融合图像语义的动态视频拼接方法
2018-12-10王冬生宋文杰付梦印
杨 毅,王冬生,宋文杰,付梦印
(北京理工大学自动化学院,北京 100081)
0 引 言
随着机器人技术的进步与发展,机器人对于视觉信息的需求越来越高,普通摄像头受限于视场角,全方位相机又存在分辨率过低且拍摄死角较大等问题,而图像拼接技术能够将多个的图像拼接成一幅大视场图像,可以更准确地检测和追踪图像中的目标[1]。视频拼接是图像拼接的技术延伸,其对拼接的实时性、连续性、鲁棒性有更高的要求,在视频监控和无人驾驶系统中有重要的应有价值。
图像拼接作为视频拼接技术的基础,按照拼接模式可以分为两类。第一类是以文献[2]为代表的通过估计全局2D投影变形来对齐输入图像的拼接模式[2],该模式主要利用一个全局3×3单应矩阵将多张图像对齐到同一坐标平面[3],并使用多频带融合算法获取大场景拼接图像,但这类方法是基于拍摄内容近似处于同一个平面的假设实现,对于不满足假设的情况,由于全局投影模型不一致,会导致拼接图像出现重影或模糊等问题。第二类是利用多个局部单应矩阵对齐图像的模式[4-9],代表方法是文献[7]在2015年国际计算机视觉与模式识别会议上提出自适应图像拼接方法(adaptive as-natural-as-possible,AANAP)[7],该方法将图像划分为密集网格,每个网格都计算出一个单应矩阵。并将局部单应性与全局相似性变换组合,根据图像目标自动估计出所有参数。这类方法可以允许一定程度的局部视差,但由于引入网格的形变估计,极大增加了计算成本,拼接一张图需要十几秒甚至几分钟,不能直接应用到视频拼接算法中。为了降低拼接的计算成本,本文从当前图像拼接技术出发,将图像分为上下两个半平面,用两个局部单应矩阵拟合,在局部视差允许的情况下,加快算法的处理速度。
目前视频拼接按相机设置和应用场景可以分为3大类,第1类是静态场景下摄像机间几何关系固定的拼接方法[10-11],该类方法由于应用环境比较单一,只需预先标定校准一次摄像机间的位置,然后辅助过渡区域局部融合算法,就能够实现实时的图像拼接。第2类是运动环境下摄像机间几何关系固定的拼接方法[12-14],该类方法同第1类相似,也需要预先标定好摄像机之间的几何关系,但由于应用于运动环境,环境所属平面变化时都会不可避免地产生局部视差。第3类是静态和运动环境下摄像机间相互独立的拼接方法[15-17],该类方法主要应用于非刚性固连的摄像机组,例如手持摄像设备,悬挂式拖车环视设备等,由于输入设备之间的位置关系不确定性,场景投影平面时变性,需要实时校准标定参数。对于手持设备拍摄的离线视频,为了实现更好的拼接效果,视频需作平滑运动轨迹的稳定处理[16]。对于在线拼接方法,由于无法预知相机运动轨迹,很难获取满意的拼接图像,本文采用基于拼接质量反馈的方法优化拼接结果。
图像语义分割技术是指使用一定的分类方法对图像进行像素分类。在深度学习应用到计算机视觉领域之前,人们使用纹理基元森林(texton forest,TF)和随机森林(random forest,RF)分类器进行语义分割,随后提出的卷积神经网络极大地促进了语义分割领域的发展。文献[18]提出了用于语义分割的全卷积网络(fully convolutional networks,FCN),FCN主要使用了卷积化、上采样、跳跃结构等技术,改善了语义分割的结果,将端对端的卷积网络应用到语义分割领域,这使得卷积神经网络无需全连接层即可进行密集的像素分类,使用这种方法可生成任意大小的分割图,在这之后,语义分割领域几乎所有先进方法都采用了该模型。2015年文献[19]提出一种用于图像分割的深度卷积编码器-解码器架构(A deep convolutional encoder-decoder architecture for image segmentation,SegNet),包含一个编码网络和对应的解码网络,并跟随一个像素级别的分类层。编码层由13个卷积层构成,其作用是提取图像特征,解码器网络将低分辨率的特征图谱还原到输入图像的分辨率,可以处理任意大小的输入图像并输出相同大小的分割图。在FCN中,尽管使用了解卷积层和一些跳跃连接,但输出的分割图仍然比较粗糙,SegNet没有复制FCN 中的编码器特征,而是复制了最大池化索引,只存储特征映射的最大汇集指数,这使得SegNet比 FCN更节省内存,效率更高,其在城区场景理解方面效果表现明显,因此本文采用文献[19]提供的SegNet 语义模型对城市环境进行语义分割,图1为语义分割效果图。

