一种改进的基于文本的重复代码自动识别方法
2018-11-17宾航飞胡志刚
刘 伟,宾航飞,胡志刚
一种改进的基于文本的重复代码自动识别方法
刘 伟1,2,宾航飞2,胡志刚2
(1. 湖南中医药大学信息科学与工程学院,湖南 长沙 410208;2. 中南大学软件学院,湖南 长沙 410075)
代码味道的识别与自动重构是近年来软件工程的热点领域之一,而重复代码是一种在软件工程中较为常见的代码味道。本文在基于文本的重复代码识别方法的基础上,通过词法分析对特定的Token作出处理后再对源代码进行对比,最后通过语法树的对比来对结果进行过滤以降低误报率。测试结果表明该方法对于重复代码有着较好的识别效果。对重复代码的自动识别算法研究有着借鉴意义,在软件的质量、维护等领域上也具有广泛的应用需求。
重复代码;代码味道;自动识别;抽象语法树
0 引言
随着信息技术的高速发展,人们已开发越来越多的软件系统,而软件系统的复杂程度也随之越来越高,软件系统的规模也越来越庞大,软件系统的健壮性、可维护性、可扩展性等质量属性也越来越重要,软件质量已成为软件工程的重要研究分支 之一[1-4]。
随着软件系统规模的扩大、复杂度的提升,即便耗费了大量的人力物力,软件系统的正确性仍然难以保证,不良的代码和低劣的设计也随之出现。在Martin Fowler的《重构——改善既有代码的设计》中使用“代码味道(code smells)”来指代软件系统中的差劲设计和质量低下的模块。在该著作中,将常见的代码味道进行归纳并提出了22种代码味道。
在代码味道中,重复代码是一种重要的代码味道,也是在软件系统中最为常见的代码味道之一。重复代码将导致代码的冗余,同时降低了软件系统的健壮性和可维护性,浪费不必要的工作量。
与其他代码味道相比较,重复代码具有更高的客观性和可度量性,易于使用数学语言或程序语言进行表达,因此,相比其他代码味道的识别,重复代码的识别更加具有可行性。
国外对于重复代码的研究始于20世纪90年代[5],而国内对这方面的研究起步较晚,且在取得的成果上还有一定的差距,但在重复代码检测及重构上仍有一定的成果[6-8]。
国内外已提出许多重复代码识别方法和技术,并且开发出了相应的检测工具。这些方法可大致分为基于文本(context)、基于词法(token)、基于语法(syntax)、基于语义(semantic)、基于度量(metrics)等,还有一些其他方法。
(1)基于文本(context)的识别方法
该方法在对软件系统的源代码进行简单处理后(一般只过滤注释、空行等),直接进行重复代码的判断。在Lingxiao Jing等[9]提出的方法中,先对意义相同的循环控制语句、条件语句等进行了过滤,再进行比较以查找重复代码。Johnson[10]首先提出基于文本的识别方法,该方法使用哈希函数将代码片段进行哈希计算,通过哈希值的比较来查找重复 代码。
(2)基于词法(token)的识别方法
该方法可看作基于文本的识别方法的改进。该方法先将源代码中的内容通过词法分析转换为token序列,再对转换后的token序列进行比较。该方法由Baker[11]首次提出,其采用了后缀树算法来比较token序列的相似性。
(3)基于语法(syntax)的识别方法
该方法将程序解析为语法树,通过查找其中相似的子树来查找重复代码。Baxter等[12]首先将抽象语法树(AST)技术应用于重复代码识别。
(4)基于语义(semantic)的识别方法
该方法以程序依赖图(PDG)为代表,先根据程序的数据流和控制流构建程序依赖图,再通过查找其中的同构子图来查找重复代码。郭婧等[8]在基于程序依赖图的克隆检测方法上,通过对程序语句进行断层和分类处理,以加强对重复代码的识别 能力。
(5)基于度量(metrics)的识别方法
该方法先根据程序的源代码或者抽象语法树进行分析,得出度量因子,通过比较度量因子来查找重复代码。该种方法由Mayrand等人首次提出[13]。
