融合微博情感分析和深度学习的宏观经济预测方法
2018-12-14赵军豪李玉华李瑞轩辜希武
赵军豪,李玉华,霍 林,李瑞轩,辜希武
(1.华中科技大学 计算机科学与技术学院,武汉 430074; 2. 广西大学 中国-东盟区域发展协同创新中心,南宁 530004)(*通信作者电子邮箱idcliyuhua@hust.edu.cn)
0 引言
经济预测方法的研究经过多年的发展,已经出现了大量的预测模型。这些模型分为两大类:一种是基于时序的方法,主要包括移动平均法、趋势外推法等;另一种是基于因果的方法,主要包括回归分析、马尔可夫预测、人工神经网络等;另外深度学习的发展使得复杂系统的拟合更加准确。互联网的快速发展和中国网民的快速增加,使得人们产生信息和获取信息的方式和规模都发生了变化,使用互联网数据进行预测模型的修正成为研究的热点,已经有不少研究证实实时的互联网数据能够用于经济活动预测,并且起到积极的作用。
本文的主要贡献如下:
1)提出了一种融合微博情感分析和深度学习的预测方法SA-LSTM(Long Short-Term Memory based on Weibo Sentiment Analysis), 该方法利用微博解决统计数据的滞后性问题,利用长短期记忆(Long Short-Term Memory, LSTM)及其变形构建多层神经网络来拟合具有时序关系的复杂宏观经济系统。
2) 在不同数据集上,利用差分自回归移动平均模型(Autoregressive Integrated Moving Average model, ARIMA)、线性回归(Linear Regression, LR)、反向传播神经网络(Back Propagation Neural Network, BPNN)、LSTM网络和SA-LSTM分别进行实验,实验结果表明,SA-LSTM能够明显减小预测的相对误差,有较强的泛化能力。
1 相关工作
国内外有很多对宏观经济预测的研究。传统的经济预测方法,比如ARIMA、线性回归等,存在很大的局限性:ARIMA要求时序数据是稳定的,或者差分后是稳定的; 线性回归对复杂的非线性系统拟合能力较差。针对宏观经济预测中复杂非线性关系,对非线性系统拟合能力强的神经网络模型成为国内外宏观经济预测研究的热点[1]。利用BPNN建立预测模型的研究有很多:孙安黎等[2]基于BPNN构建输电线工程造价预测模型,利用少量样本即能够准确地估计工程造价,适用于工程前期对比方案的优劣; 赵海华[3]结合径向基(Radial Basis Function,RBF)神经网络以及无偏灰色模型(Grey Model,GM)建立灰色 RBF 神经网络预测模型,并通过对安徽省财政收入数据进行预测分析,发现用该模型训练不仅收敛速度快、泛化能力强,而且模型精度较高; Akbilgic等[4]提出了一种混合径向基神经网络,该网络整合了岭回归、回归数和径向基神经网络,通过对股票指数的日均走势预测实验证明了该网络在变量间具有复杂的非线性关系以及具有相互依赖性时有较好的效果。经过多年的研究和发展,人工神经网络及其各种改进模型仍然不能完全摆脱其易陷入局部最小值的缺陷,不能反映样本之间的时序关系;然而这种时序关系在经济领域普遍存在,对于预测分析有很大的帮助。与此同时,深度学习中LSTM在预测领域表现出极其出色的对时序数据的处理能力。陆泽楠等[5]结合近几年钢铁交易价格的走势数据,训练LSTM模型,并与支持向量回归模型对比分析,发现LSTM 神经网络可以更精确地预测钢铁的价格走势;李浩等[6]用深度学习对我国1980~2015年国内生产总值(Gross Domestic Product, GDP)数据建立预测模型,结果表明,基于深度学习的预测精度显著高于ARMA、LR、指数回归;Fu等[7]针对交通流的随机性和非线性特征,使用LSTM和门控循环单位(Gated Recurrent Unit,GRU)神经网络方法来预测短期交通流量,实验证明基于递归神经网络的深度学习方法 LSTM和GRU的表现优于自ARIMA模型。
