基于智能移动终端的驾驶行为聚类研究*
2018-11-01李振威高田翔刘子伟
李振威 石 英 高田翔 刘子伟
(武汉理工大学自动化学院 武汉 430070)
0 引 言
随着我国汽车保有量的迅速增长,驾驶员的不良驾驶行为成为导致交通事故和城市致堵致乱的重要因素,引起了人们对驾驶行为识别的关注度[1-2].国内外研究人员对行车过程中的驾驶行为进行了大量的研究分析,对于驾驶行为的研究主要分为基于视觉图像和基于多传感器数据融合这两种手段.
利用驾驶人或车辆的图像来对驾驶行为进行识别是目前较为主流的驾驶行为识别方案.Takenaka等[3]对车辆前装摄像头拍摄的图像进行识别,提取车辆运行状态、方向、交通信号等特征,利用双层结构分类器对这些特征进行上下文分析来评估驾驶行为.基于视觉图像的驾驶行为识别在环境理想的实验情况下识别效果较好,但实际应用中光线强度、摄像头角度的不确定性,以及周围环境的干扰都会对识别效果造成影响.
通过多种传感器融合感知车辆状态及周边环境的驾驶行为识别也渐渐流行起来.Sathyanarayana等[4]通过在车上加装加速度、重力、陀螺仪、GPS等传感器获取车辆速度、加速度等数据,利用kNN和SVM算法分别对驾驶行为进行识别.
由于给车加装便携式传感器过程复杂,且成本高,利用搭载了丰富的传感的移动智能终端进行驾驶行为检测易推广、易扩展,有着巨大的优势[5].Diaz等[6]利用智能手机内置的传感器获取速度等数据,并与车上加装的传感器获取的数据进行对比,证实两者获取的数据相似度较高,前者获取的数据能用来表示车辆的速度等状态.Eren等[7]同样利用智能手机的加速度计、陀螺仪和磁力计采集数据,进行驾驶行为的判别和其安全性的分析.
因此,本文采用智能移动终端内置的传感器采集行车数据,提出了一种基于智能移动终端的车辆驾驶行为分析方法.该方法对采集到原始数据进行时域特征提取的基础上,采用主成分分析(PCA)进行数据特征降维.对于经过主成分分析提取出主要驾驶行为特征的数据样本,结合k-means和FCM聚类算法对驾驶行为特征进行聚类,并分析其典型特点与分布规律.
1 智能移动终端数据分析与处理
1.1 传感器数据分析
智能手机自带的加速度传感器和陀螺仪均为原生三轴惯性传感器,其输出的值描述了设备在环境中的动作,对应于设备坐标系,而不是车辆对地的全局坐标系[8].设备坐标系与全局坐标系的关系见图1.
当车辆处干水平面且设备Y轴方向与车辆前进方向一致时,设备三轴方向上的加速度才能够准确地描述车辆的运动状态.为了便于实验数据处理,实验过程中智能手机水平放置,并且保持Y轴加速度方向与车辆移动方向一致,这样采集的数据在坐标系上与车辆对地坐标系保持一致.

图1 设备坐标系与全局坐标系
加速度传感器和陀螺仪数据是一个n行6列的矩阵,在正常行驶、加速和右转弯这三种驾驶行为下的传感器参数变化见图 2.
