藏文情感词典的构建及微博情感计算研究
2018-11-22孙本旺
孙本旺,田 芳
(1.青海大学 计算机技术与应用系,青海 西宁 810016; 2.青海大学 信息化技术中心,青海 西宁 810016)
0 引 言
藏文情感词典的构建研究是自然语言处理的重要部分,也是藏文文本情感分析的基础。基于藏文情感词典的情感计算,主要是通过藏文基础情感词、藏文程度词、藏文否定词等来实现,因此藏文情感词典构建的好坏直接影响情感分类的结果。利用已有的中文情感词典资源自动构建藏文情感词典,不但能解决藏文词典构建费时费力的问题,还能保证藏文情感词典拥有足够多的词汇量。藏文情感词典构建方法的研究将有利于推动藏文词典的构建研究、藏文文本的情感倾向分析研究。
1 相关研究
1.1 藏文情感词典构建研究现状
祁坤钰构造了一个英藏机器翻译的藏语语义分类体系,并提出了藏语语义词典设计的理论框架、语义分类思想和属性描述原则[1];邱莉榕等研究了藏文语义本体中的上下位关系模式匹配算法来构建藏文语义本体[2];柔特基于Word Net对比英文和藏文词之间的语义关系、构建双语大型数据库和制定映射过程中词汇空缺等方法,构建了基于半自动匹配的藏文语义词典[3];巴桑卓玛等人工收集和整理了一部藏文基准情感词典,在此基础上,基于词向量扩充情感词典,并利用KNN扩充法自动扩建藏文情感词,最终建立了一部比较实用的藏文情感词典[4];杜雪峰提出利用藏汉双语词典和Hownet相结合的办法来构建藏文词典,构建了包含基础情感词、否定词、转折词和程度副词等的藏文词典[5];Zhang Zhen等利用英文情感词典和藏英词典相结合的方式来构建藏文基本情感词典[6];Yan X等通过人工手段建立了一个全面的、高效的极性词典,其中包括基本词典、程度副词词典等藏文词典[7]。
1.2 藏文微博情感分析研究现状
麻省理工学院的Picard教授最早提出了情感分析的概念。Picard教授在1995年发表了论文《Affective Computing》[8],并在两年后在此论文的基础上撰写了有关情感计算的最早同名论著[9]。在藏文情感分析方面,扎西本等基于情感词典的褒贬义词、转折词及否定词来计算藏文句子的情感倾向[10];张俊等通过借鉴中文微博情感分析中比较常见的基于统计的方法和基于词典的方法对藏文微博进行情感分析,实验结果是基于藏文词典的藏文微博情感分析的准确率明显高于基于TF-IDF的藏文微博情感分析的准确率[11];普次仁等将藏文分词后,用词向量表示词语,把藏文语句变为由词向量组成的矩阵,利用无监督递归自编码算法对该矩阵向量化,有监督地训练输出层分类器以预测藏文语句的情感倾向[12];袁斌针对藏文微博中存在的藏汉混排问题,提出了一种基于语义空间的藏文微博情感表示方法,该方法通过句法树实现了语义向量化,提高了情感特征中的语义成分,并解决了多语言混合文本处理问题[13];李苗苗提出了藏文文本情感分析的词语级、句子级、篇章级三层框架,提出了利用情感词典和规则集分析藏文句子情感的一种方法,采用SVM算法对篇章级进行情感分析[14];江涛等提出了基于多特征的情感倾向性分析算法,算法以情感词、词性序列、句式信息和表情符号作为特征,并针对藏文微博常出现中文表述的情况,将中文的情感信息也作为特征进行情感计算,利用双语情感特征有效提高了情感倾向性分析的效果[15]。
