健康领域异构数据模式集成研究与实现
2018-11-19田燚林
田燚林,王 勇
(北京工业大学 信息学部,北京 100124)
0 引言
健康数据呈现出很强的异构性,其由很多结构化数据与文档数据组成。异构数据模式集成是解决大规模数据共享问题的一个较好方案,通过数据源集成平台将结构化数据、文档数据等整合起来,并提供统一的透明全局数据集成视图,使其像在单系统中一样进行实时业务数据处理与信息交换,从而很好地解决了健康领域数据的“信息孤岛”问题,同时完成健康领域数据的统一查询[1]。
模式集成一直以来都是研究的热点与难点,传统研究工作主要集中在模式集成理论与关系模式集成方面。但是随着越来越多非结构化数据的不断出现,研究重点则转移到异构XML数据源的模式集成与冲突解决上。PORSCHE是一种混合模式集成算法[2],其可以用于集成XML模式树。它采用模式增长的方式解决多个数据源模式的集成工作,最终产生一个汇聚局部数据源所有概念的全局模式树。当局部数据源模式较为相似时,PORSCHE可以产生很好的集成效果,但其不能较好地支持结构冲突的解决,在生成的全局模式树中存在着很多冗余关系。本文的模式集成算法很好地定义与检测了XML模式集成中的关系嵌套冲突、关系方向冲突及实体属性冲突,减轻了模式集成后的冗余,具有更好的模式集成质量。
1 模式集成概述
在异构数据源集成系统中,各局部数据源的数据模式是由不同用户、基于不同应用目的与数据结构原型设计的,它们之间存在着各种差异及冲突。为了实现对集成系统透明的统一访问,需要研究一种方法屏蔽或解决局部数据源模式的差异及冲突。集成系统是在保证各局部数据源自治性的基础上,集成各局部数据源,提供统一访问接口,通常采用的办法是在异构数据源集成系统中构造一个全局模式[3]。
全局模式的生成是一个模式集成过程。异构数据源的局部模式之间存在着语义差异、结构差异、表达格式差异、定义规范不一致等问题。模式集成的首要任务即消除各局部模式间的差异,生成全局模式供全局查询使用,同时建立信息映射机制,并建立模式映射相关文档,以便统一查询时的查询分解[4]。
构造全局模式的关键步骤是为异构数据源建立统一的数据模式,通过模式转换算法将异构数据源模式统一到全局的公共数据模式上[5]。本文采用XML Schema作为全局模式的描述。因此,健康领域异构数据的模式集成工作可以转化为XML Schema的模式集成方法。
2 XML Schema模式集成问题描述与研究现状
语义与结构冲突是模式集成领域的两大挑战[6]。当不同数据源用不同元素名称描述相同概念时,或者当不同数据源使用相同元素名称描述不同概念时,则会发生语义冲突。如图1所示,模式树(a)表示医院信息管理系统(HIS)中的病人信息结构,模式树(b)表示健康档案管理系统中的病人信息结构。同样表示病人地址信息,在a模式中使用address名称表示,在b模式中则使用location名称表示。

图1 病人信息两种模式
当不同数据源使用不同结构表达相同关系时,则会发生结构冲突。常见的结构冲突有如下3种形式:①图2(a)表示关系嵌套冲突,是指相似概念间关系被直接表达与间接表达的冲突。当相似概念之间表达相同关系,只是嵌套层次有所差异时,则会发生这种冲突,体现在XML节点树中即是路径长度差异;②图2(b)表示关系方向冲突,是指相似概念之间关系在XML节点树中的方向相反,但它们代表同一种关系;③图2(c)表示实体属性冲突[7],这种冲突是最常见的冲突,在不同数据源模式中,表示同一概念的设计方法不同,有的用属性表达,而有的用实体表达。
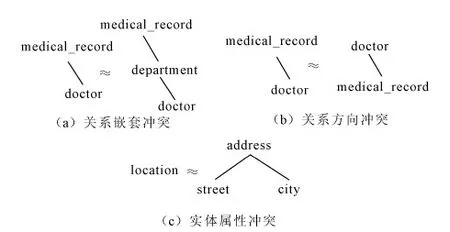
图2 结构冲突形式
3 XML Schema模式集成关键问题解决
XML Schema模式集成分为3步,首先计算源模式之间的语义相似度与结构相似度,解决语义冲突,产生候选匹配映射,其次检测与解决候选匹配映射集中的结构冲突,最后将未产生冲突的概念进行集成,生成全局模式。
3.1 模式集成中的语义冲突解决
3.1.1 语义相似度计算
语义分析作为自然语言处理技术的一个重要方面,其所依赖的语言知识表示中最重要的初始环节即是语义词典。美国Princeton大学的WordNet[8]是语义词典一个非常好的范例。目前,WordNet已成为一个事实上的国际标准,其框架的合理性已被词汇语义学界与计算词典学界所公认。
