一种融合聚类和异常点检测算法的窃电辨识方法*
2018-11-13李宁尹小明丁学峰蔡慧汪伟
李宁,尹小明,丁学峰,蔡慧,汪伟
(1.中国计量大学 机电工程学院,杭州 310018; 2.国网浙江长兴县供电有限公司,浙江 湖州 313100)
0 引 言
当前,我国电力行业正处在技术水平升级的关键时期,需要加强新技术产品的开发。电网规模的逐渐增大和电力消费增长的同比提高,使电力网络经济化运行、节约资源降低线损以及优化电力消费结构成为当今社会关注的热点话题[1]。
随着窃电现象的层出不穷,我国电力企业每年因窃电产生的损失高达200亿,社会供用电秩序也受到了极大地影响。所以电力企业必须开展高效的反窃电工作,以做到合理供电、合理用电,尽可能降低经济损失[2]。
目前,国网供电公司采取的反窃电措施主要有:应用专业化的电能表箱和计量箱;将低压出线端闭合至计量装置的导体,此技术是目前反窃电技术中应用最为广泛的方法;安装反窃电智能电能表、丰富电能表功能;提高电采集系统的应用率等[3]。但是这些方法大多以研究反窃电装置为主,缺乏足够的反窃电算法用于分析海量的历史用电数据,从而很难发现窃电用户的用电特征[4]。
当前主流的反窃电算法有聚类、BP神经网络、离群点算法等。文献[5]利用自适应k-means聚类算法提取用户的典型负荷曲线,用于实现负荷预测和负荷控制。文献[6]分析了基于BP神经网络的异常点检测方法处理各种数据的情况,为挖掘电力数据异常点提供一种新的思路。文献[7]介绍了一种基于异常因子检测分析的电能表飞走异常分析方法,是一种检测电能表飞走异常的新方法。
文章中研究的是一种针对电量数据异常点挖掘的窃电辨识方法,该方法融合聚类和异常点检测算法,可以解决单一算法对离散度较高、非规律性的样本无法有效挖掘的问题。方法的实现过程是:先利用聚类算法对样本进行粗略分类,按照包含窃电异常嫌疑点数量大小降序排列,然后运用异常点挖掘算法对窃电嫌疑最大(即包含异常点数量最多)的一类进行二次分析,最后综合两种算法分析结果和实际情况确定最终的窃电嫌疑数据,并实现窃电报警。换句话说,这种方法可在现有的计量装置下,通过分析用电量数据特征发现窃电用户,降低防窃电成本[8]。
