基于词向量的英文教育文本推荐技术*
2018-11-02李浩,孙媛①
李 浩,孙 媛①
(1.中央民族大学 信息工程学院,北京 100081;2.国家语言资源监测与研究少数民族语言中心 北京 100081)
教学资源不再仅仅局限于纸质文本和黑板板书的方式来呈现,而是利用到了计算机技术,以Word、PDF、PowerPoint等方式呈现,使得“教”与“学”两个过程更加方便。但教学资源如何优质共享是一个亟待解决的困难[1]。教育文本种类繁多,很多学习者不能快速准确地判断是否为自己所需,这就需要一个能精准推荐的技术。
一、相关研究
随着英文信息处理技术的发展,无论是在字词信息处理研究,还是在信息处理应用开发方面,众多科研人员进行了不懈的努力和有益的探索。在基本完成以“词”为单位的研究内容后,以“句”、“段”、“篇”为主的研究也发展十分迅速。
要想进行自然语言相关方面的研究,首先需要将人类语言数字化[2]。首先提出的是词袋表示方法,但此模型向量的维度与词典的大小成线性关系,会造成维度灾难。所以提出了词向量模型,它是一种分布式词向量[3]的表达方式,同时在分布式表达时常用的有NNLM模型、C&W模型。NNLM模型求解由于其softmax层,复杂度很高,C&W模型排序目标函数不用计算复杂的softmax了,但仍然保留了全连接的隐藏层,这部分也要消耗不少计算资源。Google的Mikolov提出一种简单的语言模型word2vector模型,就是简单地把上面复杂模型中的非线性隐层去掉了。
文本推荐技术的重点在于文本相似度的计算,在一些邮件、网页文本等推荐技术中,大多数都是用经典分类算法,它们是用传统向量空间模型来表示文本。
1.向量空间模型
向量空间模型以空间上的相似度表达语义的相似度。但是因为这种模型向量的维度与词典的大小成线性关系,所以当词典数量大时,会造成维度灾难。同时,对于一些少量词语的文本会造成高度稀疏问题。当两个文本没有共同词语时,通过模型计算,会得出两篇文档相似度为0,这对于一些相同语义、不同表达的文章进行比较,显然是不合理的。
2.词向量模型
