结合密集神经网络与长短时记忆模型的中文识别①
2018-11-14张艺玮赵一嘉王馨悦董兰芳
张艺玮,赵一嘉,王馨悦,董兰芳
1(中国科学技术大学 计算机科学与技术学院,合肥 230022)
2(辽宁省实验中学,沈阳 110031)
文本识别[1]分为印刷体识别和手写体识别.目前这两种识别都得到充分的研究,并普遍认为印刷体字符识别中的关键问题已得到有效解决.但是对于印刷体字符识别而言,图像质量的严重下降会给识别造成极大的困难; 而关于中文字符识别[2],需要克服的难点更多,首先,中文类别较多,按照GB2312标准,我们常用的一级汉字就有3755类; 其次,中文字符结构复杂,它包括偏旁、部首和字根; 还有字符间形近字比较多,准确区分形近字也大大增加了识别难度.所以,实际使用的文本识别技术还有很大的提升空间.
中文字符的识别方法主要分为结构模式识别和统计模式识别[3].其中结构模式识别是早期中文识别的主要方法,它根据字符自身的规律信息进行结构特征提取,这些结构特征包括字符轮廓特征、骨架图像上提取到的反映字符形状的特征等[4].基于结构模式识别的主要优点在于匹配精度高,区分相似字能力强; 但是由于其依赖结构特征的提取,而特征的提取易受到干扰因素的影响,所以这种方法的抗干扰能力较差.随着统计理论的发展,统计模式识别方法[5]逐渐成为中文字符识别的研究热点,它提取将要被识别的统计特征,然后利用某些函数对这些特征进行分类.常见的统计特征包括网格特征、方向像素特征、穿越特征、外围特征等.这种方法的主要优点是具有良好的抗噪声、抗干扰能力,对字符形变也有较强的鲁棒性,但是对细节区分能力不强.
上述传统方法都是基于手工设计、提取特征,这个过程不仅耗费人力,而且会积累误差和噪音,极大地影响最后的识别效果.
近几年,深度学习不断发展,特别是深度卷积神经网络(CNN)[6]等模型在模式识别及计算机视觉领域的大量突破性成果的涌现,为中文识别带来新的活力;2013年富士通团队采用改进的CNN网络[7],在单个汉字识别方面取得了令人瞩目的成绩.
本文在深度学习的基础上,针对多种字符,包括中文、英文、数字、特殊符号等,结合密集卷积神经网络DenseNet、双向长短时记忆模型BLSTM和连接时域分类CTC进行文本行端到端的识别.采用DenseNet通过卷积、下采样等操作提取图像特征,并将生成的特征序列传递给BLSTM,相对于卷积神经网络,BLSTM使用特殊的存储记忆单元更充分的利用文本上下文特征进行建模,最后采用CTC对之前的特征信息进行解码,输出识别结果.这个网络结构可以接受任意长度的输入序列,不要求对文本提前分割,在避免字符分割错误带来误差的同时,对于字符连接信息有一定程度的记忆能力,整体性能强,可以进一步提高文本识别率.
1 网络结构
1.1 DenseNet
深度卷积神经网络一个很重要的参数是深度.网络深度的提升往往伴随着网络性能的提升,但是随着网络深度的加深,训练参数梯度消失的问题会愈加明显,而DenseNet[8]的出现很好的解决了这个问题.
DenseNet是在Highway Networks[9,10],Residual Networks[11](ResNet)以及GoogLeNet[12]的基础上被提出来的.不同于之前加深网络或者加宽网络,DenseNet的提出者从卷积神经网络的特征序列入手,通过对特征序列的极致利用,简化模型参数,同时达到更好的效果.它的主要思想是跨层连接,网络每一层的输入都是前面所有层输出的并集,而该层学习到的特征序列也会被直接传给后面所有层作为输入; 在上述过程中,信息流进行了整合,避免了信息在层间传递丢失和梯度消失的问题.