2 藏文情感词典的构建
研究藏文情感词典的构建,将有利于藏文微博的情感倾向分析,推动藏文的网络舆情分析、机器人情感识别等应用研究。
2.1 现有情感词典的基本信息
基于现有的中文情感词典构建情感基本信息库。收集了清华大学褒贬义词典(包含情感正反极性,褒义词4 468个,贬义词5 567个),台湾大学NTUSD词典[16](包含情感正反极性,褒义词2 810个,贬义词8 276个),Hownet词典[17](包含情感正反极性,褒义词4 766个,贬义词4 370个,程度词分为最(most)、很(very)、较(more)、稍(ish)、欠(insufficiently)、超(over)、以及否定词表),以及哈工大停用词词典(包含停用词767个)。《藏汉大辞典》[18]中所有单词表现格式如下所示:

2.2 TSD的构建
按先行经验,通过基于Hownet词典和《藏汉大辞典》来构建藏文情感词典(Tibetan sentiment dictionary,TSD)。TSD词典包含基础情感词、程度词、否定词、转折词。构建流程如图1所示。
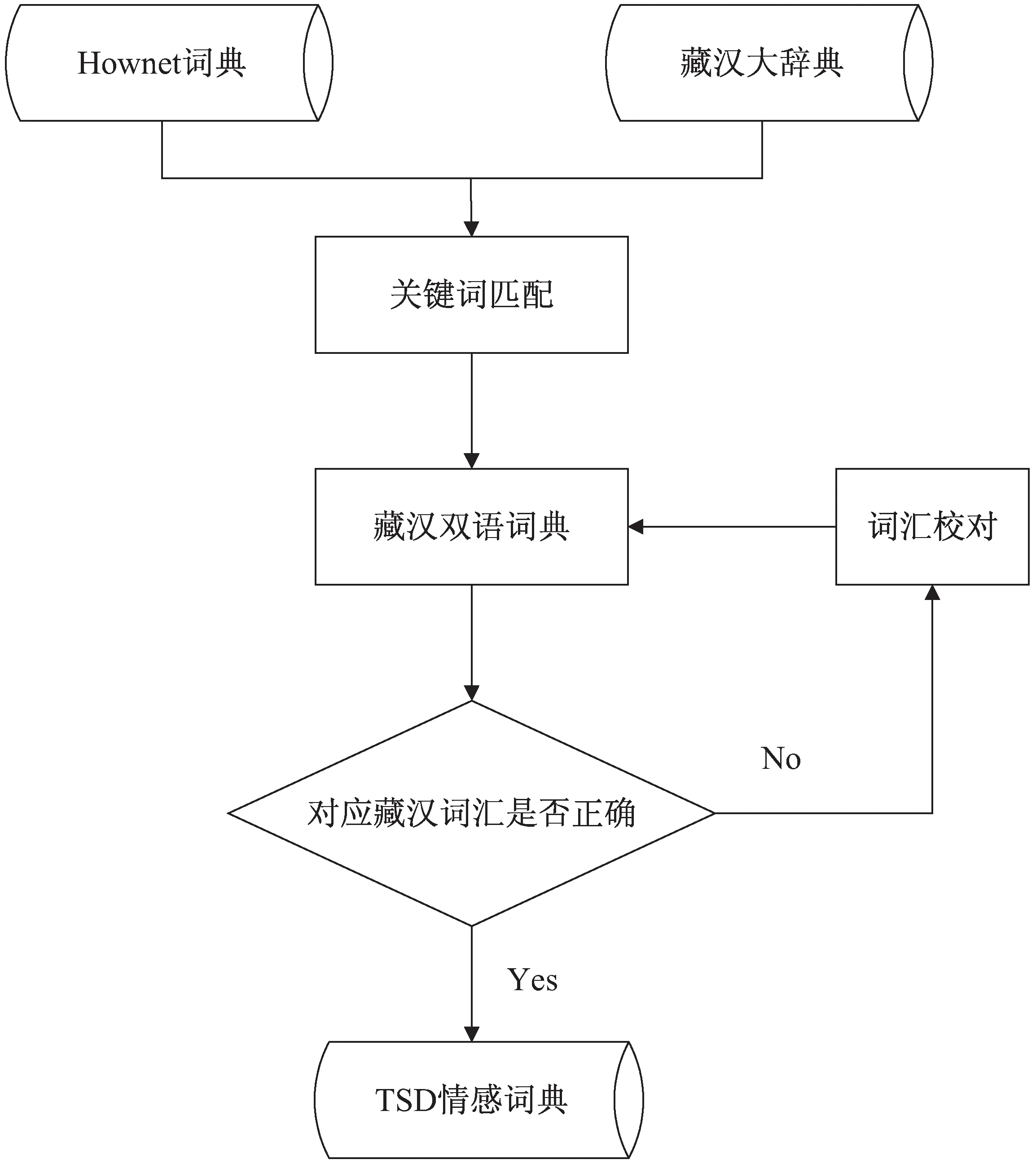
图1 TSD藏文情感词典的构建
2.3 SSTSD的构建
主要采用合并去重算法,首先将Hownet词典和清华大学褒贬义词典合并,然后将合并结果与台湾大学NTUSD词典合并去重,最后将合并结果与《藏汉大辞典》通过匹配算法来构建藏文情感词典(Sanjiang source Tibetan sentiment dictionary,SSTSD),SSTSD情感词典用Hownet词典表达的TXT表示。利用哈工大停用词典与《藏汉大辞典》通过匹配算法来构建藏文停用词词典。首先,通过匹配算法查找相应词汇自动构建藏汉双语词典;然后校对检验对应词汇的正确性;最后提取藏文词汇,并利用去重算法得到正确的SSTSD藏文情感词典和停用词词典。SSTSD词典除了转折词、双重否定词等小部分通过人工翻译和校对得到,绝大部分是自动构建。SSTSD词典包含基础情感词、程度词、否定词、转折词、双重否定词、藏文停用词。构建步骤如图2所示。
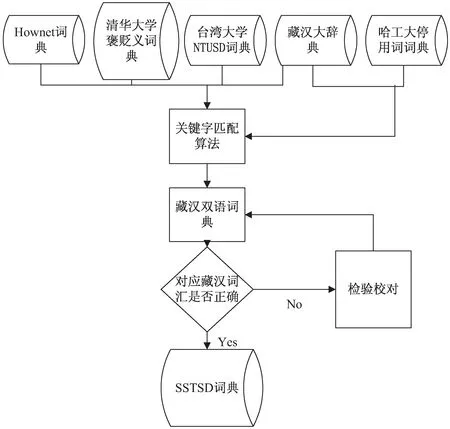
图2 SSTSD词典的构建
3 藏文微博的情感倾向分析
3.1 情感倾向分析方法
基于情感词典的藏文微博情感分析的方法一般是通过微博中情感词或情感短语的权值叠加计算来判断某条微博的情感倾向。在进行微博情感计算时首先要考虑去停用词,然后考虑藏文微博是否含有转折词。微博中的转折词可以改变整条微博的情感倾向,因此对藏文微博情感倾向的判断分两种情况处理,即微博包含转折词的情况和微博未出现转折词的情况。
3.1.1 未出现转折词
如果微博中包含褒义情感词或情感短语,则按照式1来计算:

(1)
