Hadoop下自适应随机权值多特征融合图像分类
2018-11-22陈立潮曹建芳潘理虎
王 敏,陈立潮,曹建芳,潘理虎
(1.太原科技大学 计算机科学与技术学院,山西 太原 030024; 2.忻州师范学院 计算机科学与技术系,山西 忻州 034000)
0 引 言
随着互联网技术的变革,大数据技术、深度学习、人工智能等相关研究变得越来越重要,其中大数据技术在各领域应用广泛,它不仅仅用于分析处理海量数据,还用于解决由于计算量大导致算法效率较低的问题[1]。图像分类可以使图像数据得到归并,对于图像的识别和检索都有非常重要的作用。当前,图像分类的主要方法是以图像底层特征(如颜色、纹理、形状等)为基础,利用相关算法训练出分类模型后预测图像的类别信息。
Azhar等[2]提取图像的Sift特征后,用SVM构建分类模型,实现对蜡染图像的分类。Camlica等[3]利用LBP特征,通过支持向量机对医学图像进行了分类。由于图像底层特征的提取和表示对图像的分类性能有着重要的影响,一般来说,采用单一特征不能更好地描述一幅图像的内容,因此,从图像中提取多种特征通过一定方法组合成能更好地描述图像内容的特征向量成为很多研究者的选择[4]。但不同特征在图像中的重要性并不完全相同,当采用多个底层特征来描述图像内容时,如果只是将单个特征简单拼接,就不能控制每个特征对分类结果的影响系数,这在一定程度上影响了分类器的准确率。因此,文中提出了一种自适应的随机权值多特征融合图像分类算法(Multi-feature fusion classification algorithm with random weight,MFFRW),并通过实验对其进行验证。
1 随机权值多特征融合分类算法
数据融合可以分为像素级、特征级和决策级三个层次[5]。特征级融合属于中间层,它将来自传感器的原始数据提取特征后进行融合。已有研究成果表明[6-7],多特征融合能够提高图像分类或识别的性能。
特征融合的关键是寻找最优权值组合,因此,设计权值确定算法就变得尤为重要。最初的研究主要是通过反复实验确定,但这种方法受主观因素影响较大,所以很多研究者就提出了自适应的权值确定算法。张春森等[8]依据每个特征对应的分类正确率,利用提出的权值计算公式自适应确定在融合特征中每个特征对应的权值,但权值计算公式中的常量取值由人工确定,受人为经验影响。李玉峰等[9]用预先训练好的单个特征对应的分类器模型分别识别训练集中的数据,如果能正确识别,那么该特征对应的权重加1,如此循环计算出每个特征对应的权值。