DenseNet一般由多个dense block和transition layer组成.图1是DenseNet的主要结构——dense block的示意图.可以看出,H4层不仅直接用原始信息x0作为输入,同时还使用H1、H2、H3层对x0处理后的信息作为输入; 我们可以用一个非常简单的式子描述dense block中每一层的变换,如式(1):
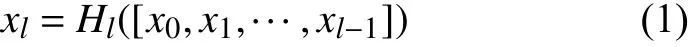
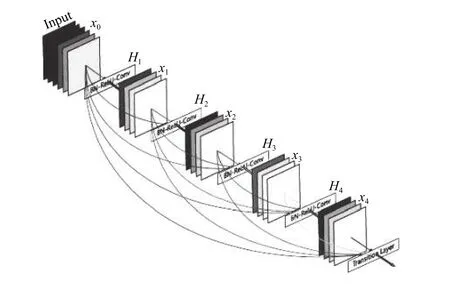
图1 一个5层的dense block示意图
相比于普通神经网络的分类器只依赖于网络最后一层的特征,DenseNet可以综合利用浅层特征,加强了特征的传导和利用,减轻梯度消失的问题,所以更容易得到一个光滑的具有更好泛化性能的决策函数.
1.2 BLSTM
传统的递归神经网络(RNN)[13]展开后相当于一个多层的神经网络,当层数过多时会导致训练参数的梯度消失问题的出现,从而致使长距离的历史信息损失.因此,传统RNN在实际应用时,能够利用的历史信息非常有限.为了弥补上述缺陷,Hochreiter等人[14]在1997年提出了LSTM单元结构,如图2所示,它由1个记忆细胞和3个门控单元组成,记忆细胞用于存储当前的网络状态,3个门控单元与记忆细胞相连,分别称作输入门、输出门和遗忘门,它们控制信息的流动.