在互联网快速发展的今天,互联网非结构化数据成为提高预测精度的积极补充[8]。陈卫华等[9]利用深度学习和股吧发帖数增长率数据对沪深300指数波动率进行样本外预测,研究发现深度学习预测效果明显好于选取的其他对比模型,另外股票论坛数据对提升波动率预测精度有所贡献;刘涛雄等[10]在政府统计变量的基础上,增加互联网搜索行为变量进行GDP的预测,发现互联网搜索行为可以提高预测精度;Huang等[11]提出了一种基于百度指数预测旅游流量的新方法,通过比较是否加入百度指数,发现游客人数与百度指数中的一组相关关键词之间存在长期均衡关系和Granger因果关系,且百度关键词搜索指数与日益增长的观光客流量呈正相关关系; Yao等[12]通过将谷歌指数作为一个外生变量纳入ARIMA和自回归移动平均线来研究谷歌指数对原油价格的影响和预测能力,实验结果表明,谷歌指数原油价格有负面影响,有助于提高模型预测能力。
根据以上分析,本文结合互联网微博数据以及 LSTM网络提出的SA-LSTM宏观经济预测方法,不仅解决了统计数据的滞后性问题,而且能够很好地拟合宏观经济系统中的非线性关系和时序关系。
2 SA-LSTM模型结构
本章主要介绍SA-LSTM模型结构。首先描述了宏观经济预测系统的特点,然后介绍了模型的主要构成LSTM及其特点,接着讲述了如何利用微博进行预测分析,最后给出了SA-LSTM模型具体结构。
2.1 宏观经济预测系统特点
在宏观经济预测中,数据具有这样的特点:
1)可供训练的样本太少。各个经济指标的统计一般以季度或者年为单位,而且国家有明确且完整记载的数据只有十年左右。
2)样本间具有一定的时序关系。经济的发展具有一定的规律,统计数据能够在一定程度上反映未来的经济情况。
3)统计数据滞后。宏观经济预测一般是以季度或者年为单位的,对于突发情况,统计数据不能够及时反映。
4)经济的发展具有阶段性,特别是进入21世纪以来,经济发展可谓是日新月异。当前年份经济的发展状况更多地受距它较近年份的影响,较远年份的影响小。
根据宏观经济预测系统的特点,本文通过融合微博情感分析和多层LSTM网络来构建预测模型,从而很好地解决该问题。
2.2 SA-LSTM网络简介
RNN(Recurrent Neural Network)是一种循环神经网络,它的一个很大的特点是在训练和预测时加入了时间的概念,即本次输出的计算会受到前一次输出结果的影响,所以在模型结构上,与BPNN最大的不同点在于隐含层节点之间是有连接的,每一个隐含层节点的输入既包含了输入层的输入,又有来自上一时刻隐含层的输出。
传统的RNN模型一个很大的问题是会出现梯度消失和爆炸的情况,其原因在于在梯度下降过程中,每一层误差反传都会引入乘子,所以导致经过多步之后,乘子的连乘会导致一系列麻烦。
LSTM神经网络对RNN的改进在于对神经元的改变,如图1所示。在这个模型中,常规的神经元被替代为存储单元,每个存储单元包含三部分:一个输入门、一个输出门和一个遗忘门,这个单元保证了误差将以常数的形式在网络中流动;然后在此基础上添加乘法门和非线性函数为模型引入非线性变换,并使得信息有选择性地表达。
2.3 微博情感分析
本节主要介绍微博情感分值的表示方法,以便使之能够参与模型的训练。情感分析的任务目标是能够判断用户情感是积极、消极或是中性的情感,并根据情感的程度给予不同的数值表示。方法主要有两类:一类是基于深度学习的方法,分别在句子级、实体级、篇章级多粒度完整地建立分析任务,这方面的工作比较著名的有百度自然语言处理(Natural Language Processing, NLP)实验室等;另一类是传统的利用情感词典的方法。本文采用基于情感词典的进行规则匹配的方法,后续的工作会利用深度学习的方法进行改进。
基于情感词典匹配的方法主要包含两部分:对中文文本分词和根据情感词典计算微博情感分值。
2.3.1 中文分词
不同于英文以词为单位并且每个词都可以独立地表达一个意思,中文文本以字为单位,然而一个字不可以完整地表达一个意思。在中文中,一句话的意义是通过多个连续的字来传达的,所以这就需要对中文文本进行切分,分成一系列具有独立意义的字符串。通常将此过程称为中文分词。
本文采用中国科学院研发的中文分词系统ICTCLAS2014-JAVA版。一方面考虑到本文实验代码采用Java语言,另外最重要的是经多年积累和验证该分词方法分词速度快,单机速度可达1 Mb/s,分词精度能够达到98%以上, 被很多商业系统所采用。
2.3.2 微博情感分值计算
本文选用基于情感词典的方法计算情感分值。情感词典选取知网发布在2007年10月22日发布的“情感分析用词语集(beta版)”。本文将“正面评价”和“正面情感”同时作为积极情感词,将“负面评价”和“负面情感”同时作为消极情感词。