该算法虽然避免了人为干预,但需要多次输入输出,算法复杂度高,且预先的分类器模型质量与初始训练样本质量密切相关。袁广林等[10]提出一种基于概率分布可分性判据确定特征融合权重的方法,根据目标与背景特征值的概率分布动态计算它们之间的区分度,克服了利用单一特征跟踪易受相似目标与背景的影响,提高了算法鲁棒性,但该方法只适应于目标跟踪等相关应用场景,对多分类场景并不适用。
综上所述,权值确定受人为影响小、算法复杂度低和融合效果好成为未来研究的方向。张春森、李玉峰等提出的自适应权值算法虽然在一定程度上提高了融合效果,但受算法设计思想、复杂度和应用场景的限定,权值的确定还受主观因素影响,算法复杂度较高,且应用场景单一。因此,提出一种受主观因素影响小、复杂度低、能适应多种场景的自适应权值确定算法就变得非常重要。
1.1 MFFRW算法框架设计
MFFRW算法属于特征级融合的图像分类算法,包括特征提取、特征归一化、随机权值矩阵生成、特征融合、训练分类器、得到最优权值组合及对应的分类器6个步骤,框架如图1所示。
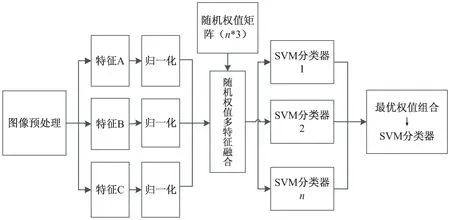
图1 MFFRW算法框架
该算法将单一特征通过随机权值矩阵形成融合特征,然后通过训练多个分类器进一步得到最优权值组合。算法在特征提取阶段和SVM训练阶段彼此独立,满足并行算法的执行条件,因此可利用大数据技术提高运算效率。
1.2 特征归一化
不同特征向量的量纲不同,取值范围也存在较大差异,当融合成一个特征向量时,需要按照一定的规则加以处理[11]。同一幅图像的不同特征之间,数值上存在很大的悬殊,为了避免其对分类结果的影响,文中采用线性归一化方法将特征值缩放到一个指定范围,用如下方法进行特征归一化。
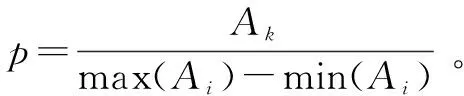
1.3 融合规则
为了实现MFFRW算法,进一步给出它的数学描述形式:
(1)随机权值矩阵。

(2)融合特征向量矩阵。
用x,y,z分别代表3种不同的图像底层特征,通过式1得到融合特征向量矩阵Wn×1,矩阵的每一行代表一个融合特征向量,n的大小取决于随机权值矩阵的行数。
(1)
令
wi=Aix+Biy+Ciz,i=1,2,…,n
(2)
(3)MFFRW算法。