在信息传递时,输入门控制输入到记忆细胞的信息流;输出门控制记忆细胞到网络其他结构单元的信息流;遗忘门控制记忆细胞内部的循环状态,决定记忆细胞中信息的取舍[15].LSTM的这种门控机制让信息选择性通过,使记忆细胞具有保存长距离相依信息的能力,并可以在训练过程中防止内部梯度受外部干扰.
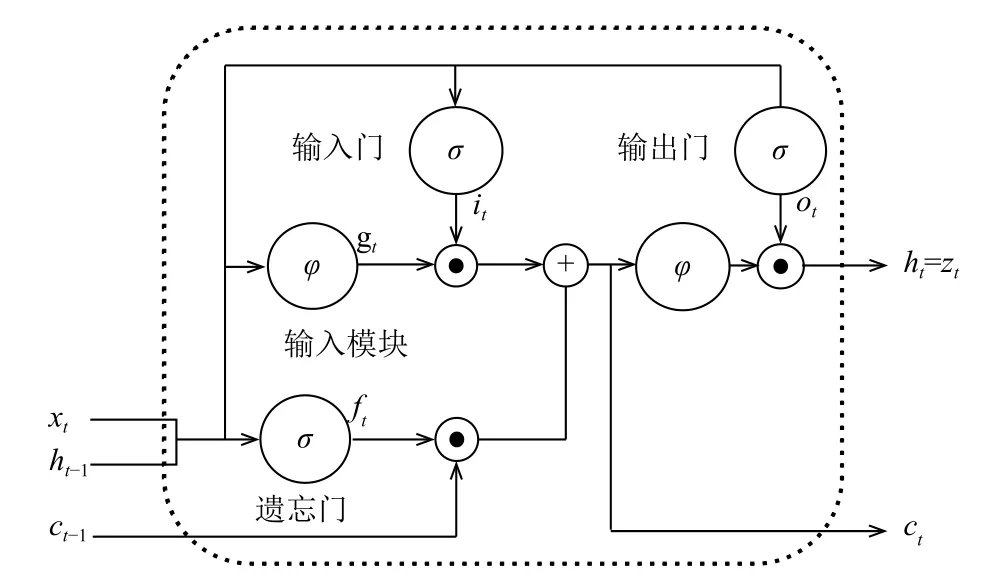
图2 LSTM单元结构图
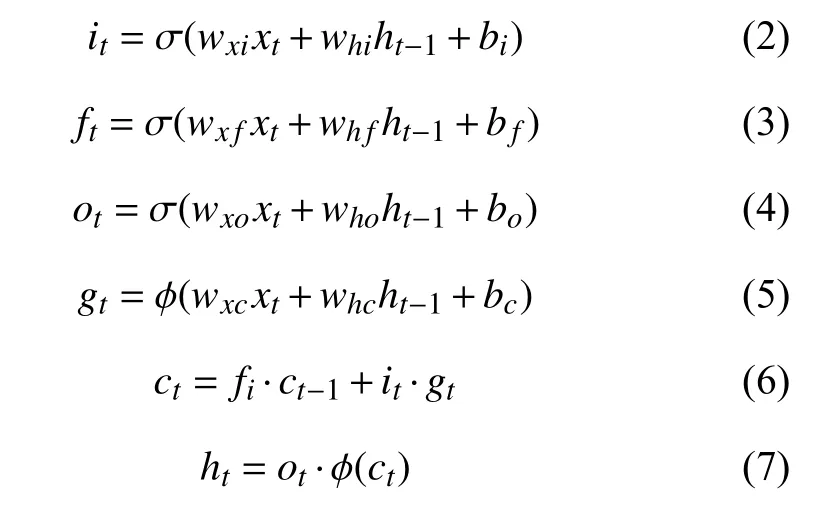
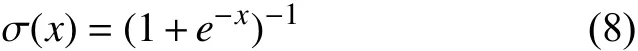
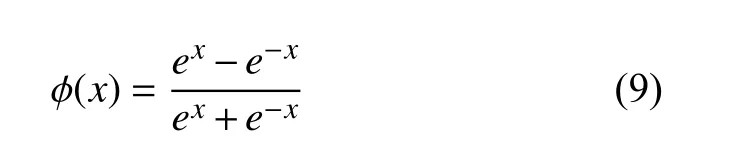
对于计算机视觉领域的很多任务,如对模型的预测或识别,未来信息同历史信息一样重要.例如文本行识别,在识别当前词时,它之前与它之后的词语信息都会对当前词的识别有所帮助.但是,前文描述的模型只能单向输入,序列无法利用未来的信息.于是,Schuster等人[16]提出双向RNN (BRNN)概念,它的核心思想是将序列信息分两个方向输入模型中,模型使用两个隐藏层分别保存来自两个方向的输入数据,并将相应的输出连接到相同的输出层,如图3所示.
