基于大数据分析的网络异常流量检测
2018-12-03杨青
杨 青
(苏州信息职业技术学院计算机科学与技术系,江苏 苏州 215200)
随着时代的发展,计算机科学与人类的生活越发紧密,高效全能的网络为人们的生活带来便捷。计算机科学对大众的普及,使用户数据量激增,与此同时网络犯罪活动也出现在大众视野中。为保证网络系统的安全性,对基于大数据环境下网络数据的监管是十分重要的[1-2]。
目前,对网络数据进行检测大多基于统计学相关理论进行建模,建模方法直接影响对数据检测效果,用得比较多的方法有两种:神经网络、支持向量机。运用神经网络原理检测数据的众多方法有一个共性,就是要求网络异常数据样本达到一个特定的数量,如果异常样本数量较小则检测效果就不明显。因此采用神经网络原理建模对网络数据进行检测,存在应用范围受限和神经网络结构不确定的问题。支持向量机不存在异常数据样本数量的问题,而且学习效果更好,故在数据流量检测方面应用得更多。
由于网络数据量的激增以及受计算机硬件的限制,传统的数据处理平台已无法对海量数据进行高效、全面的处理,因而云计算平台应运而生。该平台可利用网络上一切可利用的资源,化整为零,将一个大的问题化为若干个小问题予以解决,能高效率地达到目标。目前人们对云计算平台的研究越来越深入[3-5]。
为了取得较好的网络异常数据检测效果,本文利用云计算技术对大数据环境下的网络异常流量检测方法进行研究,并对检测效果进行测试。
1 网络异常流量分类
网络异常流量大致分为以下几种类型:Alpha Anomaly、DDos、Port Scan、Network Scan、Worms和Flash Crowd。对这些典型的异常流量类型的区分可从目的端口总数(特征一)、目的IP地址(特征二)、源端口总数(特征三)、源IP地址(特征四)、流计数(特征五)、字节数(特征六)以及分组数(特征七)等特征来进行区分。各典型异常数据流量类型详细区分特征如下。
1)Alpha Anomaly异常流量:高速点对点的数据传输动作,可通过特征六和七来对其进行检测。
2)DDos异常流量:分布式拒绝服务攻击动作,可通过特征二、四、五、七来对其进行检测。
3)Port Scan异常流量:对主机的非安全区域或者安全性较差区域进行扫描动作,可通过特征三、四、七来对其进行检测。