1 窃电辨识方法原理
1.1 聚类算法
聚类算法有很多种,选择哪一种算法用于实际样本分析取决于数据的类型、聚类的目的。聚类算法主要分为:划分方法、层次方法、基于密度的方法以及基于模型的方法等,在这些方法中使用最为广泛的是划分方法中的K-means聚类算法。该算法数据处理的效率高且原理简单、易于实现,因此文中采用K-means聚类算法。
K-means聚类算法不同于分类方法,它不需要事先确定样本分类类别的属性,一般是根据经验和需求先确定聚类的数目k,然后随机选取k个点作为k个簇的聚类中心。初始聚类数目和初始聚类中心对聚类效果的影响都很大,一般对K-means聚类算法的改进都是在这两个方面进行[9]。而聚类准则函数通常都是采用误差平方和最小函数,即:
(1)
式中SSE是数据库中所有样本平方误差的总和;x是空间中的点,表示给定的对象;ci是第i个簇的样本平均值。
聚类算法迭代结束的条件是聚类准则函数达到最优,这种最小方差划分使生成的结果簇尽可能的紧凑和独立。
1.2 基于距离的异常点检测算法
在大量数据中挖掘异常点的任务可以被分为两个子任务:
(1)准确定义异常点;
(2)找到异常点挖掘方法。
1.2.1 定义异常点
假设任意一个样本点的邻域内最多允许的邻居数为M,若发现某个样本点存在第M+1个邻居,则该点不是异常点;反之,若某个样本点的邻居数少于M个,则该点是异常点[10]。总结来说,在正常情况下,样本的邻居节点越少,则它是异常点的概率就越大。
求任意样本点的邻居数的方法是计算它与其他所有点的欧式距离,根据距离的大小来定义它们之间的相似度[11],最后根据上述假设确定分析的样本点是否是异常点。由于所研究分析的对象是日用电量数据,所以此处采用的是一维欧氏距离。对两个一维样本数据x1和x2,欧式距离公式定义为:
