学科合作网络链路预测结果的排序鲁棒性
2018-11-12李亚婷
张 斌 李亚婷
(1.武汉大学中国传统文化研究中心; 2.武汉大学信息资源研究中心,武汉,430072)
对于研究者来讲,组建一个科研团队,要面对的首要问题是如何找到合适的科研合作对象。在科研起步阶段,大多数研究者是通过与导师或所在师门的同学来完成首次合作;在参加工作阶段,就会和自己所在的科研团队进行合作。有时,研究者会碰到这样的情况,因为某些研究工作的需要,主动想要在本学科领域里进行跨团队合作,甚至是跨学科合作,而这目前主要是靠研究者自身的社会关系和经验判断来解决。如果研究者能了解到相关内容的研究和合作现状,那么他会很容易知道自己的合作对象应该是谁。即使在实际合作中,研究者之间没有联系或者是联系较弱,但这些信息对于他们来讲也是非常重要的,至少可以提个醒,是否忽略了一些很重要的或者是具有潜在意义的合作关系,而链路预测在这方面可以发挥重要作用[1]。
相较于学科整体合作面貌,对学科核心作者之间的链路挖掘会更有针对性,对于理解未来科研合作走向也是至关重要的。但是,当抽取核心作者并构建网络时,该网络相较于原网络可能会出现结构上的变化,而网络结构的改变势必会影响到最终的预测结果和预测效果。基于此,本文针对图书馆情报文献学合作网络,抽取整体作者合作网络和核心作者合作网络,分析两者应用场景的差异,初步探讨由实验网络结构的改变而带来预测结果的排序鲁棒性(robustness)问题。
1 相关研究回顾
如何刻画复杂网络中节点之间的相似性是数学和物理学里的一个重要理论问题,并不容易解决。基于结构相似性的链路预测指标和算法只涉及到网络的结构信息。不同的相似性指标会侧重从网络结构的某一个方面来刻画,如果目标网络在此方面的结构特征显著,那么就可以得到较好的预测效果,反之,则较差。数据规模[2]、聚集系数[3-4]、同配系数[5]、网络效率[5]等结构参数会对不同预测指标的预测结果产生重要影响。从统计分析视角来看,基于邻居节点的预测指标和基于拓扑结构的预测指标在各自内部之间具有相当程度的一致性,而择优连接(PA)指标则和其他指标之间差异性非常大[6]。