基于优化分类的数据增广方法
2018-11-17蒋梦莹林小竹
蒋梦莹,林小竹,柯 岩
(1.北京石油化工学院 信息工程学院,北京 102617;2.北京化工大学 信息科学与技术学院,北京 100029)
0 引 言
传统的图像分类识别方法大多需要人为地进行特征提取,图像信息剧增使其难以满足人们生活需求。深度学习是近十年来人工智能领域取得的重要突破,通过逐层抽象,深度挖掘数据的本质信息。2012年,krizhevsky等[1]设计的AlexNet卷积神经网络结构在ImageNet图像竞赛中取得冠军。GoogleNet[2]和VGGNet[3]是2014年ImageNet竞赛的双雄,两类模型的共同特点是网络结构比以往的模型更深。在2015年ImageNet竞赛上,MSRA何凯明团队的深度残差网络(residual networks,ResNet)[4]大放异彩,残差网络使网络结构更深,分类正确率更高。随着卷积神经网络的结构不断加深,网络参数越来越多,在有限的训练数据集下,容易发生过拟合现象,使图像分类的正确率下降。提高图片分类正确率的方法主要分为两种:一种是调整网络的结构或改进对各层特征的处理能力,通过改变网络中的激活函数(ReLu)[5]、引入dropout层[6]等方法来提高模型特征学习的能力,进而提高模型分类的正确率;另一种是从数据集入手,通过扩增数据集增加训练集样本来提高模型分类正确率。
本文提出一种优化分类的数据增广方法,通过对训练集某一类或几类样本进行数据增广,提高模型分类正确率,并通过实验验证了方法的可行性。本文采用Caltech-101[7]数据集和Corel1K数据集,在开源的深度学习框架Caffe[8]提供的CaffeNet模型上进行实验,采用预训练模型初始化网络参数,然后利用训练集进行微调。通过分析训练集每类的正确率对分类效果不好的一类或者几类后进行数据增广,一定程度上提高了识别的准确率。
1 卷积神经网络
卷积神经网络是常见的深度学习框架之一,已经成为众多科学领域特别是在模式分类领域的研究热点。由于卷积神经网络在进行图像处理的过程中,不需要对图像进行复杂的前期预处理工作,可以直接地输入原始图像,因而得到广泛应用。卷积神经网络是为了识别二维形状而特殊设计的一个多层感知器,这种网络结构对比例缩放、平移等变形具有一定的不变性。卷积神经网络主要包括卷积层、激活函数层、下采样层、局部响应归一化(local response normalization,LRN)层、全连接层和Softmax分类层。