一种高吞吐率的系统Raptor码并行译码方法
2018-12-06任雁鹏梁利平
任雁鹏,管 武,梁利平
(1. 中国科学院微电子研究所 北京 朝阳区 100029;2. 中国科学院大学微电子学院 北京 怀柔区 100049)
数字喷泉码技术以其高性能的纠错能力,得到广泛的青睐。其中的低复杂度码型——系统Raptor码[1-2],更是广泛应用于无线传输领域[3-5]。系统Raptor码在编码时,对源数据包增加少量冗余包;在译码时,通过接收到的源数据包和冗余包纠正传输过程中的丢包,实现数据恢复。这种以包为单位的纠错方法,具有较高的吞吐率和较低的复杂度,在高速数据传输中优势明显。
随着超高清、3D视频以及海量数据的高速传输,未来无线数据传输吞吐率将达到1 Gbps以上。然而,当前3GPP标准(3rdgeneration partnership project)中采用的系统Raptor码技术,速率还在100 Mbps量级,已经无法满足高速传输的需求。需要更高速率的系统Raptor码编码译码技术。
目前,许多学者都在进行系统Raptor码的改进和优化。文献[6]发现系统Raptor码运算耗时最大的部分为译码中的高斯消元运算,其占整个译码总时间的91%以上;并提出优化失活译码高斯消元算法,将传统高斯消元算法中矩阵求逆的计算复杂度由O(L3)降低至O(L),其中L为与源数据包数量相关的参数。矩阵递归求逆译码算法[7]和矩阵降维快速译码算法[8]基于系统Raptor码的部分码——系统RaptorQ码,实现了软件优化,但速率较低。文献[9]采用CPU(central processing unit)+GPU(graphics processing unit)的模式进行系统Raptor码并行加速,使无线数据传输吞吐率达到21 Mbps。文献[10-11]则采用FPGA(filed programmable gate array)进行高斯消元运算的硬件加速,进一步提升吞吐率。
上述方案针对高斯消元运算的改进和优化,使译码性能得到了提升。但是,其译码过程中,高斯消元运算需要译码出所有源数据包,译码运算复杂度大、串行依赖度高,无法大幅降低译码延时,提高译码吞吐率。实际上,数据传输中仅存在少量丢包;如果能够只对丢失的少量数据包进行译码,则可大大降低译码复杂度。本文经过对译码过程的分解,提出了一种低复杂度的降维译码算法。该算法仅对丢失的数据包进行译码,并采用全并行的硬件加速结构,实现低延时高吞吐率的系统Raptor码译码器。
1 系统Raptor码编译码原理
系统Raptor码的编译码原理如图1所示。发送端,编码器对源数据分别进行预编码和LT(Luby transform)编码,生成编码数据。编码数据包含所有源数据和少量冗余数据。编码数据经物理信道发送给接收端。物理信道呈删除信道的特征,会有少量编码数据的丢失。接收端,译码器对接收到的数据包进行预译码和LT译码,纠正信道中丢失的数据包,恢复出所有的源数据包[1]。

图1 系统Raptor码编译码原理图
1.1 系统Raptor码编码
系统Raptor码编码时,首先,源数据包T=[t0, t1,…,tK-1]和零矩阵Z1×(S+H)构成预编码输入矢量D=[Z1×(S+H), T]T,其中K为源数据包的数量,S和H分别为预编码参数,由K计算得出。输入矢量D与预编码矩阵的逆矩阵A-1进行二进制乘法,生成L个预编码码字C=[c0, c1,…, cL-1]T,其中L=K+S+H:

然后,进行LT编码,生成编码码字E=[e0, e1, …,eN-1]T:

式中,GLT是一个N×L的矩阵,N>K;码字E包含K个源数据包和N-K个冗余包。
1.2 系统Raptor码译码
接收端,首先进行预译码。译码端接收到Nr个码字E′=[e′0,e′1,…,e′Nr-1](K<Nr≤N)。E′和零矩阵Z1×(S+H)构成预译码输入矢量D′=[Z1×(S+H), E′]T。根据接收码字的ESI(encoding symbol ID,编码符号索引号),重建与E′对应的预译码矩阵A′M×L,其中M=Nr+S+H。A′M×L的行数M跟列数L不相等,无法进行求逆运算。在计算预译码码字C'=[c′0, c′1,…, c′L-1]T时,需通过高斯消元法进行运算:

然后,进行LT译码,得到所有源数据包T:

式中,GL′T是一个K×L的矩阵,根据已接收冗余包的ESI构建。
传统系统Raptor码的译码结构如图2所示。接收端首先接收编码码字,并根据ESI构建 AM′×L和GL′T。然后执行高斯消元的预译码和LT译码,得到所有源数据包。预译码和LT译码串行执行。

图2 系统Raptor码译码串行执行结构
在译码过程中,高斯消元需经过逐行列的递进处理,串行依赖性高,运算复杂度为O(L3)[12]。即使采用硬件加速,也只能对局部运算并行实现,降低译码延时的效果有限。而且随着K的增大,高斯消元运算的复杂度大幅增长,严重影响译码延时和吞吐率。
2 系统Raptor码降维译码算法
传统系统Raptor码译码延时大,无法满足未来无线传输高吞吐率的需求。在实际中,接收数据仅存在少量丢包。只要译码出丢包数据,即可完成纠错。本节对传统系统Raptor码译码算法进行分解,结合系统Raptor码编码的已知矩阵,提出低复杂度的降维译码方案,降低译码延时。
根据式(1)与式(2),系统Raptor码的编码可表示为:
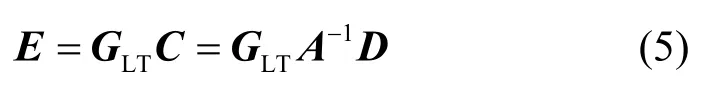
经过删除信道丢包后,接收端共收到Nr个编码包,其中包含Kr(Kr≤K)个源数据包Tr=[t′0, t′1,…,t′Kr-1]和Nr-Kr个冗余包R=[r0, r1,…, rNr-Kr-1]。丢失的K-Kr个源数据包记为Tx=[tx0, tx1,…, txK-Kr-1]。
在式(5)中,当有丢包时,实际接收的数据包构成E ′。根据实际接收冗余包的ESI重新构建LT矩阵为GLT″。输入矢量Drx由零矩阵Z(S+H)×1,TrT和TxT构成,其中Tr和Tx中的各元素根据ESI置于Drx的相应位置。式(5)变换为:

式中,GL′′T是一个Nr×L的矩阵;Drx是一个L×1的矩阵。
式(6)对输入矢量Drx中的源数据包进行分解,拆分成两个输入矢量Dr0和D0x。Dr0和D0x都是L×1的矩阵。Dr0包含所有已接收的源数据包,其中丢包的地址用0填充。D0x为待求的丢包矩阵,D0x中对应已接收数据包的地址都为0。式(6)分解为:

进一步变换,得出系统Raptor码的降维译码公式为:

当网络丢包率较低时,丢包数量远小于源数据包数量K。D0x中待求的丢包元素很少,求解D0x可实现系统Raptor码的降维运算。另外,在式(8)的运算中,使用预编码逆矩阵A-1替代预译码矩阵A′M×L,避免了对A′M×L的高斯消元运算,大幅降低运算复杂度和译码延时。
对式(8)的各项进一步分解:

其中:

由式(9)可以看出,根据实际接收的数据E′、参数A″和Y,即可求解出丢失的数据D0x。在译码过程中,对于给定的K值,A-1为已知矩阵;对于A″和Y,可根据已接收的源数据包Dr0和冗余包进行并行运算得到。
经过对传统系统Raptor码算法的分解,仅对丢失的数据包进行译码,实现降维运算。运算中使用已知的预编码矩阵A-1替换原始的预译码矩阵A′M×L,避免了复杂的高斯消元运算。实现了低复杂度的降维译码,降低了译码延时。
3 系统Raptor码降维并行译码实现
结合系统Raptor码的降维译码算法,本节给出低延时的降维并行译码结构,如图3所示。译码主要包括3个运算模块:源数据包处理模块、冗余包处理模块和丢包计算模块。源数据包处理模块对式(12)进行运算。根据已接收的源数据包,计算得出矩阵X中的元素。冗余包处理模块根据已接收的冗余包构建LT译码矩阵GL′′T,并计算式(10)和式(11)中 ′′A和Y中的元素。然后根据式(9)计算丢包D0x,完成整个译码过程。在该结构中,所有接收到的源数据包和冗余包并行处理,降低运算延时,提高译码吞吐率。
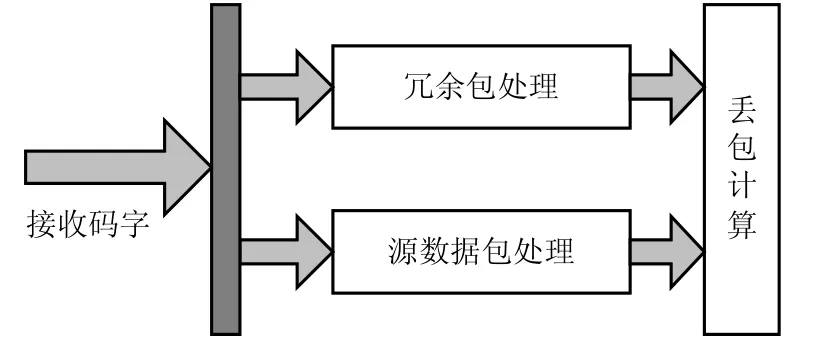
图3 系统Raptor码降维并行译码结构
根据图3的降维并行译码结构,设计系统Raptor码的全并行硬件结构,如图4所示。在系统Raptor码中,对于给定K值,其A-1为确定的,可以将A-1预先存储在寄存器中。冗余包处理模块处理接收到的冗余包,源数据包处理模块处理接收到的源数据包,最后计算丢包。所有接收的数据包存入寄存器中。下面对各模块的运算做具体说明。

图4 系统Raptor码全并行降维译码硬件结构
3.1 源数据包处理模块
首先将接收数据包根据ESI存储到E′的对应位置。发送端发送完一组数据后,接收端根据ESI查询源数据。如果全部接收则不需译码;如果存在丢包,则保存丢包的ESI并等待恢复。
然后利用接收的源数据包计算矩阵X。根据接收包的ESI查找A-1对应的矩阵行,将A-1与接收包进行与和异或运算,得出X中该ESI对应的值。所有源数据包的运算并行执行,降低译码延时。
3.2 冗余包处理模块
根据冗余包的ESI查找生成矩阵表GLT,将GLT中ESI对应的行组合在一起重新构建LT译码矩阵GL′T。然后根据式(10)和式(11)计算 A ′ 和Y。 GL′T为稀疏矩阵,A-1和 GL′T矩阵都为0~1矩阵。在硬件实现中,将 GL′T矩阵中1对应的地址与A-1中的值进行与和异或运算,计算出译码逆矩阵 A ′ 。同理, GL′T与矩阵X进行运算得到矩阵Y。
该结构可以对所有冗余包并行处理,不需采用串行处理的模式,这样就避免了类似高斯消元中逐行列串行处理的耗时。
3.3 丢包计算模块
接收端收到Nr个接收包时,查询ESI并确定丢包位置,计算丢包。根据式(9),使用矩阵Y、 A′′和E′计算丢包矩阵D0x。
在系统Raptor码全并行的降维译码硬件结构中,所有已接收的源数据包和冗余包并行运算,源数据包处理模块和冗余包处理模块并行执行,可以在很少的时钟周期内计算出所有丢包,大幅降低了译码延时,提高译码吞吐率。
4 性能仿真及比较
结合本文提出的全并行降维译码方案,在Xilinx Kintex-7系列的410T FPGA芯片实现系统Raptor码译码器。源数据包数量K取216,网络丢包率为10-2量级,单个数据包的位宽W为4 Byte。采用Xilinx软件平台进行硬件综合和功耗估计,结果如表1所示。其中逻辑单元需67 539个,占芯片总资源的26.5%,最高运行时钟为128.2 MHz,功耗为1 155 mW。

