基于深度学习的井下环境异常工况智能识别技术研究*
2018-11-30涂思羽彭平安蒋元建
涂思羽,彭平安,蒋元建
(中南大学 资源与安全工程学院,湖南 长沙 410083)
0 引言
矿山井下作业环境复杂恶劣,安全生产事故频发,井下作业人员、设备、环境等系统安全难以保证,矿山生产效率被严重制约。为使井下作业人员摆脱高危复杂环境,提高矿山开采效率,实现矿山本质安全,将先进的智能技术引入矿山已成为矿业技术发展的迫切需求。目前,无人化开采是当前矿山开采的热点问题,国外部分矿山,如EI Teniente地下铜矿、澳大利亚北部露天铁矿、Solomon Hub铁矿、智利Gaby铜矿、Gabriela Mistral铜矿等通过引入无人开采技术(机车、电铲、卡车、火车无人驾驶;凿岩台车、铲运机自动作业)以保障矿山安全、高效生产[1-3];国内如普朗铜矿、建龙重工思山岭铁矿等矿山也逐步开始引入无人开采技术(卡车、电机车无人驾驶系统,遥控装矿、自动控制运输及卸载)[4-5],矿业技术逐渐向智能化、无人化转型升级,无人开采技术已经逐渐成为国内外矿业技术发展的必然趋势。
目前,矿山无人开采技术仍处于发展阶段,实现无轨装备及其他各类型装备自主行走和自主作业是矿山无人开采亟待突破的问题。实现无轨装备及其他各类型装备的自主行走和自主作业,要求装备自身具有高度的智能化水平,如具备环境辨识、判断思维、决策及响应行为的能力。其中,作业环境辨识是无轨装备及其他各类型装备无人化作业的前提,是实现矿山无人化开采的关键环节,因此,开展矿山作业环境的智能识别研究具有重要的理论和现实意义。
近年来,大批国内外学者从事井下作业环境识别技术研究,为矿山无人开采奠定技术基础。如Hon、Ye等[6-8]利用无线射频识别(RFID)技术实现对井下对象检测、定位,但该技术需对每个对象贴上标签,系统构成也较为复杂;Yalcin、Jin等[9-10]采用激光雷达技术实现对行径路上的障碍物检测,但是该技术的实时性和精度相对较低,同时整体系统需具有较高稳定性和可靠性;孟宇等[11]运用条码识别方法识别路标图像,从而实现设备检测,但准确率较低,成本相对较高。上述研究方法所涉及的设备价格昂贵,技术结构较为复杂,且仅能实现对井下对象的检测定位,不能实现多对象的具体类型判断。而无轨装备除能检测周边环境对象外,亦能判断对象的具体类型,从而对环境中各对象做出相应的行为响应。
随着计算机技术的快速发展,诸多学者采用深度学习方法对目标对象进行识别分类研究,取得了广泛的应用成果。识别分类的网络模型日趋完善,如2012Alexnet、2014VGGNet 、2014GoogleNet、2015ResNet、2017Dense Net、2017SENet、Google Net和Inception V2、Inception V3、InceptionV4、InceptionResnetV2等[12-19]均能实现对象的精准分类,且实时性高,但深度学习模型对井下复杂环境异常工况的识别分类研究鲜有涉及。因此,本文提出运用深度学习模型帮助无轨装备及其他各类型装备识别异常工况,仅需配备车载摄像机和计算机系统就能具备识别分类能力,涉及设备数目少,成本较低,系统构成简单,且实时性和准确性高。研究结果对实现无轨装备及其他各类型装备自主行走和自主作业(智能避障、无人驾驶、智能铲装、自动卸矿)、提高矿产开采效率及保证人员安全具有重要意义,同时具有较高的应用价值。
1 异常工况智能识别分类实验
1.1 实验原理
近年来,卷积神经网络(简称CNN)在图像识别技术领域取得巨大成功,如人脸识别、医学图像识别等,CNN通过深层神经网络结构提取图像的高层语义特征,完成复杂图像的识别分类工作。一般卷积神经网络模型包含输入层(Input)、卷积层(Convolution layer)、下采样层(又称池化层Pooling layer)、全连接层(Fully connected layer)、输出层(Output),其架构如图1所示。