卷积层采用多个过滤器(即卷积核)来过滤图像中的各个小区域,从而实现对图像特征的提取。在进行卷积操作后,图像仍然很大,为了降低数据维度,对图像进行下采样操作。在典型的卷积神经网络中,前几层都是卷积层和下采样层交替,在靠近输出的最后几层通常为全连接层(如图1所示)[9]。卷积神经网络的训练过程主要包括前向传播和反向传播两个过程,主要是学习卷积层的卷积核参数和层间连接权重等网络参数。
本文采用的CaffeNet网络结构,CaffeNet与AlexNet结构相似,区别在于池化和归一化的顺序不同。CaffeNet包含5个卷积层、3个下采样层、2个局部响应归一化层、3个全连接层以及1个softmax分类层。整个网络的训练过程分为前向传播和反向传播,前向传播是隐层提取特征的一个过程,主要通过卷积和池化操作实现。反向传播采用BP反向传播算法传递误差,求解最优参数。误差最小化求解使用的是随机梯度下降法来更新权值。网络的各层网络参数见表1,n表示分类类别数。
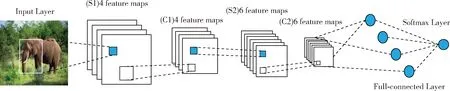
图1 典型的卷积神经网络结构
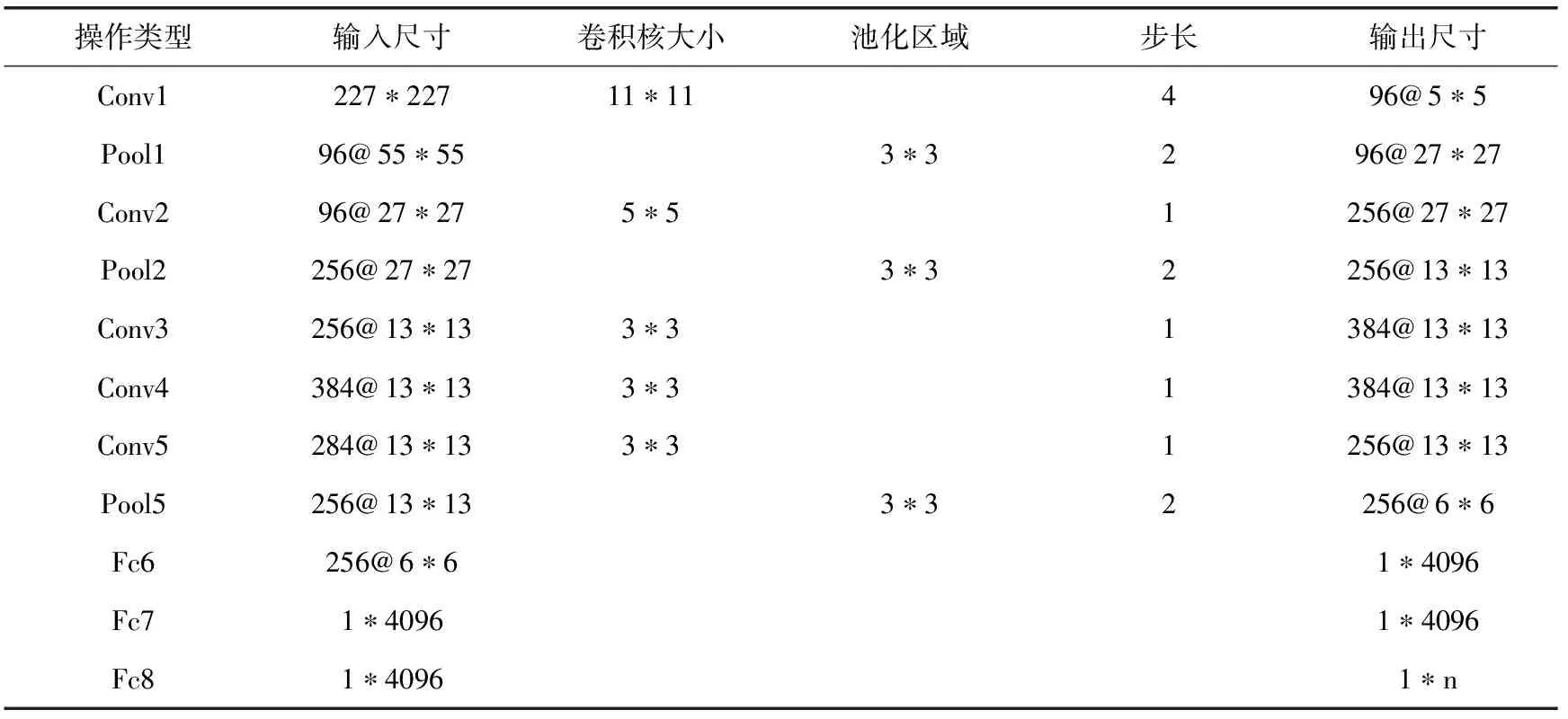
表1 CaffeNet网络参数
对于卷积层输入X,二维卷积过程
(1)
其中,x表示输入X中卷积区域M中的元素,w表示卷积核中元素,m、n表示卷积核大小,b表示偏置,f(·)称为激活函数,采用的是ReLu激活函数,即ReLu=max(0,x)。在进行卷积时,常对图片进行边缘填充,在图片进行卷积操作后保持图片大小不变,如表1的第2、3、4、5卷积层所示。
下采样层采用最大池化方法,取下采样卷积核大小的对应位置最大值。对于下采样层输入Y,下采样过程
pool=down(max(yi,j)),i,j∈p
(2)
其中,y表示下采样层输入Y中池化区域p中的元素,down是下采样过程,即保留下采样区域的最大值。通过下采样操作可以使图片具有一定的缩放不变性。
全连接层将所有二维图像的特征图像拼接为一维特征作为全连接层的输入,对于全连接层输入z,公式如下
full=f(w*z+b)
(3)
输出层采用softmax分类器进行分类。LRN层[10]是2012年Hinton等提出的,LRN层的作用是对局部输入区域进行归一化处理,使响应值较大的值相对更大,提高模型的泛化能力。
本文在训练网络模型时采用微调网络模型参数的方法,即使用在ImageNet数据集上进行预训练后得到的模型参数来作为初始化CaffeNet网络模型的参数。保持网络底层的参数不变,利用训练样本进行微调,只训练最后一层全连接层的参数。由于网络底层的参数是最难更新的,而从ImageNet数据集上学习得到的底层滤波器往往描述了各种不同的局部边缘和纹理信息,这些滤波器对一般的图像有较好的普适性。
