基于L-STM模型的中文情感分类
2018-11-17王景中庞丹丹
王景中,庞丹丹
(北方工业大学 计算机学院,北京 100144)
0 引 言
情感分类是情感分析的具体任务,通过分析统计带主观倾向性文本,明晰发表者关于某事物态度,同时把文本区别成正、负情感极性。在电子商务蓬勃发展的网络环境下,产品的评论数据已经成为商家提高产品及服务质量的重要数据来源。这些评论中包含用户对产品各方面的情感倾向,对其进行情感分类不仅可以帮助生产厂商和销售商通过反馈信息来提高产品质量、改善服务、提高竞争力,还可为潜在消费者提供网购指导。文本情感分类能够根据给定的文本数据自动的判别出用户观点的情感极性[1],具有非常重要的学术研究及实际应用价值,也受到广大学术研究者及商家、企业的关注。结合现状来看,主要包含基于规则的、基于机器学习的、基于深度学习的3类情感分类研究。
上述分类方法主要通过向量空间模型完成特征表示,也就是把文本结构化转变成向量形式来计算,而把词当作文本特征后,会造成特征高维情况,一旦训练次数有所失误,高维数据更可能引起过拟合问题,文本分类器泛化能力随之下降。本文基于张量空间模型,将文本数据映射到空间内,同时完成相关计算,面对以上情况时,有助于降低过拟合可能性。除此之外,利用支持张量机(STM)、LSTM神经网络构造出L-STM算法模型,科学设置超平面参数,由此减少计算期间迭代次数,加快文本训练速度。实验结果表明,L-STM模型较传统文本分类模型具有更高的分类准确率。本文创新点与意义如下:利用张量空间模型使文本数据张量化,有助于规避高维数据过拟合现象;基于STM算法提出L-STM算法模型,有效减少了求解最优解的迭代次数,进而缩短了文本的训练时间;3组实验结果表明本文方法的有效性、可行性。
1 相关技术
1.1 Word2Vec
引入词向量的目的是将语言中的词进行数学化,即将词转化为计算机能够识别的形式,从而可通过各种算法完成自然语言处理任务。文献[2]介绍了一种经典的词向量表示方法One-hot repre-sentation,但其缺点是维度过高且不能很好的表达词与词之间的语义关系。
Word2Vec[3]作为Google于2013年开源的工具包,重点在于获得word vector,它高效、容易使用,只需进行相应训练,便能将文本数据转变成K维向量数据。这种算法不仅能获取语境信息、压缩信息规模,还提供CBOW (continuous bag of words model)和Skip-gram(continuous skip-gram model)语言模型,且CBOW、Skip-gram全部拥有输入/输出层与映射层,两者训练过程大体相似。
word embedding训练阶段,由于Skip-gram模型具备高效、准确等优点,故而得到普遍利用。详细结构如图1所示。

图1 Skip-gram模型
若给定一个需要训练的词序列W1、W2、…、Wn,那么Skip-gram模型的目标就是最大化概率取log的平均值即使式(1)最大
(1)
式中:c值的大小与模型的训练效果成正比,即c值越大,效果更理想,然而训练时间也会相应延长[4];对于文本分类而言,仅用保证训练语料库与窗口大小C符合要求,便能快速获得更理想词向量。
现阶段,word embedding常用于POS、Tagging[5]、中文分词、情感分类等方面,实用效果非常显著。
1.2 张量理论
定义1 高维空间中向量自身拓展即为张量,N阶张量是指A∈RI1×I2×…×IN,A中的元素用ai1,i2,…,iN表示,其中1≤in≤IN,1≤n≤N。
定义2n模式积:张量和矩阵的n模式积是指S∈RI1×I2×…IK与矩阵E∈RIN×J的n模式积表示为S⊗E,可得新张量Β∈RI1×I2×…In-1×In×…×Ik,B∈S⊗E值即为一N-1阶张量。
定义3 秩一分解:如果一K阶张量可表示成K个向量外积,那么此向量又叫做秩一分解。也就是
S=∏(1)*∏(2)*…*∏(K)
si1,i2,…ik=πi1πi2…πik
(2)
1.3 支持张量机问题描述


(3)
借鉴SVM最大化分类间隔的思想,引入松弛变量c和惩罚因子ξi(1≤i≤M),得到等价的优化问题如下
(4)
为了求解上式的最优化问题,引入拉格朗日乘子αi≥0,ki≥0(1≤i≤N)。则其拉格朗日函数数为