图1 语义分割效果图Fig.1 Effect of the Semantic segmentation
综上所述,图像语义分割结果可以提供图像的高阶语义信息,对环境有更高的解析,但该技术还未曾应用到视频拼接领域。为了提高现有视频拼接技术的准确性与鲁棒性,本文提出一种融合图像语义信息的在线动态视频拼接方案。
1 系统框架
为了加快拼接速度,本文采用多线程方式分时并行处理拼接过程,拼接系统由主线程、特征配准线程、特征评价线程3部分组成,系统框架如图2所示。主线程的主要步骤包括:图像预处理、图像降采样、图像语义分割、单应矩阵预测模型更新、拼接质量优化、图像融合等。其中图像预处理是指利用改进的张正友棋盘格标定算法[20]校正原始图像的图像畸变;图像语义分割前需要先将原图降采样到360×480大小,然后利用语义模型(本文采用文献[19]提供的SegNet城区语义模型)对图像进行语义分割,可将街道图像像素点分为11类,最后得到与原始图像相同尺寸的语义图,结果如图1所示。在第1次图像畸变矫正后初始化特征配准线程,该线程主要作用是求解拼接所需的单应性投影模型。
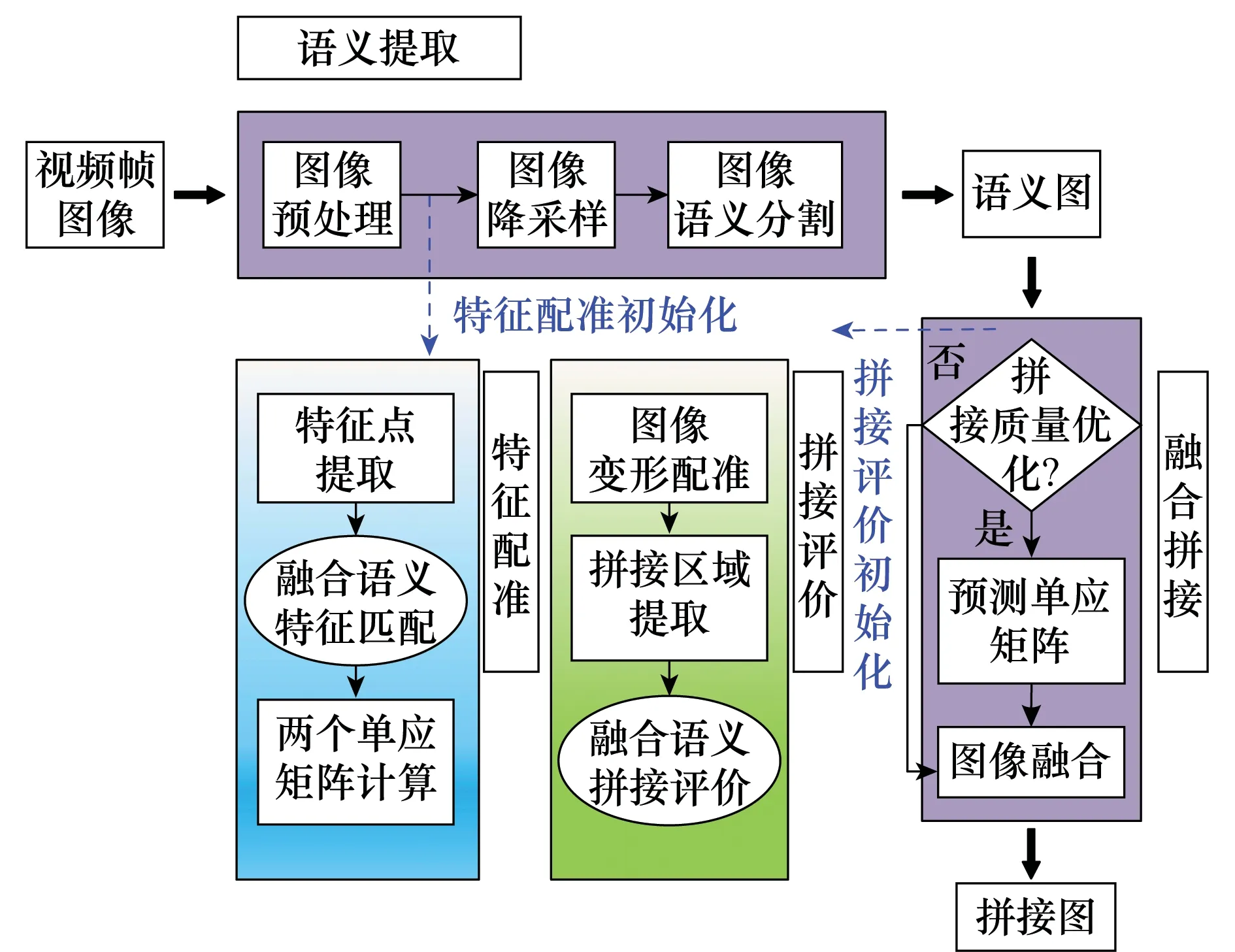
图2 本文视频拼接算法流程图Fig.2 Video stitching algorithm flowchart in this paper
在拼接评价线程中,本文通过投影变换将待配准图投影到参考图平面上,并对两图重叠区域处的语义、纹理、色彩等信息进行相似度分析,获得拼接结果的定量评估。主线程能够实时检测拼接评价线程的量化评价结果,判断是否需要优化拼接,当拼接质量评价结果大于设定的评价阈值Th时融合对齐的图像,最终输出拼接图;否则,利用单应矩阵预测模型预测当前单应矩阵,达到优化拼接结果得目的。当拼接评价线程接收到来自主线程的优化拼接请求时,会利用优化的单应矩阵重新对齐图像。在n次优化尝试后,输出评价质量最高的一组对齐结果。假设单应矩阵在一段时间内是线性变化的,该模型可以表示为
(1)
式中,H(t)表示当前时刻计算出的单应矩阵;HC(t)表示利用模型预测出的当前单应矩阵;score表示拼接评价评估结果;T(l)指第l-1次到第l次单应矩阵计算的时间间隔,本文仅利用最近十次的数据进行预测。
本小节介绍了融合图像语义的自适应动态视频拼接方法系统框架和主线程的主要步骤,提出了利用拼接评价结果实现基于历史拼接信息的拼接参数预测。
2 特征匹配
图像特征匹配,是指利用一定方法将多幅图像的相似特征进行匹配,是图像对齐的前提,匹配的准确度直接影响到图像拼接的质量。
为了解决全局投影模型不一致的问题,本文将图像场景划分为上下两个半平面,分别提取两个半平面(见图3(a))内的特征点,并对特征点进行配准(见图3(b)),计算出相应的两个单应矩阵。