2 改进的数据增广方法
2.1 数据增广
数据增广的思想来源于著名的EM算法(expectation maximization algorithm),它是EM算法的一种小样本形式。数据增广算法的提出是为了模拟不正常参数的后验分布。
在训练深度神经网络时,往往需要大量的训练样本输入,使网络模型有更好的泛化能力。而实际中,由于训练集样本数是有限的,网络模型的复杂度也在逐渐增加,使得模型对训练样本特征的表达能力下降,网络容易发生过拟合现象。解决过拟合的方法有很多,针对数据集有限的情况,研究者们提出数据增广方法,通过人工增加训练样本数据量来提高分类准确率。
自然图像的数据增广方式有很多,如①对颜色的数据增强,即图像亮度、饱和度、对比度变化等的增强;②采用随机图像差值方式,对图像进行裁剪、缩放;③尺度和长宽比增强变换,对图像进行水平、垂直翻转或者平移变换;④对图像引入高斯噪声或者对图片进行模糊处理;⑤类别不平衡数据的增广[11]。
2.2 优化分类的数据增广方法
数据增广方法常用于改善网络模型过拟合。对于训练集测试集正确率都很高的情况,不同类别的特征抽象程度不一,在相同数量的训练样本下,大多数类别能训练得到很高的正确率,而少数具有复杂特征的类别正确率并不高。一般的数据增广方法都是增加训练样本每一类的数量或者在不平衡数据集上通过数据增广来使得数据集的每一类样本数量平衡。本文提出一种优化分类的数据增广方法,首先求出测试集每一类的分类正确率,然后找到测试集中正确率最低的一个分类,即模型对于这一类的分类效果不好,最后对这个分类进行数据增广处理。
卷积神经网络最后一层全连接层与输出层之间实际是对训练样本的特征向量进行分类。最后一层全连接层的特征向量通常为4096个单元(如图2所示)。
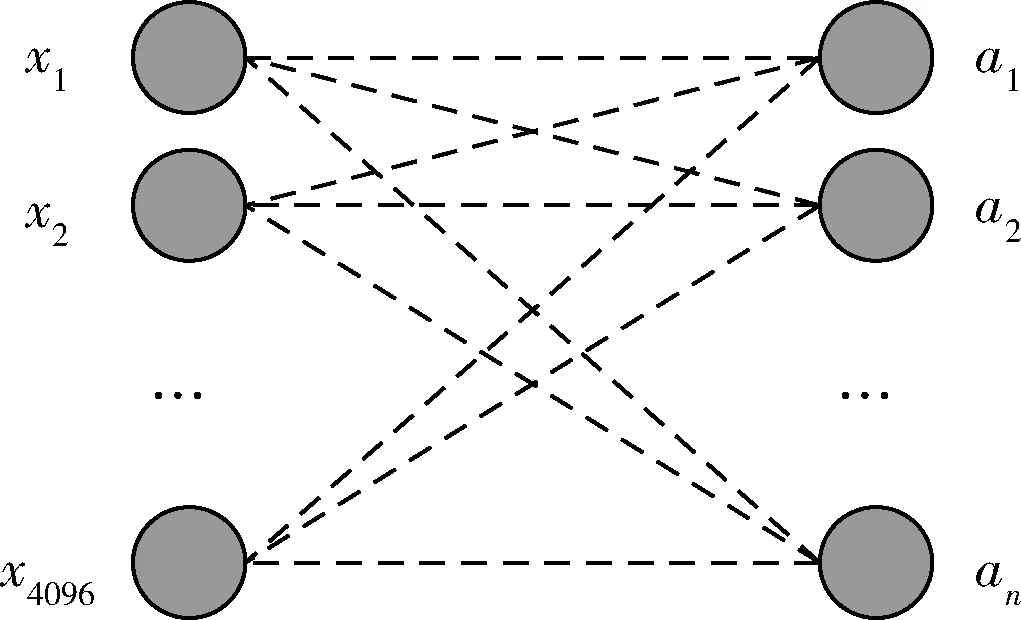
图2 全连接层结构
其中,x1、x2、…、x4096为全连接层的输入,a1、a2、…、an为输出,n表示分类的类别数。当输入一个样本时,得到一个分类类别关于输入的多元方程组如式(4)所示
(4)
其中,w为全连接层的权值参数,b为全连接层的偏置。
单独对第i类分析,输入特征向量与分类类别i存在如图3所示的联系。

图3 全连接层第i类结构
当输入k个样本时,对于每个类别来说,也存在着一个多元方程组如式(5)所示。方程的未知数为该类别所对应的权值参数w,输入样本个数即为构成该方程组的方程个数。