4)Network Scan异常流量:采用多个网络地址对同一个主机端口进行扫描动作,可通过特征一、二、四、五、七来对其进行检测。
5)Worms异常流量:Worms在事实上属于Network Scan的一种特殊例子,通过本身的安全漏洞来进行复制,可通过特征二、三来对其进行检测。
6)Flash Crowd异常流量:较多数量的不正常用户对访问某一资源的申请动作,可通过特征一、二、四、五、七来对其进行检测。
2 网络异常数据检测大数据分析平台
2.1 大数据分析平台
云计算平台依其良好的实用性和适用性迅速占领市场。目前,市面上的云计算平台种类繁多,其中应用最广的是apache的开源分布式平台Hadoop,它具有价格低、容错性高等优点[6]。Hadoop云计算平台主要由文件系统(HDFS)、数据库(Hbase)、分布式并行计算(Map Reduce)三大部分组成[7-8]。
2.2 Map Reduce过程
作为云计算平台中用于并行处理的核心模块Map Reduce,其作用就是将一个传统的数据处理任务分为多个任务,分散处理,合作完成,以此来提高计算效率。Map Reduce模型结构如图1所示。

图1 Map Reduce模型结构
Map Reduce编程的核心内容是对Map和Reduce函数进行特定动作定义。Map和Reduce函数任务会因动作目的的不同而有所不同,但是核心任务都是对数据值的读取以及运算。Input Format类是作为Map函数的动作基础而存在的,由于Map函数的作用对象是key/value对形式的数据样本,所以Input Format类的主要任务就是将输入样本转换为key/value对。Hadoop云计算平台通过查询,若发现tasktracker模块处于空闲状态时,平台会统一算法调度,把相应的数据Split分配到Map动作中,与此同时也会将Split内所有信息一并上传处理,之后采用create Record Reader方法读取数据信息,并将数据转化为key/value对的形式,为Map操作奠定基础。tasktracker处于工作状态时程序则进入等待[9]。
2.3 基于Hadoop的SVM算法
目前,应用较广的分析软件LibSVM是由台湾大学林智仁教授等开发的,其主要有两个用途:SVM模式识别、回归分析。John C. Platt于1988年提出了SMO算法,通过采用此方法对LibSVM进行了二次规划优化,优化后的LibSVM工作效率更高,尤其在SVM模式识别时求解效果更好,得到了广大学者的一致认可。
