不平衡数据分类研究及在银行营销中的应用
2018-11-09季晨雨
季晨雨
(北京卫星信息工程研究所,北京 100000)
0 引言
不平衡数据分类是分类问题中比较特殊的问题,主要特点是样本类分布不平衡。在不平衡的二分类问题中,表现为其中一类的学习样本远多于另一类的样本[1]。不平衡数据集分类会存在偏向多数类,对少数类误分比率很高的问题。这是因为多数类的样本数目明显多于少数类,但有时候少数类恰恰是我们关注的重点。
本文利用了银行营销人员以电话方式对其定期存款业务进行推销的案例。随着市场竞争的加剧,银行需要识别目标用户并进行精准营销以扩大收益,提高工作效率。在本例中,需要根据以往营销积累下的数据集构建客户是否会购买定期存款的预测模型,帮助银行识别目标客户群体,进行精准营销,提高营销的成功率,避免非目标客户因电话营销对银行产生负面印象。在该案例中,以客户是否购买定期存款为目标属性,该属性中“是”和“否”的数据集样本数目比为4640∶36548,属于典型的不平衡分类问题。如果在构建分类模型时不考虑数据集的平衡性,模型会出现对少数类误分率很高的问题,但少数类恰恰是我们关心的目标客户群体。因此,在构建分类模型时需要解决不平衡数据分类的问题。
1 不平衡数据分类问题解决办法
解决不平衡数据分类问题,可以从数据、算法、评价指标三个层面着手[2]。
1) 从数据的角度:通过改变原始数据集的分布,采用过采样或欠采样,即增加少数类样本或减少多数类样本,使不平衡数据集的正负类样本数达到平衡[3]。
2) 在算法上:修改已有的分类器,使之适应不平衡数据的特征。主要包括代价敏感分类器,集成学习等方法。其中,代价敏感分类器对少数类样本和多数类样本分类错误的代价区别开来,将少数类错误地分到多数类将付出更大的代价。集成学习是在训练集上训练多个分类模型,预测时根据每个分类器的分类结果进行投票,得到最终的预测结果。常用的组合分类方法,包括Bagging,Boosting以及随机森林Random Forest等[4]。
3) 从评价指标上:对于一般的分类模型通常使用模型的准确率进行评估。分类模型的准确率反映了分类模型对数据集整体的分类性能。但只使用准确率来衡量对不平衡数据集的分类效果,并不能反映对少数类的分类性能。利用少数类的召回率(查全率)可以反映正确判别的少数类占所有少数类的比例。 F1分数同时考虑了分类模型的准确率和召回率,是处理不平衡数据分类问题时的有效评价指标[5]。
F1分数可以看作是模型准确率和召回率的一种加权平均,F1分数的分布在0-1之间。
还可以采用ROC曲线下的面积AUC作为评价指标。因为ROC曲线有一个很好的性能,当测试集中的正负样本的分布变化时,ROC曲线能够保持不变,因此适合作为不平衡数据集分类时的评价指标[6]。
2 银行营销中的不平衡数据分类
2.1 数据集说明
本文所研究的数据集来源为UCI所提供的Bank Marketing Data Set数据集,该数据与葡萄牙银行机构实施电话直销向客户推销其定期存款业务有关。数据集收集的时间自2008年5月至2010年10月,共包括41188个样本和21个属性,其中目标属性为是否购买定期存款,分别用“yes”和“no”代表是和否。输入变量在结构上有数值型和类别型,还可以按属性的含义分为客户信息属性、银行营销行为属性、社会经济背景属性和其他属性。

表1 数据集属性列表
2.2 数据预处理
由于数据集中存在类别型属性,需要对类别型属性进行数值化操作,即编码处理。对housing、loan等二分类属性,进行0-1编码,对education等有序分类属性,按影响由小到大的顺序编码,对job,marital等无序分类属性进行哑变量编码。