本文计算微博情感分值的方法是:首先对每一条微博的每一句话,从左向右依次寻找情感词,如果找到,则赋予一定的权值;然后找到该情感词前后修饰情感词的程度副词、否定词,并将它们的权值和情感词的权值进行累乘得到该情感词的加权分值;接着将前面所有情感词的加权分值进行求和;最后分析该句子是否为感叹句或者反问句,如果是则将上面的结果乘以感叹句或者反问句的权值,得到本句话的情感分值。将每条微博内每句话的情感分值求和即得到每条微博的情感分值。
因为本文实验的数据样本是以季度为单位的,所以对每个季度所有微博的情感分值求算术平均值。
一条微博内每句话的情感分值计算如式(1):
(1)
其中:Non为否定词权值,Seg为情感词的权值,Lev为程度词的权值,n为修饰当前情感词的程度词的个数。
一条微博情感分值计算如式(2)所示:
(2)
其中:sen为本句话在句型上的权值,m为该条微博情感词的个数。
2.4 SA-LSTM模型结构
根据宏观经济预测系统的特点,以及2.1节、2.2节所述的LSTM网络和情感分值的计算方法,本节给出SA-LSTM的具体结构,该模型的具体结构如图1所示。
根据LSTM网络的特点,该模型第一个隐含层的输入包括三部分:政府统计的经济指标、微博情感分值以及上一时间片该隐含层的输出,具体公式如下:
(3)

该模型第2个隐含层的输入包括两部分:同一时刻上一隐含层的输出和同一隐含层上一时间片的输出,具体公式如下:
(4)
该模型的损失函数是预测误差平方和与模型权值参数的平方和之和,具体公式如式(5):
(5)
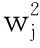

图1 SA-LSTM模型结构
该模型具有以下特点:
1)能够表征时序数据。RNN是专门用来处理时序数据的,其每一个隐含层节点的输入既包含了输入层的输入,又有来自上一时刻隐含层的输出,这使它可以使用先前的信息来学习当前的任务。LSTM网络基于RNN进行改进,在保留上述优点的基础上,使得信息能够保持长时间的记忆。利用该模型能够很好地反映统计数据对未来的影响。
2)融合时效性强的微博文本。微博文本能够实时反映经济发展状况以及社会对于经济发展的舆论倾向,借此来弥补统计数据滞后的缺点。
3)模型层数少。本文使用的LSTM网络只有两层,分别为单向LSTM和双向长短时记忆循环神经网(Bidirectional-LSTM,BLSTM),这使得模型在保留自身特性的同时,降低由于训练样本过少而产生过拟合的风险。
3 实验与结果
3.1 数据集
本文实验所使用数据包括两部分:非结构化数据和结构化数据。
在本文中,结构化数据是指政府机构统计的指标数据。精准的预测结果和合理的预测指标体系是分不开的,想要准确地预测区域未来投资情况,需要有足够而且覆盖范围广但是又不冗余的预测指标,包括经济发展、交通发展、文化教育科技发展、对外贸易和能源等各方面的指标,它们从不同的角度反映了区域经济发展情况。
本文采集的数据来自中国经济网统计数据库,分别采集了河南省、江苏省、上海市、山西省4个省市2012- 01— 2016- 12五年20个季度的数据。在借鉴现有文献研究成果的基础上,遵循指标变量的客观性、代表性、非差异性及可获得性4个原则, 重点考虑东道国的经济发展水平、交通建设、科技发展水平、市场开放程度、能源等影响东道国投资环境的重要因素,构建评价指标体系,具体包含了7个评价指标:地区生产总值、房地产开发企业投资完成额、股票成交额(深圳证券交易所)、运输业固定投资完成额、软件业务收入、进出口总额、发电量[13]。预测目标是固定投资总额。本文以新浪微博作为非结构化数据,因为微博具有的自由、高流动性与时效性等特点能够及时反映社会对经济发展状况的态度。
本文采用的获取微博方法基于Python 语言,Selenium WebDriver 工具编写爬虫程序,自动获得想要的微博文本,其中以河南经济报、新浪江苏城市频道、经济和信息化在线——上海、新浪山西四个公众号所发的微博分别作为河南省、江苏省、上海市、山西省数据集的非结构化数据。时间范围是2012- 01— 2016- 12,一共可分为20个季度,各个季度微博条数如表1所示。

表1 四省市2012 — 2016微博数
3.2 对比分析模型
将预测模型SA-LSTM与以下4种模型进行对比分析:
BPNN 这是一种按照误差逆向传播算法训练的多层前馈神经网络[14]。
LSTM网络 LSTM是一种时间递归神经网络,适合于处理和预测时间序列中间隔和延迟相对较长的重要事件。在本实验中构建的网络结构包括LSTM和BLSTM两个隐含层[15-19]。在实验中,该模型的神经网络部分与SA-LSTM一样,只是没有加入微博情感分值。
ARIMA 该模型是将非平稳的时间序列转化为平稳时间序列,然后将因变量仅对它的滞后值以及随机误差项的现值和滞后值进行回归所建立的模型。在本文中以要预测的投资预测总额作为时间序列[20]。
LR 该方法是利用数理统计中回归分析来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法[21]。
3.3 实验和结果分析
3.3.1 情感分析实验结果
本文非结构化数据的处理是通过2.2节介绍的基于情感词典的微博情感分析方法,计算得到各省市各个季度的微博的情感分值,然后将之作为预测指标,和原指标体系一起进行结果预测。微博情感分值计算结果如表2所示。
3.3.2 预测模型实验对比分析
在本实验中,将2012年第1季度到2015年第4季度的16个季度数据作为训练集,2015年第4季度到2016年第4季度的4个季度的数据集作为测试集。在模型训练阶段,输入为前一个季度的地区生产总值、房地产开发企业投资完成额、进出口总额、发电量、软件业务收入、运输业固定投资完成额、股票成交额(深圳证券交易所)和本季度的微博情感分值,一共8个指标;输出为本季度的固定投资总额。
根据江苏省、河南省、上海市和山西省4个省市2012年第1季度到2015年第4季度的数据,分别训练ARIMA、LR、BPNN、 LSTM和SA-LSTM五个模型;然后使用训练好的模型对2016年第1季度到2016年第4季度进行预测。实验结果如表3。
从表3可以看出,在河南、江苏、上海、山西4个数据集上SA-LSTM预测的平均相对误差都是最小的,与其他4种方法中的最优方法相比,能够分别降低0.06,0.92,0.94,0.66个百分点,实验结果说明本文构建的SA-LSTM模型具有较强的非线性拟合能力,能够很好地对宏观经济进行预测。
本文构建的SA-LSTM模型与LSTM模型相比,SA-LSTM模型加入了微博情感分析来修正模型。通过表3中LSTM与SA-LSTM两列可以发现加入微博情感分析后,平均能够降低相对误差4.95, 0.92, 1.21,0.66个百分点, 微博情感分析对投资预测有积极的影响。
5个模型在4个数据集上预测相对误差的方差如表4所示。

表4 预测相对误差的方差
根据表4可以发现,SA-LSTM在4个数据集上预测相对误差的平均方差是最小的,比ARIMA、 LR、BPNN、LSTM分别低64.41、 56.09、 190.14、 0.52,这表明SA-LSTM预测结果稳定,能够很好地应对突发情况,泛化能力强。
关于使用江苏省、上海市、山西省数据集进行预测时在某一个季度会出现加入微博数据范围误差较大的情况:一方面是因为本文选取的微博数据较少且来源单一,存在一定的局限性,并不能够完全准确地反映所对应省份的舆论情况;另一方面是因为本文在预处理微博时仅仅去掉了非本省份的微博,剩余的微博里依然存在噪声。这两方面都会对预测的实验结果造成影响。
4 结语
对于宏观经济预测系统中建模和预测存在的特点:系统高度非线性、数据样本较少和系统数据存在时滞性,本文从预测模型和数据扩充两个方面进行改进,提出融合微博情感分析和深度学习的新的预测方法——SA-LSTM,该方法综合实时性的微博数据和权威网站的统计数据进行实验并与其他四种算法进行对比分析。实验表明融合微博情感分析的深度学习宏观经济预测方法能够有效地对宏观经济进行预测,与ARIMA、Linear Regression、BPNN、LSTM模型相比具有更好的准确性和泛化能力。
本文在算法设计、数据特征上做了相关工作,有较好的结果,但仍存在可以改进的地方:
1)选取更加广泛的互联网数据,而不仅仅是微博数据。并且需要对这些采集到的互联网数据进行更加更加科学的噪声处理。
2)利用深度学习方法进行微博情感分析。基于深度学习的方法,分别在句子级、实体级、篇章级多粒度建立完整的分析任务。这种方法能够更好地捕捉情感极性在前后文表达的信息,效果上相对于传统的方法有很大的提升。