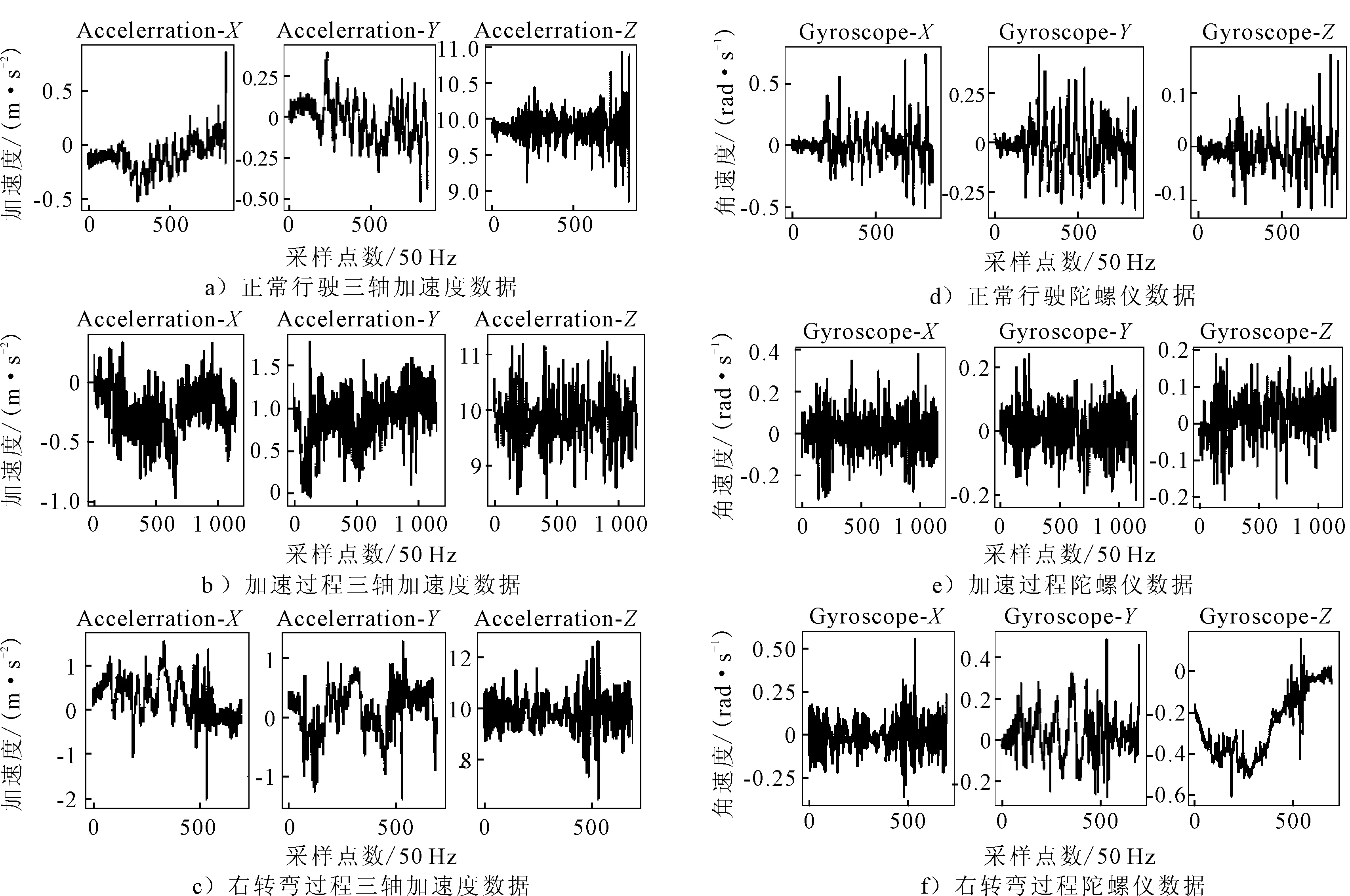
图2 不同驾驶行为传感器数据
由图2可知,三轴加速度传感器的Y轴在加速这种车辆纵向驾驶行为情况下变化明显.而在右转弯这种横向驾驶行为中三轴加速度传感器的X轴和陀螺仪绕Z轴角速度数据特征显著.因此,本文选取加速度传感器的X,Y轴和陀螺仪绕Z轴数据,也就是矩阵的第1,2,6列数据提取特征.
1.2 基于移动平均滤波的传感器数据预处理
在实际采集数据过程中,由于车身抖动和芯片自身漂移,传感器所采集的数据往往受到噪声干扰,需进行平滑滤波处理,本文采用移动平均滤波算法.
首先,对于采集数据Xj={x(i),i=1,2…,n},设定滑动窗口大小为M,那么i时刻的滤波输出值y(i)为
y(i)=y(i-1)+(x(i+p)-x(i-q))/M
(12)
式中:p=(M-1)/2;q=p+1.
滑动窗口M大小的选择十分重要.若滑动窗口M过小,数据平滑效果不明显;反之,容易过多地丢失车辆实际运动信息.通常M一般设定在[5,15]之间[9],本文选取10作为滑动窗口,见图3.