MFFRW算法将数据集中每张图片的x,y,z特征代入式2得到在(Ai,Bi,Ci)权值组合下由融合特征向量组成的数据集,将此数据按2∶1比例分成训练数据集和测试数据集,用训练数据集可训练得到一个分类模型,用测试数据集可得到此模型的分类正确率。如此,n组随机权值就可以训练得到一个分类模型集合A={C1,C2,…,Cn}和一个分类正确率集合B={T1,T2,…,Tn},将集合A中的数据降序排序后得到最优权值组合及其对应的SVM模型。
2 MFFRW算法的并行设计及实现
2.1 Hadoop平台
Hadoop[12]平台是布式处理的软件框架,是一个被认可的用于处理海量各类型数据和应对复杂计算问题的平台。其中HDFS和MapReduce是Hadoop平台的两个核心设计。HDFS是分布式文件系统,采用主/从模式体系结构,实现了对大规模数据集的流式访问。MapReduce是一种并行编程模型,能够将计算任务和数据分配到Hadoop集群的各个节点上,它借助函数式编程方法,将计算分为Map和Reduce两个过程,每个过程的处理均以键值对的形式进行输入和输出,通过定义Mapper类和Reduce类实现一个键值对到另一个键值对的映射。
2.2 Hadoop平台下的MFFRW算法
2.2.1 MFFRW算法并行框架
在Hadoop平台上的MFFRW算法实现过程如图2所示。
整个流程分为2部分,第一部分完成图像Hue特征、纹理特征、PCA-Sift特征的提取,第二部分完成特征融合并得到最优权值组合和对应的分类模型。在特征提取部分采用序列化文件的输入方式处理大量的图像小文件,降低Hadoop集群频繁启动Map任务的消耗,优化集群性能,提高图像特征提取效率。
在输出最优权值组合的过程中,通过重写setup方法、map和reduce方法实现MFFRW算法的并行。同时,为了降低Hadoop系统的I/O消耗,只将模型路径输出到HDFS文件系统,最后通过reduce方法得到最优权值组合及其对应的分类模型路径。
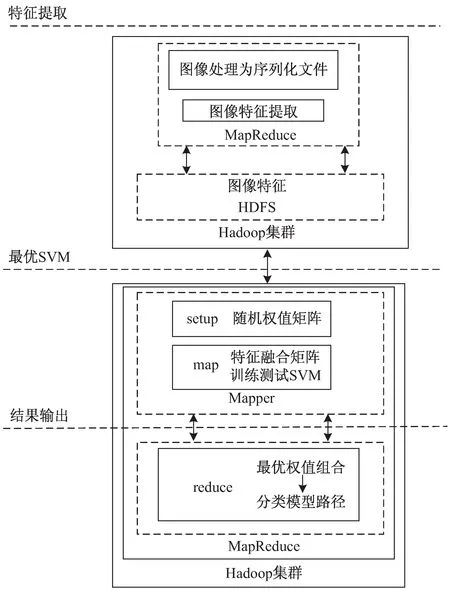
图2 随机权值特征融合SVM图像分类总体框架
2.2.2 算法设计与实现
鉴于OpenCV是一个开源的、跨平台的计算机视觉库,实现了很多数字图像处理方面的算法,同时也提供了大量的Java接口[13]。因此,文中利用OpenCV的函数库实现图像特征提取和分类,并利用PCA算法对Sift特征降维,可以起到对特征向量去噪提纯的作用,提高匹配率[14]。Hadoop平台下用Java语言编程实现了MFFRW算法。此外,由于SVM的各参数设置对分类结果影响很大,所以采用K折交叉验证算法得到径向基函数的最佳参数,通常将K的值设为10。