D(x1,x2)=|x1-x2|
(2)
采用一维样本大大降低了数据处理的复杂度,提高了算法执行的效率。因此,和其它窃电辨识算法相比,该方法具有一定的优势。
1.2.2 异常点挖掘方法
对于一个包含n个样本的数据集,采用循环搜索样本邻居的方法发现所有样本的k个邻居。当k≤M时,则可初步确定该点是异常点;反之,k>M时,则可认为该点是正常点。
1.3 融合聚类和异常点检测算法的窃电辨识方法
两种算法融合的过程是先用K-means聚类对样本进行粗略地分类,按照包含窃电异常嫌疑点数量的大小降序排列,然后利用异常点检测算法对窃电嫌疑最大的一类进行二次分析,最后综合两种算法分析结果和实际情况确定最终的窃电嫌疑数据,并实现窃电报警。
对日用电量数据特征进行分析可解决聚类数目k和初始聚类中心选择不合理导致聚类效果下降的问题。因为根据用电量的实际情况,即使实际样本波动很大,一般可将用电量分为3类,即异常偏高非窃电的样本点、处在正常范围内的样本点、偏低的窃电嫌疑点,因此可将初始聚类数目k定为3;而对于一组符合上述情况的样本,其样本最大值、样本均值、样本最小值可以作为3个类的初始聚类中心。具体的聚类流程如图1所示。
将图1中的聚类结果按照包含异常点个数的大小降序排列,然后对窃电嫌疑最大的一类样本利用异常点检测算法进行二次分析,见图2。

图1 聚类算法流程图
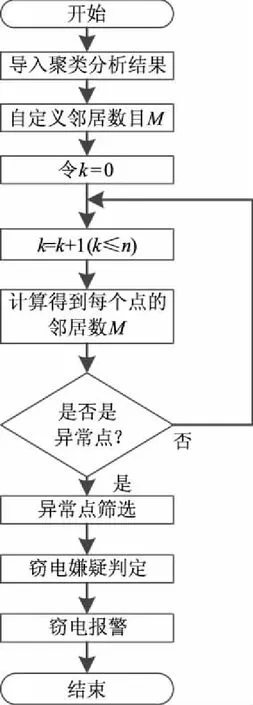
图2 异常点检测算法流程图
图3所示,融合两种算法的窃电辨识方法是对聚类算法得到的异常数据进一步筛选,提高了窃电嫌疑报警的可信度。
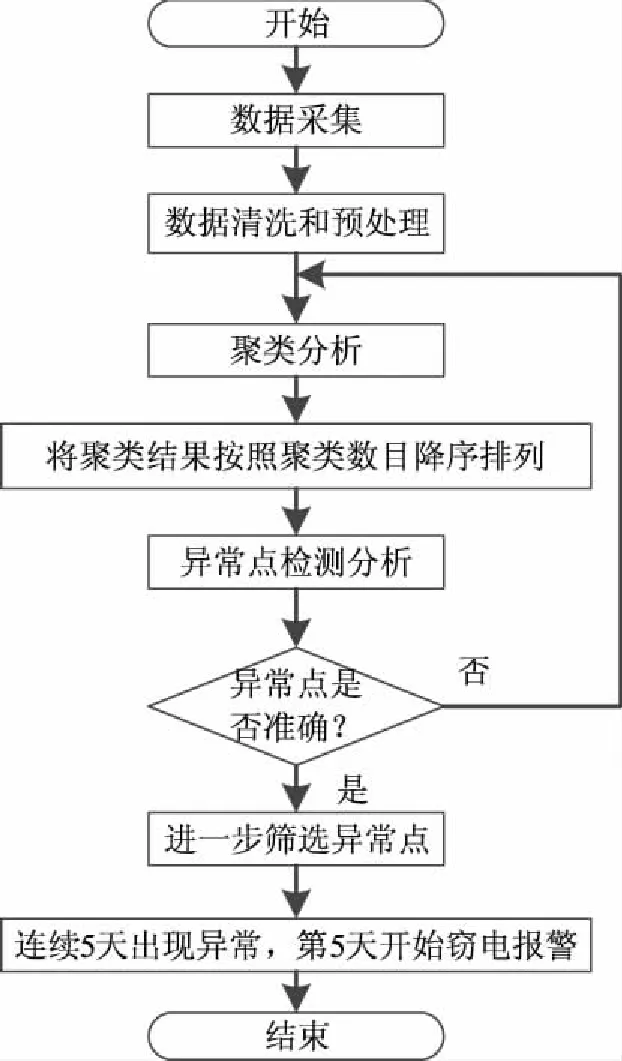
图3 融合两种算法的窃电辨识方法流程图
样本作为算法的输入,必定会影响算法输出的分析结果,因此做好数据清洗和预处理工作对提高算法的准确性至关重要。表1中数据清洗的规则主要有四条。

表1 数据清洗规则