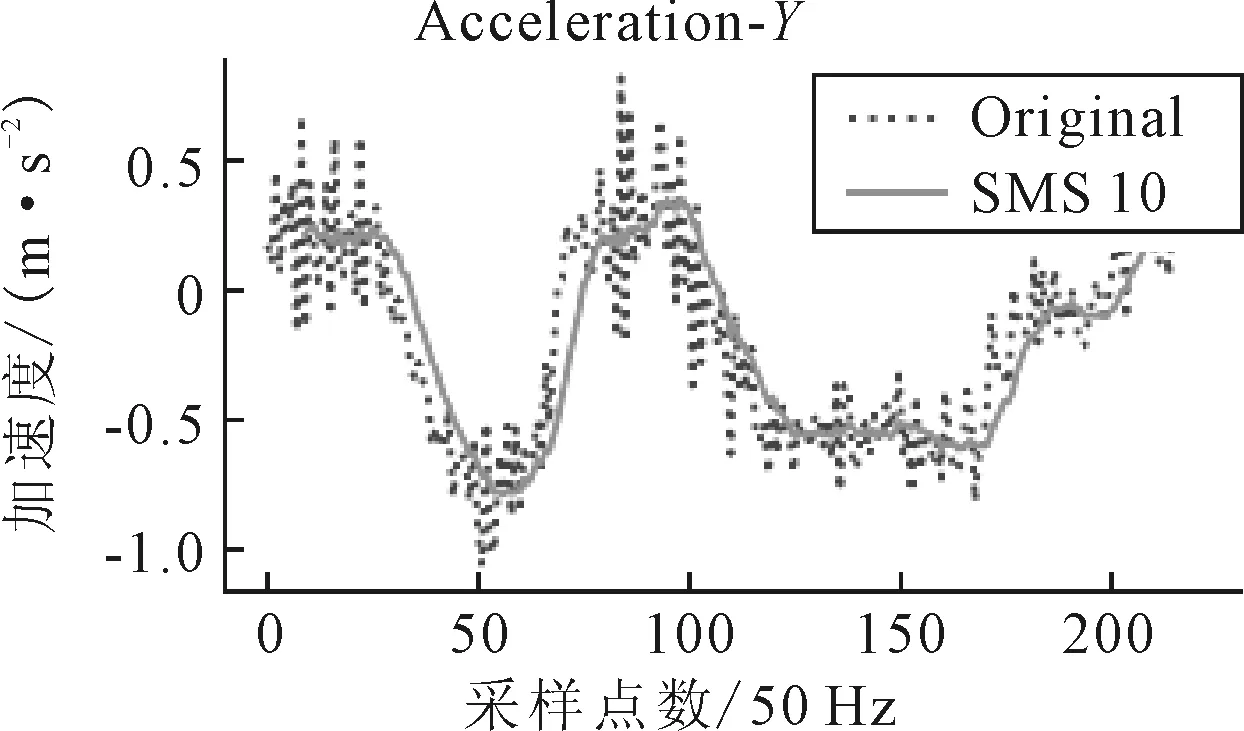
图3 加速度传感器X轴数据原始、滤波对比
由图3可知,移动平均滤波的平滑效果明显,能够有效滤除车辆震动带来的噪声.
2 基于主成分分析的特征数据降维
2.1 驾驶行为特征选取
利用上述移动平滑滤波预处理后的数据,考虑到转弯和变道等行为在极短时间间隔内具有相似性,可提取一定时间间隔内传感器数据的时域特征,提取的备选特征参数见表1.

表1 备选特征参数
表中的Xj为传感器数据矩阵的第j列数据,根据前文描述,这里选取j=1,2,6.
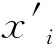
(11)
式中:xmin,xmax分别为特征值数据的最小值和最大值.
2.2 驾驶行为特征主成分分析流程
根据表1对数据样本进行特征提取,每个特征向量由21个分量组成.如此庞杂的特征参数对硬件平台的处理效率提出了较高的要求,数据降维可以有效地解决上述问题.
采用主成分分析方法,通过构造数据样本的一个正交变换,新空间的基底去除了原始空间基底下数据的相关性,因此,只需使用少数新变量就能够解释原始数据中的大部分变异[10],从而实现连续属性的数据降维,主成分分析的流程为
1) 计算相关系数矩阵n次驾驶行为数据的p=21维特征分量的原始数据矩阵X为
,X2,…,Xp)
(1)
将原始数据矩阵按列进行中心标准化后,计算相关系数矩阵R=(rij)p×p,定义rij为
(2)
2) 计算特征根 计算R的特征方程det(R-λE)=0的特征根λi,并将其按从大到小排列,即λ1≥λ2≥λp>0.