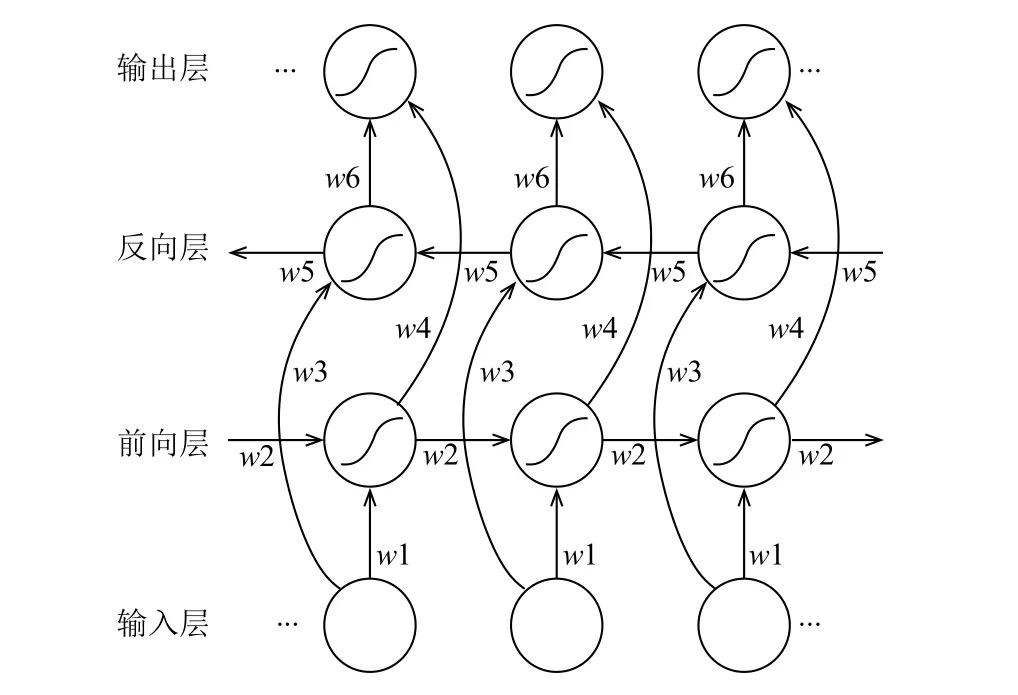
图3 BRNN在时间上的展开形式
图3中,w1,w3表示输入层到前向层与反向层的权重,w2,w5表示隐含层自身循环的权重,w4,w6表示前向层与反向层到输出层的权重.
BLSTM将BRNN和LSTM这两种改进的RNN模型组合在一起,即在BRNN模型中使用LSTM记忆单元,这样可以更好的学习局部信息的相关性.
1.3 CTC
时域连接模型CTC[17]是一种直接标记无分割序列的方法,适合于输入特征和输出标签之间对齐关系不确定的时间序列问题.它可以端到端地优化模型参数,并且对齐切分的边界,使得针对输入序列的每一帧,网络能够输出一个标签或者空白标志(‘-’).
CTC网络的输出层是在给定的输入下,计算所有可能对应的标签序列的概率,以求出标签概率最大的序列.对于一个长度为T的序列x,经过神经网络计算映射,得到序列的输出y,定义表示在t时刻标签为的概率,表示在整个标签集L∪{‘-’}上所有长度为T的序列集合,得到公式(10).
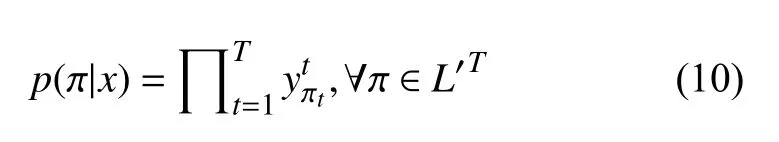
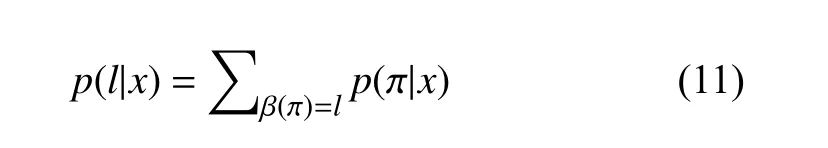
分类器的输出应为输入序列最有可能的标签序列,如式(12)所示.
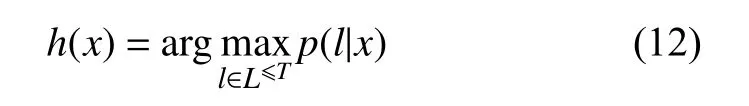
根据上述公式,目标函数最小化上述概率的负对数似然.因为目标函数是可导的,网络可以通过标准的BP方法来训练.
2 整体模型
图4是本文提出的模型整体架构图.
