多属性协同过滤推荐在物流配送服务平台的应用①
2018-11-14李建贵
李建贵,孙 咏,高 岑,刘 璐
1(中国科学院大学,北京 100049)
2(中国科学院 沈阳计算技术研究所,沈阳 110168)
随着电子商务的发展,国内市场对物流配送的需求量越来越大,基于双边资源整合,出现了大量的物流服务平台[1],这些平台中服务方案众多,结合实际的应用情景分析,当用户通过物流服务平台选定物流商及其服务发出配送请求,物流商在线确定后线下提供服务 ,在服务执行结束后通过平台对服务评分,除了给出综合评分还会对服务涉及的多个属性如时间、价格等进行评分,综合评分反映出用户对服务的整体偏好,而各个属性的评分反应出用户对服务各方面的偏好[2],如何充分利用多属性评分为用户提供尽可能满足其个性化偏好的物流配送服务是一个值得研究的课题.
目前推荐系统技术是解决用户个性化需求的主要途径,其中协同过滤算法被广泛采用来构建推荐系统,其基本思想是通过对用户-项目评分矩阵分析,过滤掉大量信息,帮用户找出感兴趣的项目[3].该算法基于如下假设: 如果两个用户对某些项目的评分比较相似,则认为两个用户之间的偏好相似,就可以推断这两个用户对其他项目的评分也比较相似,利用这种相似度找出与其相似的用户,将相似用户喜好的项目推荐给目标用户.
使用协同过滤推荐,应当充分考虑被推荐项目在其领域的特征,为此本文进行了相关研究分析.在电商领域,由于商品的种类繁多,如果对同一类商品的评分相似,并不能代表用户对其他类商品的评分相似,目标用户对协同过滤推荐的未接触过其它类商品不感兴趣的可能性很大.与电商领域不同,在物流配送领域,服务种类相对于商品来说比较单一,用户对某一服务的评分相似,说明用户在其价格、时效等方面偏好相似,对于某一目标用户而言,其相似用户喜欢的服务往往能较好的满足其偏好,这是可以将协同过滤应用于物流配送服务推荐的关键所在.
近年来,将协同过滤用于物流配送服务推荐的相关研究较少,文献[4]提出了基于用户属性关注度的协同过滤推荐算法.在物流领域学术研究中,文献[5]利用协同过滤算法设计了应用于物流信息平台的推荐系统框架,文献[6]给出了出了基于协同过滤的物流商推荐算法.
由于传统的协同过滤是基于用户对推荐项目的单个整体评分进行推荐,不再适用于有着多属性评分特点的物流配送服务推荐[7],本文构建一种基于多属性协同过滤的推荐算法,在关键步骤针对物流配送服务的实际情况进行改进,并将该算法应用于物流配送服务平台,通过构建推荐系统,向用户推荐尽可能满足其偏好的物流配送服务,在沈阳市沈北物流信息平台进行了应用验证.
1 基于多属性协同过滤的推荐算法构建
基于多属性协同过滤的推荐是对传统协同过滤的延伸,利用传统协同过滤思想预测用户对项目单个属性的评分值,然后利用所有属性的评分预测值来综合预测产生推荐,通过挖掘用户细粒度的评分数据,能更加细微的洞察用户偏好,产生更精准的推荐,算法构建过程主要包括单属性评分值预测、综合评分预测.
1.1 相关数据定义
U表示用户集,U={u1,u2,…,um}.
S代表项目集,S={s1,s2,…,sn}.
C代表项目属性集合,C={c1,c2,…,cv}.
R代表用户评分集合,R={Ri|Ri代表用户ui∈U的评分集合},对于Ri表示为三元组(USi,TSi,RSi).其中USi代表用户接触过的项目集,有USi={s|s∈S};TSi为用户的项目评分次数统计结果,有TSi={ti,j|ti,j表示用户ui对sj∈U的评分次数};RSi={ri,j,c,k|ri,j,c,k表示当前ui对项目sj属性c的第k次评分值,sj∈USi,c∈C}.
在物流配送服务平台中,Ri∈R则表示用户对所使用物流配送服务时效、时间等属性评价程度关系,即用户ui对配送服务的属性评分数据.