其中,W_Emotion_Result(i)表示褒义情感类在微博中通过累加计算的情感值;W_Emotion(x)表示微博中第x个褒义情感词的情感权重值,最终通过叠加微博中的褒义情感值得到某条微博在褒义情感类下的情感值。
如果微博中包含贬义情感词或情感短语,则按照式2来计算:

(2)
其中,W_Emotion_Result(j)表示贬义情感类在微博中通过累加计算的情感值;W_Emotion(x)表示微博中第x个贬义情感词的情感权重值,最终通过叠加微博中的贬义情感值得到某条微博在贬义情感类下的情感值。
如果微博中未包含情感词或情感短语,则判定此条微博的情感倾向是中性的。
3.1.2 出现转折词
在微博中一般只包含一个转折词,如果出现了转折词,直接取转折词后面的微博部分。如果转折词后面的微博部分中包含褒义情感词或情感短语,则按照式1来计算;如果转折词后面的微博部分中包含贬义情感词或情感短语,则按照式2来计算;如果转折词后面的微博部分中未包含情感词或情感短语,则判定此条微博的情感倾向是中性的。
3.2 情感倾向计算
因为藏文语料较少且没有开放,文中采用人工切分好的藏文微博语料进行实验。在微博的情感倾向计算中,首先将藏文微博分词,去停用词。将褒贬义情感词的初始权值都赋值为1;然后查找对应情感词的程度词级别,不同级别的程度词将会给出不同的程度级别。如果微博中含有奇数的否定词则情感倾向取反,含有双重否定词则情感值要适当增强;最后微博得分是整条微博的褒贬义倾向权值的差值。如果差值大于零则微博为正向倾向,如果差值小于零则微博为负向倾向,否则微博为中性倾向。
算法步骤如下:
Input:
Set micro-blog positivescore:positive
Set micro-blognegative score:negative
Set degree word Wi:={most,very,more,-ish,insufficiently,over};
Set degree level W_Degree(Wa):={2,1.75,1.25,0.75,0.5,1.5};
Set micro-blog number M:={M1,M2,…,Mk};
Output:
Micro-blog scores: Scores(k);
for each Mkdo
for word in Mk
if(word in stop_word)
Delete word;
else if(word in turn_word)
Mk=word.next;
else if(word in pos_word)
positive=W_Emotion_REsuit(i);
if(word.pre==Wi)
positive=W_Emotion_REsuit(i)*W_Degree(Wa);
else if(word in neg_word)
negative=W_Emotion_REsuit(j);
if(word.pre==Wi)
negative=W_Emotion_REsuit(j)*W_Degree(Wa);