图3 场景局部匹配图Fig.3 Scene partial area matching map
本文匹配流程如图2特征配准线程所示,以图4为例说明。首先使用David Lowe提出的具有尺度不变性的加速稳健特征(speeded-up robust features,SURF)算法提取特征点如图4(a)所示。该算法利用Harr特征以及积分图像加速特征提取过程,能实时提取特征点并为特征点计算位置和尺度信息,最终生成一个64维的SURF特征描述符,包括采用Henssian矩阵获取图像局部最值和利用Harr小波特征求取的特征点的主方向。然后使用快速最近邻搜索包(fast library for approximate nearest neighbors,FLANN)匹配方法直接对原始图SURF特征进行匹配,再使用k-最近邻算法(k-nearest neighbor,KNN)筛选匹配点后的匹配结果,结果显示存在大量误匹配,如图4(b)所示,主要集中在邻域信息相近但语义不同的像素点对之间。
传统方法仅使用特征向量欧式距离的相似度进行匹配,由于没有考虑到点自身的高阶语义属性,不可避免地会产生一些错误匹配,因此本文提出一种融合图像高阶语义的匹配算法,旨在增加匹配正确率。给定红绿蓝通道(red,green,blue,RGB)图像,X={x1,x2,…,xN}对应于所有图像像素的集合,N为图像像素点数量,待配准图与参考图像素集合分别用XM,XR表示。图像语义分割后对原图每个像素指定预定义的类,如图4(c)所示,分割提取的高阶语义信息基本与实际物体所属类别一致,以不同颜色标记不同类像素,标签集合L={l1,l2,…Ij…,lC},j∈{1,2,…,C},C表示对象类标签的个数,由于语义分割的结果存在分类误差,本文用PLj表示像素分割为语义标签j的准确度,表1说明了语义标签的准确度。
图4(d)部分是本文提出的融合图像高阶语义信息图像特征匹配方法在场景I下的效果图,可以看出,本文的方法能够剔除图像中大量的误匹配,提高匹配正确率的同时优化匹配点数量。在分析过程中为了增加实验的可信度本文对包含场景I的5个不同场景进行分析测试。