在MapReduce框架中,Map任务和Reduce任务主要由setup、map或reduce、cleanup函数组成。其中setup函数只在任务开始时执行一次,map和reduce函数循环执行多次直到全部数据处理完毕,cleanup只在任务结束时执行一次。文中利用各函数的运行特点设计实现MFFRW算法,算法描述如下:
输入:n个类别的图像训练和测试数据集S1,S2,…,Sn。
特征提取算法:
Step1:将输入数据集中的小图像文件处理为序列化文件,保存至HDFS文件系统;
Step2:map函数读取序列化文件并将图像统一处理为150*200大小,Step2~4在map函数中实现;
Step3:获取每张图像的类别信息,并提取对应图像的Hue特征(x)、LBP特征(y)、PCA-Sift特征(z);
Step4:将Step3的类别信息和特征组成键值对形式<类别,特征值>,记为:cf1,cf2,…,cfn,保存至HDFS文件系统。
MFFRW算法:
Step1:在Map任务的setup函数中生成随机权值矩阵Mn×3,Step2~6在map函数中实现;
Step2:将cfi(i=1,2,…,n)拆分为x,y,z三个特征分量后代入式2,得到融合后的特征向量集WF;
Setp3:WF按2∶1比例随机分为WF1和WF2,选取WF1作为训练样本,WF2作为测试样本;
Setp4:将WF1的每个元素输入到SVM,得到训练好的分类模型;
Setp5:将WF2中的每个元素输入到训练好的分类模型,得到对应模型的分类正确率Cr;
Setp6:反复执行Step2~5,得到一个由Cr组成的集合{Cr1,Cr2,…,Crn};
Setp7:reduce函数中将Setp6集合中的数据进行排序,得到最大值和对应的权值组合,即最优权值组合。
输出:将最优权值组合和它对应的模型路径输出到HDFS文件系统。
3 实验结果及分析
3.1 实验环境和数据来源
利用5台计算机搭建Hadoop集群,1台为Master节点,其余4台为Slave节点。所有节点计算机硬件配置都采用酷睿i7四核八线程4.2 G处理器,8 G内存,4 T硬盘空间;软件配置如下:操作系统为64位的Ubuntu 14.04,Java环境为jdk1.7.0_79,Hadoop为Hadoop-2.5.1(64位编译)的版本。
实验数据来源于Corel1000图像库中,每个类别的前65张图片作为训练集,后35张图片作为测试集,对于多个SVM,训练和测试的数据总量情况如表1所示。