else if(word.pre==deny_word)
positive=(-1)*positive;
negative=(-1)*negative;
else if(word.pre==double-deny_word)
positive=2*positive;
negative=2*negative;
for each Scores(k) do
Scores=positive-negative;
end
end
end
算法最后对比了基于不同藏文情感词典的情感倾向性分析结果,验证词典的正确性。
4 实验结果与分析
4.1 SSTSD词典与现有词典的比较
SSTSD词典得到了4 183个褒义情感词,4 823个贬义情感词,1 427个中性词,192个程度词,17个否定词,11个转折词,13个双重否定词。巴桑卓玛等构建的藏文情感包括2 000 个正向情感词,2 000个负向情感词,1 739个中性情感词。杜雪峰构建的情感词典包含了5 070个藏文基础情感词,否定词的总个数为26,双重否定词的总个数为11,程度副词的个数为71,转折词的个数为2。
从以上信息可以得出,SSTSD词典更加系统全面,具有良好的参考性。
4.2 情感计算结果分析
利用500条藏文微博语料,通过不同藏文情感词典计算得出微博情感倾向,将基于TSD词典与SSTSD词典得到的正确微博情感句和错误微博情感句作对比,如图3所示。
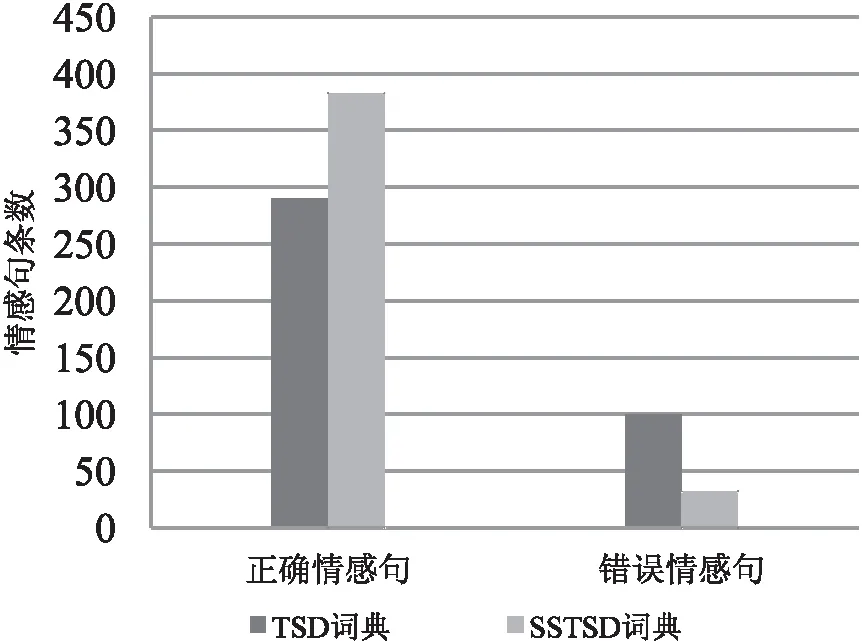
图3 实验结果对比
通过图3可以看出,在微博语料相同的条件下,基于SSTSD词典的正确微博情感句要明显高于基于TSD词典的正确微博情感句,基于SSTSD词典的错误微博情感句又明显低于TSD词典的错误微博情感句。
基于两个词典的实验结果通过评价指标进行对比,如表1所示。
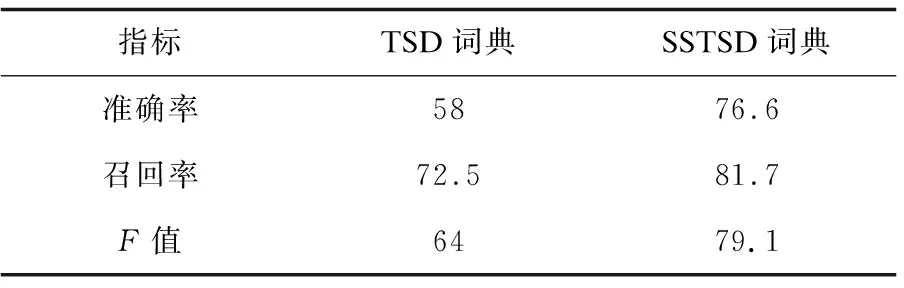
表1 TSD词典与SSTSD词典的对比 %
从表1可以得出,基于SSTSD情感词典的准确率、召回率、F值相对于TSD情感词典,分别提高了8.6%、9.2%、15.1%。
将基于TSD词典和SSTSD词典的准确率、召回率和F值进行对比,如图4所示。

图4 实验结果计算对比
通过图4可以看出,基于SSTSD词典的情感分类准确率、召回率和F值都大于基于TSD词典情感分类。TSD词典含有情感词4 093个,SSTSD词典含有情感词10 433个。通过分析可以看出,基于情感词典的情感倾向性分析很大程度上依赖情感词,情感词的好坏直接影响情感分类的准确性。基于情感词典的情感分析方法简单容易实现,后期要实现新情感词不断得自动添加。
5 结束语
文中构建的藏文情感词典更加系统全面,其总词量达到10 666个,含有基础情感词、停用词、否定词、转折词等,在以后的工作中还会不断更新完善。此外人工半自动地构建了藏文语义情感词典,情感分类更加细化,词汇量达到了2万多。基于SSTSD词典的藏文微博情感倾向分析的准确率达到了76.6%,实验结果表明,该词典达到了实用性和参考性的价值。