1.2 单属性评分值预测
1.2.1 用户相似度计算
要得到用户的最近邻居集合,需要进行用户间相似度计算.常见的相似度计算方法有Euclidean距离法、Cosine相似度、Pearson相似度和修正的 Cosine相似度[8],本文使用Euclidean距离法,将用户对共同使用过的配送服务属性评分视为多维空间的一点,通过计算两点间距离得到用户关于某一属性偏好的相似度.
对于热门的配送服务,因其在费用、时效等方面有着较高的品质,受到大多用户的一致好评,则不同用户对这类服务的评分相似不能较好的体现其偏好相似,而存在一些服务,不同用户对其评分产生的差别很大,服务满足不同用户需求偏好的程度不同,对于这类服务来说,不同用户的评分相似才能较好的体现其偏好相似,从而在计算用户相似度时的贡献更大.
针对上述情形,本文计算用户相似度时引入服务的个性化特征因子[9],使用公式(1)计算:
为用户ui对服务sj中属性c的评分的均值;,c为使用过服务sj的用户集中所有用户对属性c评分的均值,φ为使用过服务的用户数,σj,c为服务sj在属性c上评分的标准差.
得到服务的个性化特征因子βj,c:
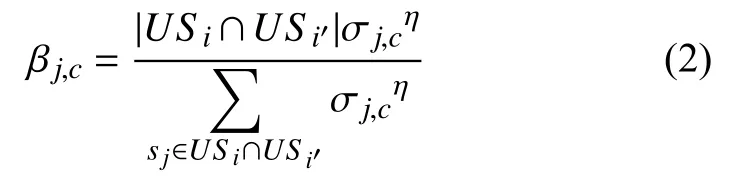
USi∩USi'为用户共同使用的服务,η为一个可变参数,用来调节计算过程中服务个性化特征的程度,如果η=0,则没有考虑.
加入由公式(2)计算得到的服务的个性化特征因子,用户ui和ui'关于属性c评分的Euclidean距离为:
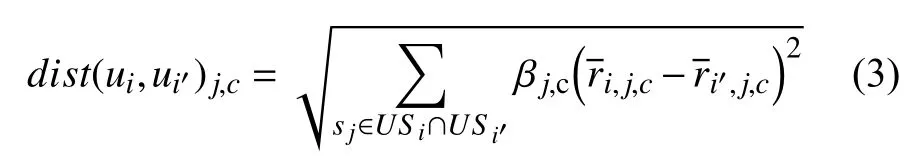
,j,c和i′,j,c为两个用户关于服务sj中某属性c的平均评分.
转化成对应的相似度:
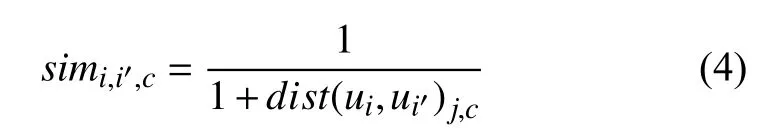
simi,i',c为两个用户关于属性c评分的相似度.通过加入惩罚因子减小用户之间共同评分服务数少对相似度计算产生的误差:
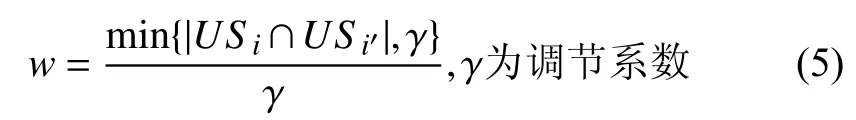
则最终的相似度计算公式为:
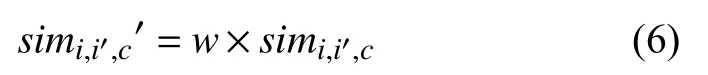
simi,i',c为用户ui和ui'在共同使用物流配送服务集合USi∩USi'上关于属性c偏好的相似度.
1.2.2 单个属性评分预测值计算
通过式(6)计算得到与用户ui关于物流配送服务属性c偏好相似的用户构成的最近邻居集合Ni,c,预测目标用户ui对未使用服务sj属性c的评分值:
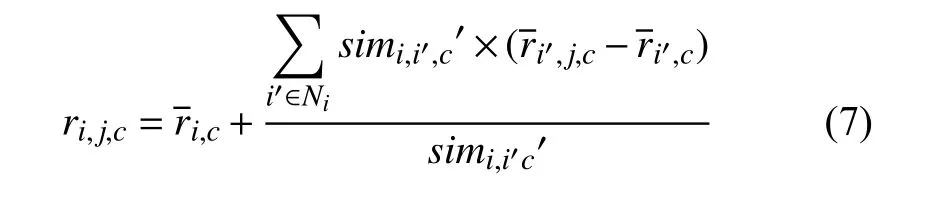
,c为用户ui对所有服务在属性c上评分的均值,′,j,c代表邻居用户ui'对sj在属性c上评分的均值.