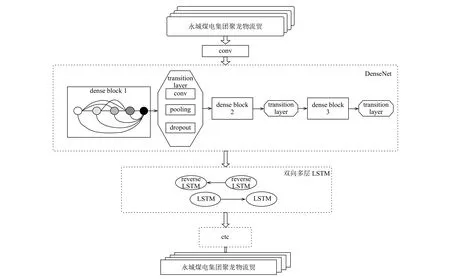
图4 模型整体架构图
因为汉字种类繁多,结构复杂,简单的卷积神经网络已经很难完全提取图像细节特征,深层网络又可能造成信息消失、参数繁多以及难收敛等问题,所以本模型选择结构简单,但效果突出的DenseNet网络结构提取图像底层特征.DenseNet网络中的每个dense block中有4个Bottleneck layers,即BN-ReLU-Conv(1×1)-BN -ReLU- Conv (3×3)结构.该结构中 Conv(1×1)可以减少输入参数的数量; dense block结构中每一层网络都设计地很窄,只学习较少的特征序列,这样可以减少网络参数,提高网络效率,达到降低冗余性的目的.DenseNet网络中的transition layer用来连接dense block,它由conv层、pooling层以及dropout层组成,conv层用来决定是否压缩模型参数; pooling层控制特征序列的大小,因为在dense block内部,特征序列的空间维度是保持不变的,故而在两个dense block之间进行下采样; 最后插入dropout层,它是由Srivastava等人[18]在2014年提出的防止网络过拟合的技术,即在模型训练时按照一定的比例(本文设置为0.2)随机选择某些节点不工作,使得模型具有多模型融合的效果,可以降低网络损失,提升网络性能.为了不丢失图像特征,本文没有选择全连接层作为DenseNet结构的最后一层,而是直接用图像的特征序列作为BLSTM的输入.
接下来,多层的BLSTM提取时序信息.将DenseNet提取的多维特征序列,按照BLSTM层的输入要求进行转置,然后分别送给正向LSTM与反向LSTM层进行学习,LSTM计算提取每张图35列特征序列间的信息.
在BLSTM充分获取数据间的特征后,运用CTC层对之前的训练数据强制对齐,实现无分割序列的标签工作.在当前输入下,CTC层计算每一列对应到4001(本文字符种类数4000+1种空白)种标签元素上的序列概率分布,并将这些序列按照一定的规则进行映射后,统计每个标签序列的概率,求出最可能的标签序列并输出.CTC转录层可获得图像的序列描述,即图像的最终表示方式.
每个文本行图像经过DenseNet+BLSTM+CTC 3个主要环节得到最终的特征表达,如算法1.
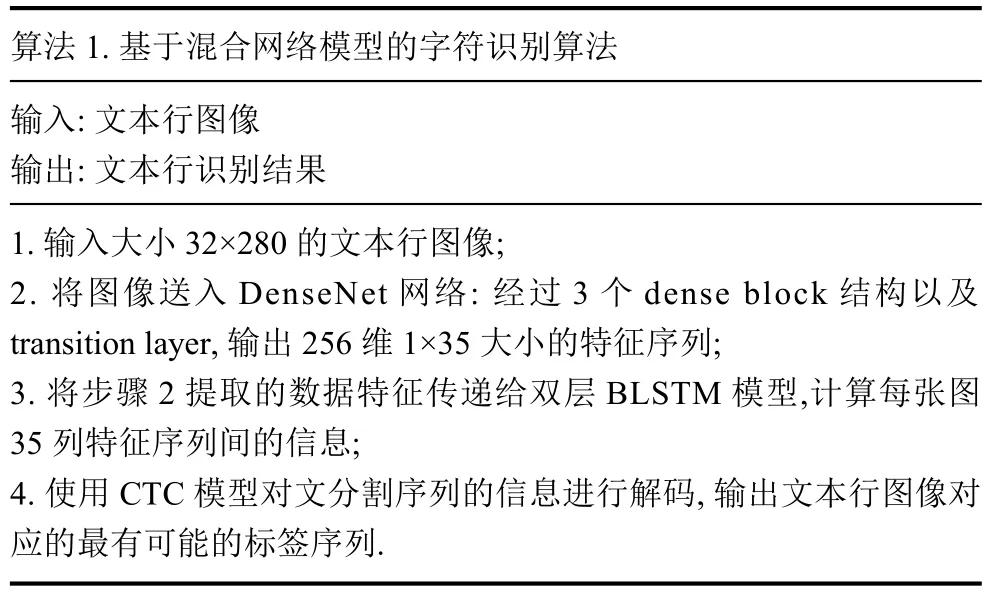
算法1.基于混合网络模型的字符识别算法输入: 文本行图像输出: 文本行识别结果1.输入大小32×280的文本行图像;2.将图像送入DenseNet网络: 经过3个dense block结构以及transition layer,输出256维1×35大小的特征序列;3.将步骤2提取的数据特征传递给双层BLSTM模型,计算每张图35列特征序列间的信息;4.使用CTC模型对文分割序列的信息进行解码,输出文本行图像对应的最有可能的标签序列.