图4 本文匹配方法效果图Fig.4 Matching method in this paper

表1 文献[19]模型语义标注正确率Table 1 Semantic annotation accuracy of model in[19]
本文使用语义分割产生的像素级语义标签对传统基于特征向量欧氏距离的匹配方法进行扩展,将语义分割结果与图像特征匹配对集合M={m1,m2}相关联,其中m1表示正确匹配对集合,m2表示错误匹配对集合。特征匹配过程表示为
P(mij∈m1)=ω1φij+ω2φ(xi,xj)
(2)
式中,1≤i,j≤N,xi∈XM,xj∈XR;mij为点xi与点xj组成的特征匹配对;当概率P(mij∈m1)大于匹配阈值Mth时认为该匹配是正确的;ω表示各项权值,ω1+ω2=1;φ(xi,xj)表示匹配点对应特征向量欧式距离相似概率;φ表示匹配对属于同一语义分类的概率,表示为
(3)
式中,seg(xj)表示对像素xj进行语义分割后的分类结果,由于匹配点对的语义分割结果同时错误的概率很小,本文仅考虑图像单个像素语义分类误差。匹配点对特征向量欧式距离的相似度可以用匹配点间欧式距离与匹配集合中相关匹配欧式距离集合中次最小值的关系来确定,即
φij(xi,xj)=
(4)
式中,Min2表示取集合中次最小值的函数;Disij为点xi与点xj所组成匹配对的欧式距离,匹配对的欧式距离越近,φij(xi,xj)的值越大,匹配正确的概率越高,欧式距离的计算方法为
(5)

传统匹配方法中仅用到式(5),当最小欧式距离与次最小欧式距离的比值小于设定阈值时,认为特征点与对应的最小欧式距离的特征点是匹配的,但匹配过程仅利用了特征点的邻域点信息,文献[21-22]提出结合图像的红外光优化配准算法,并取得了一定成果,但红外采集设备的引入,带来了数据同步困难和经费成本增加等问题。本文提出的融合高阶语义信息的特征匹配方法能够充分结合图像自身的语义属性,优化配准算法,提高匹配正确率。
3 拼接质量评价
拼接质量评价本质是对拼接图与参考图的重叠区域进行图像相似度评价,传统评价法仅从图像的色彩、纹理等几何特征角度分析,而没有考虑目标的语义属性。本文将图像语义信息与传统的图像几何信息相融合,提出一种融合图像语义的图像拼接质量评价方法,结果更符合人眼实际评价标准,实现流程如图5所示。

图5 本文拼接评价算法流程图Fig.5 Stitching evaluation algorithm flowchart in this paper
本文评价算法主要从图像的纹理、色彩、语义3方面出发,综合考虑图像在这3方面的相似程度,最终计算出更为符合人眼视觉的评价结果Q,图6是一个具体场景下的示意图。

