中国县域商业网点总量布局的统计评价
2018-11-22张俊娥
张俊娥
(绥化学院 经济管理学院,黑龙江 绥化 152061)
0 引言
国家商务部于2001年,向各个城市提出了《城市商业网点规划》的编制要求,2008年开始对县级市的商业网点规划开始编制。2007—2017年间,就社会消费品总额来讲,城市占比由68%攀升到了88%,而县及县以下占比则由32%下滑到了12%[1]。由上可知,在建设商业网点的过程中,城市高速发展时县及县以下表现出了滞后现象,对于大部分县域来讲,商业网点大多集中在商业中心区;对于村镇商业网点来说,大多布局散乱且不合理,商业设施并未按照合理的结构搭建,大型商业设施盲目建设,商业设施整体档次偏低等问题严重[2]。本文选取中国28个地区的县域为研究样本,用商业网点总量为研究数据基础,建立了中国县域商业网点总量的二级评价指标体系,用熵权法测度了指标体系中各指标的权重;运用模糊综合评价法对所选区域县域商业网点总量进行了评价,并验证了中国县域商业网点布局总量分布的不足,为优化我国县域商业网点布局提供依据。
1 样本选择和数据来源
县域经济是我国历史比较悠久的一种经济形态,长期以来与中心城市经济相持存在,两者的主要区别是:中心城市一般是由市辖区构成,而县域主要是由县级市、自治旗以及自治县等县级单位构成[3]。截止到2016年末,中国县级行政区单位总数共有2851个,其中包括1366个县,360个县级市,954个市辖区,另外还有117个自治县,2个特区。这些县城及所辖乡镇区域统计汇总,县城户籍人口共1.39亿人,暂住人口0.16亿人,城镇人口7.93亿人,全国县域人口共计9.32亿人,全国总人口13.8亿人,因此全国县域人口在全国总人口的比例为67.5%,绝大多数省份的县域人口比例都能达到该省份总人口的一半以上,全国县域地区生产总值达24.14万亿元,占全国GDP的51.04%,因此县域经济近年来越来越引起学者们的重视。
通过表1可以看出,近年来中国县级行政区的数量呈递减趋势,随之而来的是市辖区数量的递增,市辖区的数量在十年内已经增加了将近100个。自2007—2016年,全国县级区划分数量基本稳定在2855个左右,但其中市辖区和县级市的数量在发生较大改动,一直处于改动和调整状态。
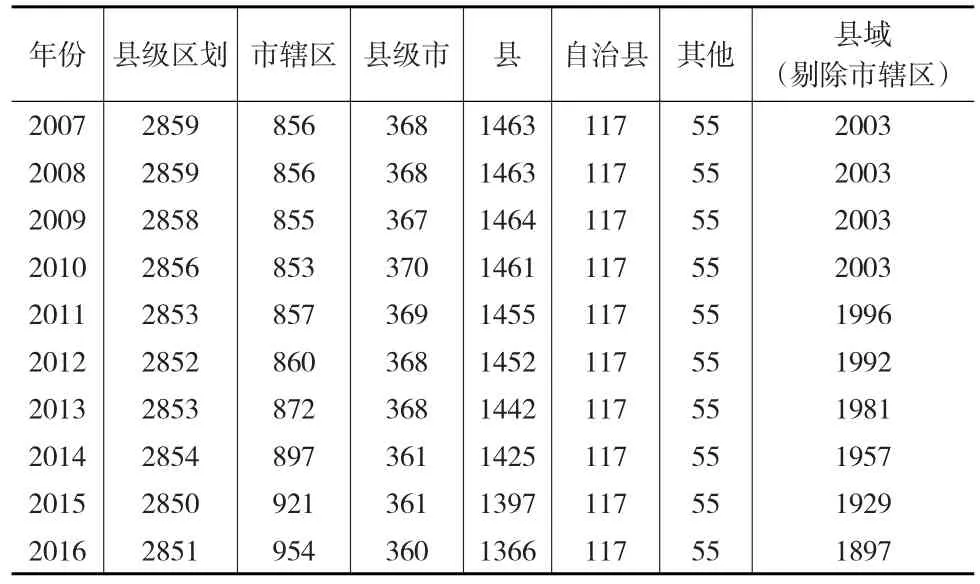
表1 中国县级行政区划
本文对县域的样本选择标准如下:一是将撤县设市和撤县设区等发生了变化的县域、林区和特区进行剔除;二是剔除市辖区(保留县级市),由于市辖区中的城市经济行为较为突出,因此在对县域经济进行研究时将市辖区进行剔除;三是剔除数据严重缺失的香港、澳门和台湾经济特区,青海、西藏和新疆等偏远地区。经过剔除后本文选择的县域样本数量有1685个,由于选择的样本数量是全国县域总量(不包括剔除的市辖区)的90%,因此在说明问题上具有较强的说服力和权威性。
由于一些地区数据的缺失,因此在指标选取时剔除了新疆、青海和西藏地区的县域,本文选取了2016年全国28个省区的1685个县域为研究样本,数据来源于中国统计年鉴及中国县域统计年鉴。本文所采用的原始数据来源于国家统计局出版的《中国统计年鉴》(2011—2017)、《中国县(市)社会经济统计年鉴》(2011—2016)、《黑龙江商务年鉴》(2016)、《中国商务年鉴》(2017)。
2 研究方法
2.1 熵权法
采用熵权法测度权重能够把所选取的多个指标决策中的各个方案的信息和决策者的主观判断信息进行定量并做系统判断,得出指标集中的各项目基于熵的相对优异性量化评价指数[4]。因此本文选用熵权法对指标权重进行测度。
构建样本的指标特征值矩阵X:

其中,n为样本数,m为指标数。
在模糊综合评价的研究中,由于所选指标的数量级单位不一致,这种指标的数值及单位之间的不同定会给最终的综合评价造成影响,因此,要剔除这些影响,就要对各项指标进行无量纲化处理,通常选用阈值法进行无量纲化处理:
正向指标:

负向指标:

接下来测算第j个指标下的第i个地区的指标值在该指标中所占的比重:
再测算第j个指标的熵值:

特别地,当fijfij=0=0,那么
最后,对第j个指标的差异性系数和权重进行测算。对于第j个指标,指标值的差异越大,对方案的评价作用就越大,熵值就越小。定义第j个指标的差异性系数gj=1-Hj,则第j个指标的权重:

其中,j∈[1 ,n]j∈[1 ,n] 。
2.2 模糊综合评价方法
模糊综合评判方法是以模糊数学原理为基础理论,对“模糊性”事物展开分析与评价、将“非此即彼”二值数学逻辑加以扩充,得到“亦此亦彼”的多值可能的模糊逻辑的一种系统分析方法[5]。模糊综合评价大致由两大步骤组成。一是对单个因素进行单独评价;二是对所有因素进行综合评价。本文将探索中国县域商业网点的影响因素及这些因素之间的相关关系对县域商业网点布局的影响程度,从而实现对中国各省县域商业网点布局总量控制的模糊综合评价研究。
3 县域商业网点总量指标体系构建
3.1 指标体系预选
本文从地区经济水平、消费能力和结构、人口因素、交通因素这四个主要方面对全国县域商业网点数量进行研究[6]。县域商业网点布局总量控制预选指标体系如表2所示。
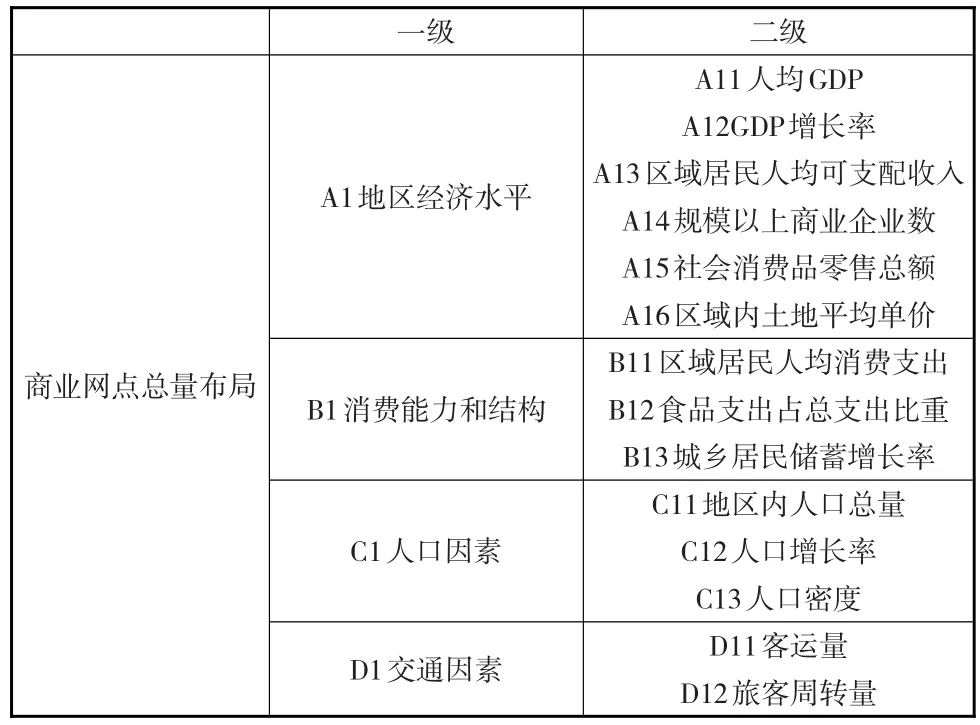
表2 商业网点布局总量控制预选指标体系
3.2 指标相关性分析
县域商业网点布局的总量控制各指标间也可能会有小幅度的联系,存在相关性,不能更好地得出县域商业网点布局的总体数量控制状况。因此,本文为了消除所选指标的相关性对最终评价体系产生的影响,要对上述所选指标做出相关性分析,得出各指标间的相关性系数,从而剔除相关性较强的指标,最终得到综合评价指标体系,本文运用SPSS20.0软件做因子分析,选出主因子。
(1)地区经济水平因子分析
从下页表3中可以看出,只有人均GDP和GDP增长率两个因子的特征值大于1,而且这两个因子的特征值之和占总特征值的83.268%,因此,提取前两个因子作为主因子,所以选用这两个指标来代表地区经济水平因素。
(2)消费能力和结构
从下页表4中可以看出,城乡居民储蓄增长率与区域居民人均消费相关度较高,而另外两个指标的相关性均小于0.5,因此消费能力和结构指标选取可用区域居民人均消费支出和食品支出占总支出的比重来代表。