从应用效果来看,AA指标和Katz指标都是很有效的预测指标,能准确快速地识别未知链路,预测结果可以用于识别共同兴趣偏好和发现历史合作经历[7]。同时,对目标网络的不同抽取策略和方案会造成网络结构的扰动(perturbation),这种扰动会影响到链路预测的排序结果。
在网络科学研究中,如果在移走少量节点后,网络中的绝大部分节点仍然是连通的,那么称该网络的连通性对节点故障具有鲁棒性。Albert等[8]比较了随机网络(ER网络)和无标度网络(BA网络)的连通性对节点去除的鲁棒性,发现在ER网络中,随机去除网络中大量节点,则会使得网络破碎成很多孤立的子网络;而在同样规模的BA网络中,随机去除同样多的节点,网络却能保持基本的连通性,但若蓄意去除少量大度节点就可以破坏网络的连通性。Iyer等[9]考察了在无标度网络、指数网络以及部分真实网络中,按照度中心性、中介中心性、接近中心性、特征向量中心性等四种节点排序算法以及随机移除节点方法,进行节点移除后对网络巨片的影响,结果显示,在高能物理合作网络和网络科学合作网络中,度中心性和中介中心性在识别重要节点上都比较有效。
移除节点会带来网络结构的改变。反过来看,真实复杂网络的结构一般都会随着时间而发生变化,通常表现在两个方面:一是节点数量的增减,二是连边数量的增减。真实复杂网络的演化过程往往还是加速增长的,连边的数量比节点的数量增长得更快[10-11]。而在实际数据采集和分析中,由于数据源、数据处理等方面的问题,研究者很难甚至无法获取到完整的网络数据。因此,一方面是真实网络在不断演化,另一方面是获取到的网络数据并不完整,这就造成了所构建网络的结构本身会发生扰动。相应地,在进行链路预测时,自然希望关于节点对之间相似性的某种排序能够对网络结构的扰动具有一定的鲁棒性。
2 研究设计
2.1 实验网络结构