图6 拼接质量评价示意图Fig.6 Stitching quality evaluation
在利用两个单应矩阵变形对齐图像后,分别提取待配准图与参考图中的重叠感兴趣区域(图6(a) Ⅲ区域),用IM与IR表示,然后分别提取图IM与图IR的纹理信息、语义信息、色彩信息等,并计算相似度。其中边缘纹理信息的提取方法是先对原始图进行灰度化处理,按照Y=0.3R+0.59G+0.11B转换方法将三通道的RGB图像转化为单通道的灰度图像。然后采用两个3×3的高斯卷积核对图像做平面卷积处理,得到横向与纵向的亮度差分近似值,再结合横向与纵向的亮度差分近似值计算出图像中每个点的近似梯度,最后,对图像进行二值化处理进而获取边缘检测图[23],其计算过程为
(6)
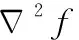
(7)
则重叠率计算方法为
(8)
式中,sum(I)表示图像Ⅰ中所有像素点的灰度值总和,经过计算可以获取IM_D与IR_D边缘纹理的重叠率α(见图6(c))。
经过语义分割图IM与IR后可以获取相应的语义图IM_S与IR_S(见图6(b))。语义分割的结果使得图像中每个像素具有不同的语义强度,但分割结果也存在着分类误差。基于以上信息考虑,图像语义相似度检测方法可参考纹理边缘重叠率的计算方法,求取语义图IM_S与IR_S的相似匹配图IS,过程为
(9)
则相似率的计算方法为
(10)
其中,sum_ele(I)表示图像Ⅰ中所有非零像素点数量总和,经过计算可以获取语义图IM_S与IR_S语义相似度β(见图6(c))。
对于图像来说,色调饱和度明暗通道(hue,saturation,value,HSV)色彩空间比RGB色彩空间更能直观地表达色彩的明暗、色调以及鲜艳程度,面对光照的变化更稳定[24],本文通过研究相同颜色在不同色彩空间下的表征方法,将HSV与CIE 1976(L*,a*,b*)色彩空间相结合对图像的色彩进行分割。为了减少光照以及图像亮度对检测的影响,在色彩分割之前需要对图像IM与IR进行相应的预处理,采用均衡化方法处理图像的RGB通道直方图,加强色彩效果,然后通过对通道H以及通道A、B的颜色信息进行分析如图6(b)所示,计算图像IM与IR的色彩匹配图IC,过程为
(11)
根据物体色彩在图像中平滑过渡的特点,对不同的色彩空间,用高斯核定义HSV的H通道项与LAB通道的A、B通道项,其表达形式为
(12)
式中,H(x,y)表示HSV空间下H通道在点(x,y)处的像素值;A(x,y)与B(x,y)则分别表示LAB空间下A与B通道在点(x,y)处的像素值;σH,σA和σB控制高斯核的影响,其值设定为H、A、B通道的强度变化幅值;每个核l(k)(x,y)由ω(k)加权。计算结果倾向于将相同位置下色彩变化不明显的点作为相似点处理,有助于色彩相似度的检测,最终色彩相似度γ的计算方法为
(13)
由于图像相似程度与图像的纹理、语义、色彩等特征直接相关,因此本文用Q=αβγ表示计算出的图像拼接质量评价结果。
4 实验与分析
本文在Liunx系统下通过c++编程实现了提出的方法,并在配置为2.8GHz CPU、16G RAM 和低耗版GTX-1050Ti的笔记本上进行实验。从融合语义的匹配准确性、拼接质量评价客观性以及自适应拼接的算法效率出发,做了相关的实验。
4.1 融合语义的图像特征匹配
在验证融合图像语义匹配方法的实验中,本文使用文献[5-7]提供的5个场景的图像数据进行特征匹配实验,场景如图7所示。在提取特征之前,本文将图片都转化为640×480大小,本文和文献[17]都采用SURF算法提取图像特征,该算法相比于传统尺度不变特征变换(scale-invariant feature transform,SIFT)方法同样具有尺度旋转不变性,但其计算效率快了一个数量级,能够高效地提取特征。文献[17]匹配的算法采用的是FLANN,结合KNN匹配对筛选算法,匹配结果存在大量误匹配,主要集中在不同类但特征相似的像素点对之间。本文从匹配正确率、匹配数量、匹配时间出发,对文献[17]与本文提出的匹配方法进行对比实验,结果如表2所示,根据调试经验,阈值Dth设为经验值0.7,Mth设为经验值0.8。

表2 5个场景下匹配算法的性能比较Table 2 Comparison of matching algorithms in five scenes
在比较不同特征匹配方法准确度实验中,本文使用随机抽样一致(random sample consensus,RANSAC)算法,通过计算不同投影模型M的投影误差,得到误差阈值范围内的内点集I,通过k次迭代,k=ln(1-p)/ln(1-wm),求取最优投影模型MB使得其内点集中元素最多,式中p为置信度,设为0.999;w为内点所占比例,设为0.3;m为最小样本数,设为4;误差阈值设为3。因此在迭代了850次后,此时在内点集中的匹配点对认为是正确匹配的,通过计算正确匹配点在不同方法产生匹配对集合中所占的比例,得出匹配准确度。表2的结果显示,本文提出的方法与文献[17]中使用的方法相比,获取的匹配对数量相近,但匹配准确性却提高了50%左右,这使得本文的方法在迭代次数相同的情况下能够更准确且快速地计算出图像间的单应矩阵。
由于引入了图像语义信息,图像中大量的误匹配被剔除掉,在提高匹配精度的同时优化匹配点数量,缩短了单应矩阵的计算时间。
4.2 融合图像语义拼接质量评价方法
本文提出的拼接质量评价方法本质是对两幅图像的相似度进行评估,而图像对齐效果直接影响到拼接的质量。单应性是指从一个平面q到另一个平面Q的映射,可以表示为q=sMWQ,式中单应矩阵表示为H=sMW,其中s表示尺度的比例系数;M表示相机的内参数矩阵;W=[Rt]表示由旋转平移组成的物理变换矩阵。实验在大小为1 600×1 200的图像中进行(见图7),选取图8(a)中400×400红色窗口内图像作为参考图,由于相机内参数矩阵在相机标定后不会变化,假设相机内参已经标定。本实验在充分考虑拼接过程中出现误差原因的基础上,对图8(a)中图像在不同尺度、旋转以及平移参数下进行变换,并利用同一位置相同大小的窗口产生3组数量为400的图像序列,过程如图8(b)所示,利用4种图像相似度计算方法进行图像检索实验。