(6)其他方法
其他重复代码识别方法在实际应用中使用较少,如基于低级语言的方法,该方法通过比较编译后产生的汇编代码、Java字节码[14]来识别重复代码。由Philipp Schugerl提出的基于描述逻辑的方法[15],该方法综合了基于语法的方法与基于语义的方法,通过分析程序得到抽象语法树,再使用语义网推理器(semantic web reasoner)进行语义分析,并结合了Hadoop的Map/Reduce框架,着重于对程序的控制流进行比较来查找重复代码。Georges Golomingi Koni-N’Sapu提出的基于重构场景的方法[16],该方法通过对重构方法的分类,指出各种重构方法使用重复代码的情况,根据这些情况寻找程序中是否出现了对应的重复代码。
上述的方法各有其优缺点,本文提出了一种基于文本的、结合词法分析与语法分析的重复代码识别算法,尝试对现有的重复代码查找算法进行改进。
1 重复代码查找算法的评估方法
1.1 重复代码的分类
代码段(Code Fragment)指代任意一段代码行序列,在不同的重复代码识别方法中代码段一般也有着不同的粒度,如类定义、函数定义、逻辑控制语句等。重复代码,又称为克隆代码,即指相同或相似的两个及以上的代码段。其中,一对相似的代码段称之为克隆对,两个及以上的相似代码段称之为克隆群。
在国内外的研究中,普遍根据代码段的文本相似性和功能相似性将重复代码分成了四类[17-18]: (1)除空格、注释、代码布局之外都相同的代码段;(2)除了对变量名、类型或函数名等进行重命名外,代码片段在语法级别相似;(3)进行了增加、删除、修改的代码段;(4)功能相同,但句法上不同的代码段。
在一些研究中,将第1类称为完全克隆,第2、3类称为近似克隆(near-miss clone)[19],而第4类称之为语义克隆(semantic clone)[20]。
1.2 发现率与精确度
为了对重复代码识别方法进行评估,一些研究提出如下定义,用于评估重复代码识别方法的有效性与实用性[21]。
(1)在将重复代码识别方法应用于具体的软件系统时,将软件系统中真实存在的重复代码的集合称之为真实克隆。真实克隆只能通过人工检查来确定,且具有一定的主观性。但它仍然是评估一个重复代码识别方法的基础。
(2)通过某种重复代码识别方法所检测到的重复代码的集合称之为候选克隆。
(3)既属于候选克隆,又属于真实克隆的,即为合理候选克隆。
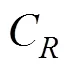
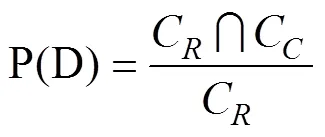
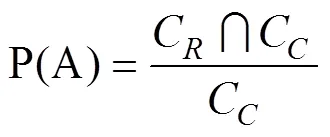
发现率和精确度是用来衡量重复代码识别方法的主要指标,一个好的方法既要有较高的发现率也要有较高的精确度,在本文中,将使用这两个指标来评估各种重复代码识别方法。
2 基于文本的重复代码查找算法设计
本算法在采用基于文本的重复代码查找算法的基础上,结合了词法分析和语法分析等方法,以提高识别率和精确度。
代码之间以代码行为单位进行比较,两段代码之间相同的行数超过所定阈值即可视为重复代码。两个代码行之间通过字符串匹配判断是否相同。
本算法由以下三个步骤组成:
(1)代码标准化。移除源文件中的注释、空白行和其他无效内容,并对代码中的某些Token进行处理以提高发现率。代码标准化可以有效提高发现率,但对精确度有着一定的影响。
(2)代码比较。逐行对代码文件进行比较,记录两个代码片段间重复的行数,结合所定阈值判断两个代码片段是否为克隆对。
(3)结果优化。代码比较之后的结果可能出现较大误差,本算法通过抽象语法树的比较等手段对结果进行过滤,在保证较高发现率的同时,一定程度上提高精确度。
2.1 代码标准化