WordNet 是一个在线词汇参照系统,其独特之处在于其是依据词义而不是词形组织词汇信息。WordNet使用同义词集合(Synset)代表概念(Concept),词汇关系在词语之间体现,语义关系在概念之间体现。WordNet 构造的核心是如何表示词汇概念节点,以及在这些概念节点之间建立各种语义关系。WordNet 将英语词汇组织为一个同义词集合(Synset),每个集合表明一个词汇概念,同时力图在概念间建立不同指针,表达上下位、同义反义等不同语义关系。
用以下公式计算语义相似度:
(1)
首先将属性标签进行分词,通过WordNet获得各个分词含义[9]。其中|Ci|表示概念Ci通过WordNet获得的含义数,SimSen(S1i,S2j)表示概念C1第i个含义与C2第j个含义之间的相似度。WordNet语义词典将所有词组织在树状的层次结构中。在一棵树形图中,任何两个节点之间有且只有一条路径。这条路径的长度即可作为两个概念语义距离的一种度量,可以利用 WordNet中词节点之间上下位关系构成的最短路径计算词语之间的相似度,距离越小,相似度越大。计算公式如下:
(2)
其中,PathLength代表将S1与S2联系起来的路径长度。
3.1.2 结构相似度计算
针对语义冲突中不同数据源用不同元素名称描述相同概念的问题,计算节点之间的语义相似度产生语义相似度矩阵,因而可以被很好地检测出来。但是针对不同数据源使用相同元素名称描述不同概念的问题,则需要综合考虑元素节点的结构信息。
元素节点的结构信息主要包括两部分内容:一是元素节点的属性信息,表示为元素节点的叶子节点;另一部分是元素节点的父节点或子节点信息[10],统称为元素节点的上下文信息。假设A1代表源模式1中的一个元素节点,A2代表源模式2中的一个元素节点,则计算A1节点与A2节点之间的结构相似度即可转换为计算A1节点与A2节点的叶节点相似度及上下文节点相似度。
设A1节点的叶子节点集合为|leaves(A1)|,A2节点的叶子节点集合为|leaves(A2)|,以A1节点作为基准,计算A1节点与A2节点之间的叶节点相似度公式如下[11]:
(3)
|leaves(A1)|代表A1节点的叶子节点个数,分子代表A1节点的叶子节点中与A2节点的叶子节点中语义相似度超过设定阈值的个数。取A1节点中的一个叶子节点,对A2节点的叶子节点进行遍历,如果A2节点的叶子节点中存在与A1节点中该叶子节点的语义相似度大于设定阈值的情况,则保留该节点作为分子。
A1节点与A2节点之间的上下文节点相似度使用以下公式进行计算:
(4)
与叶节点的相似度计算类似,|ContextA1|代表A1节点的父节点与子节点个数,|{A1i|A1i∈ContextA1^∃A2j∈ContextA2,lingSim(A1i,A2,i)≥threshold}|代表A1与A2节点上下文节点集合中语义相似度超过设定阈值的个数。
在语义相似度计算得出映射的基础上,再进行计算得出映射的节点结构相似度。如果结构相似度也大于阈值,则宣布两个节点之间存在映射关系。
3.2 模式集成中的结构冲突解决
上述部分描述了模式集成中存在的3种结构冲突,针对不同结构冲突设计了不同检测方法,结构冲突的检测基于上文生成的候选匹配集。
3.2.1 关系嵌套冲突
在XML模式转换成的树结构中,当相似概念之间的关系采用不同路径长度或不同嵌套结构进行表达时,它们之间则会存在结构嵌套冲突[12]。如图2(a)所示,medical_record//doctor和medical_record//department//doctor都表示病历与医生之间的关系,只是路径长度不同。因此,结构嵌套冲突可以采用如下数学公式进行检测:
len(x1//y1)≤maxlen
len(x2//y2)≤maxlen
|len(x1//y1)-len(x2//y2)|≤maxdis
(5)
x1、y1代表数据源1中的两个节点,x2、y2代表数据源2中的两个节点。(x1,x2)(y1,y2)是上文生成的候选匹配映射。len(x1//y1)代表x1节点到y1节点的路径长度,由于关系型数据库中的1∶1和1∶n关系都为直接关联,而m∶n关系一般会用1∶n与m∶1进行描述。关系模式转换到XML模式后,会以嵌套结构表示关系。因此,关系嵌套冲突只考虑嵌套层次相差一层的情况,即路径长度相差不超过1。因此,maxlen取值为2,maxdis取值为1。针对关系嵌套冲突,在合并为全局模式时,只取路径长度大的关系即可。