(5)
(6)
(7)
(8)
(9)
1.4 LSTM神经网络
LSTM[8]是一种特殊的循环神经网络,不仅能够解决RNN的梯度消失问题[9],还能学习长期的依赖关系。LSTM模型用存储单元替代常规的神经元,而每个存储单元是与一个输入门、一个输出门和一个跨越时间步骤无干扰送入自身的内部状态(Cell)相关联的,如图2所示。

图2 LSTM模型
Cell状态是LSTM神经网络的关键,它类似一个传送带可以直接在整个链上运行,只有一些少量的线性交互且信息在上面流传不易改变。
2 基于L-STM模型的情感分类系统
2.1 整体架构
结合实际情况考虑,本次选择半监督学习方式,首先需要完成相关数据集(带标签)预处理,并利用Skip-gram模型直接训练word embedding;其次,把数据由向量变换为张量形式,同时当作L-STM模型输入,经计算分析获取最优解;最后利用决策函数明确文本分类情况,简单来看,决策函数值大于或小于零时,文本级别分别是正和负。基本架构如图3所示。

图3 情感分类流程
2.2 数据转换模块
此次模型输入选择张量数据,有助于降低数据高维与过拟合可能性。以下是向量数据张量化步骤:
(1)预处理完成时需进行有效整理,借此得到文本向量数目是n,并以TF-IDF对这些向量进行加权表示。

(3)数据转化。结合当前映射方式来看,基本包含如下两步:第一,遵照相应规则进行特征排序;第二,遵照相应规律将所有特征向量填充至矩阵。本文按照特征词相关文档频率来排序,然后按给定顺序为张量各特征填充相应内容,而末尾不足位可补0。转换情况参如图4所示。
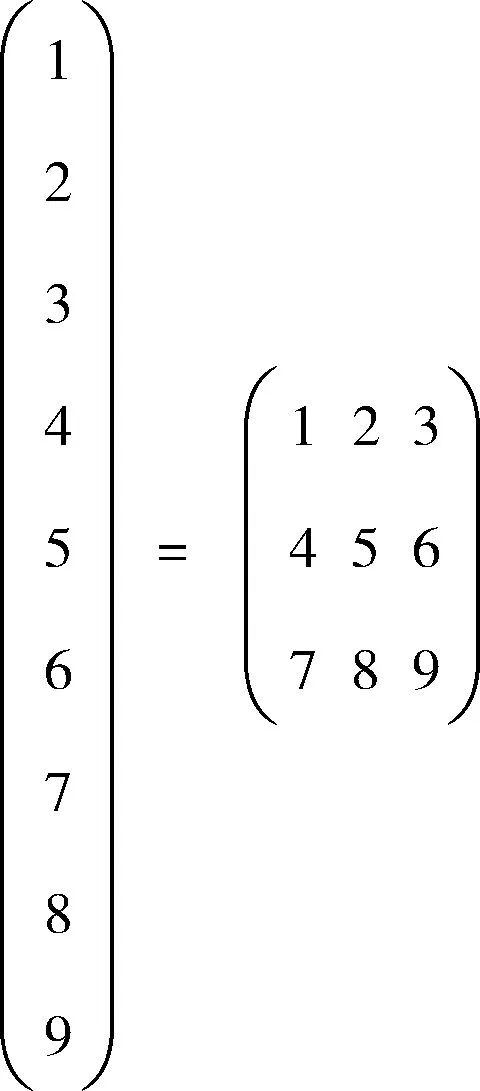
图4 数据转化
2.3 L-STM模型算法描述
L-STM模型算法流程如图5所示。

图5 L-STM模型算法流程
算法描述:

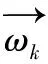


(10)