传统的基于文本的重复代码查找算法有着实现简单,精确度高的特点,但是发现率却很不理想,只对第1类克隆有着较高的发现率。其原因在于代码在被复制的过程中,开发人员可能对代码做出简单的修改,例如对注释、变量名、函数名进行修改、添加或删除的操作,从而产生第2类、第3类克隆代码。简单的基于文本对比的重复代码查找算法,只能识别完全相同的两段文本,因此很难对第2类、第3类克隆代码进行有效识别。
代码标准化可以有效改善上述问题,其作用有如下两个:
(1)降噪
代码标准化可以对代码进行“降噪”,即去除对于代码比较毫无意义且有干扰的元素。
首先,注释普遍存在于各种语言的代码中;同时,开发人员通过多个换行分隔各段代码,以提升代码的可读性;此外,不同的代码具有不同缩进格式,而代码结构层次的不同也会形成不同的缩进。在代码比较的过程中,注释和这些多余的换行、空格显然是要进行消除的。例如,在降噪过程中将去除两个及以上的连续空格,仅保留其中一个。
其次,代码的大小写不同也会对代码比较造成影响,因此在降噪进程中可以统一代码的大小写。
除了注释、多余换行、空格等干扰元素之外,开发人员的编程习惯也会对代码格式造成影响,例如在赋值语句中等号两边使用一个空格间隔或者不使用空格,都于开发人员的代码书写习惯有关。因此,在降噪过程中需要去除等号、括号以及比较符等“间隔符”与其它元素之间的空格,以消除开发人员的代码书写习惯的影响。
针对各种语言特性,可以设计相对应的降噪方法:对于Java语言,可去除意义性不强的声明包package以及导入包语句import;对于C/C++语言,可以在降噪过程中去除“#include”等对于代码意义影响不大的代码行。
(2)Token处理
降噪处理可以去除对重复代码有干扰的元素,对提高算法的发现率有一定的作用。但降噪处理只能提高对第2类克隆代码的识别能力,对第3类克隆代码识别效果的提升并不明显。
Token处理即对某些字符串(在代码中可能是方法名,也可能是参数名)进行替换,根据规则全部替换为指定的Token值。例如,将所有变量名替换为字符“p”,将所有数字常量替换为数字0,字符串常量替换为字符串“s”。
通过Token替换,该算法能够有效识别经过修改变量名、类型以及各种常量的重复代码段,从而提升了算法对第3类克隆代码的识别能力。
在本算法中,Token处理可分为三种程度。
(1)不进行任何Token处理,算法将直接对降噪后的代码进行比较。
(2)只对各种常量进行Token处理,将数字常量、字符串常量等替换为一个统一的常量。在本算法中,对字符串常量统一替换为字符串“s”,整数常量统一替换为整数“0”,实数常量统一为“0.0”。
(3)在(2)的基础上,对所有标识符进行统一的替换。即对类型、变量名、函数名等统一替换为p。需要指出的是,由于代码并未进行语法分析,因此在词法分析中,对象的方法名、属性同样会被识别为普通的标识符。如代码“people.getName()”,经过第三种程度的Token替换后会成为代码“p.p()”。该情况的出现会造成大量的误报,因此在第三种程度的代码标准化中,需通过词法分析将方法名、成员变量标识为不进行替换的Token。因此上文中的代码“people.getName()”将替换为代码“p.getName()”,从而在提高发现率的同时,避免大量的误报。
在本算法中,降噪和Token处理都是通过词法分析来完成的,通过这个标准化的过程,能有效地提高本算法对于第2类克隆的发现率。
2.2 代码比较过程
代码经过标准化处理后,将对其进行比较,并识别出重复代码。本算法以代码行为单位进行文本比较。
该过程中有两个重要阈值:重复代码阈值和不匹配行阈值。
(1)重复代码阈值声明了当两段代码之间有多少行代码匹配时即可被视为重复代码。该阈值对整个算法至关重要,尤其是代码标准化过程会使得大量的代码行在标准化之后成为了匹配的代码行,因此这个阈值的设定会大幅地影响整个算法的发现率和精确度。