假设每个类别有k个输入样本,对于第i类则有
(5)
实际上,在训练网络模型时,训练集的样本数往往是有限的,每类出现的输入样本数量达不到实际全连接层权值参数的数量,即k<<4096。那么,对于一个多元线性方程组来说,方程组个数小于未知数个数,方程组为欠定方程组,写成矩阵形式如式(6)。欠定方程组有无穷多解也就是方程组具有多组解

(6)
由于方程组的解即是类别i对应的权值参数,权值参数代表每个输入特征x在该类别的所占比例。所以,对于每一个单独的分类来说,决定其分类的特征可能只有少数几类,大多数特征值是不起决定性作用的。
当某一类样本的特征相对复杂时,有限数量的该类别输入样本可能使得其对应的线性方程组的解陷入局部极小的情况,如图4所示。对于该类别来说,网络模型难以学习到较好的特征,即出现网络整体分类正确率相对较高。当增加输入样本个数后,方程组的方程个数增加,方程组的基础解系所含向量个数增加,那么网络模型更容易达到全局最优。
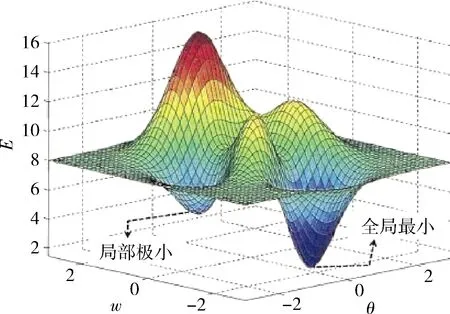
图4 网络模型参数解分布
当网络模型整体分类没有发生过拟合的情况下,单个类别仍存在分类效果不好的现象。优化分类的数据增广方法将分类效果不好的那一类输入样本增加。增加该类的输入样本,也就是增加该类所对应的方程组的方程个数。所以,对单类进行数据增广能够提高网络模型对该类的分类正确率进而提高整体的分类正确率。
3 实验分析
本文所有实验均在深度学习框架caffe上实现,硬件平台为:Intel(R) Core(TM)i7-7700HQ CPU、主频为2.80 GHz、内存为8.00 GB。
3.1 实验数据集
本实验分别采用Caltech-101数据集和Corel1K数据集进行实验。Caltech-101是李菲菲和Marco Andreetto等于2003年在加州理工学院创建的数字图像集。Caltech-101总共9146张图片,包括101类前景图片和一个背景类。每类有30~800张图片,大部分图片有50张。图2为Caltech-101的一部分示例图片。

图5 Caltech-101数据集的部分示例图
Corel1K数据集共包含科雷尔公司收集整理的1000张图片,分为10种类型物体,每种物体有100张。图3为Corel1K的部分示例图片。

图6 Corel1K数据集示例图片
3.2 实验结果及分析