3 实验
3.1 实验设置
实验基于caffe框架.在Intel Core i7,内存8 GB,显卡GTX1080机器上进行训练,模型的初始学习率设为0.0001,学习率按照“multistep”方式更新.
3.2 实验数据
由于发票上存在一些比较特殊的字体,而且发票上的印刷体字符图像存在断裂、粘连等情况,目前没有相关已经开源的训练数据库,所以本文的实验数据主要来自网上的印刷体图像以及自己生成大规模的数据.实验图像生成算法如算法2.

算法2.实验图像生成算法输入: 文本编辑文件中4000类字符文本,包括的中文一级汉字3755个输出: 250万张文本行图像Begin:1.fori=1,2,…,4000 2.将文本编辑文件中的第i个字符文本读入程序3.使用OpenCV计算机视觉库生成一张32×32的空白图像4.使用freetype字体引擎将读入的文本按照发票上的字体形式加载到空白图像,同时设置图像中字体的大小、图像的空白比例等5.将原始图像进行灰度化、二值化6.end for 7.读取语料库中的语句,按顺序拼接上述步骤制作的单字图像,以生成文本行图像8.对图像进行多种变换: 加入旋转变化; 加入椒盐噪声; 高斯噪声; 设置不同参数的腐蚀操作、膨胀操作; 对图像反复进行拉伸操作; 加入弹性变换; 加入模糊操作等 //降低图像质量,拟合发票上的字符图像9.将图像调整至32×280大小,满足网络输入要求10.重复7–9步,共生成250万张图像End
将实验数据按照9:1的比例分成训练集与测试集,将图像进行自适应阈值二值化[19]后如图5所示.

图5 文本行图像示例
3.3 实验结果及分析
为了选取更合理的模型结构,本文对dense block的设置以及BLSTM的层数进行了多组对比实验.
表1的实验是在总卷积层数相同的情况下,改变dense block的结构,观察识别效果.实验1使用4个dense block,每个dense block内部有6个卷积层,实验2使用3个dense block,每个dense block内部有8个卷积层,其中引入Bottleneck layers.从实验结果来看,实验2在识别率上表现更好,同时因为包含1×1的卷积层,参数也得到精简.

表1 关于dense block的实验数据表
基于表1的实验结果,选取实验2的dense block结构,再更改dense block内部的Growth rate,即本模型中3×3卷积层产生的特征序列数量,观察实验性能.
表2中的实验在DenseNet-B的基础上进行.(DenseNet-B是指dense block中1×1卷积层产生的特征序列的数量是3×3卷积层的4倍,我们设3×3卷积层的Growth rate=k,则1×1卷积层应有4k个特征序列.实验3中Growth rate=16,实验4为32) 观察实验结果发现,实验4比实验3的识别结果稍有提升.

表2 关于Growth rate的实验数据表
经过多组实验,本模型在确定DenseNet的dense block结构后,对BLSTM的层数进行实验.