通过对物流配送服务平台中用户评分行为进行研究,发现用户对同一属性的评分存在波动性,如果用户对于某一属性在不同服务间评分的波动较大时,则说明对该属性比较偏好,如果对于某一属性评分接近稳定,则在用户评分预测时参照其历史评分值使得准确度更高.
根据参考文献[10],通过信息熵En来对使用协同过滤得到的单个属性评分预测值进行修正.
将用户ui关于所有服务的属性c的评分情况统计,得到取值区间RAc为 [rcmin,rcmax].STu,c={tr|tr表示对属性c评分为r的次数,r∈RAc}.
信息熵计算公式:
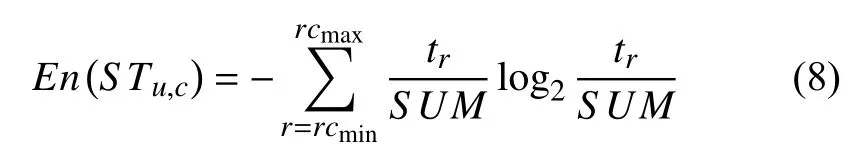
En(STu,c)取值范围为[0,log2(rcmax–rcmin+1)],当rcmin=rcmax熵为0,当对于所有r∈RAc,tr相等时,取到最大值Enmax.综合式(7)和式(8)最终用户对服务sj属性的评分预测值如下:
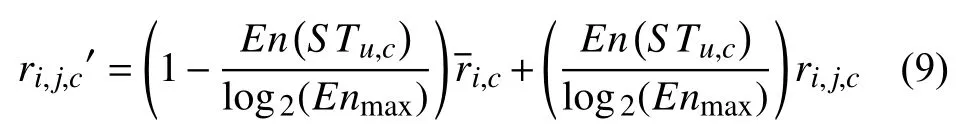
ri,j,c'为用户ui对物流配送服务sj的c属性评分的的最终预测值,为目标用户ui在属性c上评分的均值,ri,j,c为协同过滤推荐分值,由公式可知,En(STu,c)越小,预测评分受历史评分影响较大.
同理,可以预测目标用户ui对未使用配送服务Sj其它属性的评分值.
1.3 综合评分预测
利用ui对未使用配送服务Sj各个属性的评分预测值进行综合预测,研究发现同一用户对配送服务不同属性评分的波动性不同,如果某一属性波动性小,则在综合评分预测中所起作用大[11],对用户ui而言,属性c的评分预测权重为:
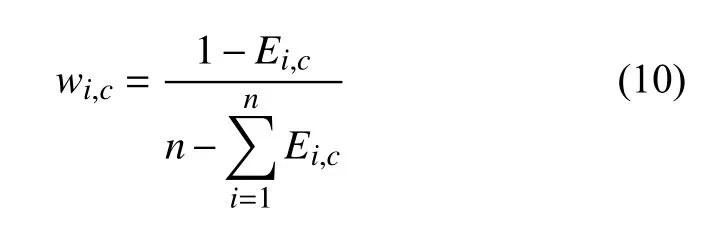
Ei,c表示对ui而言c归一化后的信息熵值,n为属性的个数.
通过式(10)得到的用户各属性评分预测权重,对用户未使用配送服务Si各属性评分预测值加权求和,得到用户ui对配送服务sj的综合评分预测值:
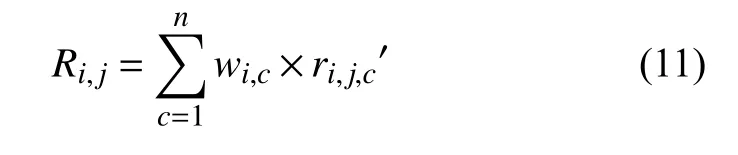
根据式(11)计算得到目标用户ui对所有未使用配送服务的评分,将分值按从高到低排序形成Top-N服务列表推荐给用户.