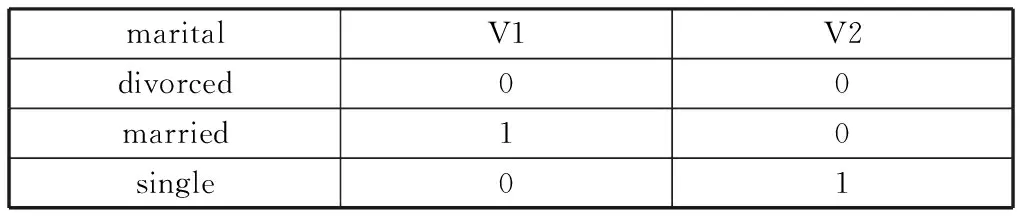
表2 marital属性哑变量编码
对于数值型特征,需要进行连续型特征离散化处理,以便减小极端值和异常值对模型的影响。例如,duration属性最大值为4918,平均数为258,中位数为259,75%分位数为319,均远远小于最大值,所以需要对duration变量进行离散化。为了应对不同属性度量单位不同的情况,减小对基于距离度量的分类模型的影响,进行数据规范化,将数据压缩到一个范围内。
由于数据集的某些类别型属性存在取值为unknown的样本,需要进行缺失值处理。在job和marital属性上的缺失值较少,可以直接把含有缺失值的样本删除。对于education、loan等缺失值较多的属性,利用各属性值完整的样本作为训练集,以缺失值所在的属性作为目标属性进行分类,以此预测缺失值。
2.3 实验结果与分析
原数据集样本个数41188,其中包括4640个正类样本,即购买定期存款的客户样本和36548个负类样本,即没有购买定期存款的客户样本。
为了解决样本的不平衡问题,我们需要对训练集进行SMOTE过采样。对于SVM模型,需要设置class_weight参数为‘balanced’来进行样本均衡。
对训练集采取5-fold交叉验证,并以准确率最高的模型使用的超参数作为最终模型的超参数。将训练并验证好的模型应用在测试集上,以得到的分类结果作为分类模型性能的比较依据。
考虑到数据集的不平衡性,单独使用准确率已经不能正确评价分类模型的好坏,因此选择召回率(查全率)、F1分数和ROC_AUC作为客户购买预测模型的评价指标,三个评价指标均是值越大,分类模型的性能越好。
分别利用逻辑回归模型、决策树模型、SVM模型、随机森林模型、GBDT模型得到的分类结果如表3所示。
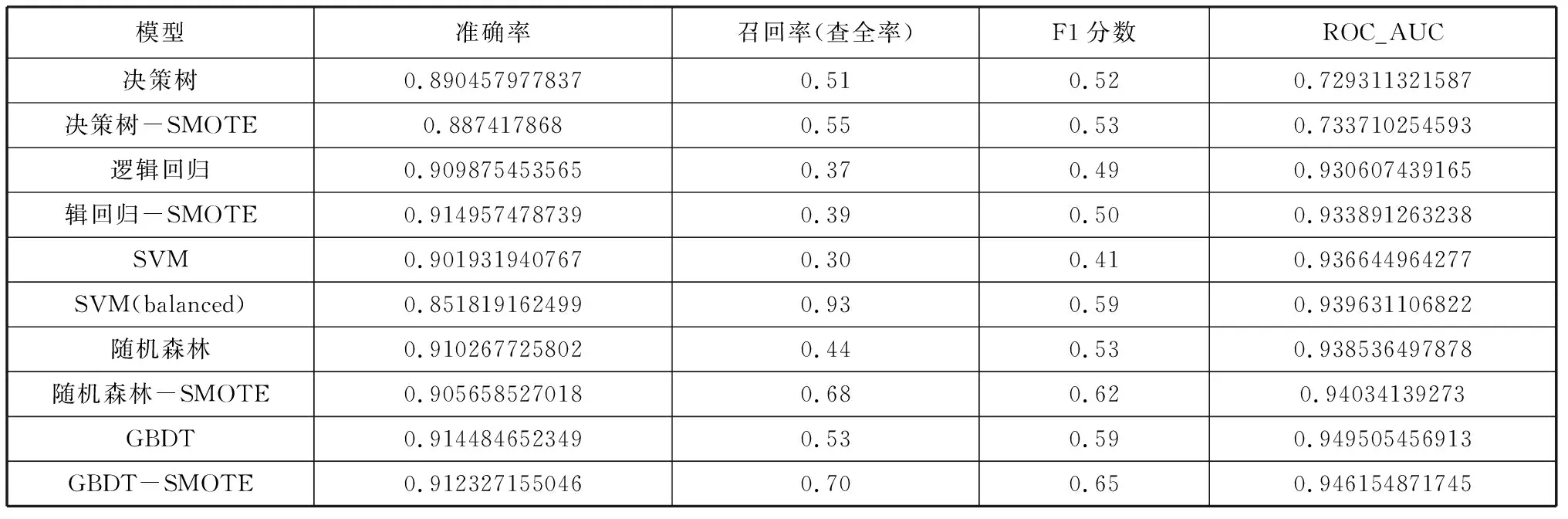
表3 各模型分类结果
根据各模型的分类结果可知,经过SMOTE重采样后的决策树模型、逻辑回归模型、随机森林模型和GBDT模型在召回率(查全率)、F1分数和ROC_AUC评价指标上均有提升,说明SMOTE重采样可以在一定程度上减少样本的不平衡带来的影响。设置‘balanced’后的SVM模型比不设置的SVM模型召回率(查全率)、F1分数和ROC_AUC评价指标上有所改进,但付出了准确率降低的代价。
总的来说设置‘balanced’后的SVM模型在召回率(查全率)上表现最佳,基本可以识别大部分的目标客户,即选择购买定期存款的客户。而采用SMOTE重采样后的GBDT模型在召回率(查全率)、F1分数和ROC_AUC评价指标上的综合表现最好。
3 总结
本文对不平衡数据分类问题进行了研究,从数据、算法、评价指标三个层面介绍了不平衡数据分类的解决办法,并将其应用于银行营销中客户购买定期存款的预测任务。对原始数据集进行了数据预处理,构建了逻辑回归、决策树、SVM、随机森林和GBDT预测模型,并对模型进行参数优化和评估。其中,设置‘balanced’后的SVM模型在召回率(查全率)上表现最佳,基本可以识别大部分的目标客户,即选择购买定期存款的客户。而采用SMOTE重采样后的GBDT模型在召回率(查全率)、F1分数和ROC_AUC评价指标上的综合表现最好。将训练好的预测模型应用于银行营销中,可以帮助银行识别目标客户群体,进行精准营销,提高营销的成功率,提高工作效率,扩大收益。