研究选择中文社会科学引文索引(CSSCI)数据库收录图书馆情报文献学的来源期刊,获取在2008—2013年期间该学科一直被连续收录的14本期刊上发表文章的题录数据[12],构建整体作者合作网络G0,作为初始研究对象。为了构建网络结构扰动的实验环境,需要采用节点移除策略,并完整的保留余下部分,相关实验网络见表1。具体的处理过程如下:
(1)将网络G0按照节点度值从小到大进行抽取,即移除节点度小于或等于该度值的节点,形成实验网络。比如:按“节点度>1”策略,表示抽取整体作者合作网络中节点度大于1的节点,即移除节点度小于或等于1的节点,之后余留下的网络,以此类推。
(2)研究假定年均发文在一篇以上的作者为核心作者。针对网络G0,考虑时间跨度六年,设定节点度大于或等于6的节点为核心作者节点,即“节点度>5”策略,由此抽取出核心作者合作网络G0′。
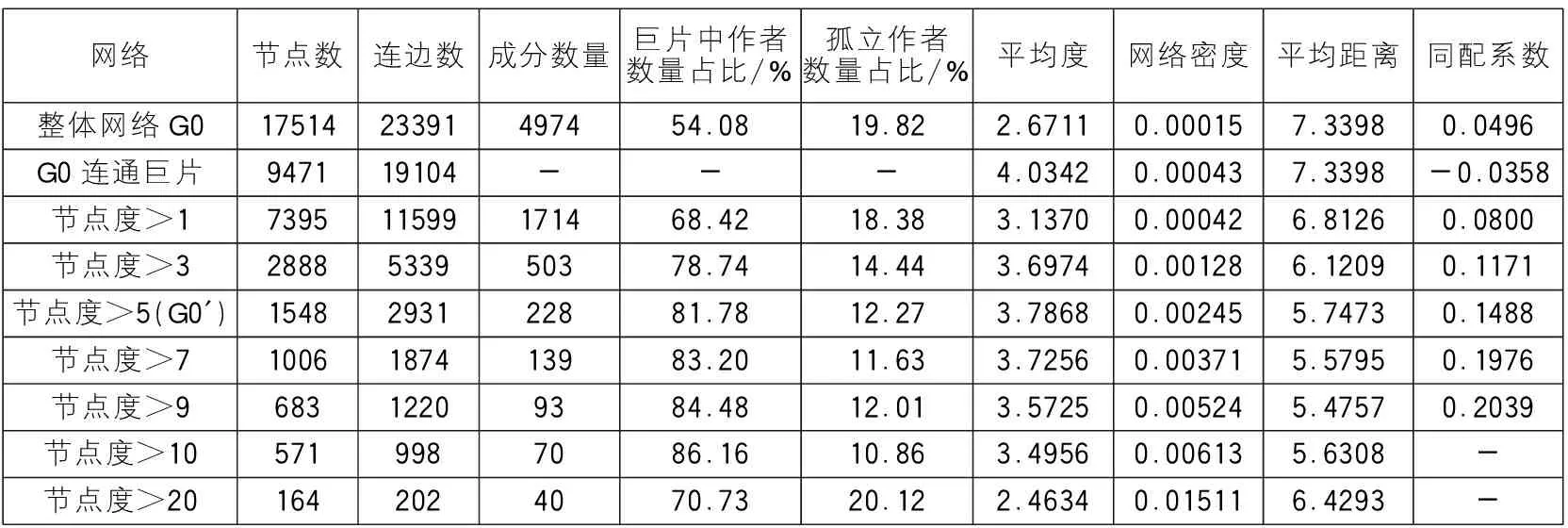
表1 按不同节点度标准抽取的实验网络
2.2 链路预测指标
由于本次实验所构建的网络结构会发生扰动,处于相同角色的节点,即使没有相同的邻居节点,也有可能因为角色的相似而产生连接。预测合作关系时,既要考虑结构等价的相关指标,同时也要考虑一般等价的相关指标。因此,这里使用的是较为常见的六种链路预测指标,包括基于节点的相似性指标(CN指标、AA指标和PA指标)和基于路径的相似性指标(Katz指标、RootedPageRank指标和SimRank指标)[6]。
CN指标[13]:sxy=Γx∩Γy。一个给定的网络,节点vx的邻居集合为Γx,节点vy的邻居集合为Γy,则它们之间的相似性定义为共同的邻居数。
Adamic-Adar(AA)指标[14]:
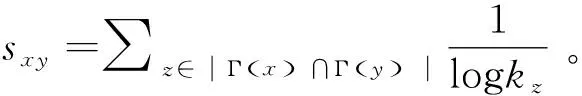
择优连接(PA)指标[15]:sxy=kxky。其思想是如果参照无标度网络产生的原理,认为新加入的节点更倾向于与大度节点相连接,那么可认为两节点间产生连边的可能性与两节点的度均有关,也就是说,可认为相似性正比于两端点度的乘积(Product)。因此,PA指标又称为度积(DegreeProduct)指标。