(2)在第3类克隆中,代码片段可能存在某一行或多行代码进行了修改、增加、删除操作。针对该情况,在代码比较过程中设定一个不匹配行阈值,该阈值声明了两个重复代码段之间所允许的不匹配行数的最大值。通过该阈值,使算法能够发现部分第3类克隆。但是,如果将该阈值设定得过大,则会使算法的精确度降低,造成大量的误报。
在代码行的比较过程中,如图1所示,常见的代码行匹配情况有三种:连续匹配、不连续匹配、错位匹配。连续匹配是指两段代码段之间每一行都是完全匹配的,不连续匹配是指两段代码行之间有相同行数的不匹配现象,错位匹配是指两段代码行之间有不匹配现象,但两段代码行之间不匹配的行数不相同。
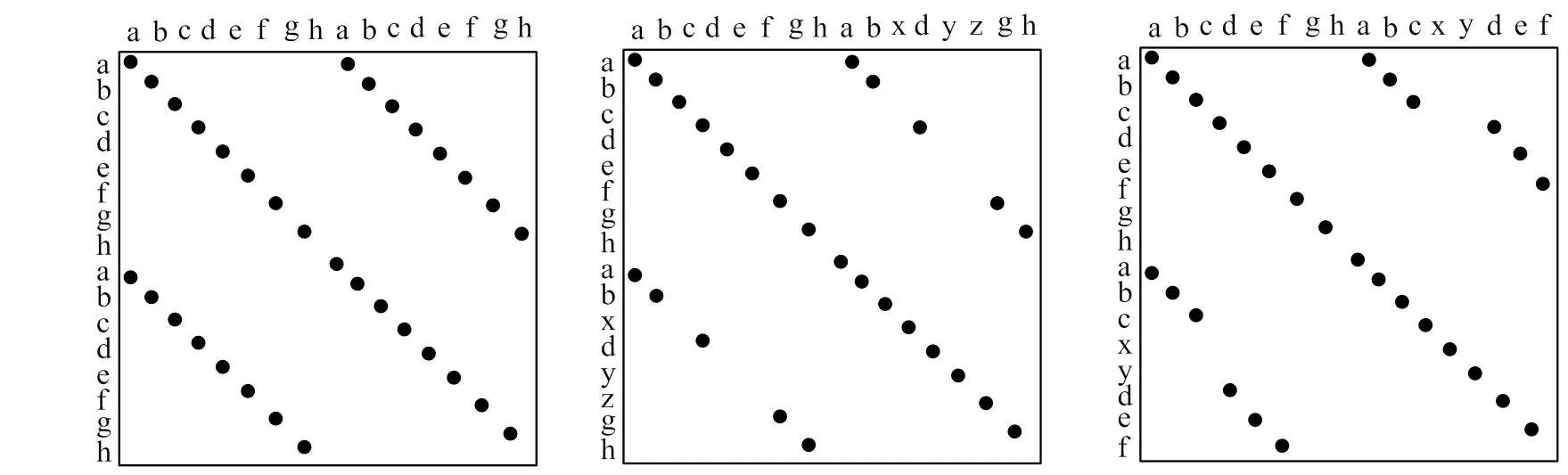
图1 连续匹配、不连续匹配和错位匹配示意图
需要指出的是,在本文所提出的算法中,并没有检测错位匹配的重复代码情况,因为实现错位匹配检测需要付出相当程度的时间复杂度,因此未对错位匹配的情况进行检测。而对于不连续匹配,不匹配行阈值即用于发现不连续匹配。
2.3 基于语法树匹配的结果优化过程
使用在本算法查找重复代码的过程中,标准化过程、不匹配行阈值在提高发现率的同时,也会降低精确度,因此,本算法设计了一个基于抽象语法树匹配的过程,用于去除查找结果中的非重复代码段,以提高该算法的精确度。在该过程中,将两段待比较的代码转换成为抽象语法树,再比较两棵树的匹配程度,计算语法树之间的相似度,过滤掉相似度较低的识别结果。
3 算法验证与结果分析
在本章中将以本文提出的算法进行实验,并对结果进行比较和分析,以判断该算法是否有效,并分析各项参数对于发现率和精确度的影响。从上文对算法的描述可知,标准化程度、重复代码阈值和不匹配行阈值是影响重复代码查找结果的3个重要因素。本章也将研究这3个因素对于查找结果的影响。
3.1 实验数据集
为了对该算法进行实验,收集了一百个开源Java项目的源代码作为实验数据集。
3.2 评价指标
上文中提出了两个用于评估重复代码查找算法的指标:发现度和精确度。发现率是指合理候选克隆与真实克隆的比例,比例值越高说明发现克隆代码的能力越强;精确度是指合理候选克隆与候选克隆的比例,比例值越高说明识别能力越准确。
需要指出的是,在本次实验中,发现度与精确度是无法进行精确衡量的,因为真实克隆代码需要通过人工在实验数据集中查找出来,具有极高的主观性。因此只能先通过较为权威的克隆代码识别工具找出某个小型项目中的候选克隆代码,将该结果作为初步筛选,并在此基础上人工查阅已被标记的克隆代码片段的上下文代码,补充遗漏的克隆代码片段,得到最终的真是克隆代码,以此算出发现率和准确率。
3.3 参考集
在本实验中主要使用PMD的检测结果作为对照集来检验本算法的检测效果(发现率和准确率)。PMD是一种开源的分析Java代码错误的工具。与其他分析工具不同的是,PMD通过静态分析获知代码错误,即在不运行Java程序的情况下报告错误。PMD附带了许多可以直接使用的规则,利用这些规则可以找出Java源程序的许多问题。此外,用户还可以自己定义规则,检查Java代码是否符合某些特定的编码规范。
3.4 实验过程与结果分析
实验挑选了两个开源Java项目进行实验:jManage和freemarker。对这两个项目进行重复代码查找。
上文中提到标准化程度、重复代码阈值和不匹配行阈值是3个本算法中重要的变量。由于作为参考集的PMD工具只有重复代码阈值这一设置项,因此只将本算法中的标准化程度、不匹配行阈值作为变量进行实验,重复代码阈值设置为固定的常量。
标准化程度可分为3种程度,用数字1-3表示。
程度1表示不进行任何Token处理,算法将直接对降噪后的代码进行比较。
程度2只对各种常量进行Token处理,将数字常量、字符串常量等替换为一个统一的常量。在本算法中,对字符串常量统一替换为字符“s”,整数常量统一替换为整数“0”,实数常量统一为“0.0”。