3) 确定主成分个数 根据设定的主成分累计贡献率α(α一般取85%~95%)确定主成分的个数m,即

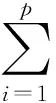
(3)
4) 计算主成分 计算m(m≤p)个特征根相应的单位特征向量βi分别为
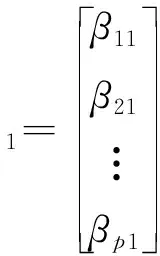
(4)
由式(4)所得单位特征向量计算相应的主成分Zi,得
Zi=β1iX1+β2iX2+…+βpiXp,i=1,2,…,m
(5)
3 驾驶行为聚类分析
3.1 聚类性能度量
对于聚类结果,通常采用外部指标和内部指标进行性能度量.前者将聚类结果与某个参考模型进行比较,后者则直接考察聚类结果.
由于目前并没有关于驾驶行为的参考模型,无法使用外部指标,因此本文采用内部指标中常用的戴维森-堡丁(Davies-Bouldin index,DBI)指数评价聚类结果.
考虑聚类结果的类簇划分C={C1,C2,…,Ck},μi为簇Ci的聚类中心.定义类簇Ci内数据样本间的平均距离为avg(Ci),类簇Ci与Cj聚类中心点间的距离为dcen(μi,μj).那么DBI指数DI可表示为[11-12].
(6)
给定两个簇,每个簇样本之间距离平均值之和比上两个簇的中心点之间的距离作为度量,然后考察该度量对所有簇的平均值,显然DI越小越好.
3.2 基于k-means聚类的驾驶行为分析
利用k-means聚类算法对给定的驾驶行为特征向量数据样本集X={x1,x2,…,xn}进行聚类划分,最终将其划分为k类C={C1,C2,…,Ck}.k-means算法的目标函数为
,μi)
(7)

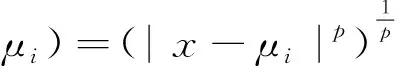
(8)
其中:p=1时,Minkowski距离为曼哈顿距离;p=2时,Minkowski距离为欧式距离.
式(7)描述了簇内样本围绕聚类中心的紧密程度,E值越小则簇内样本的相似度越高,簇和簇之间的相似程度越低.
k-means算法通过迭代优化更新聚类中心来求解目标函数的最优解,具体步骤如下:
步骤1从X中随机选取k个样本作为初始聚类中心{μ1,μ2,…,μk},给定迭代次数t和阈值ε.
步骤2计算每个数据样本到聚类中心的距离,将其归类到距离最近的那一类中;
步骤3重新计算聚类中心点,更新聚类中心μi.
步骤4重复进行步骤2,直到达到最大迭代次数t,或平方误差E的变化小于阈值ε.
本文利用k-means聚类算法对驾驶行为特征向量集进行聚类,根据聚类结果的分布以及DBI指数DI的大小确定最合理的聚类数量k.
3.3 基于FCM聚类的驾驶行为分析
驾驶行为特征数据集通过 k-means算法聚类快速确定最优聚类数量k后,再用FCM算法基于给定聚类数量进行聚类分析.
FCM算法使用隶属度来确定每一个样本数据属于某一类的程度,较之k-means 算法的单一归类方法,其聚类效果更佳[13].
利用FCM算法对给定驾驶行为特征向量数据样本集X={x1,x2,…,xn}进行聚类划分,假设分为k类C={C1,C2,…,Ck},μi为簇Ci的聚类中心.FCM算法的目标函数与k-means一样为
,μi),uij∈[0,1],m∈[1,∞]
(9)
不过相比于k-means算法,FCM算法引入了隶属度uij和模糊参数m.
uij为数据xi属于类簇Cj的程度,FCM算法要求每个驾驶行为数据样本对于各个聚类簇的隶属度之和为1,即
(10)
m则是用来控制聚类结果模糊程度的常数,越大表示聚类结果越模糊,本文取m=2.
因此,FCM算法的目标变为在式(8)的约束条件下求解式(7)的最小值,使得被划分到同一簇的驾驶行为样本之间相似度最大,而不同簇之间相似度最小.
采用Lagrange乘子法,得到其对偶规划为
(11)
FCM算法也是通过迭代优化修改聚类中心和隶属度矩阵来求解目标函数的最优值,算法具体步骤为
步骤1从X中随机选取k个样本作为初始聚类中心{μ1,μ2,…,μk},给定迭代次数t、阈值ε和模糊参数m.
步骤2根据式(9)更新隶属度uij.
步骤3重新计算聚类中心点,更新聚类中心μi.
步骤4重复进行第2步,直到达到最大迭代次数t,或平方误差E的变化小于阈值ε.
步骤5最后对每个样本取其隶属度最大值所在的类作为其确定性分类,实现模糊聚类结果的去模糊.