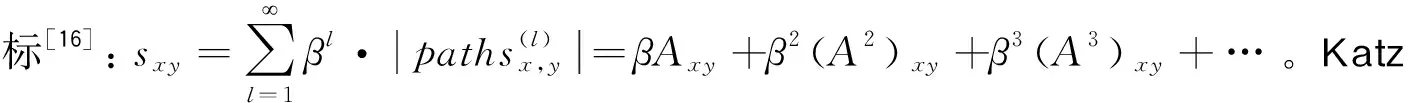
RootedPageRank(RPR)指标[15]:受网页排序算法PageRank的启发,RootedPageRank指标假设随机游走粒子在每走一步的时候,都以一定概率返回初始位置,该指标又称为带重启的随机游走(RandomWalkwithRestart,RWR)。
SimRank指标[17]:
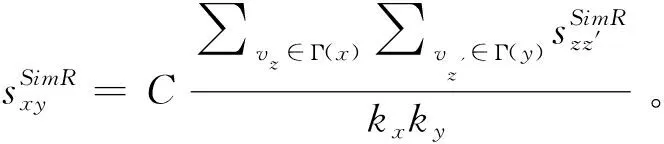
3 分析与结果
3.1 预测结果的比较
在实际预测时,AA指标和Katz指标是很有效的预测指标,能准确快速地识别未知链路[7,15]。因此,这里将链路预测指标AA和Katz应用在整体作者合作网络G0的连通巨片和核心作者合作网络G0′,分别得到相似性计算结果的排序前10的合作组合,见表2和表3。
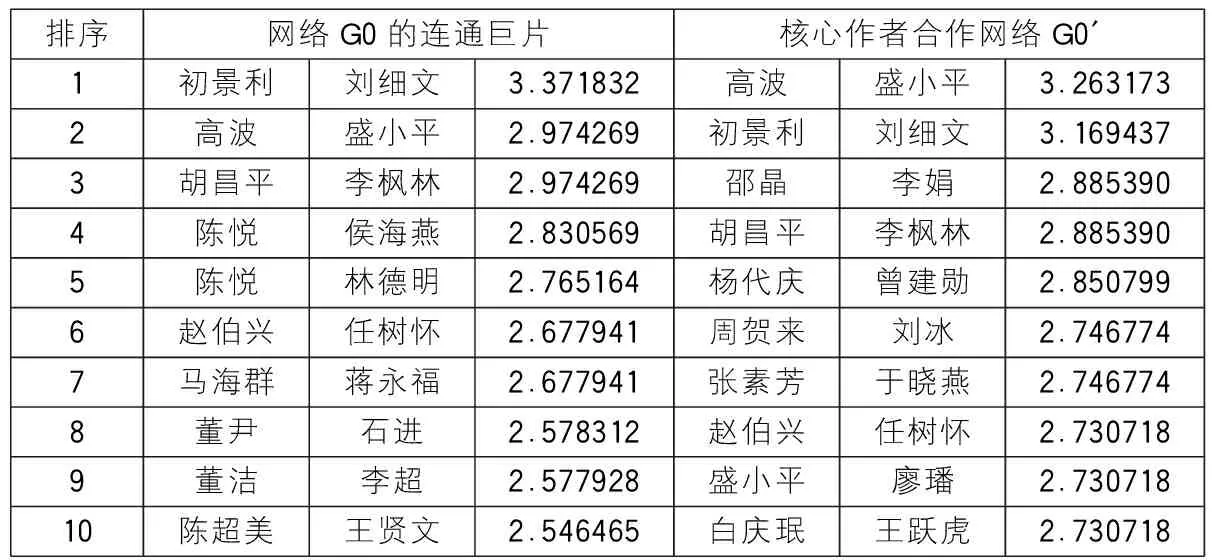
表2 AA指标预测结果排名前10对比
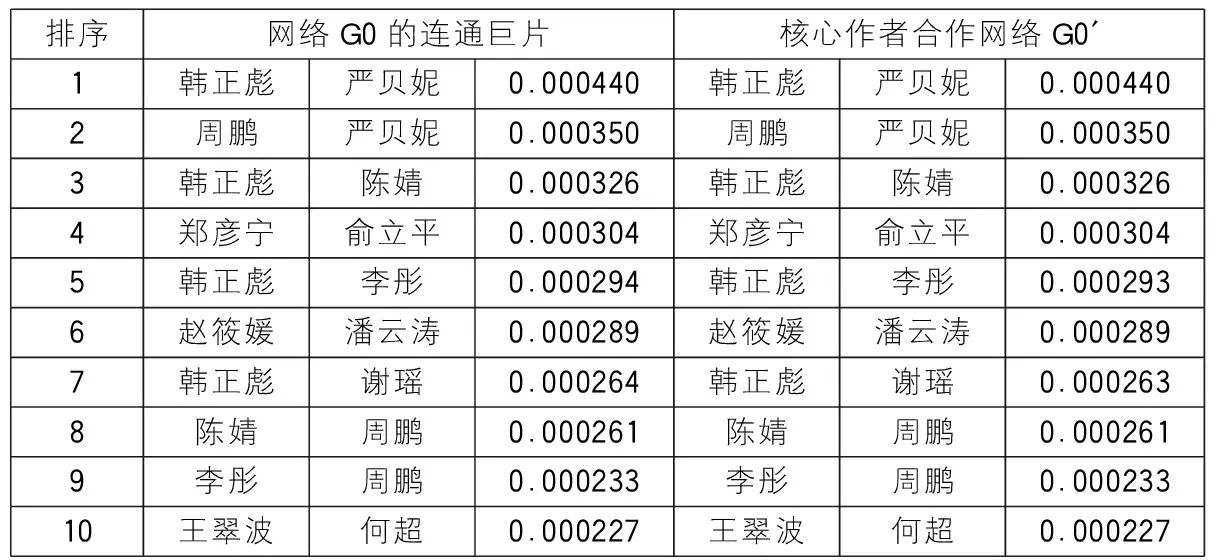
表3 Katz指标预测结果排名前10对比
易于理解,核心作者在科研产出上的能力会很强,如果依此假定核心作者的科研活跃度也很高,会积极主动地进行科学交流并建立合作关系,则所挖掘出来的核心作者组合在未来便具有更高的可能性进行科研合作,这些合作组合是应该被挖掘出来并进行推荐的。利用可视化工具Gephi(版本0.82)可以呈现出这些挖掘出来的作者组合所在的局域网络,从而进行应用场景讨论。在具体方法上,选择相应的作者节点及其邻居网络,将这些子网络过滤出来。图示中节点的不同着色,表明其所归属的社区,节点的大小代表着度值的大小。
图1所示为AA指标下G0′网络中核心作者“初景利”所在的局域网络,设邻居网络的深度为2,过滤出来的子网络包含117个节点300条连边。此时,对于给定的作者节点“初景利”,利用AA指标得到的短的排序的候选邻居列表,就可以作为合作推荐建议给出了。