总之,清洗后要保证日用电量数据和相应的用电时间一一对应,否则无法正常处理和分析。数据预处理包含电量计算和电量数据归一化。
任意一天用电量的计算方法定义为:
di=pi-pi-1
(3)
式中pi代表第i天的表计总正向有功功率,pi-1代表第i-1天的表计总正向有功功率。
当样本数量较多时,一般采用线性归一化方法将所有样本化为介于0和1之间的数。线性归一化公式为:
(4)
式中x(i)代表任意一个样本值;min(x(n))代表样本最小值;max(x(n))代表样本最大值。
经过上述数据清洗和预处理过程,很大程度地减少了原始样本数据不均衡对窃电辨识效果的影响。以此为基础,经过K-means聚类算法和异常点检测算法的两次分析筛选,最终得到的异常点数据已经有很大的窃电嫌疑了。最后,通过对异常点对应的时间进行准确报警,可以为一线稽查人员的现场排查工作提供较为准确的依据。
此外,考虑到该方法所用数据都是由智能电能表采集得到,电能表如果存在时钟偏差将导致用电数据不准确,进而在很大程度上影响窃电辨识结果的可信度。电力行业一般要求现场运行的电能表实际时钟与北京时间的差异δ≤5 min/年(即0.82 s/天),因此在实际的分析过程中,要根据电能表是否存在偏差以及偏差程度大小适当调整算法辨识的结果以减少误差。
2 算例分析
为了验证该方法在实际窃电辨识工作的有效性,下面选取了用电信息采集系统采集的真实数据进行分析验证。
经过数据清洗后的某低压用电用户A在2015.4.1~2015.10.9期间的日用电量数据如图4所示。横坐标表示按照时间前后顺序排列的数据编号,纵坐标表示的是用电量数值。从图中可以看出,该样本数据离散度较高、规律不明显,所以不能直观地看出该用户在哪一天开始窃电。因此,下面使用融合聚类和异常点检测算法的数据挖掘方法进行分析。
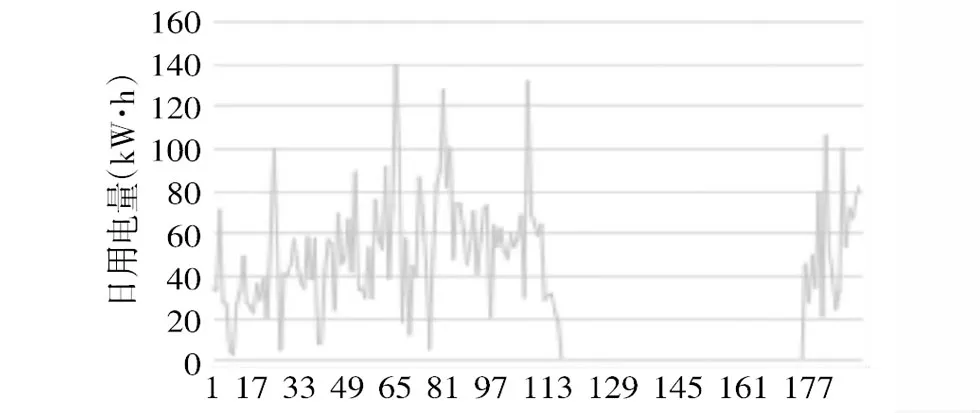
图4 用户A日用电量