程度3是在程度2的基础上,对所有标识符进行统一的替换。即对类型、变量名、函数名等统一替换为字符“p”。
不匹配行阈值只使用0-3这个范围,因为根据之前的观测发现不匹配行阈值超过3会引起大量的误报,因此不匹配行阈值是没有必要超过3的。
首先实验了算法的发现率,对于jManage项目进行重复代码查找的结果如表1,对freemarker项目进行重复代码查找的结果如表2。
表1 jManage项目中的PMD查找结果

Tab.1 The detection result of PMD for jManage
表2 jManage项目中的重复代码查找结果

Tab.2 The detection result of the proposed approach for jManage
表3 freemarker项目中的PMD查找结果

Tab.3 The detection result of PMD for freemarker
表4 freemarker项目中的重复代码查找结果

Tab.4 The detection result of the proposed approach for freemarker
根据实验结果可以得出标准化程度、不匹配行阈值这两个变量对于重复代码查找的发现率和精确度的影响:
不匹配行阈值一定的情况下,标准化程度越高,算法的发现率也就越高,但精确度也就随之降低。
证明代码标准化在提高发现率的同时也导致了精确度的降低,当然在发现率本来就较高的情况上,再进行标准化对结果也没有太大的影响。而在标准化程度一定的情况下,不匹配行阈值越高,同样算法的发现率也就越高,但精确度也随之下降。因此不匹配行阈值也在提高发现率的同时降低了精确度,而且不匹配行阈值的取值不应该过大,否则会造成大量的误报。但是设置合适的不匹配行阈值,如将其设置为2,对查找第3类克隆是有一定的帮助的。
可以看出,标准化程度、不匹配行阈值对于本算法是至关重要的两个变量,在很大程度上可以影响算法的检测结果。设置合适的标准化程度、不匹配行阈值对于重复代码查找是相当重要的。freemarker项目重复代码查找结果中,在标准化程度为2,不匹配行阈值为0的情况与标准化程度为3,不匹配行阈值为0的情况之间,精确率出现大幅度的下降。经过人工审查发现大量相似的构造函数被识别为克隆代码,而类似构造函数、Getter和Setter等特殊方法不适合被识别为克隆代码。
4 结语
本文设计了一种基于文本的重复代码查找方法,该方法在基于文本的方法的基础上结合了词法分析和语法分析,以进一步提升发现率和精确度。通过实验发现该算法的发现率和精确度在实际项目中都有着不错的表现。
但该方法中的比较算法仅仅考虑了文件之间的两两比较,没有考虑查找多个文件中共同的重复代码,未来的工作将考虑对多个文件中的重复代码进行查找。
[1] 翁秀木. 一个通用的软件质量评估指标体系[J]. 软件, 2015, 36(3): 59-63.
[2] 印杰, 李千目. 软件代码漏洞的电子取证技术综述[J]. 软件, 2015, 36(12): 49-59.
[3] 段明璐, 杨勋姮. 软件故障树算法建模的研究[J]. 软件, 2018, 39(2): 66-74.
[4] 杨勋姮, 段明璐. 软件缺陷分析技术的研究[J]. 软件, 2018, 39(2): 93-101.
[5] BAKER B S. A program for identifying duplicated code[J]. Computing Science and Statistics, 1992, 24(1): 49-57.
[6] 于冬琦, 吴毅坚, 彭鑫,等. 基于相似性度量的面向对象程序方法级克隆侦测[J]. 电子学报, 2010, 38(2A): 174-181.