当然,在这个推荐过程中,如果能将相关作者的研究兴趣进行关联分析并突出出来,则会更有说服力。事实上,由于合作网络的结构形成本就会受到很多外界主客观因素的影响,如地理距离、经济环境、社会信任等[18],换句话说,基于结构相似性的预测结果也会涵盖研究兴趣这一维度,因此,依据预测结果排序构建推荐列表也是合适的。
图2所示为AA指标下作者组合“初景利”和“刘细文”所在的局域网络。其中,a图为网络G0的连通巨片中的局域网络,邻居网络的深度为1,包含60个节点163条连边;而b图为G0′网络中的局域网络,邻居网络的深度为1,过滤出来的子网络包含31个节点82条连边。对比分析,b图所示网络在规模上比a图所示网络减少了一半,但所呈现出的邻居节点则更加清晰明确,更易挖掘出潜在合作对象。
作者节点“初景利”和“刘细文”归属于同一个社区,两者之间并未建立过合作关系。在CSSCI数据库中查找这两人在1998—2007年所发表的论文信息,显示两人在这个时间段内也没有共同发表过论文。在2008—2013年间,初景利发表论文28篇,刘细文发表论文25篇,与这两人都有过合作的作者(共同合作者)共有9人。这些合作论文的主题都与开放存取相关,也就是说,初景利和刘细文的共同兴趣偏好是有关开放存取的话题。基于一个熟人网络的假设,同时这两人又具有共同的兴趣偏好,他们具有很高的潜在合作的可能性,这不仅是对过去,而且对未来也是有效的。事实上,初景利和刘细文目前同在中国科学院国家科学图书馆工作,两人相互之间是同事关系,即为熟人关系。进一步地,如果要解读合作关系是否成立,则需要更多的节点属性信息。
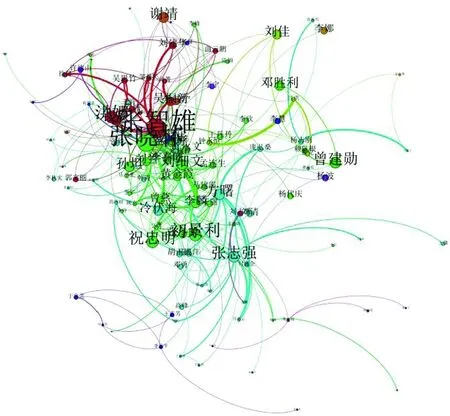
图1 核心作者“初景利”所在局域网络的可视化
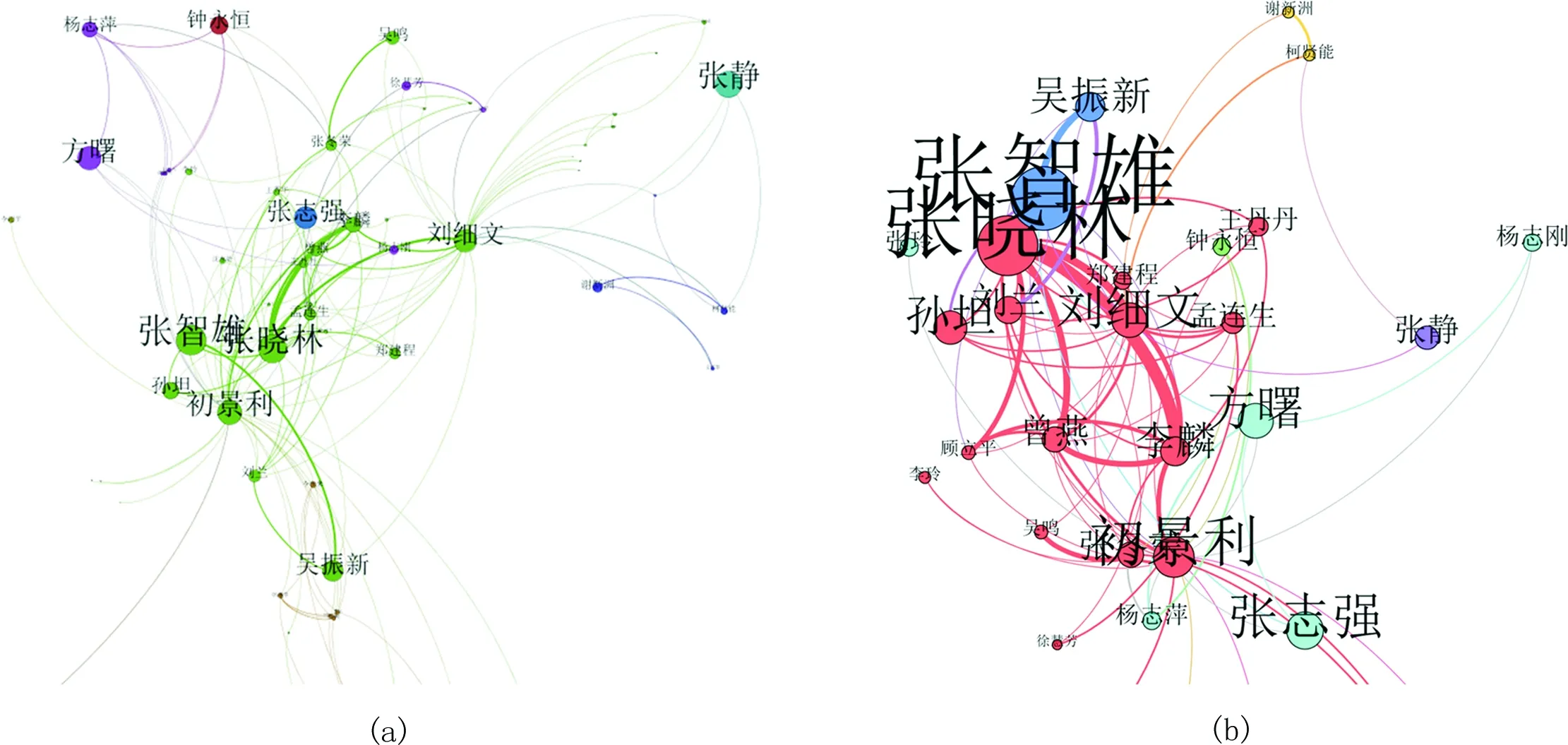
图2 “初景利”和“刘细文”所在局域网络的可视化对比