该样本的用电量最大值dmax=139.260 0(单位:kWh,下同),用电量最小值dmin=0,样本均值dmean=32.028 3。基于上述原理,初始聚类数目定为3,即将原始样本分为3类C1、C2、C3,初始聚类中心集合Ccenter={139.260 0,32.028 3,0}。
因为实际分析的样本数量有限,此处的样本未经过归一化。聚类分析的结果是将样本分成3类,聚类后的结果不是按照原有时间顺序排列,而是根据大小分类(见图5)。
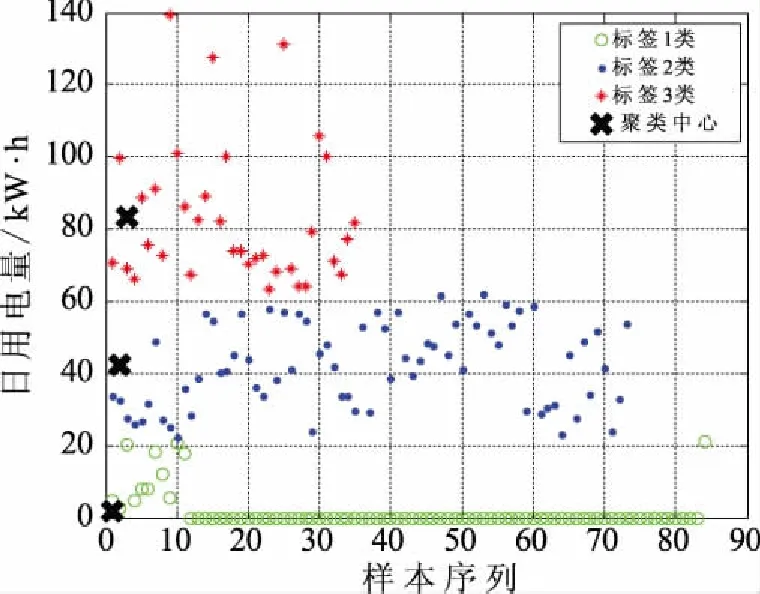
图5 聚类算法分析结果
很明显,经过聚类得到的分类结果还是比较粗糙的,处在簇边缘的一些样本被错误分类。
因此,需要利用异常点检测算法对该分类结果进行二次分类。按照包含窃电嫌疑异常点数目大小将3类结果降序排列,即:标签1类>标签2类>标签3类,3类用电量数据如图6所示。
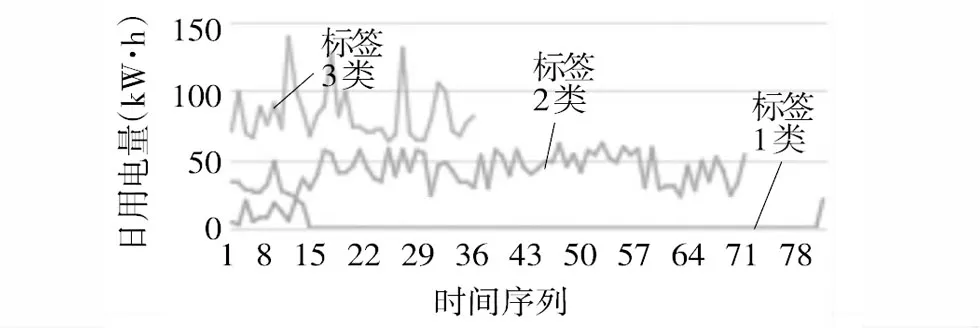
图6 标签分类用电量
考虑到窃电实际情况,在针对窃电嫌疑最大的标签1类进行二次分类的结果中,将少量“×”状的样本数据(即错误聚类到标签1类的样本点)去掉,“”状样本点即为最终的异常点,将异常点与其对应的时间联系起来,就可以实现窃电时间报警(见图7)。
单独使用异常点检测算法得到的分析结果如图8所示。图中底部的粗线部分是检测出的70个用电异常点,个数较多且较为密集。
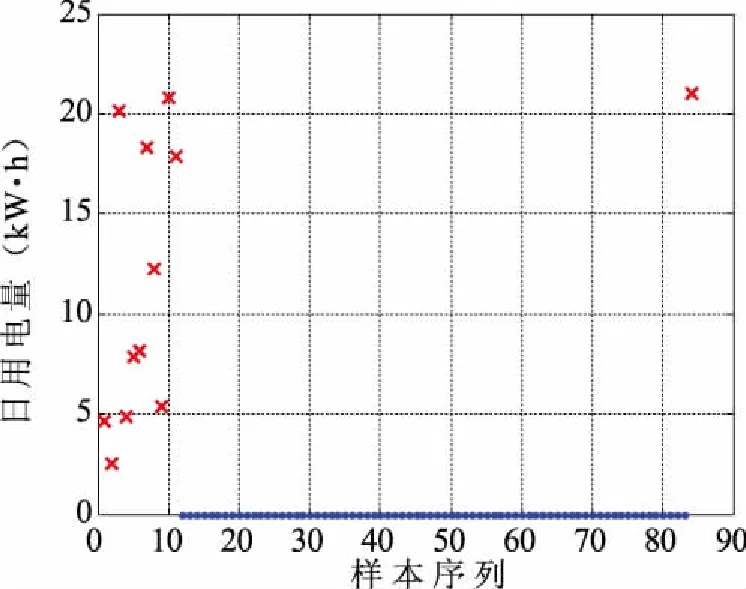
图7 标签1类异常点二次分类结果
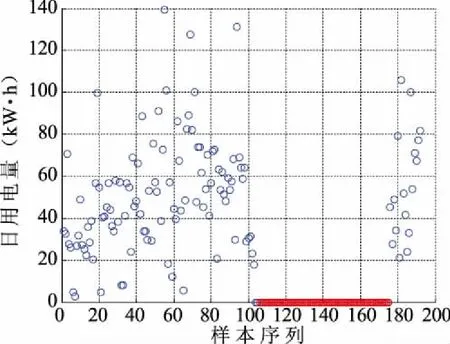
图8 异常点检测算法分析结果
通过上述案例分析得到的窃电报警时间为2015年7月17日,实际查证的开始出现窃电异常的时间为2015年7月13日,与算法流程中设置连续5天出现异常,第5天开始报警的条件相符合。此外,案例中分析的电量数据是来自正常的用电信息采集系统,不存在因电能表时钟偏差导致电能计量不准确的问题,因此算法的报警时间是准确的,验证了该方法在窃电辨识方面的准确性和实用性。