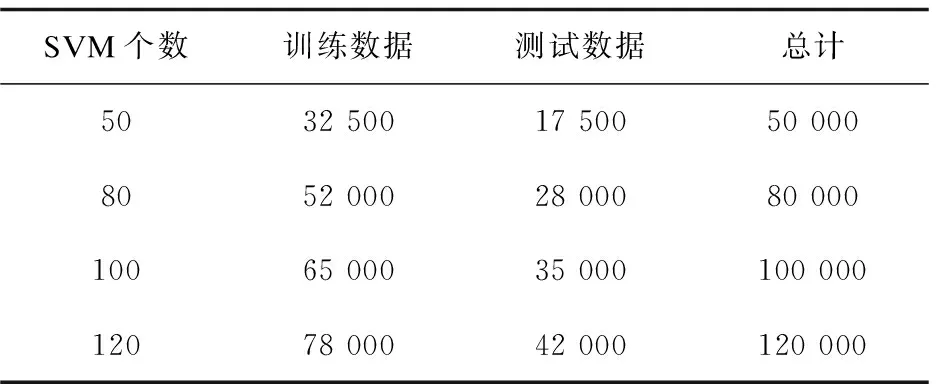
表1 多个SVM训练、测试数据统计
3.2 图像分类及分析
3.2.1 图像分类正确率对比
为验证文中算法的效果,在相同条件下得到MFFRW算法与1∶1∶1融合、文献[6-7]的分类正确率对比结果,如表2所示。
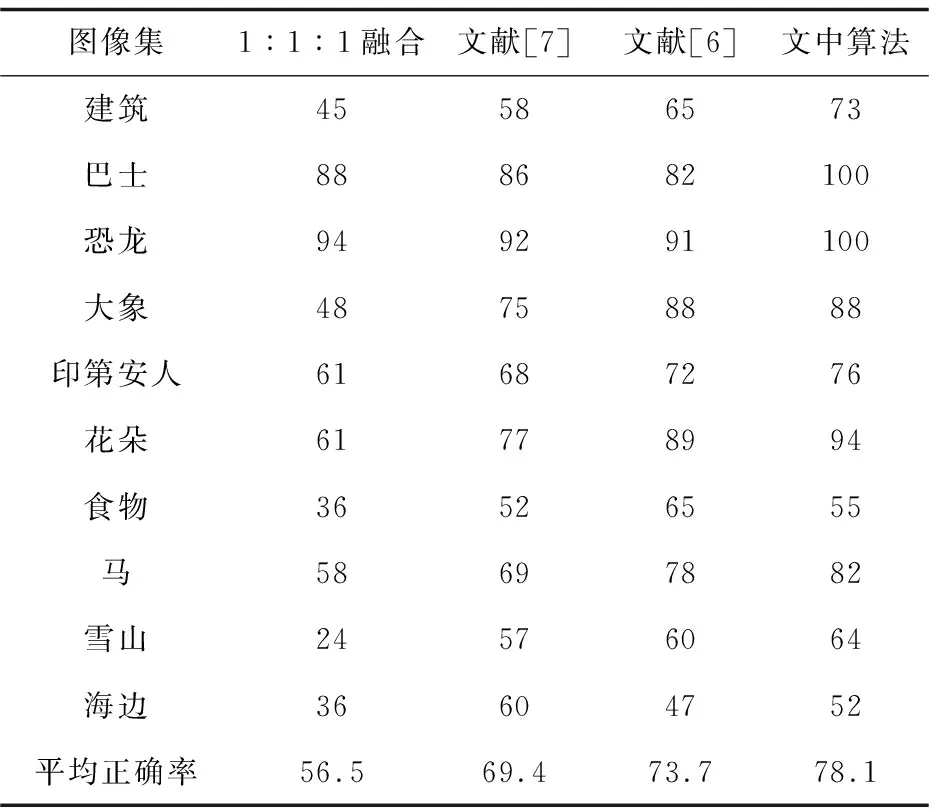
表2 正确率对比 %
从表2可以得知,文中算法的分类效果相对较好,巴士和恐龙的分类正确率达100%,其中单个特征的分类正确率与MFFRW算法的对比效果如图3所示。

图3 单个特征与最优SVM正确率对比
由图3可知,MFFRW算法的分类效果比单个特征更加优越。综上可知,通过文中算法确定的权值组合能更好地描述图像内容。
3.2.2 加速比
加速比[15]指同一任务在单节点环境下运行时间与多节点环境运行时间的比值,是衡量Hadoop平台下并行算法效率的一个重要指标。为验证文中算法在Hadoop平台下的性能,通过训练50、80、100、120个SVM进行了加速比实验,结果如图4所示。
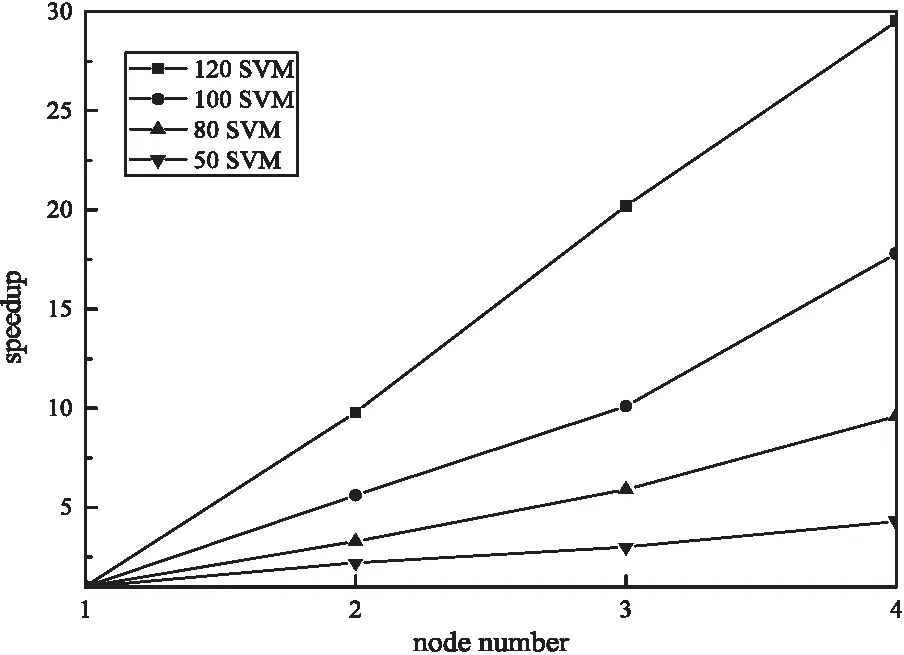
图4 加速比对比
理想状态下,系统的加速比应随着节点计算机的增加而线性增长,但由于受通信开销、负载平衡的原因,实际上加速比并不能线性增长。从图4可以看到,在训练个数不多时,系统的加速比随着节点计算机的增多而增大,但增长幅度并不大,而随着训练个数的增多,系统加速比增长幅度会变大,当训练个数达到120时,系统的加速比几乎呈线性增长的趋势,这进一步说明了Hadoop集群在计算量大时更能体现其优越性。
4 结束语
对Hadoop平台下的MFFRW分类算法进行了深入的探讨和研究,并将MapReduce并行编程模型应用于文中算法以解决计算量大的问题,在保证算法正确率的前提下,有效提升了算法效率。实验结果表明,该算法分类正确率高、运行耗时少、不受主观因素影响,搭建的Hadoop集群能够充分利用各节点计算机的资源,相对于单节点计算机,系统获得了很好的加速比,充分体现了Hadoop集群分布式并行处理的强大运算能力。
随着大数据技术的广泛应用,将大数据技术应用于传统算法已成为新的研究热点。下一步的研究工作中,将扩展Hadoop集群的节点数,调节参数,提升分布
式集群的性能;进一步改进图像特征提取算法。