同样,本文对比了经典的CNN模型和2015年大放异彩的ResNet网络结构,如图6所示.
表3列出了BLSTM分别取1层、2层以及3层时,对实验性能的影响.对比表明,用两层的BLSTM可以取得更好的识别率,而随着层数的增加,模型的识别时间逐渐增加.分析认为2层BLSTM能更好的提取文本间的信息,1层存在特征提取不充分的情况,而3层可能出现过拟合的情况.
首先将本文提出的模型与经典的CNN+BLSTM+CTC模型进行对比,在同样的实验数据下,经典的CNN模型的最高行识别率只有91.3%,明显低于DenseNet模型的识别率,并且收敛速度没有本文提出的模型快.接着,本文对ResNet+BLSTM+ CTC模型进行了多组测试,最后选取结果最好的模型与本文提出的模型进行对比.从图6(a)可以看出,ResNet模型相比于经典的CNN模型有较大的提升,行识别率为95.0%,而本文模型的行识别率达到96.68%.
分析图6的(a)与(b)图,可以看出,随着网络迭代次数的增加,三种模型都逐渐收敛,其中,DenseNet模型与ResNet模型收敛迅速; 当模型效果趋于稳定后,本文提出的模型识别准确率最高,这也充分说明了DenseNet+ BLSTM+CTC结构在识别率及收敛速度方面的优越性.
为了更加充分地验证本文模型的性能,我们又与Tesseract[20]OCR软件进行了对比.在开源的OCR引擎中,Tesseract OCR是效果最好的.它最先由惠普实验室开始研发,至1995年时已经成为OCR业内最准确的三款识别引擎之一.2005年,Google开始对Tesseract进行优化.本文充分利用Tesseract可以自训练识别库的优势,针对性地训练中文识别库,并利用该识别库实验.