图1 一般卷积神经网络架构Fig.1 Convolution neural network architecture
卷积层通过卷积核滑动,对图像局部进行卷积运算,利用局部连接和权重共享的方式,极大降低参数数量,低层卷积主要提取图像边缘特征,高层卷积捕获复杂组合性特征,再通过非线性激活函数Sigmoid、Tanh、ReLU强化识别能力[20];池化层是对卷积后的特征图进行聚合统计,分为最大池化、平均池化[21-24],可有效降低图像维度,并保持图像特征在一定程度上尺度不变的特性,极大减少计算量;全连接层将特征提取器提取的图像特征进行综合。
Softmax分类器属于多分类器,Adam是自适应调整学习率的优化算法,其算法如公式(1)所示:
mt=β1mt-1+(1-β1)gt
vt=β2vt-1+(1-β2)gt2
(1)
式中:t为时间,s;mt为对梯度的一阶矩估计,vt为对梯度的二阶矩估计,类似对期望E|gt|,E|gt2|的估计;β1和β2为矩估计的指数衰减速率,取值在0~1之间。
通过计算偏差校正,如公式(2)所示,m^t和v^t是对mt和vt的校正。

(2)
利用公式(3)进行梯度更新:
(3)
式中:ε为数值稳定的小常数,一般取值为10-8;μ为步长,一般取值为0.001。
ReLU非线性激活函数如公式(4)所示,值大于0的保留,反之取为0,该激活函数加快收敛速度,有效防止梯度消失和发散,一定程度上可防止过拟合。

(4)
批量正则化(Batch Normalization)方法加快网络训练速度,如公式(5)所示:
(5)
式中:xk为输入数据;x′k为xk归一化后的数据;E[xk]为均值;Var[xk]为方差。
Dropout方法在模型训练时按一定比例更新部分神经元参数,能有效防止过拟合。
1.2 实验方法
优秀的网络模型皆是基于大量标注数据集(如COCO、ImageNet)训练而成,然而在实际应用中,高质量且具有标签的大型矿山井下数据集资源匮乏,难以支撑优秀网络模型,可能产生严重的过拟合问题。迁移学习将已训练好的模型参数迁移到新模型进行新的模型训练[25],可有效解决过拟合问题。因此,本文提出基于迁移学习进行异常工况小数据集训练。首先增广数据集,提取大规模数据集(ImageNet)预训练模型InceptionResnetV2的权重和特征向量用于新数据集训练的初始化;然后冻结分类器之前所有层,添加全连接层,重新训练1个完整的全连接模型,采用批量正则化(Batch Normalization)方法进行批归一化处理,使用ReLU激活函数,运用Dropout方法防止网络训练出现过拟合现象(训练准确率远远高于测试准确率);最后使用Softmax分类器进行井下异常工况具体分类。主要研究框架如图2所示。

图2 研究框架Fig.2 Research framework
1.3 实验过程
1.3.1 构建数据集
分析无轨装备正常运行和作业的主要影响因素,如表1所示,从而建立井下复杂环境4类异常工况(溜井、散落大块与矿堆、损坏电缆和作业区内其他车辆)数据集。根据矿山实地拍摄及Python爬虫采集数据[26],分为溜井、散落大块与矿堆、损坏电缆和作业区内其他车辆4类,各400张图片,共计1 600张图片,其中1 280张图片作为训练集,另各选40张作为验证集,选择160张图片作为测试集。在小样本情况下进行深度神经网络训练常发生过拟合问题,因此,采用数据增强方法(旋转变换、平移变换、缩放变换、翻转变换)进行图像源数据预处理,扩充数据样本量。

表1 主要影响因素Table1 Main affecting factors
1.3.2 实验平台及参数设置
实验基于Ubuntu16.04系统,使用开源深度学习框架Tensorflow的高级API Keras作为开发环境,使用GPU加速模型训练。
在模型训练过程中,为获得更好的梯度下降性能,需选择最佳学习率、Dropout值等,同时使用批量正则化(Batch Normalization)方法,基于ReLU激活函数、交叉熵损失函数进行网络训练,最后使用4分类的Softmax分类器识别分类,实验参数设置见表2。

表2 实验参数Table 2 Experimental parameters
2 实验结果及分析
基于InceptionResnetV2预训练模型进行训练及测试,采用添加不同全连接层的迁移策略进行实验对比分析,得出最终实验结果。
2.1 策略一
首先冻结预训练模型的特征提取网络层,全局平均池化层处于最后卷积块之后。然后添加1层全连接层,神经元个数分别设置为4 096,2 048,1 024,512,分别重新训练1个完整的全连接模型。实验迭代300次,详细参数设置如表1所示,模型训练过程的训练准确率均趋于100%,训练损失均趋于0,但验证准确率和验证损失有较大差异,如图3所示,图3(a)代表全连接层不同神经元个数的验证准确率曲线,图3(b)代表相应的验证损失曲线。