随着训练样本基础数据越来越多和训练样本时间呈指数形式的激增,在单机工作的条件下,运用二次规划算法对训练样本进行处理仍较困难。这也是训练样本规模增大带来的问题[10]。
为了攻克这一难题,加快SVM算法的求解速度,笔者对Hadoop云计算平台上的SVM算法进行研究,使其运算效率更高,耗时更短。
SVM算法的核心思想是寻找出每一个训练数据所对应的决策函数,即训练数据的支持向量来对其进行分析。由于支持向量具有稀疏性的特征,并且在整个数据向量集中支持向量所占的比例极少,因此可以以此为突破口,对数据实现并行SVM算法。在计算的整个过程中,并行处理实质上就是对训练数据进行切分,分块采用SVM算法进行求解,以此来实现运算时间的减少,提高运算效率。基于Hadoop的SVM算法示意图如图2所示。

图2 基Hadoop的SVM算法示意图
应用于Hadoop云计算平台的SVM算法主要包含以下几点内容:
1)向平台传递信息。
向Hadoop云计算平台传递信息时,应用SVM算法从文件系统HDFS中获取信息数据,通过数据集群配置技术对信息数据分析处理,同时对工作的Map和Reduce操作过程进行分类处理并输入所有步骤中的节点信息。
2)Map动作过程。
运用Map函数将文件系统HDFS的图像信息样本读入整机系统中时,首先改变block中的文件参数类型;其次通过遗传算法对转换的动作参数进行优化处理;再次运用svm_train函数对数据样本进行分析转换,获得key/value对形式的支持向量;最终将得到的结果传递至Reduce,进行Reduce操作。
3)Reduce动作过程。
运用Reduce函数对上一步Map动作过程得到的支持向量进行分类排序,最终将排序的结果储存到特定的文件夹中[11-12]。
3 实验分析
3.1 实验平台搭建
下面通过实验对本文研究的检测方法以及单机平台进行网络异常流量检测的效果进行对比。
单机网络异常流量检测平台以及基于大数据的网络异常流量检测方法中主机和各个节点均使用相同配置的计算机。
从Mitlincoln实验室和LBNL实验室中调取实测数据作为检测训练的源数据,再从源数据库中选取典型异常流量各200条数据样本,一半作为训练用的数据样本,一半作为测试用的数据样本。
3.2 检测系统测试分析
