA9.1以及CUDNN7加速包的支持。 图10 各个卷积层的输出结果 利用数据增强后的数据集训练TestNet,针对网络的分类结果,以平均分类正确率和过拟合比评价数据增强算法的性能。对于数据集中某一类图像的正确分类情况,定义了分类正确率如式(13): Acc=images_correct/images (13) 其中:images_correct表示在该类中网络分类正确的图像数量,images表示该类中图像的总数。 对包含n类的样本集,定义了平均分类准确率如式(14): (14) 其中Acci表示第i类的分类正确率。 反映CNN是否过拟合训练数据的指标为过拟合比(OverfitRatio),其定义如式(15): OverfitRatio=Train_AvgAcc/AvgAcc (15) 其中OverfitRatio中的Train_AvgAcc表示用训练后的网络测试原训练集的平均分类正确率。 表4记录了在3个数据集上分别实现4个实验,共12个实验的平均分类正确率及过拟合比。 图11按数据集展示了在该数据集上实验的平均分类正确率随迭代次数增加的变化趋势,未使用数据增强算法的实验组,在各个数据集上平均分类正确率最低;使用所提GMM-CGAN的实验组,在各个数据集上平均分类正确率最高。过拟合比是反映模型过拟合数据程度的指标,过拟合比越低模型的泛化性越好,反之泛化性越差。表4展示了12个实验的过拟合比,因未使用数据增强算法的实验组中训练样本的相似度较高,所以过拟合比最高;其中使用所提的GMM-CGAN的实验组过拟合比最低,说明所提模型提升数据的多样性最高。 图11 不同增强算法在各数据集上的正确率曲线 综上所述,所提的GMM-CGAN模型具有收敛快,在相同迭代稳定后平均正确率高的特点。 使用真实数据的实验证明所提模型是可靠的、高效的。 表4 各数据集增强后的分类结果 本文所提的GMM-CGAN模型,在原有浓雾天气形势图基准集的基础上有效扩展了浓雾天气形势图数量,解决了浓雾天气形势图基准集因数据量偏小无法有效训练CNN的问题。 GMM-CGAN方法生成的新数据集所训练的CNN, 其平均分类准确率达到89.1%,证明GMM-CGAN方法及所训练的CNN架构性能均高度可靠。未来工作将进一步研究其他类型小数据集场景(如数值型小数据集的增强)的增强模型。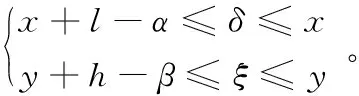
3.3 基于GMM-CGAN模型的数据增强


3.4 增强后数据集的CNN分类

3.5 实验结果分析与评价
4 结语