图7 5个测试场景Fig.7 Five tested scenes


图8 生成图像测试序列Fig.8 Generating the image test sequence
除本文方法外,另外3种图像相似度计算方法如下。
(1) 峰值信噪比
峰值信噪比(peak signal to noise ratio,PSNR)是一种全参考的客观图像相似度评价指标,该方法计算的是两幅图像间均方误差相对于最大信号平方的对数值,结果数值越大两个图像间的相似程度越高。
(2) 结构相似性
结构相似性(structural similarity index,SSIM)是一种全参考的图像相似度评价指标,该方法分别从图像的亮度、对比度、结构3方面度量图像相似性[25],更符合人眼视觉感受。
(3) 感知哈希
哈希方法描述了一类可比较的哈希函数,该方法提取图像的低频信息作为比较内容,对图像的尺寸、对比度、亮度具有良好的鲁棒性[26]。
在相似度评价实验前,先将图8所示的3组图像序列做高斯滤波和亮度变暗处理,模拟实际拼接过程中投影变换带来的边缘模糊以及曝光不均匀造成的亮度差异的情况。为了方便比较,本文将4种评价方法的结果进行归一化处理,最终结果如图9所示。

表3 4种评价方法耗时Table 3 Time-consuming of four evaluation methods
本实验对3组不同变换方式产生的图像序列与参考图进行相似度评估。图9结果显示本文提出的方法相对于感知哈希算法鲁棒性更强,相对于PSNR方法评价结果区分更明显。本文方法和SSIM方法都能够很快地收敛到真值附近但本文算法评价结果随图像差异变化过渡更符合人眼视觉。表3显示的是4种算法在处理大小为400×400图片过程中的平局处理时间,结果显示感知哈希算法结果最快,而SSIM由于其计算量大,每个过程需要267 ms,本文提出的方法则只需要82.6 ms,满足实时处理的需求。综上所述,本文提出的基于图像语义的拼接质量评价方法在评价结果以及处理耗时方面表现良好。
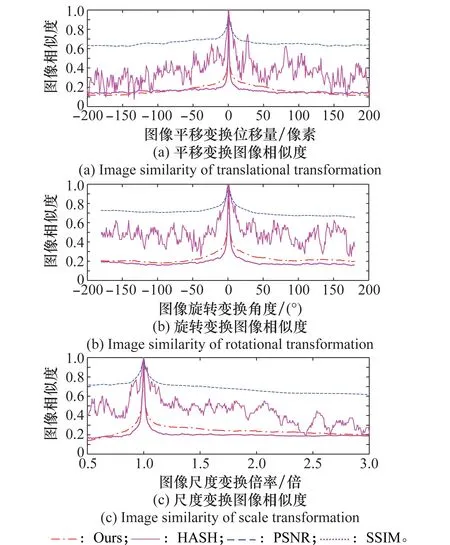
图9 4种评价方法测试结果Fig.9 Test results of four evaluation methods
4.3 自适应动态视频拼接方法
本实验的数据由安装在红旗H7上的两个摄像机拍摄得到,实验平台如图10所示,摄像机采用的是菲力尔公司推出的Flea3系列相机,该相机能以60每秒传输帧数(frames per second,FPS)的速度采集分辨率为1 280×1 024的图像,为了加快处理,本文将视频帧压缩到640×480。图10所示的两个摄像机采用非刚性连接,其中左侧摄像机与车体固连,右侧摄像机可以多自由度运动,模拟两个摄像机相对位姿不固定的情况。测试地点选在北京理工大学中关村校区,测试环境如图11所示,环境既包括静态背景也包括车辆行驶中产生的动态背景,在获取视频过程中加入了人为对摄像机位姿的扰动,此时有来自两个方面的因素会导致拼接参数的更新:①摄像机间相对位姿的变化;②由于场景移动导致视场中投影平面的变化。拼接的过程是按照第1节提出的拼接框架进行,以拼接质量评价结果作为反馈,进而优化拼接结果,使得结果尽可能达到本文设定的拼接评价阈值Th,本实验设定阈值Th为经验值0.7。