以上将物流配送服务平台与实际情况结合,将基于多属性协同过滤的推荐算法主要环节进行重新定义与描述,构建过程中通过考虑用户间共同评分服务的个性化特征以及用户对服务属性评分的波动性降低用户评分预测的误差,有助于提高服务平台的推荐准确性.
2 算法在物流配送服务平台中的应用
2.1 相关背景
本文提到的物流配送服务平台是物流信息云平台的一个子平台,通过该平台帮助需要物流配送服务的用户能够找到现有的服务,随着平台运作和大量物流商入驻,沉淀了大量物流商及其配送服务信息,这些服务在费用、时效方面存在差异,同时平台聚集了大量物流配送服务需求用户,这些用户对于配送服务的费用、时效存在偏好差异,对于用户来说了解每一项服务是不现实的,用户在选择服务时需要外界帮助,而推荐系统正好有这种功能.
平台目前具备的服务评价功能是系统实现的基本条件: 每完成一笔物流配送服务交易,平台会提醒用户对所使用的物流配送服务进行评价,现有平台的评价指标为用户关心的运输费用、运输时效、服务态度、运输安全性属性除此之外还有整体评价.评价采取打分制,分值划分为5个等级,1代表非常不满意,5代表非常满意.
基于上述背景,本文提出在现有物流配送服务平台中加入推荐系统功能,基于构建的多属性协同过滤算法为用户推荐满足偏好的物流配送服务.
2.2 物流配送服务推荐系统设计
遵循低耦合、分层、模块化的设计原则,将系统分为三个模块: 用户建模模块、推荐引擎模块、结果处理模块,推荐系统为服务器端程序,以物流配送服务平台中的服务为推荐库,首先通过建立用户兴趣模型即用户-服务评分矩阵,然后由推荐引擎基于构建的多属性协同过滤推荐算法,生成推荐结果,最后根据推荐结果的预测分数对推荐结果排名,返回给平台,由物流配送服务平台向用户呈现推荐结果,推荐系统组织结构如图1所示.
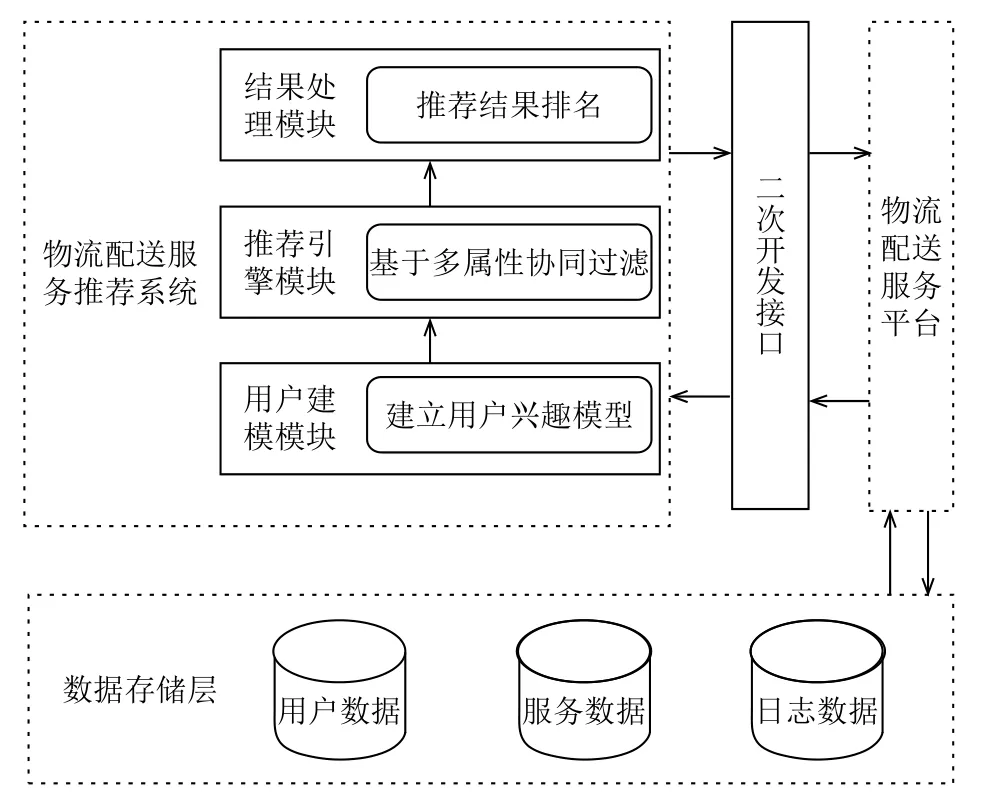
图1 基于多属性协同过滤的物流配送服务推荐系统结构图
系统通过调用物流配送服务平台提供的接口获取用户、服务等数据,这些数据由平台维护,系统产生的结果会再次通过平台提供的接口返回,本系统也提供接口供平台二次开发使用.