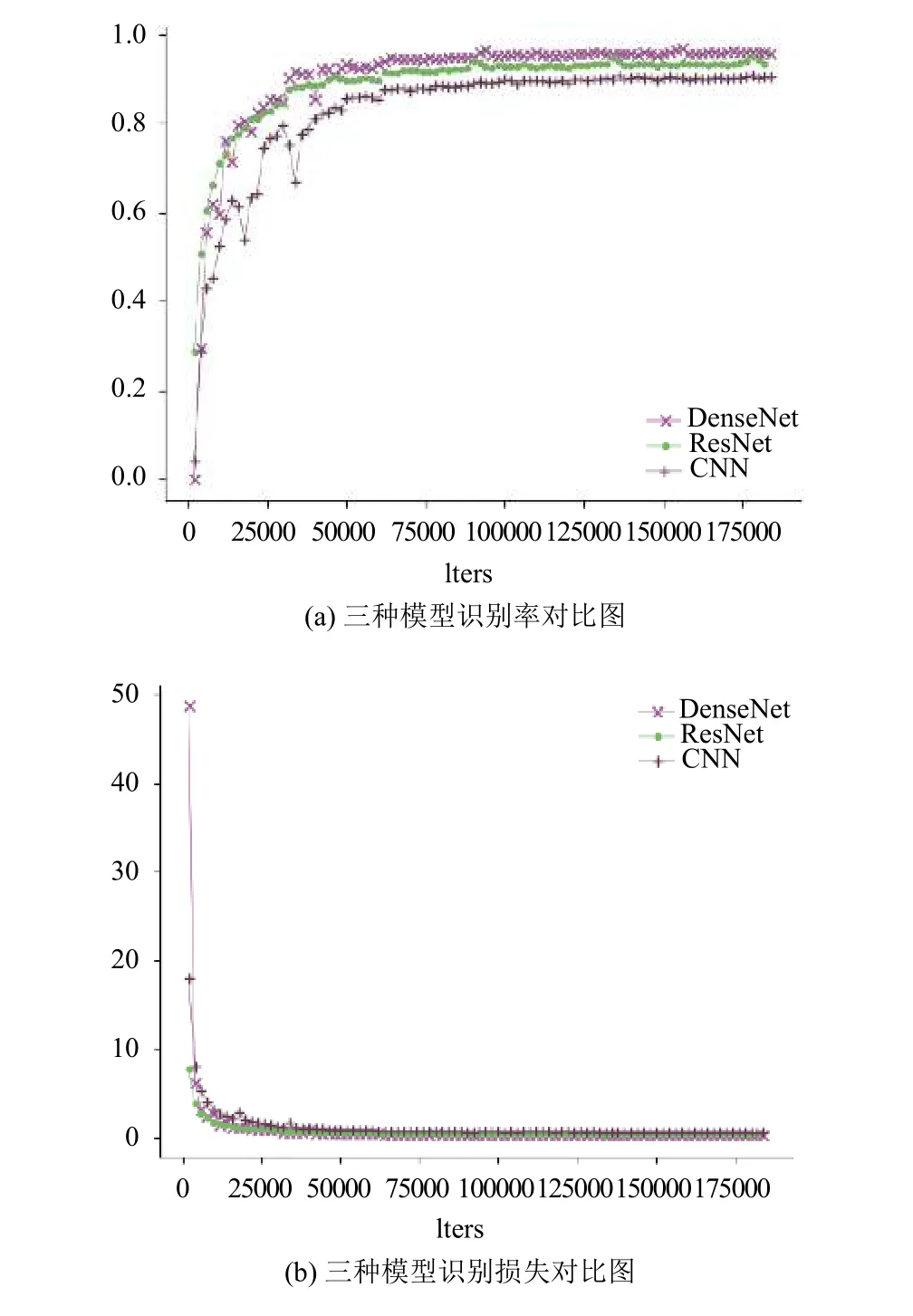
图6 本文模型与ResNet模型识别性能对比图
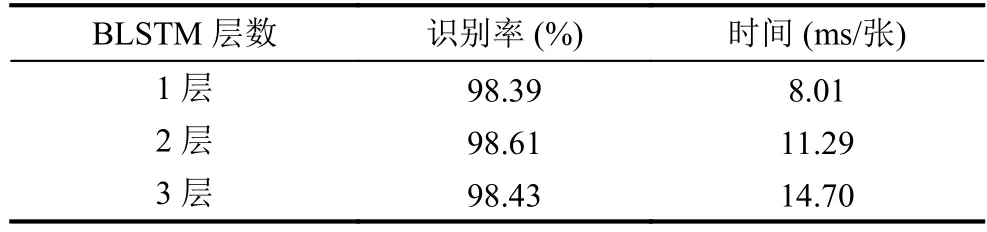
表3 BLSTM层数对实验的影响

表4 两种方法实验对比
在进行Tesseract识别测试时发现,对于很多文本行,Tesseract可能出现识别错1个或2个字符的情况,所以它针对一行文本图像完全识别正确的概率很低,但针对行中单个字符,它的识别率可以达到82.47%.对比发现,本文提出的模型在单字识别率上提升了16.14%,而时间仅相当于Tesseract的1/47,效果显著.
4 结论
文本识别是一项很有挑战性的任务,尤其是中文识别.针对文本行图像,本文首次提出DenseNet+BLSTM + CTC的端到端识别的混合架构.利用Dense Net自动提取文本图像特征,多层卷积特征融合了低层形状信息和高层语义信息,避免了手工设计图像特征的繁琐,减少特征计算的难度; 在分析图像信息后,BLSTM提取字符图像间相关性特征,并从两个方向进行分析,前向层从前向后捕获文本演变,后向层反方向建模文本演变,有效的利用序列的上下文信息[21]; 最后将两个方向的演变表达融合到CTC中,产生图像的序列化表达.实验结果表明本文方法在识别率、识别时间、内存占用多方面表现优秀,并具有无限潜能,同样适用于其他序列标注任务.