鉴于one-hot形式模型的缺点,出现了另外一种词向量表示方式——分布式词向量。它的基本思想是:通过大规模的语料的训练,将一篇文档中的每个词语映射成一个维度预先设定的向量,一般可以为50维或100维,每个向量看成向量空间中的一个点,然后计算这些点在向量空间上的“距离”,通过距离的大小来判断对应词语之间的句法和语义的相似性。
二、英文文本向量的构建
1.word2vec技术构建词向量
word2vec可以根据给定的语料库,通过模型快速地将一个词语表达成向量形式。其算法有两种重要模型:Skip-gram(Continuous Skip-gram Model)与CBOW(Continuous Bag-of-Words Model)[4]。
此研究采用基于word2vec项目给出的googleNews语料得到词汇向量,采用word2vec预训练的单词向量模型。此训练语料库大小为30亿个单词,训练出来的向量为300万个300维的英文单词向量。
2.文本向量构建
本研究中文本向量的表示基于两种方法:
(1)所有词均值方法:求出该文档所有词对应的词向量的均值
此方法求出每篇文档所有词对应的词向量的均值,利用np.mean()函数计算出文档向量的表示。mean()函数的功能为求取算术平均值。
numpy.mean (a,axis=None,dtype=None,out=None,keepdims=False)
其中a为一个数组,经常操作的参数为axis,此研究中函数的具体用法为np.mean(word_vecs,axis=0),我们需要得到的文本向量为一行多列的向量,word_vecs为一个行数为一篇文档的单词数,列为300的矩阵。所以将word_vecs压缩行,对各列求平均值,返回了一个1*300的矩阵,以此来代表一篇文章的向量表示。
(2)关键词表示法:求出文章关键词的词向量的均值
利用TF-IDF方法[5]求出每篇文档的前10个关键词。TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的频率高,并且在其它文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。词频(Term Frequency)指的是某一个给定的词语在该文件中出现的频率,即词w在文档d中出现的次数count(w,d)和文档d中总词数size(d)的比值,计算公式为:
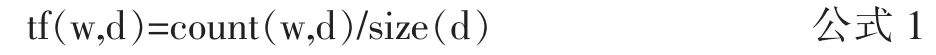
逆向文件频率(Inverse Document Frequency)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。即文档总数n与词w所出现文件数docs(w,D)比值的对数,计算公式如为:

将公式1、2代入公式3中,计算出每篇文档tfidf前10的词作为此文本的关键词。以这10个关键词的词向量的平均值来表示文本向量。
3.文本相似度计算
将文本数据化表示后,便可通过其在向量空间上的表示来计算向量之间的距离来代表文本之间的相似度。本文采用余弦相似度的方法[6],利用向量的余弦夹角来计算相似度,余弦值越大,相关性越大。源文档的文本向量表示为ti,目标文档的文本向量表示为tj。计算公式为:
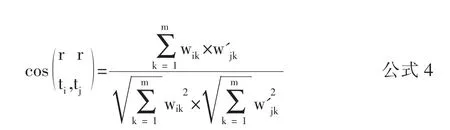
三、实验结果及分析
1.实验数据来源
本文用谷歌发布的word2vec的训练模型(googlenews_model)预先训练的词向量。其中训练语料为基于GoogleNews的300万个英文单词。利用网络爬虫,从新闻网站爬取语料作为测试语料。具体如表1所示。

表1 测试语料表
2.实验结果分析
分别将每种文本类型的第1篇作为源文件与其它14篇测试语料文本进行比较,计算其文本相似度,在模型一用全部词向量的平均值作为文本向量的方法中,分析结果,将与源文本相似度前4的文本及模型的估计评分值输出来得出结果如表2所示。

表2 模型-输出的估计评分值表
对于一些有明确二分喜好的用户系统,评价指标可以用到分类准确度指标[7]。此实验中,以源文本的类别为参照,将推荐的4篇文档进行类别对比,作为用户对推荐的二分喜好。在推荐的这4个文档中,对于一个未曾被用户选择或评分的文本,最终结果有4种,即系统推荐且属于源文档同一类别,系统推荐不属于同一类别,系统未推荐且属于同一类别,系统未推荐且不属于同一类别,分别对应的数目为Ntp、Nfp、Nfn、Ntn。其推荐准确率为推荐的L个文本中用户认为正确的所占的比例,公式为:

召回率计算公式为:

将公式6代入公式5得出P(L),将公式8代入公式7得出R(L),F1指标值计算公式为公式9。

其中M为总测试数,u为个体。系统推荐的相对应的4篇文章,让10名真实用户给其推荐打分(设定为0-1),平均分如表3所示。
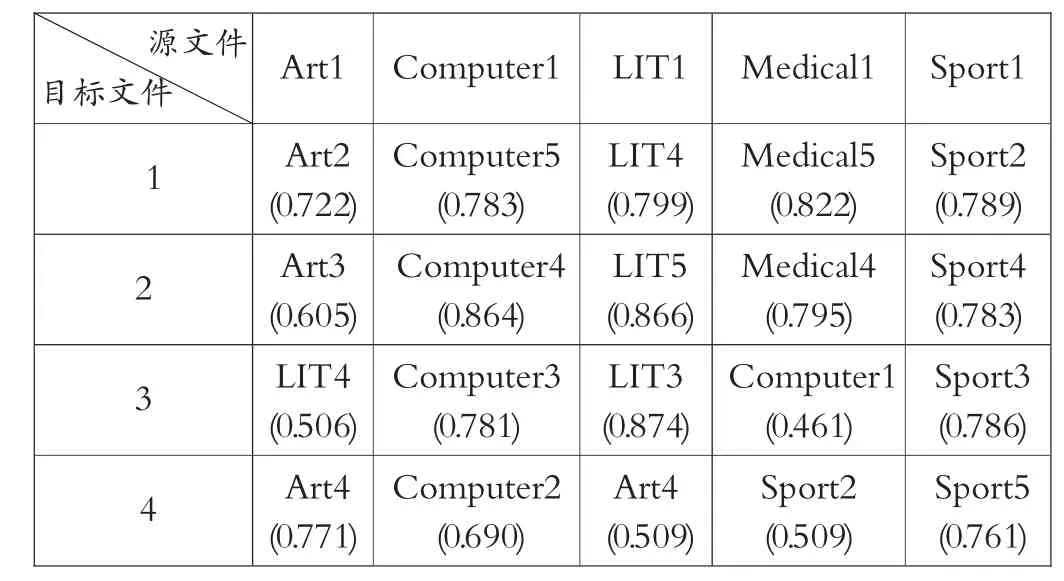
表3 用户真实打分表
在模型二中,将与源文本相似度最高的前4篇文本输出来得出结果如表4所示。系统推荐的相对应的4篇文章,让10名真实用户给其推荐打分(设定为0-1),平均分如表5所示。得出模型的评价指标数据如表6所示。计算其平均绝对误差MAE,公式为:
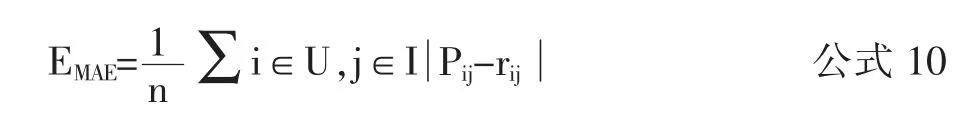
将公式 5和公式7代入公式10,可求出MAE。
四、总结和展望
本实验基于word2vec项目,得到项目给出的通过大规模的GoogleNews语料训练出的词汇向量,进而求出文本向量,通过余弦相似度方法计算向量之间的距离。在文本向量的表示中用到了两种方法并进行比较,得出提取文档关键词的词向量求平均的方法效果更好,相比传统的关键词推荐技术和VSM模型推荐技术,此方法在词向量表示时加入了语义信息,能更准确地进行文本推荐。将此法应用到英文教育文本推荐技术中,能很好地对文本进行分类处理,大大提高了学习者学习效率,使其能快速准确地学习到相关文章,同时教学者能快速准确地找到教学所需资源,更好地进行备课,使得“教”与“学”的过程更加便利。
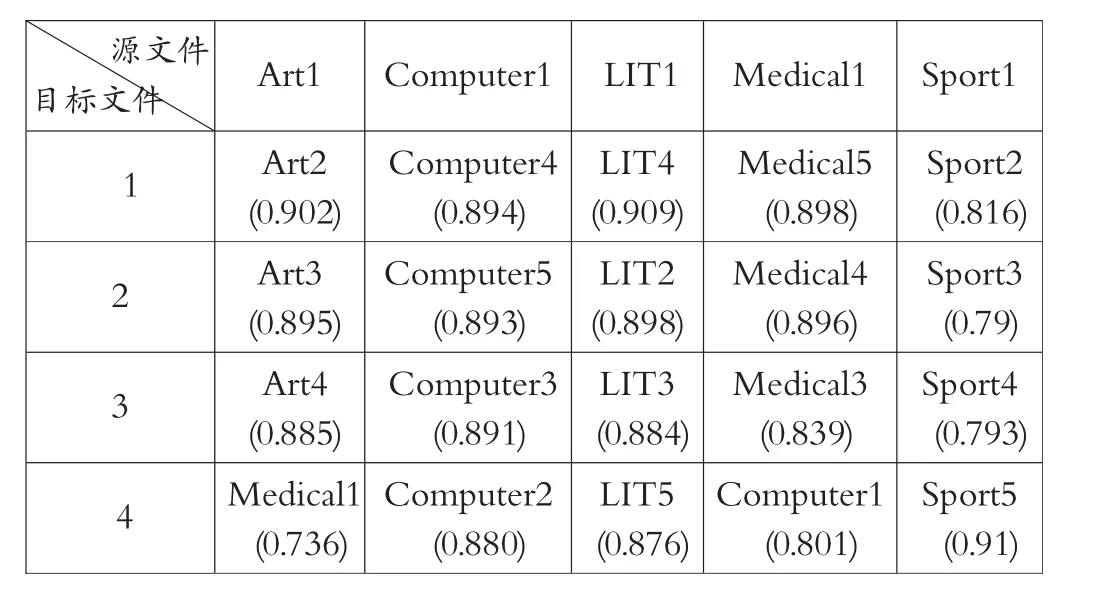
表4 模型二输出的估计评分值表
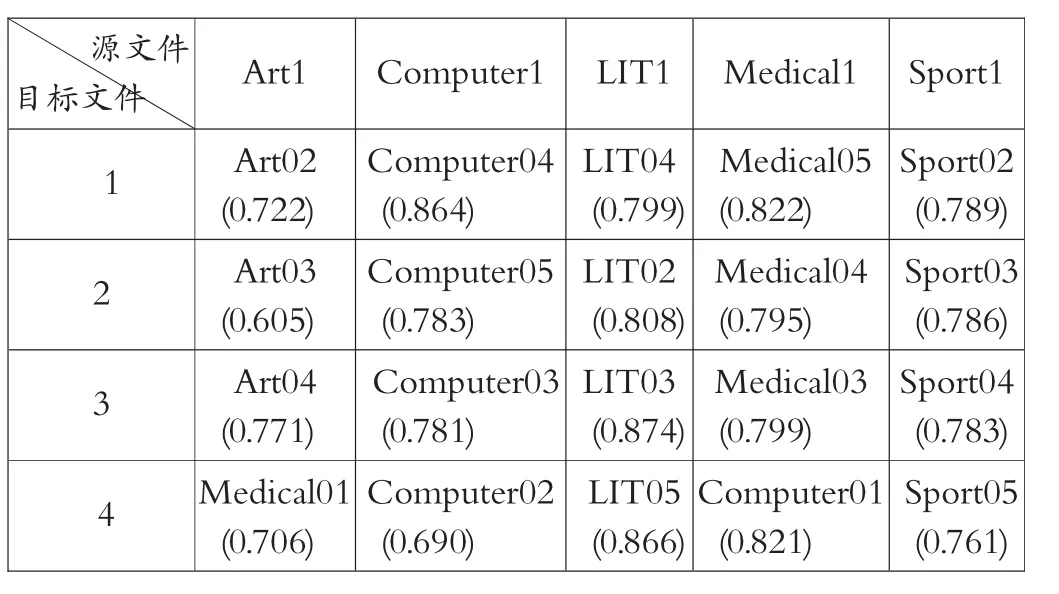
表5 用户真实打分表
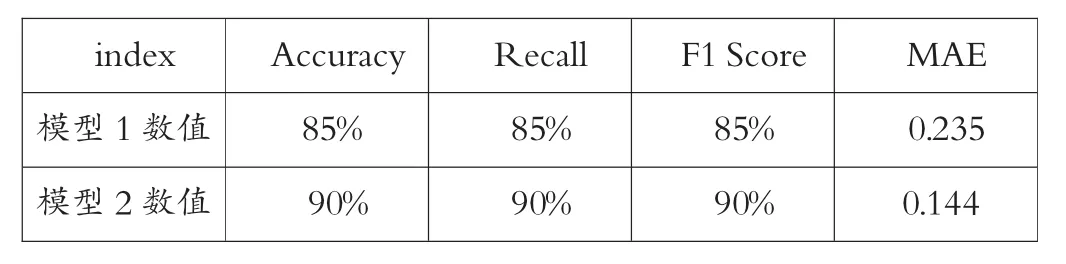
表6 评价指标数据表