图3 结果比较分析(策略一)Fig.3 Results comparison analysis(Strategy One)
由图3可知,当全连接层神经元个数为4 096时,验证准确率趋于100%,验证损失趋于0,模型收敛性能相较于其他模型好,随着全连接层的个数逐渐降低,模型收敛性能逐渐减弱。 同时,可以分析得出,全连接层的神经元个数越多,模型验证准确率越高,成正相关关系;损失与神经元个数成负相关关系。因此,全连接层的神经元个数是影响模型性能的关键因素,而由于添加单层全连接层的损失未完全接近于零,所以需进一步讨论全连接层层数与模型性能的关系。
2.2 策略二
将全连接层设置为2层,2层神经元个数分别设置为4 096与4 096,2 048与2 048,1 024与1 024,512与512,其他实验参数设置如表1所示,模型训练过程的训练准确率均趋于100%,训练损失均趋于0,但验证准确率和验证损失存在差异,如图4所示,其中图4(a)代表全连接层每层不同神经元个数的准确率曲线,图4(b)代表相应的损失曲线。
由图4可知,当全连接层2层神经元的个数均为4 096时,模型收敛性能最佳,验证准确率最佳(达到100%),验证损失几乎接近零。同时,随着神经元个数的减少,模型需要更多的迭代次数才能达到较好的验证准确率,使验证损失降到最低。因此,2层全连接层的神经元个数越多,模型验证准确率越高,相应的验证损失也就越低,得出的规律与策略一实验得出的规律一致。
最后,将策略一实验得出的全连接层神经元个数为4 096的最优模型训练过程与策略二实验得出的2层全连接层及神经元个数为4 096的最优模型训练过程进行最终比较分析,结果如图5所示。其中,图5(a)代表全连接层不同神经元个数的验证准确率比较曲线,图5(b)代表相应的验证损失曲线。

图4 结果比较分析(策略二)Fig.4 Results comparison analysis(Strategy Two)
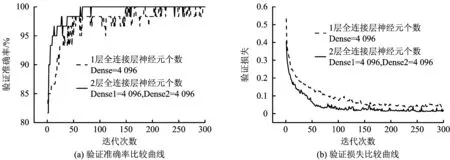
图5 最终结果分析Fig.5 Final results comparison analysis
由图5可知,全连接层层数为2层时,模型的收敛性能最佳,验证准确率几乎接近100%,验证损失几乎为零,模型性能好。根据上述迁移策略的模型训练过程,得出全连接层神经元个数、全连接层层数对模型性能具有非常重要的影响,只有将2元素都充分考虑,才能得到最优模型。
因此,选择添加2层全连接层且每层神经元个数均为4 096,通过该策略训练的模型进行测试,测试集大小为160张,其平均测试结果如表3所示,溜井的测试准确率为95.996%,相较于其他测试准确率偏低,分析原因可能是测试样本图像质量较差,或是溜井的格筛上存在一些未掉落的矿堆,干扰异常工况分类效果,但总体来看,该模型的测试性能好,能有效对井下复杂环境异常工况进行分类。
3 结论
1)提出深度学习的方法,实现了对井下复杂环境工况的自主识别,通过分析影响无轨装备正常运行和作业的主要因素,建立井下复杂环境4类异常工况(溜井、散落大块与矿堆、损坏电缆和作业区内其他车辆)数据集。

表3 井下复杂环境异常工况各类别测试准确率Table 3 Test accuracy of each category of abnormal operating conditions %
通过旋转变换、平移变换、缩放变换等数据增强技术,有效防止网络训练过拟合。
2)实验选择0.000 001的学习率,对预训练模型权重参数进行微调,采用Adam优化器,批次大小设置为60,Dropout设置为0.5,这些超参数设置对迁移学习策略的比较分析起到了关键性作用,是模型性能优化的前提。
3)从验证准确率、验证损失进行双向分析,通过方案对比寻求最优化方案,并根据测试数据相关结果,验证了提出相关算法的性能,使实验分析更加准确,对井下多种作业对象的具体类型判断正确,实时性和准确性都较高。
4)得出全连接层神经元个数及层数是模型性能的重要影响因素,通过添加2层全连接层,且每层神经元个数为4 096时的训练模型性能最佳,测试效果符合预期,能较好应用到井下复杂环境异常工况的自主识别中,为矿山无人化开采提供支持。