对比表2和表3中相应指标排序前10作者组合的排序位置,可以发现,AA指标下的作者组合不仅在结果上产生了变化,而且相同结果的排序位置也有了变化;但Katz指标下的作者组合却保持了一致,且得分数值及其排序位置也都基本一致,因此,本次研究不再对Katz指标下的预测结果进行可视化分析。由于整体作者合作网络G0的连通巨片和核心作者合作网络G0′的结构有所不同,于是,这种网络结构的改变会给排序结果造成多大影响,就是需要关注的问题了。
3.2 排序鲁棒性分析
在上述实验中,当抽取核心作者并构建网络时,实验网络会出现结构上的变化,这种结构上的改变也确实影响到了最终预测结果。不妨计算AA指标和Katz指标在整体作者合作网络G0中的预测结果,将其与核心作者合作网络G0′进行比较,计算预测结果在相同规模下的重叠情况,结果见表4。此时,从重叠比例上看,Katz指标相比AA指标,对网络结构的改变更具有抗干扰性。

表4 整体作者合作网络与核心作者合作网络预测结果的重叠情况
表1所示是2008—2013年间图书馆情报文献学合作网络按照不同抽取策略所形成网络的拓扑结构特征。随着抽取节点度值的增大,网络结构会发生剧烈变化,同时网络的同配系数也随之增大,这意味着大度节点之间产生联系的概率会升高。这种抽取网络的行为可以看作成一种节点移除策略,即按照节点度值从小到大批量移除指定度值的节点。需要说明的是,研究所使用的实验网络是无标度网络。
相比于随机网络而言,无标度网络对于随机节点故障具有极高的鲁棒性。按照表1的节点移除策略,每次选取的节点都是度值很小的节点,批量移除这些节点对整个网络的连通性不会产生大的影响,见图3,其中f为去除的节点数占原始网络总节点数的比例。

图3 批量移除节点后合作网络的鲁棒性
虽然批量移除度值很小的节点仍可以保证网络的基本连通性,但却很容易造成共同邻居节点的缺失,这对基于共同邻居的相似性指标(如:CN、AA)非常不利。将表4的计算过程重新应用到“节点度>3”和“节点度>5”的网络上,以“节点度>5”的网络为基准,计算基于节点的指标(CN、AA、PA)和基于路径的指标(Katz、RootedPageRank、SimRank)的预测结果的重叠情况,见图4。

图4 不同预测指标排序结果的重叠比例发展趋势