图10 实验平台Fig.10 Experiment platform
本实验在图11所示的校园环境采集2 205张视频序列做测试。为了测试程序的鲁棒性,测试时车辆以10 km/h的速度行驶,拍摄环境有特征丰富的地面与建筑,也有特征缺失的墙面,相机的相对位姿也在动态变化,使得重叠区域有超过整张图像二分之一的序列也有低于五分之一的序列,图12是从视频序列中抽取的4张拼接结果图,其中左侧为使用本文提出的视频拼接方法所生成的效果图,右侧为使用文献[17]视频拼接方法所生成的拼接效果图。

图11 实验环境Fig.11 Experimental environment

图12 视频序列拼接效果图Fig.12 Video sequence stitching effect
图12结果显示在相机重叠区域有限,相机位姿差异明显,测试环境复杂等情况下,本文算法仍能很好地计算出吻合程度较高的拼接图。本文采用多线程编程方式将视频拼接部分为主线程、特征配准线程、拼接评价线程等,使得算法能够以约2帧(537 ms)的速度拼接运动场景下的视频帧,其中语义分割耗时占总耗时的80%左右。
本文采用所提出的拼接质量评价方法对两种拼接方法下视频序列的拼接结果进行评估,评估结果如图13所示。

图13 视频序列拼接评价结果Fig.13 Stitching evaluation result of video sequence
图13实验统计结果显示,本文拼接方法评价均值为0.664 9,文献[17]拼接方法的评价均值为0.534 7。在一些视频序列中,文献[17]拼接方法的拼接结果评价过低,其原因主要有3种可能:①参考图与待配准图视野重叠区域过小。由于摄像机组加入相对位姿的动态调整,导致某些摄像头相对位姿下的视野重叠区域过小,其特点是存在时间较长且评价结果接近于0。②参考图与待配准图重叠区域特征缺失。由于参考图与待配准图重叠区域特征单一且稀疏,导致拼接结果有局部投影误差,其特点是存在时间较短但评价结果不会太低,可以通过本文提出的基于反馈的拼接模式优化。③测试环境中摄像机距离前景目标较近,视差过大。其特点是存在时间短且评价结果急骤下跌;本文提出的带有拼接质量反馈的自适应动态视频拼接方法能很好优化这些问题。综上所述,本文视频拼接方法相比于文献[17]提出的拼接方法,拼接质量提升了24.35%,在一些复杂环境下拼接结果更为鲁棒。
5 结 论
现有的视频拼接方案大多基于图像的低阶几何特征实现,而没有考虑图像像素自身的高阶语义信息,并且拼接过程都是单方向。为了减少匹配误差、提高拼接精度,本文提出一种融合图像语义的自适应动态视频拼接方法,其重要优势在于:①该方法将图像像素点的语义信息融合到传统基于特征向量欧式距离的匹配方法中,利用图像的多种属性对特征进行匹配与筛选,提高算法对错误匹配点的鲁棒性;②该方法包含一种图像拼接质量评价方案,即充分考虑图像间纹理、色彩、语义等信息的相似程度,更贴合人眼的主观感受;③该方法在视频拼接过程中引入了拼接结果的反馈,能够根据拼接的历史信息优化特征缺失情况下的拼接结果;④该方法采用多线程编程的方式分时并行处理拼接过程,加快拼接过程。实验结果显示,相比于传统算法,本文提出的匹配算法正确率提升了50%左右,拼接评价算法更符合人眼视觉,拼接质量提升了25%左右。但本文的方法由于引入了图像的语义分割,降低了算法的实时性,在未来将着重改进现有的语义分割模型,使得语义分割更加高效准确,进而提高融合图像语义视频拼接方法的准确性与高效性。
