基于加权KNN与随机森林的表情识别方法
2018-11-19冯开平赖思渊
冯开平,赖思渊
(广东工业大学 计算机学院,广东 广州 510006)
0 引言
人脸表情识别主要涉及图像处理与模式识别两个方面,在教育、游戏[1]、医学[2]、动画[3-4]等领域都有着广泛应用。表情识别过程分为特征提取与分类识别两部分,常用的特征提取算法有PCA[5]、LBP[6]以及Gabor小波变换[7]。好的分类模型能够提高表情识别准确性,降低计算复杂度。常用于表情识别的分类方法有K最近邻(KNN)、支持向量机(SVM)[8]、神经网络(NN)[9-10]、分类树(CT)[11]与稀疏表示(SP)[12-13]等。Qite Wang等[14]提出一种基于PCA与KNN的表情识别方法,并用于在车联网中识别路怒症、疲劳驾驶与酒后驾驶状态。卷积神经网络[15]虽然分类准确率高,但需要大量参数,而且当数据出现部分缺失时容易发生错误。分类树计算复杂度不高,能够处理一定的数据缺失,但对于噪声数据比较敏感,容易导致过拟合。针对SVM计算量大以及KNN分类精度不高问题,王小虎等[16]提出一种组合FSVM与KNN的方法,通过区分度函数判断输入样本的区分程度,然后自适应地选择分类器;Zineb等[17]提出一种基于一维隐马尔可夫模型的方法,首先通过小波变换提取特征,然后通过线性判别分析法降低数据冗余度,从而减少计算量。
本文在分析上述方法后,提出一种结合加权KNN和RF[18]的分类器。首先通过人脸对齐方法SDM[19]将训练样本的人脸特征点提取出来,生成一张平均特征点分布图,然后计算测试样本与平均人脸特征点之间的距离,最后根据距离选择分类器,利用加权KNN算法对表现程度弱的样本进行分类,其余样本交由RF处理。实验结果证明,该方法具有一定可行性,在改善分类效果的同时,能够减少KNN算法的计算量。
1 相关算法描述
1.1 加权KNN算法基本原理
KNN算法是一种简单、容易实现的分类方法,尤其适用于多分类问题。其基本原理是给定训练集T,其中的每个样本都有一个类别,输入一个没有分类的测试数据,遍历所有样本,计算测试数据与样本之间的距离,然后选取距离最近的k个样本,将k个样本中出现最多的类别作为测试数据类别。虽然KNN算法易于理解,但当训练集中的样本类别不均匀时,如一个类的样本较多,而其它类别样本过少,则容易使分类结果受到影响。另外当训练集过大时,计算量也会比较大,从而降低了分类效率,不适合直接用于表情识别。针对上述情况,可以采取加权方式改善表情识别的分类效果。
在特征提取阶段,将人脸的68个特征点提取出来,如图1所示。从图中可以看出,不同特征点对于表情的贡献度不同,如果同等对待每个特征点,则可能会对最后的分类结果造成影响,从而降低识别率。例如每个人的轮廓不同,因此可以认为轮廓对表情的贡献度较低,计算距离时可以删除该部分特征点,降低数据维度,以达到减少计算量的目的。

图1 不同表情特征点分布
用欧式距离计算两个样本之间的距离D:
(1)
其中,I为特征点集合,x、y、w、v分别为测试样本与训练样本的特征点坐标。

最常见的加权方式是用距离D的倒数作为权重,权重W计算方式如下:
(2)