随着比较规模的扩大,CN、AA、Katz指标的重叠比例呈现出下降趋势,而PA、RootedPageRank、SimRank指标的重叠比例则呈现出上升趋势。一般来讲,预测结果规模通常并不会很大,不妨取值为1000个。当预测结果规模在1000个以内时,Katz指标的重叠比例是这六个指标中最高的,RootedPageRank指标的重叠比例是最低的;当预测结果规模超过1000个时,Katz指标的重叠比例下降到约60%并保持稳定,RootedPageRank指标的重叠比例也还是最低的。从这六个指标的重叠比例数值和发展趋势看,网络结构的扰动对于Katz指标的预测结果影响最小,对RootedPageRank指标的预测结果影响最大。值得注意的是,当预测结果规模超过300个时,PA指标的重叠比例上升到约70%并保持稳定;当预测结果规模超过1000个时,PA指标的重叠比例超过Katz指标。这表明,网络结构的扰动对于PA指标的预测结果影响也较小。
3.3 预测效果的分析
本研究所构建的核心作者合作网络,其基本假设是将年均发文在一篇以上的作者视为核心作者。这里将整体作者合作网络G0进行时间快照划分,得到两个快照网络,分别是2008—2011年间快照下作者合作网络G1和2012—2013年间快照下作者合作网络G2;之后,按节点度值抽取核心作者,将核心作者合作网络过滤出来,分别设为G1′和G2′[6]。表5设置了四种作者数据集抽取方案,始终保持G1′的节点度比G2′的节点度的值多2。
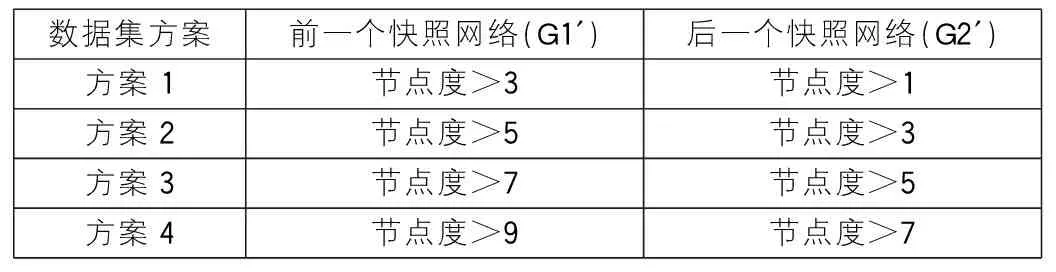
表5 作者数据集方案
不同的作者数据集抽取方案会造成网络结构发生不同程度的扰动。针对不同方案下的G1′和G2′进行链路预测,观察预测效果的变化幅度。预测效果的评价指标采用F-score,其最大值记为fmax[6],方案1至方案4的评价结果对比如图5所示。显然,六种链路预测指标在方案1和方案2下,预测效果变化不大;而从方案3开始,预测效果出现了较大变化,特别是方案4,预测效果变化幅度最大。