[7] 于冬琦, 彭鑫, 赵文耘. 使用抽象语法树和静态分析的克隆代码自动重构方法[J]. 小型微型计算机系统, 2009, 30(9): 1752-1760.
[8] 郭婧, 吴军华. 基于程序依赖图的克隆检测及改进[J]. 计算机工程与设计, 2012, 33(2): 595-600.
[9] Lingxiao Jing, Zhendong Su, Edwin Chiu. Context-Based Detection of Clone-Related Bugs[Z]. Proceedings of the 6th Joint Meeting of the European Software Engineering Conference and the ACM SIGSOFT Symposium on the Foundations of Software Engineering (ESEC/FSE), 2007.
[10] JOHNSON J H. Identifying redundancy in source code using fingerprints[C]. IBM Press, 1993: 171-183.
[11] BAKER B S. On finding duplication and near-dulication in large software systems[C]. Washington DC: IEEE Computer Society, 1995: 86-95.
[12] BAXTER I, YAHIN A, MOURA L, et al. Clone detection using abstract syntax trees[C]. Washington DC: IEEE Computer Society, 1998: 368-377.
[13] MAYRAND J, LEBLANC C, MERLO E. Experiment on the automatic detection of function clones in a software system using metrics[C]. Washington DC: IEEE Computer Society, 1996: 244-253.
[14] Ian J. Davis, Michael W. Godfrey. From Whence It Came: Detecting Source Code Clones by Analyzing Assembler[Z]. Reverse Engineering (WCRE), 2010 17th Working Conference on, 2010.
[15] Philipp Schugerl. Scalable clone detection using description logic--IWSC '11 Proceedings of the 5th International Workshop on Software Clones [C]. ACM: New York, 2011: 47-53.
[16] Georges Golomingi Koni-N’Sapu. A scenario based approach for refactoring duplicated code in object oriented systems [D]. Switzerland: University of Bern, 2001.
[17] ROY C K, CORDY J R, KOSCHKE R. Comparison and evaluation of code clone detection techniques and tools: a qualitative approach[J]. Science of Computer Programming, 2009, 74(7): 470-495.
[18] 史庆庆, 孟繁军, 张丽萍, 刘东升. 克隆代码技术研究综述[J]. 计算机应用研究, 2013, 30(6): 1617-1623.
[19] ZIBRAN F M, SAHA R, ASADUZZAMAN M, et al. Analyzing and forecasting near-miss clones in evolving software: an empirical study--Proc of the 16th IEEE International Conference on Engineering of Complex Computer Systems[C]. Washington DC: IEEE Computer Society, 2011: 295-304.
[20] GABEL M, JIANG Ling-xiao, SU Zhen-dong. Scalable detection of semantic clone[C]. New York: ACM Press, 2008: 321-330.
[21] Stéphane Ducasse, Oscar Nierstrasz, Matthias Rieger. On the effectiveness of clone detection by string matching[J]. Journal of Software Maintenance and Evolution: Research and Practice, 2006, 18: 27-58.
An Improved Approach for Automatic Detection of Duplicated Code Based on Text
LIU Wei1,2, BIN Hang-fei2, HU Zhi-gang2
(1. School of Informatics, Hunan University of Chinese Medicine, Changsha 410208, Hunan, China; 2. School of Software, Central South University, Changsha 410075, Hunan, China)
In the recent years, detection and automatic refactoring of code smell is one of the focus topic in software engineering, and duplicated code is a kind of common code smell. Based on the duplicated code recognition method of text, the false positives can be reduced through the lexical analysis to compare the source code after handling the specific token and through the comparison with the abstract syntax tree to filter the results. The test results show that the method has better detection effect of duplicated code. This has great significance in the study of automatic detection algorithm of duplicated code, and there is also wild application in software maintenance and software quality.
Duplicated code; Code smell; Automatic detection; Abstract syntax tree
TP311.5
A
10.3969/j.issn.1003-6970.2018.10.015
刘伟,男,副教授,高级工程师,博士,研究方向:软件工程和数据挖掘;宾航飞,男,硕士研究生,研究方向:软件工程;胡志刚,男,教授,博士生导师,博士,研究方向:软件工程、并行计算和云计算。
刘伟,宾航飞,胡志刚. 一种改进的基于文本的重复代码自动识别方法[J]. 软件,2018,39(10):68-73