本文将Caltech-101数据集在每类随机选取30幅图像作为训练样本,剩余部分作为测试样本。同样,将Corel1K数据集每类随机选取90幅图像作为训练样本,剩余部分作为测试样本。首先对图像进行预处理,将数据集所有图片缩放为256*256像素大小的图像块。在训练时截取227*227像素的图像,然后对所有图像进行减均值处理。在每个全连接层后,采用Dropout方法防止过拟合,由于Caltech-101和Corel1K的数据集训练样本较少,故将Dropout ratio设置为0.9,抑制更多的神经元连接。初始学习率设置为0.001。
对Caltech-101数据集的训练集和测试集所有类别进行单独测试,训练集正确率均为100%,测试集正确率最低的两组分别为第60类和第74类,分别对这两个分类进行数据增广,其增广前后正确率见表2。
表3为Caltech-101数据集在各模型上的分类准确率以及优化分类后的分类准确率。对Caltech-101数据集进行优化分类的数据增广后,其总体准确率也得到了提高。

表2 Caltech-101数据集第60类和第74类数据增广前后正确率对比

表3 Caltech-101数据集优化分类前后正确率对比
同样,对Corel1K数据集在CaffeNet网络上进行训练后,对其训练集和测试集所有类别进行单独测试,测试集正确率最低的分别为第2类和第10类。分别对其进行数据增广,增广前后正确率见表4。

表4 Corel1K数据集第2类和第10类数据增广正确率对比
表5为进行优化分类前后Corel1K数据集整体正确率。

表5 Corel1K数据集优化分类前后正确率对比
由表2和表4可知,优化分类的数据增广方法能够提高单个类别的分类正确率。由表3和表5可知,对单个类别进行数据增广后,网络模型也能对整体的分类正确率起到提高的效果。
4 结术语
卷积神经网络的优点是自动地、隐式地学习特征,不需要人为地定义特征。当有足够多的样本进行训练时,网络可以学习到很好的特征来进行分类。但实际上,网络模型进行分类训练时所需的数据样本数量往往很难满足其需求。本文从数据增广解决网络模型过拟合的角度出发,提出一种优化分类的数据增广方法。当网络模型没有发生过拟合的现象时,仍能通过优化分类的数据增广方法来提高网络模型对图片分类的正确率。对分类结果进行分析后,将分类效果不好的单个类别进行数据增广,提高这个类别的分类正确率,进而提高网络模型对整体分类的正确率。另外,由本次实验可知,在优化分类的数据增广过程中,对训练集中的某一类进行大量数据增加,容易造成训练集数据不平衡的现象。所以,进行优化分类的数据增广时,需要注意增加的单类输入样本不宜过大。
