临床研究中基线信息的统计分析与统计图表
2018-11-08谷鸿秋
谷鸿秋
在临床研究统计分析思路与统计图表系列的首篇文章中[1],我们将临床研究的统计分析思路归纳为三部分:描述基线信息;估计效应大小;补充敏感性分析。基线信息作为临床研究论文结果中不可或缺的重要内容,其统计分析方法和展现形式也值得临床研究者重视。本文将结合研究实例阐述基线信息分析所涉及的统计方法和统计图表。
1 基线信息的概念与内容
“基线”并无严格的定义,Segen医学词典给临床研究语境中基线(baseline)的解释为:基线是研究人群在前瞻性研究中最开始时的健康状况,是研究对象在接受试验组或对照组干预措施前的“0”时刻。药物的安全性和有效性可从基线数据的变化中评估,基线数据组间分布的差异或对结果评估造成偏倚[2]。通常所谓的“基线”实则相对“随访”而言,专用于前瞻性研究设计,不过其它研究设计类型也可用“基线“泛指研究人群的基本情况。基线信息包括两方面的内容:(1)研究人群的入选排除过程。先用入选标准粗略圈定分析人群,再用排除标准修正分析人群;(2)研究人群基线特征的描述与比较。基线特征常包括社会人口学特征、临床特征、实验室检查指标及疾病史和用药史等。

图1 %ggBaseline 宏程序生成的基线信息表格示例Table I:两组;Table Ⅱ:三组及以上;Table Ⅲ:带标化组间差值;Table Ⅳ:单组
2 基线信息的展示形式
研究人群的入选排除情况,常用的展示形式是研究人群流程图,即文中的“图1”。不同研究设计类型在具体的入排流程上有所不同,此前文章中已有提及,也展示过相应实例[1],此处不再赘述。研究人群基线特征的描述与比较常用基线表格展示,即文中的“表1”。“表1”在具体展示时,依据研究情形的不同,有不同形式:干预性研究中,按实验组和对照组分组展示,如PLANTO、CHANCE等大型随机对照临床试验[3,4];观察性研究中,按不同的暴露因素分组,如CNSR Ⅱ研究中评估急性脑卒中合并非瓣膜房颤患者出院使用华法令的影响因素时按是否房颤分组去描述、比较基线信息[5],或按暴露因素的不同水平分组展示,如CKB研究组在研究肥胖和卒中发生的关系时,基线表格里按暴露因素BMI的18.0、20.5、23.0、25.0、27.5、30.0六个切点分成七组[6]。上述两种思维均为从因到果的逻辑顺序,适用于前瞻性的研究设计。若为回顾性研究设计,则按从果到因的逆向逻辑顺序,依据结局分“病例”和 “对照”组,如Fox等在探讨冠心病与儿童时期卒中危险因素关系时,以是否患冠心病分为病例组和对照组来描述和比较基线信息[7]。若不分组,可将所有研究人群作为单组描述,但这种情形较为少见,如跟着指南走(GWTG)的台湾登记研究[8]。
3 基线信息的统计方法
研究人群的入选排除,只需统计每个排除标准的频数和百分比即可,但应采用层次排除法,以避免因不同的排除标准统计的人数有交叉致使合计排除人数与实际排除人数不一致。所谓层次排除法即分层次去统计每一个排除标准所排除的人数和百分比。如NRMI2研究中研究急性心梗患者的急救医疗服务与后续护理质量时,其人群排除过程即采用了层次排除法[9]。