网络异常流量检测过程如图3所示。
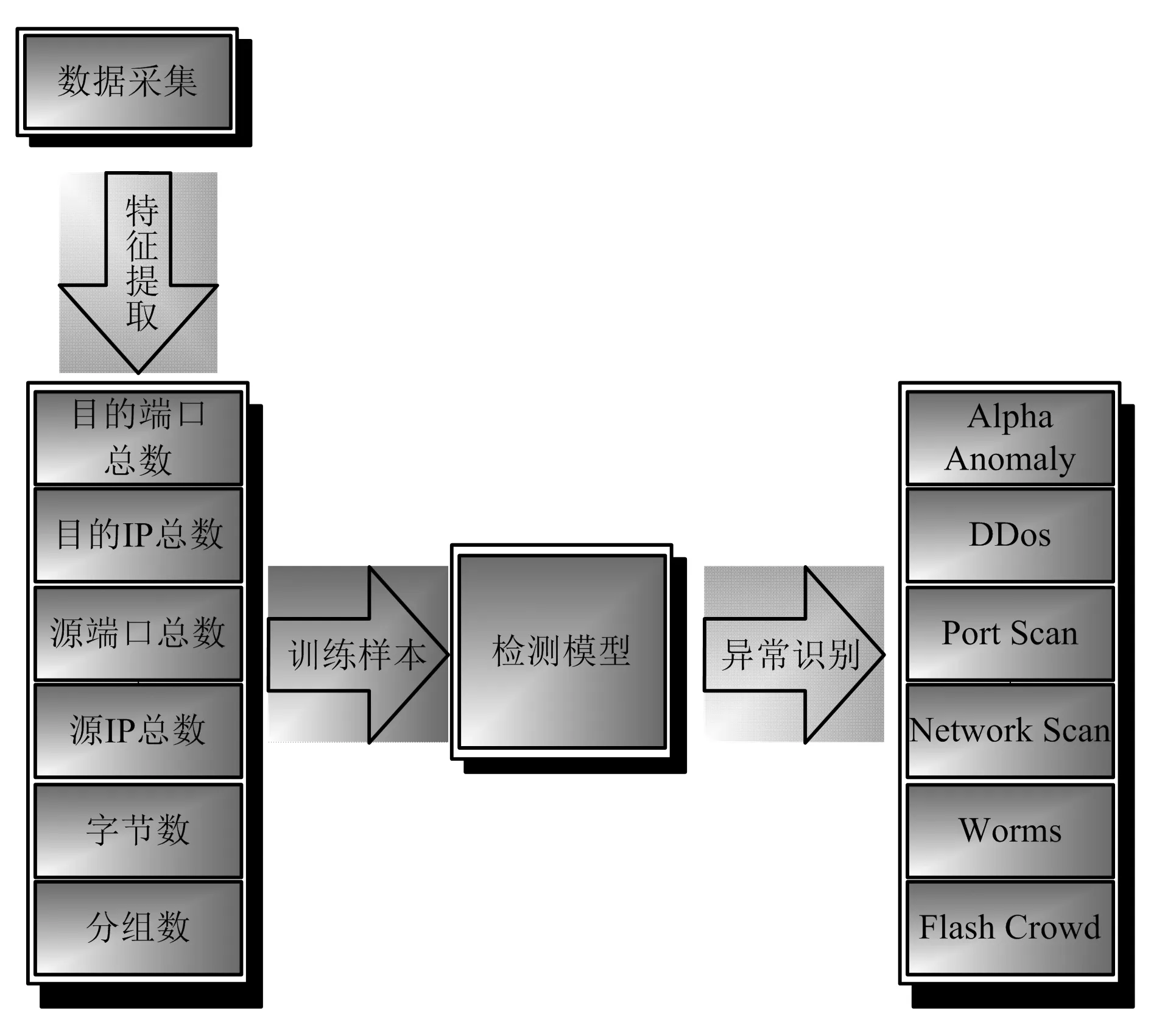
图3 网络异常流量检测过程
为了对所有网络流量检测的识别方法作出客观的评价,现一般采用反馈率(recall)和准确率(precision)这两个参量来衡量检测方法的好坏。具体表达式如下:
(1)
(2)
式中:TP为已经准确识别动作A特征的样本数量;FN为没有识别动作A特征的样本数量;FP为被错误识别动作A特征的样本数量。
使用本文提出的网络异常流量检测方法和常规的单机网络异常流量检测方法的测试结果如图4和图5所示。
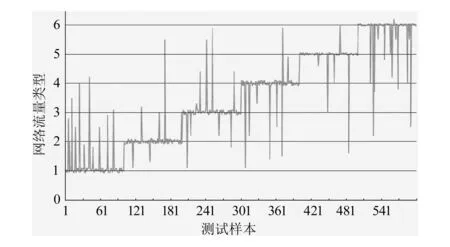
图4 本文检测方法测试结果

图5 常规单机检测方法测试结果
图4和图5中横轴测试样本代号和纵轴数字含义表1和表2。
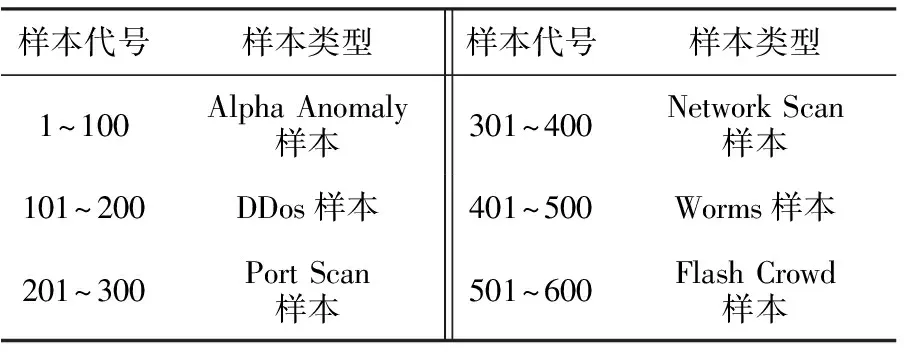
表1 图4和图5的横坐标含义

表2 图4和图5的纵坐标含义
使用本文提出的网络异常流量检测方法和常规的单机网络异常流量检测方法对测试数据进行检测,得到的评价指标对比见表3。
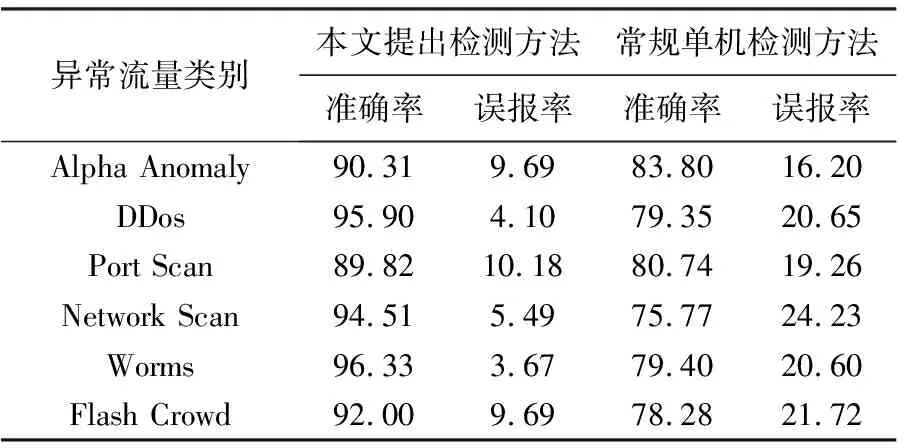
表3 两种方法的评价指标 %
从表3可以看出,本文提出的检测方法的平均准确率相比常规单机检测方法提高了17.08%,误报率降低了65.7%,具有较好的检测性能,能够满足目前大数据环境下对网络异常流量检测的要求。
在当前大数据环境下,检测模型不仅要满足准确率的要求,同时还要具有一定的检测实时性。通过多次实验,对本文提出的网络异常流量检测方法和常规的单机网络异常流量检测方法进行检测耗时对比,结果如图6所示。

图6 检测耗时对比
由图可以看出,使用本文提出的网络异常流量检测方法的检测耗时仅为常规的单机网络异常流量检测方法的8.81%,说明本文提出的检测方法相比常规方法具有更好的实时性。主要原因是本文使用的检测方法是建立在基于大数据的云计算平台上,能够将大数据中的异常网络流量检测任务分配给多个子任务计算平台进行。
4 结束语
利用云计算技术对大数据环境下的网络异常流量检测方法进行研究,并对网络流量异常检测效果进行测试,研究结果表明,本文提出的方法准确率更高、误报率更低,具有较好的检测性能,能够满足目前大数据环境下对网络异常流量检测的要求。