在异常数据挖掘方面,单独的聚类算法准确率为q1=73/84×100%=86.9%,单独的异常点检测算法准确率为q2=70/84×100%=83.3%,两种算法融合的方法检测准确率为q=79/84×100%=94.0%。
由于篇幅限制,其它算例分析过程在这里就不一一赘述,此处选取了10个典型案例(包括上述案例)的算法分析结果与实际查证结果进行了对比(见表2)。
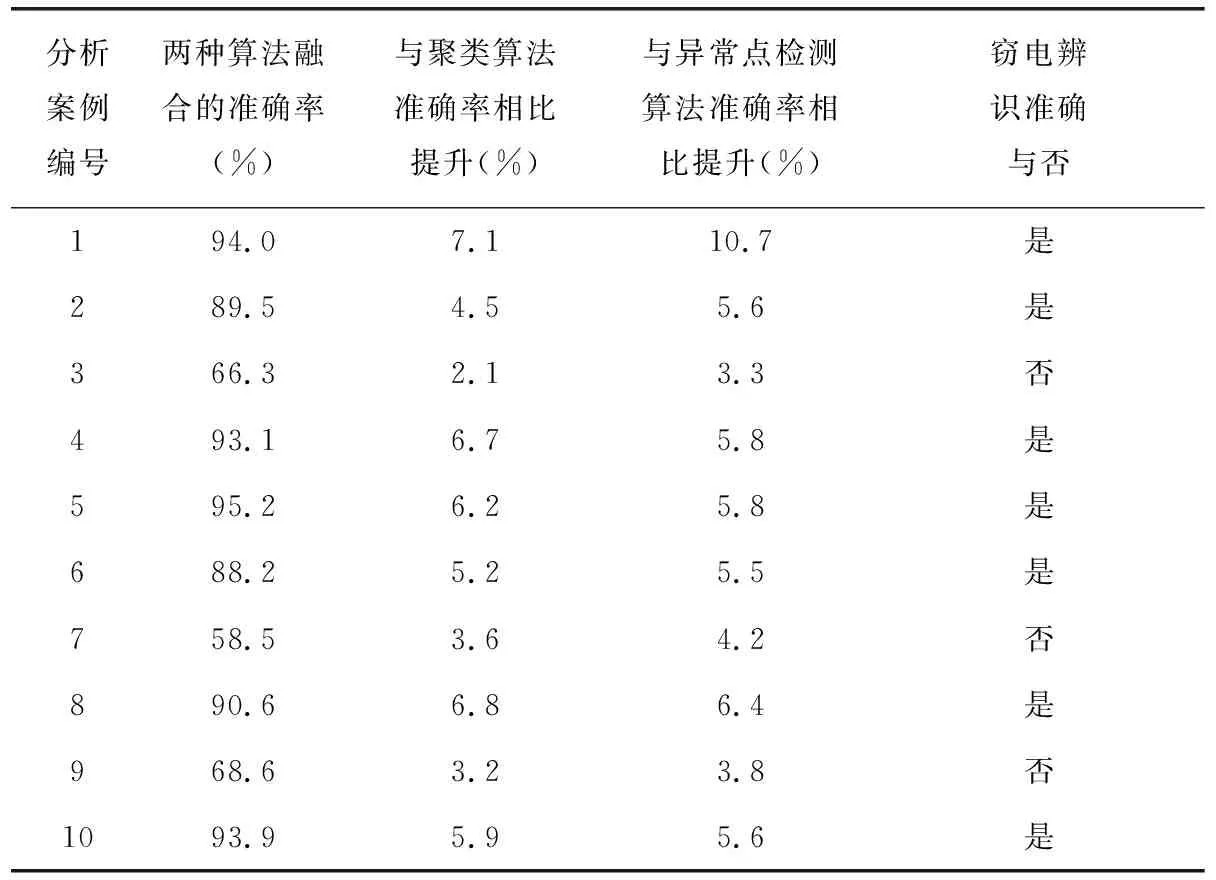
表2 典型案例分析结果汇总
从表2可以看出,对于窃电辨识准确的7组样本,两种算法融合后的异常数据挖掘准确率相比聚类算法平均提升6%,相比异常点检测算法平均提升6.4%,其中有3组样本的算法分析结果与实际查证结果存在偏差的原因在于这些用户是间断性用电,因为窃电原理是用户采取非法手段不用电或少用电,而间断性用电用户在正常不用电时期的用电数据会被当做异常点处理。
综合大量的样本分析结果,表明融合聚类和异常点检测算法的窃电辨识方法在一定程度上提高了窃电辨识的准确度和效率,具有一定的实用性。
3 结束语
在深入分析窃电原理、研究聚类算法和异常点检测算法的基础上,结合用电信息采集系统提供的用电数据,提出了一种融合聚类和异常点检测算法的窃电辨识方法。该方法利用聚类算法先对样本进行粗略分类,按照包含窃电异常嫌疑点数量大小降序排列,然后利用异常点检测算法对窃电嫌疑最大的一类数据进行二次分析,最后综合两种算法分析结果和实际情况确定最终的窃电嫌疑数据,并实现窃电报警。
相较于单纯的聚类算法和异常点检测算法,该方法将两种算法进行结合,一定程度上弥补了单一算法的不足,可以将窃电辨识的准确率提高6%左右,进而提升了反窃电工作的效率。
当然,本算法仍需要不断的完善,研究更加合适的聚类准则函数和更加高效的异常点筛选机制将会进一步提高窃电辨识的准确性。因此,针对该方法的完善工作将会在后续的研究中进行。