从预测效果的稳定程度来看,AA、Katz和SimRank显得较为稳定,它们受到网络结构扰动的影响相对较小。但需要指出的是,方案4对网络结构造成的破坏最大,而结果是预测效果取得了大幅提升。因此,实验网络结构的改变应当有一定限制,否则预测效果会出现大幅改变,即预测结果的排序鲁棒性也就无从谈起了。
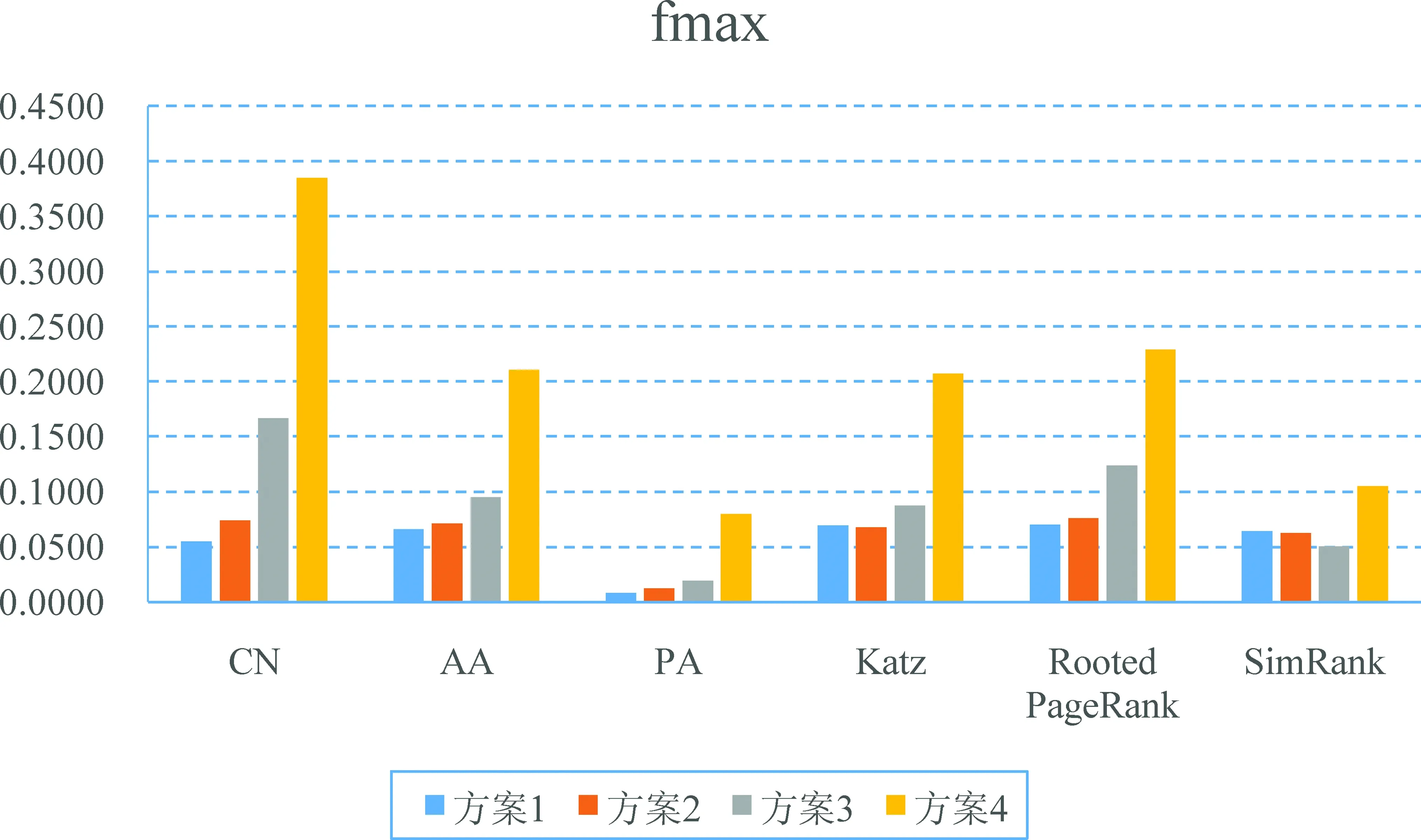
图5 不同作者数据集方案下fmax的比较
4 结束语
学科合作网络属于高凝聚性的稀疏网络。在实际操作中,会根据不同研究目的采取不同抽取网络的方案。由此带来实验网络结构的改变,是否影响到链路预测指标的预测结果和预测效果,影响程度又是怎样的,这是本文所关注的。研究通过比较在网络结构发生扰动时,不同预测指标的预测结果和排序情况,以及在相同规模下的重叠情况可以粗略判断出排序鲁棒性的好坏。研究发现,网络结构的扰动对于Katz指标的预测结果影响最小,对RootedPageRank指标的预测结果影响最大。研究网络结构的改变对链路预测效果产生的影响,发现AA、Katz和SimRank在预测效果方面显得较为稳定,它们受到网络结构扰动的影响相对较小。
严格来讲,本研究使用的计算重叠比例方法,对于分析排序结果对网络结构的扰动具有鲁棒性还是显得比较粗糙,但却具有统计学意义。通过计算重叠比例,可以快速定位出在实验网络中那些特别稳定的且相似性得分数值又很高的节点对,并用作推荐目的。更精确的鲁棒性评价通常需要考虑排序结果的位置是否出现了变化[19]。而在实际应用场景中,会首先关注量(重叠数量和比例)的变化,再关注质(排序位置)的变化。
此外,在本研究中,对核心作者的发文数量的设定是否会影响到预测效果,换句话说,就是对核心作者形成的合作网络的预测是否会比一般情况下的合作网络显得更容易的问题。可以从同配性角度上来思考。随着抽取节点度值的增大,网络的同配性系数也随之增大,这意味着大度节点之间产生联系的概率会升高。也就是说,若将度值大的节点视为核心作者,则核心作者之间会有更大的概率建立合作关系。当然,这一观点是否具有普遍性,还需要在更多的真实网络中加以检验。