表1 系统Raptor码译码器的硬件开销与性能
4.1 译码延时比较
在本文提出的降维译码方案中,当K为216时,根据网络丢包率得出编码包数N为230。经仿真,对源数据包和冗余包的并行处理,最多仅需N个时钟周期。对丢包的计算,仅需6个时钟周期。即完成一次系统Raptor码译码共需N+6个时钟周期。
与之相比,如表2所示。文献[11]的译码器采用图2的串行译码结构。源数据包数量K为12,需延时79个时钟周期完成高斯消元运算和LT译码,而且随着K的增大,译码延时大幅增长。本文在K取12时,根据丢包率计算N为14,仅需20个时钟周期可完成译码。而且本文的译码延时随K的变化很小,有效降低了译码延时。
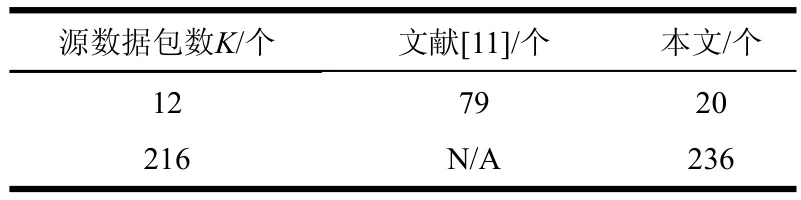
表2 系统Raptor码译码延时比较
4.2 传输吞吐率比较
结合上边的仿真结果,当系统运行时钟fClk取128.2 MHz时,每秒可以完成的系统Raptor码译码次数S为:

则数据吞吐率为:式中,W为每个源数据包的字节数。本文采用W为4字节的Raptor码,译码数据吞吐率可达3.75 Gbps。

本文的硬件方案与相关文献的硬件加速方案的性能比较结果如表3所示。其中文献[9]采用3 GHz的i7 CPU与732 MHz的GPU联合平台,文献[10-11]采用FPGA硬件平台,主要对高斯消元法进行硬件加速实现。
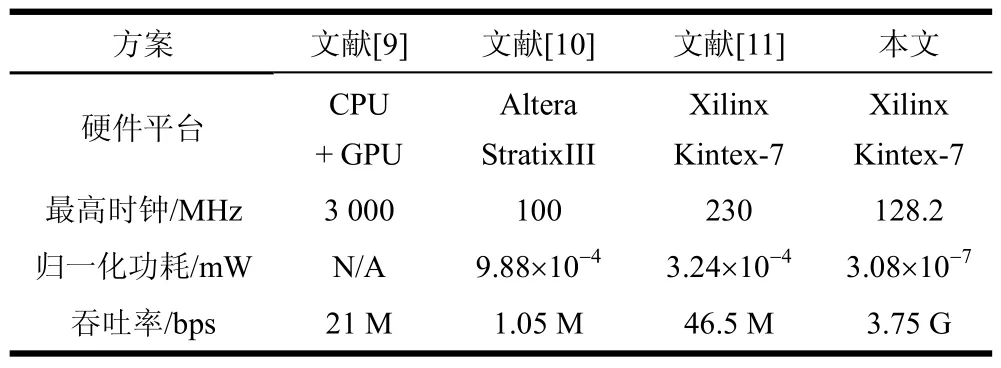
表3 系统Raptor码译码性能比较
从表3可以看出,本文的降维译码方案,仅对丢包进行译码,并且采用已知的预编码矩阵,替代需进行高斯消元的预译码矩阵,避免了对所有源数据包译码的高斯消元运算,实现了低复杂度的降维译码。在全并行降维译码的硬件结构中,所有已接收的源数据包和冗余包并行运算,大幅降低了译码延时。在单位时间内完成更多次的译码运算,实现了高吞吐率的译码和传输。
5 结 束 语
本文对系统Raptor码高复杂度的高斯译码算法进行改进,提出了一种低复杂度的降维译码算法。在该算法中,仅对少量丢包进行译码,替代传统译码算法中对全部源数据包译码的高斯消元运算,实现译码维度的大幅降低。并采用全并行的结构实现降维译码算法,最终在Xilinx FPGA XC7K410T上实现了该译码器。测试结果表明,当网络丢包率在10-2以下时,译码器译码延时大幅降低;其译码吞吐率可达到3.5 Gbps,是相同平台下采用高斯消元译码的80倍以上。该方案有效提高了系统Raptor码的译码效率,降低了译码延时,提高了数据传输吞吐率。