表3 地区经济水平因子贡献率

表4 消费能力和结构因素相关性分析
(3)人口因素和交通因素因子分析
其考察方法与上文相同,此处不再赘述,结果显示人口因素指标之间相关性均小于0.6,三项指标均可以代表人口因素。交通因素指标之间相关性为0.25,相关性较小,因此,可以选取客运量和旅客周转车这两个指标来代表交通因素。
由上述对所选取指标的相关性描述与分析,可以最终确定县域商业网点布局总量控制的指标体系,如表5所示。

表5 商业网点总量布局指标体系
3.3 指标权重测度
本文选用熵权法对县域商业网点总量控制指标的权重进行测度。
首先设定人均GDP(x1)、GDP增长率(x2)、区域居民人均消费支出(x3)、食品支出占总支出的比重(x4)、地区内人口总量(x5)、人口增长率(x6)、人口密度(x7)、客运量(x8)和旅客周转量(x9)。根据公式(2)和公式(3),对上述相关指标做无量纲标准化处理。
其次,根据公式(4)计算fij,然后由公式(5)计算熵值hj,得 出 结 果 :hj=(0.9078,0.9234,0.9123,0.9421,0.9371,0.8277,0.9657,0.8873,0.9166)。最终由公式(6)计算得出熵权系数为:
ω=(x1,x2,x3,x4,x5,x6,x7,x8,x9)=(0.1158,0.0623,0.1672,0.0574,0.0831,0.0547,0.2563,0.1054,0.0978)。由此可知,人均GDP、居民人均消费支出和人口密度这三个指标的权重系数比较大,说明这三个指标对县域商业网点布局总量问题存在较大的影响。符合现实情况,比如人均GDP,县域商业网点数量在很大程度上与地区商业的空间和经营效益相关,当一个县域的GDP越大时,其经济发展水平就越高,从而居民手中财富就越多,对当地的商业来说就越发达,从而该地区的商业网点数量也就越多。
4 县域商业网点总量的模糊综合评价
4.1 建立模糊评价集
根据表5得出的商业网点布局总量控制的指标体系,设出9个指标的和特征值代表商业网点总量控制情况,则由这9个指标构成的评价对象的因素域为U,即公式(7)所示。本文研究对象为28个省区的县域,共取28个样本,因此构成特征值矩阵X,即公式(8)所示。

其中,n=28,m=9。
本文参考国内外学者对商业网点总量的研究,将商业网点的总量控制的评价分为五个评价等级,分别为{很多,较多,合适,较少,很少},即商业网点布局总量的评价等级论域为:

本文以上述公式来说明全国各县域地区商业网点总量的合理程度,依据商业网点数量由多到少分为五个等级,一级代表该地区商业网点数量很多,集聚程度高,易出现网点之间关系复杂、服务重叠等,这样极大地增加了各类商业网点的成本,资源配置不能达到最优化,资源浪费现象严重;二级代表该地区商业网点数量较多,网点密度等要比一级的轻;三级代表该地区商业网点数量是合适的,该地区各类商业网点数量适中,各类商业网点都能最大化其效用,发挥其最大功能,有效利用该地区的资源。四级代表该地区商业网点数量较少,网点密集度相对较低,未能合理利用该地区的资源,有很大发展潜力,可以增加网点建设,充分利用资源。五级代表该地区商业网点数量很少,网点密集度很低,未能合理利用该地区的资源,发展潜力巨大,应多设立网点,充分利用资源。由公式(9)可得评价集矩阵为:

其中,m=9,rij代表第i个指标第j个等级下的标准特征值。用此矩阵及隶属度函数可得出各地区的单因素模糊评判矩阵。公式(11)为以黑龙江省数据为例得出的模糊矩阵,这样可以得出28个研究区域的单因素模糊评判矩阵,进而可以得到评价对象的各项指标对于商业网点总量等级的隶属度。本文选取黑龙江省县域数据进行分析,人均GDP指标相对于较多和合适的隶属度是0.6716、0.3284,GDP增长率相对于合适和较少的隶属度是0.57、0.43,区域居民人均消费支出和食品支出占总支出比重这两项指标相对于较多和合适的隶属度分别是0.67、0.33和0.3518、0.6482,地区人口总量指标和旅客周转量是相对于很多和较多的隶属度,而人口增长率、人口密度和客运量三项指标均是相对于很多的隶属度。由此可知,黑龙江省县域商业网点数量多数因素处在很多和较多的状态,相关部门应根据城镇化发展程度合理规划商业网点的数量,合理配置现有商业资源,以达到资源得到充分利用的目的。

4.2 综合评价
将上文中运用熵权法所得出的指标权重数值与公式(11)中所得的各地区的模糊评判矩阵代入模糊综合评价模型公式(12)中,得到:

运用模糊评判能够明显体现权数的作用,运用相关统计软件对28个地区进行模糊合成运算[7],运算过程以黑龙江为例,如公式(13)所示,所得结果见表6。

由此可得到28个省区县域商业网点数量五个等级的隶属度。根据隶属度最大的原则,选择最大值等级的数量级别作为该地区评价商业网点总量的最终标准。以公式(13)为例,黑龙江省对五个数量等级的隶属度分别为0.4656、0.2846、0.1682、0.0816、0,五项隶属度最大的是0.4656,因此,黑龙江省商业网点分布数量等级为很多,依此可得全国各地区县域商业网点分布数量等级评价,由表6所示。表中数据反映了全国各地区在2016年县域商业网点总量相对多少的问题,从总体看,16个地区县域出现商业网点分布数量多而9个地区县域出现商业网点分布数量少的现象,全国只有3个地区县域商业网点数量分布是合适的,这说明我国大部分地区县域商业网点的布局数量不合理,多和少两极分化严重。东部地区大多网点分布数量偏多,这主要是由于东部地区的经济发展水平较高及城镇化建设进程较快,各方面发展已相对成熟,网点数量达到超饱和状态,而西部地区及东北地区的经济发展水平低于东部,人均GDP不高,居民消费能力也较弱,人口密度也相对较小,则不需要设置过多的商业网点,在商业网点配置中应该更注重配置效率和经营效益,商业网点的服务功能的提升等。中部地区的商业网点数量配置相对较为合适。比如,浙江、江苏等经济较发达地区,县域商业网点数量却相对较少,其居民对商业的需求不能得到充分满足,应该合理设置各类功能性商业网点以满足其消费需求。由此可以看出全国各地区商业网点数量分布不合理,从而不能发挥各类商业网点的相应功能以满足人民生活的需要,因此应对商业网点总量加以引导和控制,同时对网点加以整改和优化,加快实现乡村振兴战略。

表6 全国各地区商业网点数量比较
5 结论
本文用模糊综合评价法对中国28个地区县域商业网点总量进行了评价,并验证了中国县域商业网点布局总量存在的问题和不足,为优化我国县域商业网点布局提供了依据。选取2016年全国28个省区为研究对象,用人均GDP、GDP增长率、区域居民人均消费支出、食品支出占总支出的比重、区域人口总量、人口增长率、人口密度、客运量和旅客周转量作为评价县域商业网点布局总量控制的指标;用熵权法对商业网点总量控制指标权重进行测度。其中人口密度、人均均消费支出和人均GDP的权重系数较大,在评价过程中起重要作用;运用模糊综合评价方法得出全国各地区对县域商业网点布局的五个等级的隶属度;再根据隶属度最大的原则,得出11个地区县域商业网点总量很多,5个地区网点数量较多,3个地区合适,5个地区较少,4个地区很少,全国各地区中,东部地区和西部地区均存在商业网点数量不合理现象。