2.3 物流配送服务推荐过程
推荐引擎通过执行推荐算法产生推荐,本文构建的基于多属性评分的协同过滤算法为了减小热门物流配送服务对用户相似度计算造成的误差,使用Euclidean距离法计算用户相似度时引入了服务的个性化特征因子,根据研究发现的用户服务属性评分波动性会对协同过滤的评分预测准确性会产生影响,使用信息熵将用户对单个属性的历史评分均值和协同过滤的评分预测值加权求和进行修正,得到用户关于服务所有属性的评分预测值,最后根据不同用户服务属性评分波动性差异产生用户各属性的评分预测权重,根据这些权重与对应属性的评分预测值加权求和得到综合预测评分进行推荐,配送服务的推荐过程如图2所示.
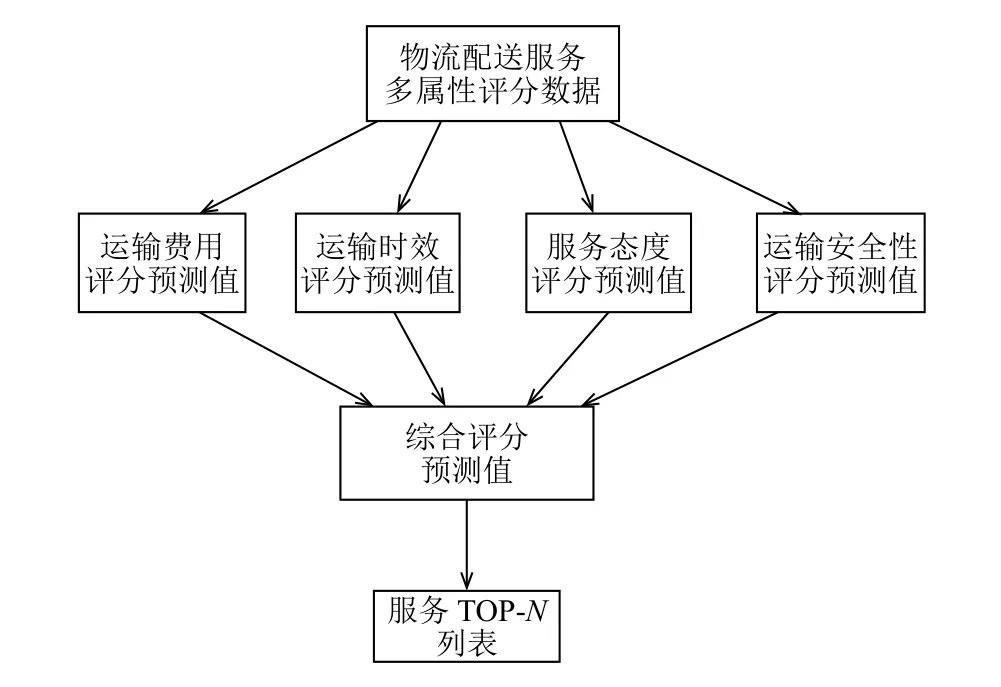
图2 物流配送服务推荐流程图
由图可知推荐过程主要分为两步: 首先分别预测用户对单个配送服务属性的评分值,然后进行综合评分预测,推荐过程描述如下:
(1)通过用户间相似度计算确定和目标用户偏好相似的最近邻居集合,用来预测用户对未使用服务的评分,通过算法1来实现.

算法1.用户相似度计算输入: ratingData(用户物流服务多属性评分数据)输出: sim(用户关于每个服务属性的偏好相似度)Step 1.根据式(2)得到所有服务每个属性的个性特征因子;Step 2.根据式(6)进行用户间关于每个属性的偏相似度计算.