4 实验验证
4.1 实验数据集
采用基于Android 系统的智能手机作为实验数据采集平台,编写了一个能在Android手机上运行的传感器数据采集程序收集数据.实验中采用Android智能手机,均配备了加速度、陀螺仪等传感器.车辆在典型道路环境下实测采集实验数据,每次数据采集的持续时间为8 s,采样频率为50 Hz.
4.2 驾驶行为主成分分析结果
对实验数据集进行移动平滑滤波处理,并提取出其时域特征,对归一化后的特征向量集进行主成分分析,分析结果的碎石图见图4.

图4 主成分分析碎石图
碎石图的横轴为按特征值大小进行排列的主成分序号,纵轴为特征值.从碎石图可以看出第6个主成分为其拐点,拐点之前折线较陡峭,拐点之后折线变平缓.
前6个主成分的特征值、贡献率及累计贡献率见表2.

表2 主成分特征值、贡献率和累计贡献率
由表2可知,前5个主成分的累计贡献率已经达到86%,因此,这5个主成分足以表达数据的总体特征.
应用主成分分析后,可以把数据从21维降为5维,这5个主成分互不相关并且占据了原始数据86%的信息,其载荷矩阵见表3.主成分载荷矩阵显示了对应主成分与原评价指标间的相关性系数,取值范围为[-1,1],绝对值越大表明相关性越强.
由表3可知,Z1和Z2主要表征加速度传感器X轴和陀螺仪Z轴的数据特征,因此,这两个主成分可以用来作为横向变动较大的驾驶行为(即转弯)的指标,其中Z1表征转弯的横向加速度变化程度,Z2表征转弯的角度变化程度.
Z3和Z4主要表征加速度传感器Y轴的数据特征,因此这两个主成分可以用来作为纵向变动较大的驾驶行为(即变速)的指标,Z3表征纵向加速度变化范围,Z4表征加速度波动的程度.
Z5主要表征加速度传感器X轴和Y轴的数据特征,因此Z5可以用来作为横向和纵向均存在变动的驾驶行为(即变道)的指标.

表3 主成分载荷矩阵
4.3 驾驶行为聚类分析
前面主成分分析得到的 5个主成分按照转弯、变道和变速指标进行分组,构成三种驾驶行为聚类分析的样本矩阵,先使用k-means进行聚类寻找最优聚类数量,接着使用FCM聚类算法对样本进行精细聚类.
驾驶行为按照Z1和Z2这两个转弯指标使用k-means聚类的结果见图5.

图5 基于Z1和Z2的转弯指标的k-means聚类
由图5可知,当聚类类别数从2增加到6时,DI系数先减小再增大,在聚类类别个数为4时DI取到最小值.当DI取最小值时,每个簇的内部的样本分布紧密,表明簇内的驾驶行为样本间相似度较高;而簇之间分隔的比较开,表明每个簇代表的驾驶行为差异比较明显.那么,用转弯指标Z1和Z2对驾驶行为数据集进行聚类时最佳聚类数量为4.
利用FCM算法对样本聚类,其聚类个数为4,聚类结果见图6.由图6可知,聚类个数为4时,FCM算法聚类结果的类簇分布轮廓与k-means算法的相似,但是FCM的类簇之间分隔的更开一些.此外FCM的DI指数1.448也比k-means的1.548小,说明FCM的聚类效果明显优于k-means,但其运行时长为0.421 s,相比k-means的运行时间0.176 s,更为耗时.