基线特征的描述与比较,需依据变量的不同特性(如连续变量、分类变量,正态、非正态),组别数(两组、三组及以上)选择相应的描述形式和检验方法。连续变量采用“均数±标准差”或“中位数(四分位数间距)”描述,两组时采用t检验或Wilcoxon秩和检验,三组时采用方差分析或Kruskal-Wallis检验。分类变量采用“频数(百分比)”描述,卡方检验评估组间均衡性。传统的假设检验采用P值评估协变量的组间均衡性,但大样本时容易出现假阳性,且采用P值评估无法给出量化的差异,因此大样本的随机对照临床试验直接看均数和百分比,并不报告组间比较的P值。大样本的观察性研究则常采用标化的组间差值[10]或Hodges-Lehmann估计数[11]评估两组间均数或中位数的差异,具体统计方法见表1。
标化的组间差值和Hodges-Lehmann估计数目前国内的研究者使用较少,在此做一简要介绍。连续变量的标化组间差值计算公式如下:
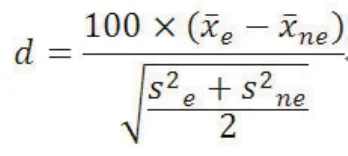
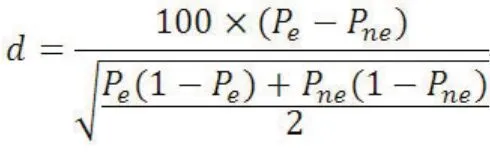
其中,Pe和Pne分别表示暴露组和非暴露组某分类变量某一水平的组内百分占比。标化差值的绝对值超过10相当于传统假设检验的P<0.05,可认为两组间协变量的差异具有统计学意义,小于10可认为组间均衡。Hodges-Lehmann估计数的想法简单,即计算两组数据配对后差值的中位数。
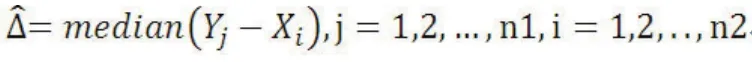
其中Yj,Xi分别表示两组某变量的观测值,n1,n2表示两组的观测个数。
4 常用的统计分析工具
研究人群入选流程图的绘制,可先借助统计软件,按层次排除法统计出各排除标准排除的人数和百分比,再借助传统的流程图绘制软件(如Visio)或办公软件(MS Office/Power point),甚至一些小巧的在线工具如ProcessON(https://www.processon.com/)、draw.io(https://www.draw.io/)等绘制流程图,再导出合适格式的图片。
基线特征的描述与比较,借助传统统计分析软件(如SPSS、SAS、R、Stata)的默认菜单或者模块基本上均可实现,但在操作难易度、便利性、可重复性、代码留痕等方面各有优劣。表2简要列举了SAS里常用的常用基线表格统计分析工具。此外,还可借助一些基于上述软件的二次开发工具包更方便快捷的获得基线统计表。如SAS软件平台里可借助笔者开发的基线表格宏程序%ggBaseline一键式自动生成适合学术期刊的RTF或PDF格式的统计表格[12]。%ggBaseline生成的统计表格,涵盖单组、多组,用P值或者用标化的组间差值/Hodges-Lehmann估计数评估组间均衡性等多种形式,具体样式如图1所示。其它软件平台,如R的qwraps2软件包里面的summary_table()函数亦可尝试[13]。

表1 基线表格的常用统计描述指标及统计检验方法
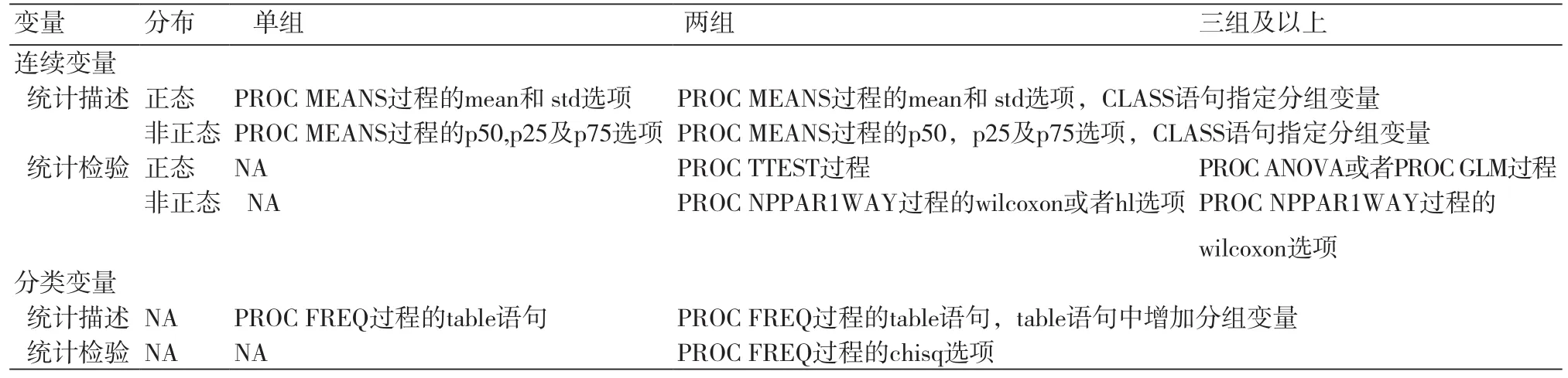
表2 基线表格的常用统计描述指标及统计检验方法的SAS实现
临床研究基线信息是研究结果的重要部分,是研究人群社会人口学特征的基本刻画,是同类研究结果互相比较的基础,同时也是对随机对照研究随机化过程的一种评价方法,此外,基线信息组间均衡性的比较也为后续多因素模型校正的效应评估提供参考依据。