(2)预测用户对未使用服务单个属性的评分值通过算法2进行.
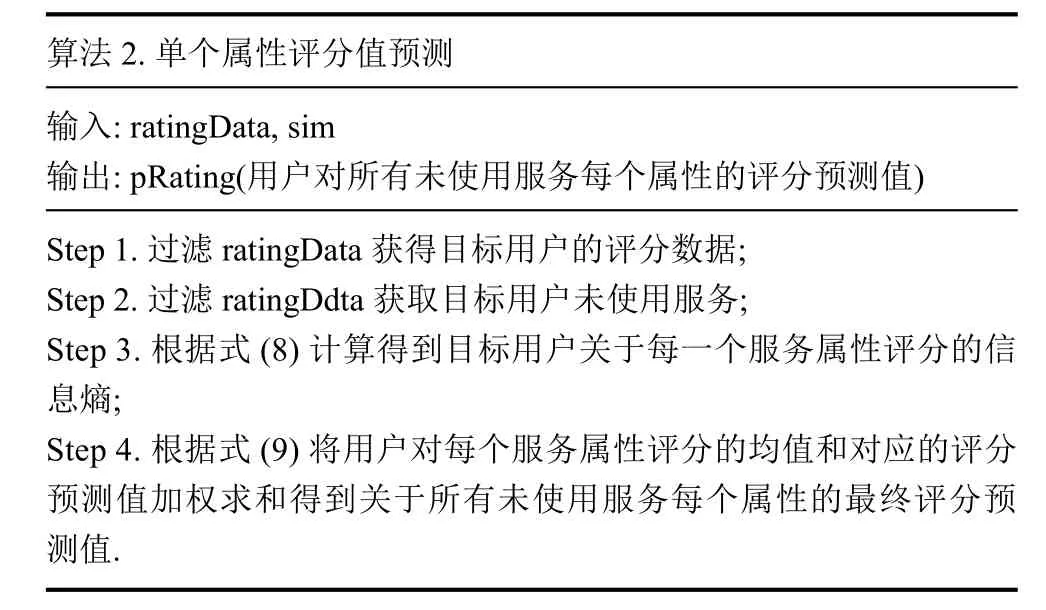
算法 2.单个属性评分值预测输入: ratingData,sim输出: pRating(用户对所有未使用服务每个属性的评分预测值)Step 1.过滤ratingData获得目标用户的评分数据;Step 2.过滤ratingDdta获取目标用户未使用服务;Step 3.根据式(8)计算得到目标用户关于每一个服务属性评分的信息熵;Step 4.根据式(9)将用户对每个服务属性评分的均值和对应的评分预测值加权求和得到关于所有未使用服务每个属性的最终评分预测值.
(3)最后一步则是综合评分预测,把计算得到的用户对未使用服务每个属性的评分预测值通过算法3来得到综合评分预测值.

算法3.综合评分预测输入: pRating输出: Top-N服务推荐列表

Step 1.根据式(10)计算目标用户每个属性的评分预测权重.Step 2.将计算得到的用户对所有未使用服务的评分预测值从高到低排序,选取前N个作为最终的配送服务推荐结果.
3 实验分析
构建的基于多属性评分的协同过滤推荐算法在物流配送服务平台中实现,当用户登录平台后,推荐能符合用户偏好的物流配送服务.
3.1 数据源与实验环境
本文采用离线测试的方式验证了推荐系统的效果,实验数据来源于实验室项目“沈阳市沈北物流信息平台”配送服务子平台,数据集包含了该平台5000条数据,包含2016下半年沈阳到北京线路400个用户对60项物流配送服务的评分,数据的稀疏度为79%.
数据选取过程中限定每个用户对至少10项不同配送服务进行评分,数据稀疏度为79%,经处理后的每条数据包含了用户ID、物流商ID以及运输费用、货物安全、服务态度、运输时效评分信息以及综合评分.通过对时间和距离的限定,排除了两者引起的较大幅度的价格变化造成的影响.
实验中的算法在Pycharm开发环境中使用Python语言实现.