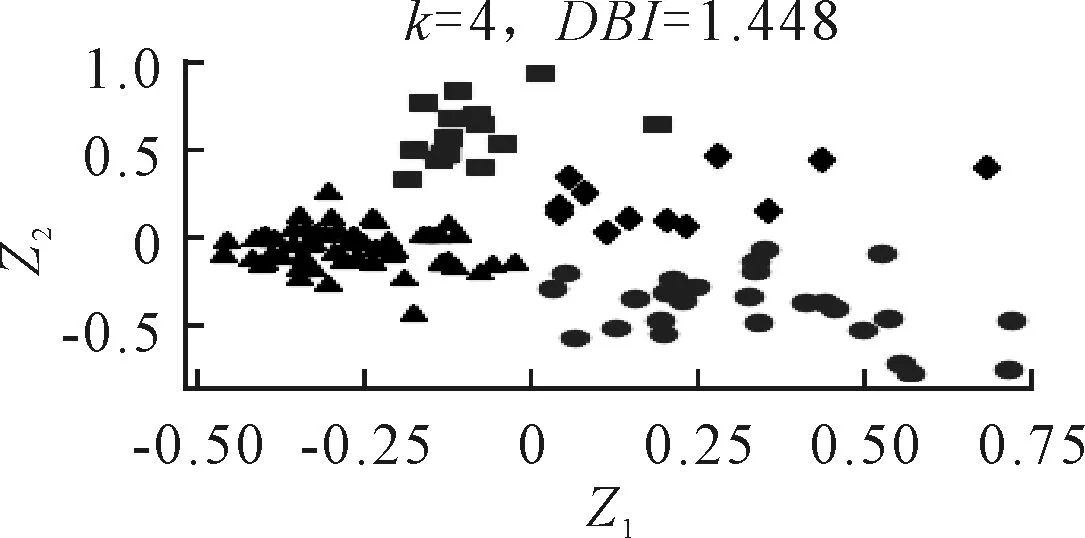
图6 基于Z1和Z2的转弯指标的FCM聚类
因此,结合k-means的快速最优聚类个数搜索性能和FCM优越的聚类分析性能,可兼顾实时性和准确性.
图6中左侧的三角形类簇两项指标都很小,表明车辆没有明显的转弯行为,而位于其右侧的三个类簇则具有不同程度的转弯行为,按照Z1和Z2的大小可分为剧烈、温和和适中这三种转弯行为.
同理,在分析变速和变道指标时,也是先通过基于k-means聚类确定聚类个数,再利用FCM算法对其进行聚类,聚类结果见表5~6.

表5 基于Z3和Z4的变速驾驶行为聚类
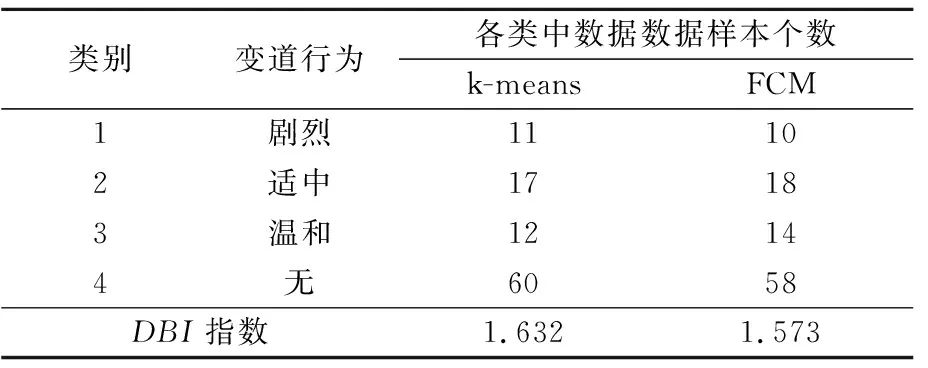
表6 基于Z5的变道驾驶行为聚类
由表5可知,驾驶行为按照Z3和Z4这两个变速指标聚为3类较合适,FCM的DBI指数比k-means的小,即FCM的聚类效果较好.聚类结果表明车辆在行驶过程中均存在变速行为,其中剧烈的变速行为占比35%,适中及温和的变速行为占比65%.
由表6可知,驾驶行为按照Z5这个变道指标聚为4类较合适,FCM的DBI指数比k-means的小,即FCM的聚类效果较好.聚类结果表明,车辆在行驶过程中大部分情况没有变道行为发生;而在发生的变道行为中,根据变道指标Z5可划分为剧烈、温和和适中.
5 结 束 语
本文利用从智能移动终端传感器采集能够表征车辆行驶状态的数据,对数据进行滤波处理后提取能够表征车辆驾驶行为的特征.通过主成分分析对车辆驾驶行为特征进行特征降维,对降维后的综合特征进行聚类分析.
实验结果表明,主成分分析有效地将驾驶行为数据的21维特征进行降维处理,提取出了5个能表明不同驾驶行为的综合特征.k-means聚类算法能够对驾驶行为数据进行快速的初步聚类,观查聚类结果的样本分布,计算DBI指数确定最优聚类个数.接着利用FCM聚类算法实现了驾驶行为数据的精细聚类,FCM聚类结果各类内部比k-means更紧密,各类间隔得比k-means更开,运行速度明显慢于k-means.
在后续研究中,将结合智能移动终端和车联网提取更多有效的驾驶行为特征参数数据,进一步完善驾驶行为评估体系,并将其应用到对驾驶员行为的规范引导以及智能驾驶辅助系统的设计中.