3.2.2 关系方向冲突
当相似概念之间的关系在XML模式树中展示为不同路径方向时,它们之间则存在关系方向冲突。如图2(b)所示,medical_record//doctor和doctor//medical_record都代表病历与医生之间的关系,只是路径方向不同。关系方向冲突可以采用以下数学公式进行检测:
len(x1//y1)≤maxlen
len(y2//x2)≤maxlen
|len(x1//y1)-len(y2//x2)|≤maxdis
(6)
x1、y1代表数据源1中的两个节点,x2、y2代表数据源2中的两个节点。(x1,x2)(y1,y2)是上文生成的候选匹配映射。len(x1//y1)代表x1节点到y1节点的路径长度。与结构嵌套冲突类似,maxlen取值为2,maxdis取值为1。针对关系方向冲突,在合并全局模式时,任取一个关系并入即可。
3.2.3 实体属性冲突
当相同概念在一个数据源中被表示为属性,在另一个数据源中被表示为实体jf ,则会存在实体属性冲突[13]。如图2(c)所示,location与adress都表示地址信息。针对实体属性冲突的检测规则如下:(x1,x2)为候选匹配映射,x1为叶子节点,x2为非叶子节点,同时x2节点到x2叶子节点的长度为1。针对实体属性冲突,在生成全局模式时,将x1节点并入x2节点即可。
3.3 模式集成算法描述
(1)将各个局部数据源模式进行模式抽取与转换,生成各个局部的XML Schema文件。
(2)对各局部的XML Schema文件进行模式编码,转换成模式树结构。
(3)对各个局部的XML Schema模式树进行语义相似度与结构相似度计算,生成节点之间的候选匹配映射。
(4)针对生成的候选匹配映射集进行结构冲突检测,并解决结构冲突。
(5)将不产生冲突的节点并入全局模式树中,生成全局XML Schema文件。
模式集成流程如图3所示。

图3 模式集成流程
4 实验结果
4.1 评价标准
对于全局模式集成的有效性评估中,分别使用准确率 (Precision)、 召回率 (Recall) 与 F 值 (F-measure) 表示模式集成算法的正确程度、完善程度与权衡结果[14],计算公式如下:
准确率:表示在模式集成中自动匹配的正确匹配占总自动匹配结果的比例。
(7)
召回率:表示在模式集成中自动匹配的正确匹配占应有正确匹配的比例。
(8)
F值:表示模式集成结果中错误匹配与丢失正确匹配的比值,可较为客观、全面地评价最后的匹配质量。
(9)

4.2 实验结果与分析
本文算法主要针对健康领域异构数据的模式集成,因此选取HL7官方提供的5个健康领域的XML Schemal作为实验数据集进行模式集成,实验结果如图4所示。
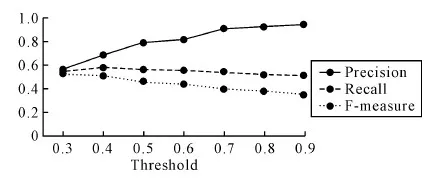
图4 模式集成匹配质量
由图4可以看出,当语义相似度阈值设为0.9时,本算法具有较高的准确率、召回率与F值。因为健康领域数据具有较高相似度,因此相似度阈值设定得越高,算法集成质量越高。
取阈值为0.9时,比较本文算法与PORSCHE算法结果如图5所示。
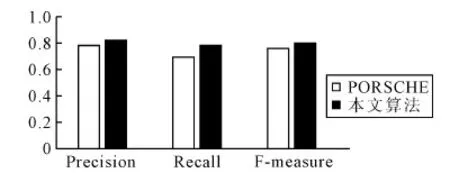
图5 模式集成算法比较
从上述实验结果可以看出,对于健康领域的异构数据,将本算法与PORSCHE算法进行模式集成都有着较高质量,但是PORSCHE算法无法解决关系方向型的结构冲突,因此生成的集成模式较为冗余。本文算法对模式集成中的结构冲突重新作了检测,能较好地解决关系方向冲突问题,对于集成后的全局视图,可以减少冗余。
5 结语
本文研究了XML模式集成中的相关理论与算法,借鉴PORSCHE算法的模式集成思路,设计了新的结构冲突检测及解决方法,重点解决了PORSCHE算法没有解决的关系反向型结构冲突。经过试验证明,本算法完成的XML模式集成能够很好地解决结构冲突问题,减少了全局模式中的冗余关系,精简了全局模式,同时利用WordNet计算语义相似度,从而提升了模式集成后自动生成的匹配准确度,为健康领域数据的统一查询工作打下了良好基础。