其中,C为一个常数,因为测试样本有可能与训练样本完全一样或相当接近,将导致权重趋于无穷大,因此在求距离倒数时需要额外加上一个常数。
距离倒数加权方法的优点在于计算简单,但其对于较近的样本会分配很大的权重,对稍远的样本分配权重时则衰减很快。该加权方法在表情识别中效果一般,对噪声数据变得较为敏感。
还有一种常用的加权方式是使用高斯函数加权,其公式如下:
(3)
其中,a为曲线高度,b为曲线中心线在横轴的偏移,c为半峰宽度。当a=1,b=0,c=0.5时,高斯函数的函数图像如图2所示。

图2 高斯函数图像
从图2中可以看出,当距离等于0时,权重获得最大值1,随着距离增加,权重逐渐减少,但是永远不等于0,因而能够满足实际应用需要。实验结果证明,在本文中使用高斯函数加权时的分类效果优于距离倒数加权。
首先对求得的样本距离从小到大进行排序,选择距离最近的k个训练样本进行加权。设与第n个训练样本属于同类的概率为Pn,通过以下公式计算Pn:
(4)
其中,Wn为第n个样本权重,分母为距离最近的k个样本权重之和。
1.2 随机森林基本原理
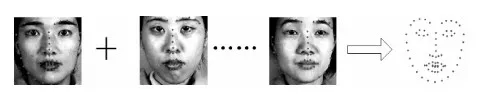
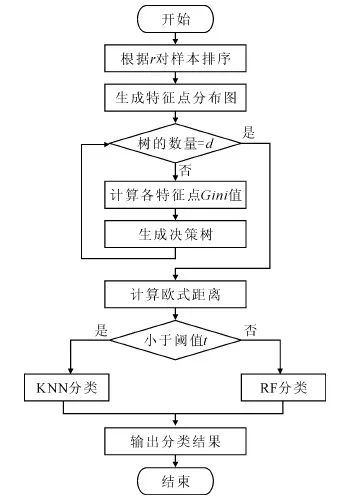
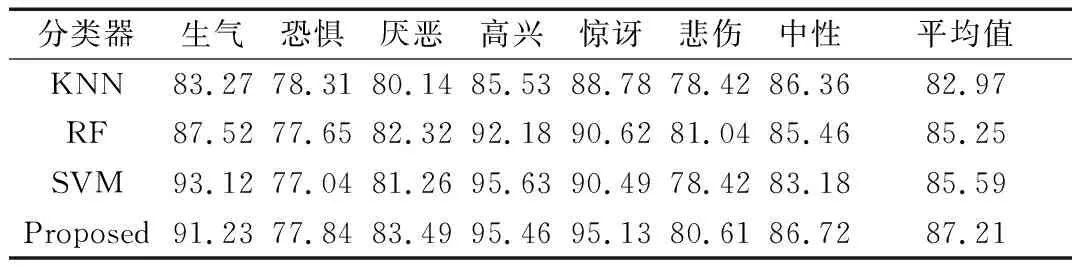
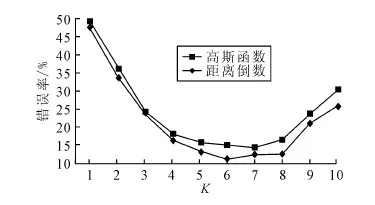
随机森林是通过随机构建多棵决策树对样本进行训练与预测的一种分类器,其中的每棵决策树都按照如下规则生成:①设样本集大小为N,对于随机森林中的每棵决策树,随机有放回地从训练集中抽取N个样本,作为决策树的训练集;②设训练集中的每个样本特征维度为M,随机从M个特征中选择m个特征子集,其中m< 加权KNN算法能够有效识别表现力较弱的表情,但是如果样本过多,则会导致KNN算法计算量增大,而随机森林训练速度较快,能在不作特征选择的前提下有效处理高维数据,并且对特征的重要性进行排序。为了充分结合两者的优越性,提高人脸表情识别率与识别速度,同时降低计算复杂度,本文提出一种加权KNN与随机森林相结合的分类器。该分类器将JAFEE表情数据库中的语义程度评分作为样本的一部分特征,通过判断测试样本是否属于表现程度较弱的表情进行分类器选择,以充分发挥改进KNN算法的优势,识别表现程度较弱的表情,同时利用鲁棒性较好的随机森林对其它表情进行分类,算法基本流程如下: (1)根据语义程度评分r对样本从低到高进行排序,为了防止样本不均匀导致的分类缺陷,需要保证加权KNN算法中样本的平衡性,按比例从排序结果中抽取样本,根据样本的特征点分布,计算坐标平均值,然后生成一张平均特征点分布图,如图3所示。 图3 生成平均特征点分布 (2)按下列步骤随机抽取样本,训练d棵决策树作为弱分类器: 计算每个特征点的基尼不纯度(Gini impurity),Gini值越大,则意味着分裂后的总体内包含的类别越杂乱。对于样本集S,Gini值计算公式如下: (5) 其中,pk表示样本集分类结果中第k个类别出现的概率。 