3.2 评价指标
通过计算评价指标来评价推荐算法的质量是实验部分的重要环节,针对不同的推荐算法可以选取不同的评价指标,本文选取的评价指标如下:
(1)平均绝对误差(MAE)
平均绝对误差用来度量用户实际评分和真实评分之间的差值,其值越小,代表预测准确性越高,定义如下:

其中,Ri,j为用户i对服务j的预测评分,ri,j为用户i对服务j的实际评分,n为测试集中服务评分的数目.
(2)准确率(Precision)
准确率表示用户产生的推荐列表中有多大的比例是实际满足用户偏好的服务,如下式:
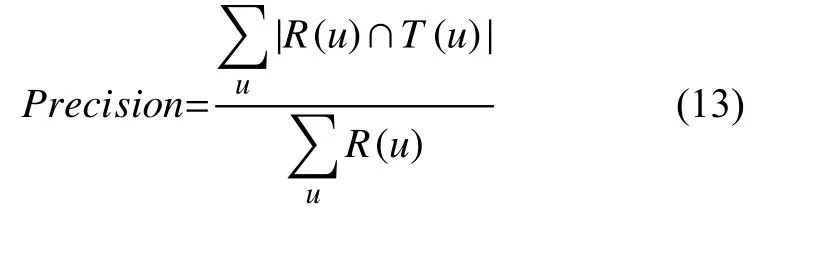
其中,R(u)为生成的服务推荐列表,T(u)表示测试集里用户表现出兴趣的服务列表.
3.3 实验结果分析
为了说明本文构建的基于多属性协同过滤推荐算法的有效性,使用实验数据将本文算法(Mul-CF)和其他算法对比分析:
(1)基于传统的协调过滤推荐算法: 基于用户对服务的综合评分,使用本文提出的改进的Euclidean距离法进行用户相似度计算,为了和基于多属性评分的推荐算法对比,称作Sin-iEuclidean.
(2)基于多属性协同过滤的推荐算法: 1)使用普通的Euclidean距离法进行用户相似度计算,称作MulpEuclidean; 2)本文算法中预测得到的用户对单个属性的评分不使用信息熵计算结果加权,称作Mu-noEn.
同时在长度不同的推荐列表Top-5和Top-7下进行对比,得到实验数据综合结果如表1所示.
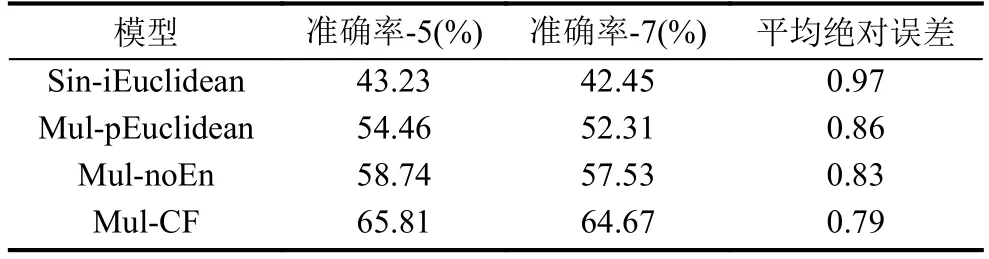
表1 不同推荐算法在实验中的性能对比表
由实验结果可知,本文构建的算法在Top-5和TopN-7列表下的准确率和平均绝对误差都明显好于其他三种算法,并且在Top-5列表下性能要略高经分析,本文算法优于其他三个算法: 一是基于粒度小的多属性评分,能较精确的反映用户偏好; 二是在计算用户相似度时,考虑了服务的个性化特征,降低了相似度计算误差; 三是考虑了用户历史评分波动性对预测的影响.
综上,通过对比实验验证了本文推荐系统的有效性,应用于物流配送服务平台能更好的满足用户需求,提高用户体验.
4 总结与展望
本文结合物流配送平台的实际情况构建了一种基于多属性协调过滤的推荐算法,引入服务个性化特征因子减小用户相似度误差,使用信息熵将用户历史评分均值与协调过滤的预测评分值线性组合进行修正,同时考虑了同一用户对服务不同熟悉评分波动的差异性,使最后得到的综合评分预测值更加准确,同时将算法应用于物流配送服务平台构建推荐系统,实验结果表明,推荐系统有较好的推荐效果,本文下一步将基于“沈阳市沈北物流信息平台”研究新用户冷启动问题,使得物流配送服务推荐系统功能进一步完善.