3 实验及结果分析
3.1 实验环境
实验平台选择Intel Corei7 8 GB内存PC机,基于Ubuntu/Linux系统环境通过Matlab工具编写全部代码,张量计算方面需要使用Matlab Tensor Toolbox,SVM借助LIBSVMS来实现。
3.2 实验数据
为检验该方法对于中文情感分类有无实用性,这里将专家已标注文本集作为测试数据,完成测试分析。根据中文情感文本语料库现状可知,我国常用数据来自于两方面:其一,COAE内部40 000份文本;其二,中科院谭松波博士团队综合汇总所得语料。本次数据集采用该团队有关酒店评论[10]情感语料开展实验,由4000份已标注评论文本集取得1800个文本,褒义、贬义分别有900个,在此基础之上,随机选取3次构造3组实验数据集,具体情况参见表1。
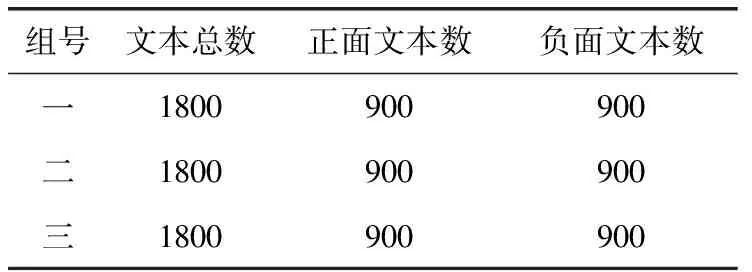
表1 3组实验数据集
3.3 情感分类评价指标
针对文本分类质量,本次通过查准率、查全率、F值进行评价,关于查准率、查全率,分别表示准确判定成某类的文本数和判定成该类的文本总数、实际为该类的文本总数之比,关于F值,可全面反映总体指标



3.4 Word2vec参数调整
参数设置与模型训练关系密切,由于各项参数调整会给训练速度与词向量质量带来各种影响。前面1.1节指出,当训练语料库非常大时,通过有效调整窗口大小C便能得到更高质word embedding。考虑到这一点,这里选择ARR(adjusted ratio of ratios)算法[11]设置word2vec模型窗口,由此讨论C与训练用时、文本情感分类准确率间对应关系。从式(11)来看,SR代表模型分类准确率,T代表训练用时。对于分类准确率与训练时间重要性评价,必须利用AccD这项参数完成,为确保二者获得同样重视,这里把AccD值设定成1%
(11)
由word2vec调参实验来看,为进一步保证分类准确率,采用15种评论数据分类分析,具体情况参见表2。

表2 15种评论数据集
图6主要利用word2vec模型完成评论数据分类工作,结合图例不难发现,各种窗口大小下分类准确率有所区别,如果将word2vec模型窗口大小设定成20,那么能实现最高准确率,无论窗口过大还是过小,分类准确率必定受到影响,故而需要结合实际情况来处理,促使结果更加理想。

图6 窗口大小-准确率
图7主要按照式(11)求解所得各种窗口大小对应ARR值,结合图例不难发现,如果ARR值最大,窗口大小是20。换言之,将窗口设定成20后,可快速获取更高质word embedding。

图7 窗口大小-ARR值
3.5 实验结果与分析
针对基于张量空间的L-STM模型,本次通过3组实验判断其实用价值,第一组主要测试同一分类模型SVM内文本数据向量化、张量化对应分类性能,然后以macroF1、microF1进行分类准确率评价,为提高本次实验合理性,促使结果更加准确,各组数据都进行50次实验,再求出每组数据平均值,具体情况参见表3。

表3 文本表示形式对分类结果的影响
根据表3进行说明,通过表中结果不难发现,同一测试数据、分类模型下,对比文本数据张量化、向量化不难发现,前者分类能力更加强大。
第二组主要测试L-STM、STM模型最大迭代次数和测试精度间关系,详情参如图8所示。

图8 迭代次数与测试精度关系
结合图8进行说明,通过图例分析不难发现,随着迭代次数持续增加,STM和L-STM测试精度不断提高。在同一迭代次数条件下,L-STM、STM测试精度及其升高幅度相比,前者更高,由此验证在模型参数满足收敛条件前提下,前者用时较短,训练较快。
第三组主要测试不同向量描述形式以不同分类模型处理所得分类结果,若文本描述成向量形式,采用典型SVM分类模型,若描述成张量形式,依次通过STM与L-STM模型开展实验分析工作,结果见表4。
根据表4进行说明,通过各评价指标不难发现,L-STM与SVM、STM模型相比,分类性能更加出色,由此能够证明,本次实现的基于张量空间的L-STM模型各方面比较优异,无论从分类准确率亦或训练时间来看,均好于其它模型。

表4 分类结果情况
4 结束语
本文基于STL框架把支持张量机应用于情感分类领域,然后将文本数据张量化作为L-STM模型输入,通过连续优化与迭代,可得参数最优解,再以决策函数为前提明确文本情感极性。这种方法优势明显,一方面可维护文本数据结构信息,另一方面可预防传统向量模型学习期间过拟合问题,不仅如此,L-STM模型在STM模型基础上融入LSTM神经网络,可以让STM模型所得向量序列完成更高等级优化,由此降低参数最优解计算期间迭代次数,节省文本训练时间,最后采用3组实验进行分析,表明情感分类方面L-STM模型更合理、更准确、更强大。