为了选择最好的特征进行分裂,加强随机森林中每棵决策树的分类能力,从而使随机森林获得最佳分类效果,本文选择最小基尼增益值GiniGain作为决策树分裂方案。GiniGain计算公式如下: (6) 其中,S1、S2为样本集S的两个样本子集,n1、n2为两个样本子集的数量,N为样本容量。 对于样本S中的特征,计算任意可能的特征值组合的GiniGain,最后选择GiniGain最小的特征值组合作为决策树当前节点的最优分裂方案,并联合训练出多棵决策树作为随机森林分类器。 (3)计算测试样本与新生成特征分布图的距离,当距离小于阈值t时,认为该测试样本属于表现程度较弱的一类,选择加权KNN算法对其进行分类;当距离大于t时,选择随机森林进行分类。当选择加权KNN算法进行分类时,输出分类结果。算法流程如图4所示。 图4 算法流程 将分类器用于测试样本之前需要验证其有效性,以避免测试时出现过拟合现象。在KNN算法中,k的取值对分类效果有很大影响,若k值太小会造成过拟合现象,导致分类器分类错误。因此,Ghosh[20]提出一种基于贝叶斯的方法选择较优的k值,但是计算比较复杂。本文采用十折交叉验证方法确定k值。 十折交叉验证是验证分类器泛化性能的一种方法,其基本思想是通过对训练集进行分组,将其平均分为K个子集,每个子集分别作为一次测试集,其它K-1个子集作为训练集,从而得到K个分类模型,然后用K个模型分类准确率的平均数评估分类器性能。通过十折交叉验证能够为算法选择一个较优的参数k,以避免出现过拟合现象。 实验中采用JAFFE表情数据库,表情库中包含10个日本女性的7种不同表情,包括生气、恐惧、厌恶、高兴、惊讶、悲伤和中性,每人同种表情的图像有3~4幅。实验中,从每种表情中随机选取22~23幅共160幅图像作为训练集,然后将160幅图像平均分为10组进行交叉验证,评估分类模型效果并且确定加权KNN算法中的参数k,每次测试时从剩下图像中随机选取20幅图像作为测试集。为了对比分类效果,分别采用KNN、RF、SVM与本文方法对数据集进行实验。4种分类器表情识别率如表1所示。 表1 4种分类器表情识别率 单位/% 图5为进行十折交叉验证时不同加权方法的错误率。从图中可以看出,高斯函数加权的识别错误率都低于倒数加权,因此认为高斯函数加权的方式优于倒数加权。同时随着k值增加,错误率趋于稳定,当k为6时错误率最低,但是随着k值继续增加,噪声越来越大,导致分类模型效果变差。 图5 十折交叉验证错误率 本文提出的加权KNN结合随机森林的分类器在表情识别领域优于普通的KNN和SVM方法,其具有以下特点:①减少了训练模型参数,通过加权方法改善了KNN算法分类效果;②与随机森林相结合,减少了KNN算法的计算量并且提高了随机森林的可调控性,充分发挥了随机森林鲁棒性强、训练速度快的优点,降低了计算复杂度。尽管通过在JAFFE表情库中的实验证明了该算法的可行性与稳定性,但若只考虑人脸特征点分布仍然不太严谨,因为每个人的脸型存在一定差异,因此下一步研究中需要考虑融合其它特征信息。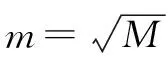
2 加权KNN结合随机森林算法
2.1 算法描述
2.2 分类器有效性验证
3 实验结果与分析
4 结语
